Recognition: no theorem link
Distance Comparison Operations Are Not Silver Bullets in Vector Similarity Search: A Benchmark Study on Their Merits and Limits
Pith reviewed 2026-05-13 18:55 UTC · model grok-4.3
The pith
Distance comparison operations prove unstable and often slower than full scans in vector similarity search benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
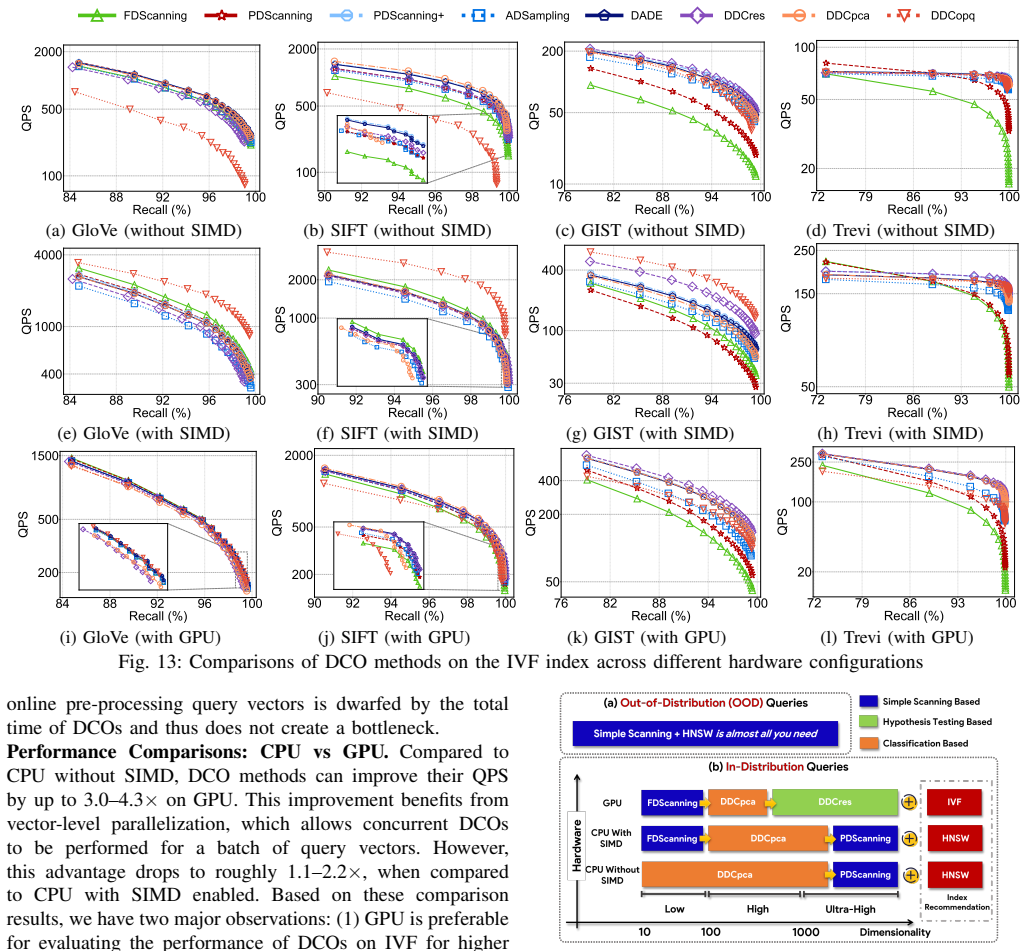
Distance Comparison Operations (DCOs) decide whether the distance between a data vector and a query lies within a threshold without full-dimensional computation. Comprehensive evaluation reveals that DCO efficiency depends heavily on data dimensionality, degrades under out-of-distribution queries, and fluctuates across hardware platforms. These operations speed up index construction and updates yet can run slower than complete distance scans, indicating they remain unsuitable for production vector database systems.
What carries the argument
Distance Comparison Operations (DCOs) that decide if the distance between a data vector and a query is within a threshold, acting as a potential shortcut to avoid full-dimensional distance computations.
If this is right
- Index construction in vector databases can run faster when using DCO methods.
