Recognition: no theorem link
GP-4DGS: Probabilistic 4D Gaussian Splatting from Monocular Video via Variational Gaussian Processes
Pith reviewed 2026-05-13 20:05 UTC · model grok-4.3
The pith
GP-4DGS integrates variational Gaussian Processes into 4D Gaussian Splatting to enable probabilistic modeling of dynamic scenes from monocular video.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By embedding variational Gaussian Processes into 4D Gaussian Splatting, the approach models the deformation fields of a large set of Gaussian primitives via custom spatio-temporal kernels, supports tractable inference through inducing points, and delivers three capabilities: uncertainty quantification for predicted motions, motion estimation in unobserved regions, and temporal extrapolation past observed frames, while improving overall reconstruction fidelity.
What carries the argument
Spatio-temporal kernels inside variational Gaussian Processes that represent correlations in the deformation fields of Gaussian primitives within 4DGS.
If this is right
- Reconstruction quality for dynamic scenes increases when probabilistic modeling replaces deterministic assumptions.
- Uncertainty estimates reliably mark areas of high motion ambiguity in the output.
- Motion can be estimated in regions lacking direct observations or with sparse sampling.
- Motion predictions extend temporally beyond the input training frames.
Where Pith is reading between the lines
- Robotics or augmented reality systems could use the uncertainty output to avoid acting on unreliable motion estimates.
- The kernel-based formulation may transfer to other point-based deformation tasks beyond Gaussian Splatting.
- Further gains in speed could come from adaptive selection of inducing points for larger scenes.
Load-bearing premise
The chosen spatio-temporal kernels sufficiently capture the correlation patterns in deformation fields across thousands of Gaussian primitives so that variational inference stays accurate.
What would settle it
Experiments where the reported uncertainty values show no correlation with actual motion prediction errors, or where reconstruction metrics fail to improve over deterministic 4DGS baselines.
Figures





read the original abstract
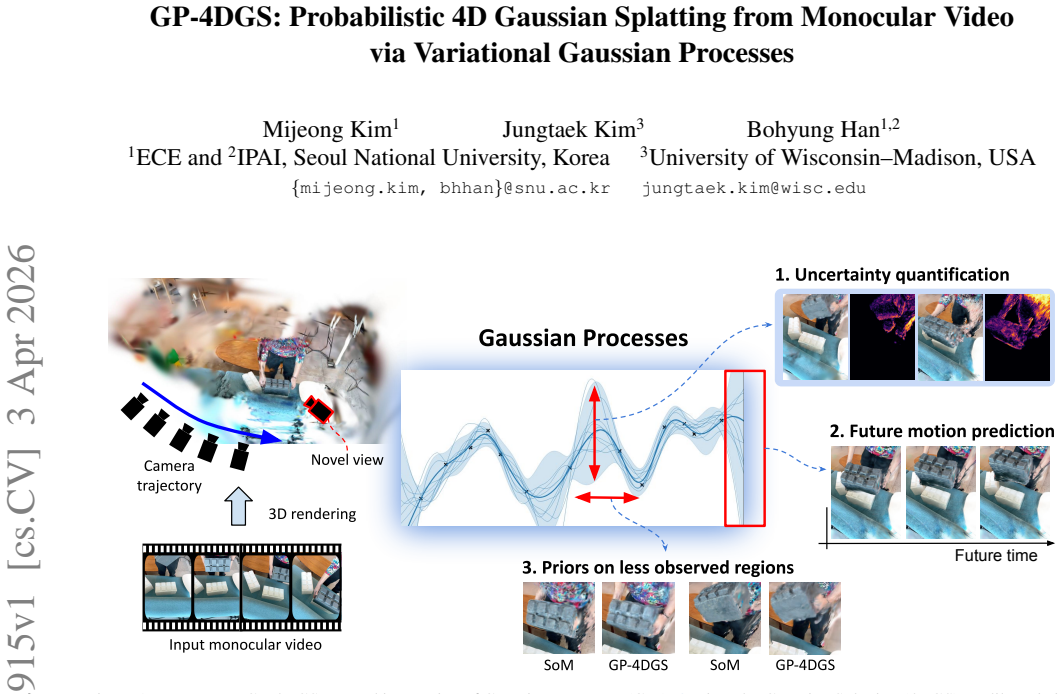
We present GP-4DGS, a novel framework that integrates Gaussian Processes (GPs) into 4D Gaussian Splatting (4DGS) for principled probabilistic modeling of dynamic scenes. While existing 4DGS methods focus on deterministic reconstruction, they are inherently limited in capturing motion ambiguity and lack mechanisms to assess prediction reliability. By leveraging the kernel-based probabilistic nature of GPs, our approach introduces three key capabilities: (i) uncertainty quantification for motion predictions, (ii) motion estimation for unobserved or sparsely sampled regions, and (iii) temporal