- Data update operations benefit from the reduced computation offered by DCOs.
- Query latency stays unpredictable and can exceed full-scan costs on high-dimensional or shifted data.
- Hardware differences such as SIMD availability or GPU usage strongly affect DCO results.
- Production vector systems should avoid relying on current DCO implementations for query workloads.
Where Pith is reading between the lines
- Adaptive DCO variants that adjust thresholds based on detected query distribution shifts could reduce the observed performance drops.
- Hybrid query pipelines that fall back to full scans when DCO confidence is low might deliver more reliable speedups.
- Broader testing on streaming or user-generated query logs from deployed systems would clarify real-world applicability.
- Vector database designers may focus on other indexing or pruning techniques until DCO stability improves.
Load-bearing premise
The chosen datasets, query distributions, and hardware configurations sufficiently represent real-world production vector database workloads and edge cases.
What would settle it
A new experiment on large-scale data showing consistent DCO speedups over full scans across all dimensions, query distributions, and hardware platforms would challenge the instability finding.
Figures























read the original abstract
Distance Comparison Operations (DCOs), which decide whether the distance between a data vector and a query is within a threshold, are a critical performance bottleneck in vector similarity search. Recent DCO methods that avoid full-dimensional distance computations promise significant speedups, but their readiness for production vector database systems remains an open question. To address this, we conduct a comprehensive benchmark of 8 DCO algorithms across 10 datasets (with up to 100M vectors and 12,288 dimensions) and diverse hardware configurations (CPUs with/without SIMD, and GPUs). Our study reveals that these methods are not silver bullets: their efficiency is highly sensitive to data dimensionality, degrades under out-of-distribution queries, and is unstable across hardware. Yet, our evaluation also demonstrates often-overlooked merits: they can accelerate index construction and data updates. Despite these benefits, their unstable performance, which can be slower than a full-dimensional scan, leads us to conclude that recent algorithmic advancements in DCO are not yet ready for production deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript benchmarks eight distance comparison operation (DCO) algorithms across ten datasets (up to 100M vectors and 12,288 dimensions) on CPU (with/without SIMD) and GPU hardware. It reports that DCO performance is highly sensitive to dimensionality, degrades under out-of-distribution queries, exhibits instability that can exceed the cost of full-dimensional scans, yet offers benefits for index construction and data updates; the authors conclude that recent DCO advances are not yet ready for production vector-database deployment.
Significance. If the empirical findings hold, the work is significant for vector-database practitioners and researchers: it supplies large-scale evidence against treating DCO methods as default optimizations and identifies concrete failure modes (dimensionality sensitivity, OOD degradation, hardware instability) that future algorithms must address. The scale of the evaluation (multiple datasets, hardware platforms, index-construction and update scenarios) is a strength that could usefully inform both system design and follow-on research.
major comments (2)
- [Section 5] Section 5 (Results and Analysis): the central claim that DCO methods 'can be slower than a full-dimensional scan' and are therefore 'not yet ready for production' is load-bearing; the manuscript should report, for each dataset and hardware configuration, the fraction of queries or index-build phases where DCO exceeds the baseline scan time, together with confidence intervals, so readers can assess how frequently the slowdown occurs rather than only that it is possible.
- [Section 4] Section 4 (Experimental Setup): the generalization from the observed instability to a production-readiness verdict rests on the assumption that the ten datasets, query distributions (including OOD), and hardware configurations are representative of real vector-DB workloads; the paper does not provide a justification or sensitivity analysis for this choice, which weakens the deployment conclusion.
minor comments (2)
- [Table 2] Table 2 and Figure 4: axis labels and legends should explicitly state whether reported times include or exclude data-transfer overhead on GPU; this affects interpretation of the hardware-stability claims.
- [§3] The abstract states 'unstable performance' without defining the metric (e.g., coefficient of variation across runs or across datasets); a short definition in §3 would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our benchmark study. We address each major comment below and have revised the manuscript to incorporate the suggested improvements where feasible.
read point-by-point responses
-
Referee: [Section 5] Section 5 (Results and Analysis): the central claim that DCO methods 'can be slower than a full-dimensional scan' and are therefore 'not yet ready for production' is load-bearing; the manuscript should report, for each dataset and hardware configuration, the fraction of queries or index-build phases where DCO exceeds the baseline scan time, together with confidence intervals, so readers can assess how frequently the slowdown occurs rather than only that it is possible.