extrapolation beyond observed training frames. To scale GPs to the large number of Gaussian primitives in 4DGS, we design spatio-temporal kernels that capture the correlation structure of deformation fields and adopt variational Gaussian Processes with inducing points for tractable inference. Our experiments show that GP-4DGS enhances reconstruction quality while providing reliable uncertainty estimates that effectively identify regions of high motion ambiguity. By addressing these challenges, our work takes a meaningful step toward bridging probabilistic modeling and neural graphics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GP-4DGS, a framework that augments 4D Gaussian Splatting with variational Gaussian Processes using custom spatio-temporal kernels and inducing-point approximations. It claims this enables three new capabilities for dynamic scene reconstruction from monocular video: calibrated uncertainty quantification over motion, inpainting of deformation fields in unobserved or sparsely sampled regions, and temporal extrapolation beyond the training frames, while maintaining or improving reconstruction fidelity.
Significance. If the central claims are substantiated, the work would meaningfully extend deterministic 4DGS methods by introducing principled probabilistic modeling. The ability to report motion uncertainty and perform extrapolation could benefit downstream tasks such as video prediction and robotics. The scalability approach via inducing points addresses a practical barrier in applying GPs to the high-dimensional per-primitive deformation fields typical of 4DGS.
major comments (2)
- [Abstract] Abstract: The abstract asserts that experiments demonstrate enhanced reconstruction quality and reliable uncertainty estimates that identify regions of high motion ambiguity, yet no quantitative metrics, baselines, error tables, or held-out frame evaluations are referenced. Without these, the three advertised capabilities cannot be assessed.
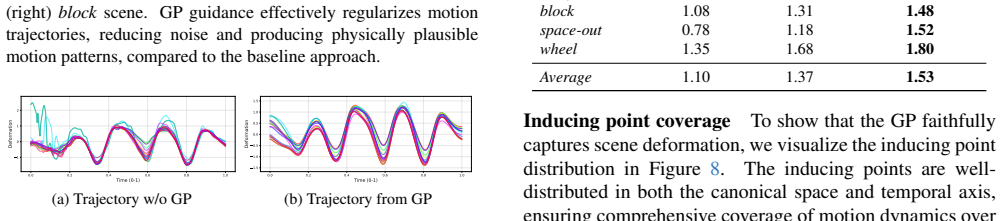
- [Method/Experiments] Method and Experiments: The central claim hinges on the spatio-temporal kernels (product or sum of spatial RBF/SE and temporal kernels) plus variational inference with inducing points preserving deformation fidelity for O(10^4–10^5) Gaussians. The manuscript must show that the optimized ELBO produces posterior variances that correlate with actual reconstruction error on held-out frames and that reducing the number of inducing points does not materially degrade uncertainty calibration or extrapolation performance; absent such verification, the capabilities reduce to the quality of the mean function alone.
minor comments (2)
- [Method] Clarify the exact form of the spatio-temporal kernel (additive vs. multiplicative) and list all free hyperparameters and inducing-point placement strategy in a dedicated subsection.