Authors: We agree that reporting the frequency of slowdowns with statistical support would strengthen the evidence. In the revised Section 5, we have added tables for each dataset and hardware configuration (CPU with/without SIMD, GPU) showing the fraction of queries and index-build phases where DCO runtime exceeds the full scan baseline, accompanied by 95% confidence intervals computed across repeated runs. This quantifies prevalence rather than possibility alone. revision: yes
-
Referee: [Section 4] Section 4 (Experimental Setup): the generalization from the observed instability to a production-readiness verdict rests on the assumption that the ten datasets, query distributions (including OOD), and hardware configurations are representative of real vector-DB workloads; the paper does not provide a justification or sensitivity analysis for this choice, which weakens the deployment conclusion.
Authors: We acknowledge the value of explicit justification. The revised Section 4 now includes a new subsection explaining the dataset selection criteria (standard benchmarks from prior literature covering diverse dimensionalities up to 12k, sizes up to 100M, and both ID/OOD queries) and hardware choices as representative of common production environments. We also added a sensitivity analysis varying query distributions, confirming that instability patterns persist. While exhaustive coverage of all workloads is impossible, these additions better ground our conclusions. revision: yes
Circularity Check
Pure empirical benchmark with direct measurements; no derivations or self-referential predictions
full rationale
The paper is a benchmark study that reports measured runtimes, speedups, and stability of 8 DCO algorithms across 10 datasets (up to 100M vectors, 12k dimensions) and CPU/GPU hardware. All load-bearing claims (unstable performance, occasional slowdowns vs. full scan, sensitivity to OOD queries) are direct empirical observations rather than outputs of any derivation, fitted parameter, or equation. No self-citation chain or ansatz is invoked to justify the central conclusion; the results stand on the reported measurements themselves. This is the expected non-circular outcome for a pure empirical evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
J. Gao and C. Long, “High-dimensional approximate nearest neighbor search: with reliable and efficient distance comparison operations,”Proc. ACM Manag. Data, vol. 1, no. 2, pp. 137:1–137:27, 2023
work page 2023
-
[2]
L. Deng, P. Chen, X. Zeng, T. Wang, Y . Zhao, and K. Zheng, “Effi- cient data-aware distance comparison operations for high-dimensional approximate nearest neighbor search,”PVLDB, vol. 18, no. 3, pp. 812– 821, 2024
work page 2024
-
[3]
Effective and general distance computation for approximate nearest neighbor search,
M. Yang, W. Li, J. Jin, X. Zhong, X. Wang, Z. Shen, W. Jia, and W. Wang, “Effective and general distance computation for approximate nearest neighbor search,” inICDE, 2025, pp. 1098–1110
work page 2025
-
[4]
Z. Wang, H. Xiong, Q. Wang, Z. He, P. Wang, T. Palpanas, and W. Wang, “Dimensionality-reduction techniques for approximate nearest neighbor search: A survey and evaluation,”IEEE Data Eng. Bull., vol. 48, no. 3, pp. 63–80, 2024
work page 2024
-
[5]
Y . Li, Y . Jin, B. Tian, H. Zhang, and M. Gao, “ANSMET: approximate nearest neighbor search with near-memory processing and hybrid early termination,” inISCA, 2025, pp. 1093–1107
work page 2025
-
[6]
Dforest: A minimal dimensionality-aware indexing for high-dimensional exact similarity search,
L. Li, W. Sun, and B. Wu, “Dforest: A minimal dimensionality-aware indexing for high-dimensional exact similarity search,”IEEE Trans. Knowl. Data Eng., vol. 36, no. 10, pp. 5092–5105, 2024
work page 2024
-
[7]
Milvus: A purpose-built vector data management system,
J. Wang, X. Yi, R. Guo, H. Jin, P. Xu, S. Li, X. Wang, X. Guo, C. Li, X. Xu, K. Yu, Y . Yuan, Y . Zou, J. Long, Y . Cai, Z. Li, Z. Zhang, Y . Mo, J. Gu, R. Jiang, Y . Wei, and C. Xie, “Milvus: A purpose-built vector data management system,” inSIGMOD, 2021, pp. 2614–2627
work page 2021
- [8]
-
[9]
Available: https://github.com/qdrant/qdrant
“Qdrant.” [Online]. Available: https://github.com/qdrant/qdrant
-
[10]
Source code and datasets in the benchmark
“Source code and datasets in the benchmark.” [Online]. Available: https://github.com/zzlin237/dco-benchmark.git
-
[11]
Gaussdb- vector: A large-scale persistent real-time vector database for LLM applications,
G. Li, J. Sun, J. Pan, J. Wang, Y . Xie, R. Liu, and W. Nie, “Gaussdb- vector: A large-scale persistent real-time vector database for LLM applications,”PVLDB, vol. 18, no. 12, pp. 4951–4963, 2025
work page 2025
-
[12]
Y . Han, C. Liu, and P. Wang, “A comprehensive survey on vec- tor database: Storage and retrieval technique, challenge,”CoRR, vol. abs/2310.11703, 2023
-
[13]
G. Casella and R. Berger,Statistical inference. Chapman and Hall/CRC, 2024
work page 2024
- [14]
-
[15]
Szeliski,Computer vision: algorithms and applications
R. Szeliski,Computer vision: algorithms and applications. Springer Nature, 2022
work page 2022
-
[16]
C. Manning and H. Schutze,Foundations of statistical natural language processing. MIT press, 1999
work page 1999
-
[17]
Recent advances in natural language processing via large pre-trained language models: A survey,
B. Min, H. Ross, E. Sulem, A. P. B. Veyseh, T. H. Nguyen, O. Sainz, E. Agirre, I. Heintz, and D. Roth, “Recent advances in natural language processing via large pre-trained language models: A survey,”ACM Comput. Surv., vol. 56, no. 2, pp. 30:1–30:40, 2024
work page 2024
-
[18]
B. Pecher, I. Srba, and M. Bielikov ´a, “A survey on stability of learning with limited labelled data and its sensitivity to the effects of random- ness,”ACM Comput. Surv., vol. 57, no. 1, pp. 19:1–19:40, 2025
work page 2025
-
[19]
C. D. Toth, J. O’Rourke, and J. E. Goodman,Handbook of discrete and computational geometry. CRC press, 2017
work page 2017
-
[20]
M. Wang, X. Xu, Q. Yue, and Y . Wang, “A comprehensive survey and experimental comparison of graph-based approximate nearest neighbor search,”PVLDB, vol. 14, no. 11, pp. 1964–1978, 2021
work page 1964
-
[21]
Survey of vector database management systems,
J. J. Pan, J. Wang, and G. Li, “Survey of vector database management systems,”VLDB J., vol. 33, no. 5, pp. 1591–1615, 2024
work page 2024
-
[22]
Billion-scale similarity search with gpus,
J. Johnson, M. Douze, and H. J ´egou, “Billion-scale similarity search with gpus,”IEEE Trans. Big Data, vol. 7, no. 3, pp. 535–547, 2021
work page 2021
-
[23]
M. Douze, A. Guzhva, C. Deng, J. Johnson, G. Szilvasy, P. Mazar ´e, M. Lomeli, L. Hosseini, and H. J ´egou, “The faiss library,”CoRR, vol. abs/2401.08281, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
FINGER: fast inference for graph-based approximate nearest neighbor search,
P. H. Chen, W. Chang, J. Jiang, H. Yu, I. S. Dhillon, and C. Hsieh, “FINGER: fast inference for graph-based approximate nearest neighbor search,” inWWW, 2023, pp. 3225–3235
work page 2023
-
[25]
Fast approximate nearest neighbors with automatic algorithm configuration,
M. Muja and D. G. Lowe, “Fast approximate nearest neighbors with automatic algorithm configuration,” inVISAPP, 2009, pp. 331–340
work page 2009
-
[26]
H. Abdi and L. J. Williams, “Principal component analysis,”WIRES COMPUT STAT, vol. 2, no. 4, pp. 433–459, 2010
work page 2010
-
[27]
Y . A. Malkov and D. A. Yashunin, “Efficient and robust approxi- mate nearest neighbor search using hierarchical navigable small world graphs,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 42, no. 4, pp. 824–836, 2020
work page 2020
-
[28]
A. Babenko and V . S. Lempitsky, “The inverted multi-index,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 37, no. 6, pp. 1247–1260, 2015
work page 2015
-
[29]
“Big ANN Benchmark,” 2024. [Online]. Available: https: //big-ann-benchmarks.com/
work page 2024
-
[30]
GloVe: Global Vectors for Word Representation
“GloVe: Global Vectors for Word Representation.” [Online]. Available: https://nlp.stanford.edu/projects/glove/
-
[31]
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
C. Schuhmann, R. Vencu, R. Beaumont, R. Kaczmarczyk, C. Mullis, A. Katta, T. Coombes, J. Jitsev, and A. Komatsuzaki, “LAION-400M: open dataset of clip-filtered 400 million image-text pairs,”CoRR, vol. abs/2111.02114, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[32]
MS MARCO: A human generated machine reading comprehension dataset,
T. Nguyen, M. Rosenberg, X. Song, J. Gao, S. Tiwary, R. Majumder, and L. Deng, “MS MARCO: A human generated machine reading comprehension dataset,” inCoCo@NIPS, vol. 1773, 2016
work page 2016
-
[33]
New and improved embedding model,
“New and improved embedding model,” https://openai.com/index/ new-and-improved-embedding-model/
-
[34]
“Distance comparison operations are not silver bullets in vector similarity search: An experimental study on their merits and limits (full paper).” [Online]. Available: https://github.com/zzlin237/ dco-benchmark.git
-
[35]
Diskann: Fast accurate billion-point nearest neighbor search on a single node,
S. Jayaram Subramanya, F. Devvrit, H. V . Simhadri, R. Krishnawamy, and R. Kadekodi, “Diskann: Fast accurate billion-point nearest neighbor search on a single node,”NeurIPS, vol. 32, 2019
work page 2019
-
[36]
H. Zhang, Y . Wang, Q. Chen, R. Chang, T. Zhang, Z. Miao, Y . Hou, Y . Ding, X. Miao, H. Wang, B. Pang, Y . Zhan, H. Sun, W. Deng, Q. Zhang, F. Yang, X. Xie, M. Yang, and B. Cui, “Model-enhanced vector index,” inNeurIPS, 2023
work page 2023
-
[37]
Intel® 64 and ia-32 architectures software developer’s man- ual,
P. Guide, “Intel® 64 and ia-32 architectures software developer’s man- ual,”Volume 3B: system programming guide, Part, vol. 2, no. 11, pp. 0–40, 2011
work page 2011
-
[38]
W. Li, Y . Zhang, Y . Sun, W. Wang, M. Li, W. Zhang, and X. Lin, “Approximate nearest neighbor search on high dimensional data - experiments, analyses, and improvement,”IEEE Trans. Knowl. Data Eng., vol. 32, no. 8, pp. 1475–1488, 2020
work page 2020
-
[39]
Similarity query processing for high-dimensional data,
J. Qin, W. Wang, C. Xiao, and Y . Zhang, “Similarity query processing for high-dimensional data,”PVLDB, vol. 13, no. 12, pp. 3437–3440, 2020
work page 2020
-
[40]
High-dimensional similarity query processing for data science,
J. Qin, W. Wang, C. Xiao, Y . Zhang, and Y . Wang, “High-dimensional similarity query processing for data science,” inKDD, 2021, pp. 4062– 4063
work page 2021
-
[41]
K. Lu, M. Kudo, C. Xiao, and Y . Ishikawa, “HVS: hierarchical graph structure based on voronoi diagrams for solving approximate nearest neighbor search,”PVLDB, vol. 15, no. 2, pp. 246–258, 2021
work page 2021
-
[42]
Z. Gong, Y . Zeng, and L. Chen, “Accelerating approximate nearest neighbor search in hierarchical graphs: Efficient level navigation with shortcuts,”PVLDB, vol. 18, no. 10, pp. 3518–3530, 2025
work page 2025
-
[43]
Incremental ivf index maintenance for streaming vector search,
J. Mohoney, A. Pacaci, S. R. Chowdhury, U. F. Minhas, J. Pound, C. Renggli, N. Reyhani, I. F. Ilyas, T. Rekatsinas, and S. Venkataraman, “Incremental ivf index maintenance for streaming vector search,”arXiv preprint arXiv:2411.00970, 2024
-
[44]
B. Zheng, X. Zhao, L. Weng, Q. V . H. Nguyen, H. Liu, and C. S. Jensen, “PM-LSH: a fast and accurate in-memory framework for high- dimensional approximate NN and closest pair search,”VLDB J., vol. 31, no. 6, pp. 1339–1363, 2022
work page 2022
-
[45]
X. Zhao, Y . Tian, K. Huang, B. Zheng, and X. Zhou, “Towards efficient index construction and approximate nearest neighbor search in high- dimensional spaces,”PVLDB, vol. 16, no. 8, pp. 1979–1991, 2023
work page 1979
-
[46]
Y . Tian, Z. Yue, R. Zhang, X. Zhao, B. Zheng, and X. Zhou, “Ap- proximate nearest neighbor search in high dimensional vector databases: Current research and future directions,”IEEE Data Eng. Bull., vol. 47, no. 3, pp. 39–54, 2023
work page 2023
-
[47]
Indexing metric spaces for exact similarity search,
L. Chen, Y . Gao, X. Song, Z. Li, Y . Zhu, X. Miao, and C. S. Jensen, “Indexing metric spaces for exact similarity search,”ACM Comput. Surv., vol. 55, no. 6, pp. 128:1–128:39, 2023. 13
work page 2023
-
[48]
Optimizing the number of clusters for billion-scale quantization-based nearest neighbor search,
Y . Fu, C. Chen, X. Chen, W. Wong, and B. He, “Optimizing the number of clusters for billion-scale quantization-based nearest neighbor search,” IEEE Trans. Knowl. Data Eng., vol. 36, no. 11, pp. 6786–6800, 2024
work page 2024
-
[49]
Product quantization for nearest neighbor search,
H. J ´egou, M. Douze, and C. Schmid, “Product quantization for nearest neighbor search,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 33, no. 1, pp. 117–128, 2011
work page 2011
-
[50]
An efficient and robust framework for approximate nearest neighbor search with attribute constraint,
M. Wang, L. Lv, X. Xu, Y . Wang, Q. Yue, and J. Ni, “An efficient and robust framework for approximate nearest neighbor search with attribute constraint,” inNeurIPS, 2023
work page 2023
-
[51]
Rwalks: Random walks as attribute diffusers for filtered vector search,
A. A. Aomar, K. Echihabi, M. Arnaboldi, I. Alagiannis, D. Hilloulin, and M. Cherkaoui, “Rwalks: Random walks as attribute diffusers for filtered vector search,”Proc. ACM Manag. Data, vol. 3, no. 3, pp. 212:1–212:26, 2025
work page 2025
-
[52]
PASE: postgresql ultra- high-dimensional approximate nearest neighbor search extension,
W. Yang, T. Li, G. Fang, and H. Wei, “PASE: postgresql ultra- high-dimensional approximate nearest neighbor search extension,” in SIGMOD, 2020, pp. 2241–2253
work page 2020
-
[53]
The metric spaces library maintained by the sisap initiative,
K. Figueroa, G. Navarro, and E. Chavez, “The metric spaces library maintained by the sisap initiative,” 2017. [Online]. Available: https://github.com/kaarinita/metricSpaces
work page 2017
-
[54]
Hnswlib: fast approximate nearest neighbor search,
“Hnswlib: fast approximate nearest neighbor search,” 2025. [Online]. Available: https://github.com/nmslib/hnswlib 14 32 64 96 128 160 192 224 0 600 800 1000 1200QPS FDScanning PDScanning PDScanning+ ADSampling DADE DDCres DDCpca /uni0000001b/uni00000014/uni00000019/uni00000016/uni00000015/uni00000019/uni00000017/uni0000001c/uni00000019/uni00000014/uni0000...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.