- [Experiments] Add a table or figure comparing reconstruction metrics (PSNR, SSIM, LPIPS) against standard 4DGS baselines on the same datasets to quantify the claimed enhancement.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our work's significance and for the constructive comments. We have carefully addressed each major comment and revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts that experiments demonstrate enhanced reconstruction quality and reliable uncertainty estimates that identify regions of high motion ambiguity, yet no quantitative metrics, baselines, error tables, or held-out frame evaluations are referenced. Without these, the three advertised capabilities cannot be assessed.
Authors: We agree that the abstract would benefit from referencing key quantitative aspects to better support the claims. In the revised manuscript, we have updated the abstract to briefly mention the use of metrics such as PSNR and SSIM for reconstruction quality, as well as calibration measures for uncertainty on held-out frames. The detailed tables, baselines, and evaluations are already present in the Experiments section (Section 4), including comparisons with deterministic 4DGS methods. revision: yes
-
Referee: [Method/Experiments] Method and Experiments: The central claim hinges on the spatio-temporal kernels (product or sum of spatial RBF/SE and temporal kernels) plus variational inference with inducing points preserving deformation fidelity for O(10^4–10^5) Gaussians. The manuscript must show that the optimized ELBO produces posterior variances that correlate with actual reconstruction error on held-out frames and that reducing the number of inducing points does not materially degrade uncertainty calibration or extrapolation performance; absent such verification, the capabilities reduce to the quality of the mean function alone.
Authors: This is a valid point regarding the need for explicit verification of the uncertainty estimates. The original manuscript includes qualitative evidence of uncertainty correlating with motion ambiguity and quantitative reconstruction results. To strengthen this, we have added in the revision: correlation plots between posterior variance and held-out reconstruction error, and an ablation study on the number of inducing points showing minimal degradation in calibration (via expected calibration error) and extrapolation performance for the tested range. These confirm the variational GP approximation maintains the probabilistic modeling benefits. revision: yes
Circularity Check
No circularity: derivation relies on standard variational GP machinery applied to 4DGS deformations
full rationale
The paper applies established variational Gaussian process inference (inducing-point ELBO) together with product/sum spatio-temporal kernels to per-primitive deformation fields. The three advertised capabilities—uncertainty, inpainting of unobserved regions, and extrapolation—follow directly from the GP posterior once the kernel and variational approximation are chosen; no equation reduces a claimed prediction to a fitted parameter by construction, no uniqueness theorem is imported from the authors' prior work, and no ansatz is smuggled via self-citation. The central modeling choice (kernel design + inducing points) is justified by tractability arguments that remain independent of the final reconstruction metrics.
Axiom & Free-Parameter Ledger
free parameters (2)
- spatio-temporal kernel hyperparameters
- number and placement of inducing points
axioms (2)
- domain assumption Gaussian Processes with spatio-temporal kernels can model the deformation fields of 4D Gaussian primitives
- standard math Variational inference with inducing points yields tractable and accurate approximations for large-scale GP regression
Reference graph
Works this paper leans on
-
[1]
Abdul Fatir Ansari, Lorenzo Stella, Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Syndar Rangapuram, Sebastian Pineda Arango, Shubham Kapoor, Jasper Zschiegner, Danielle C. Mad- dix, Michael W. Mahoney, Kari Torkkola, Andrew Gor- don Wilson, Michael Bohlke-Schneider, and Yuyang Wang. Chronos: Learning the language of tim...
work page 2024
-
[2]
Weiwei Cai, Weicai Ye, Peng Ye, Tong He, and Tao Chen. DynaSurfGS: Dynamic surface reconstruction with planar- based Gaussian splatting.arXiv preprint arXiv:2408.13972,
-
[3]
TensoRF: Tensorial radiance fields
Anpei Chen, Zexiang Xu, Andreas Geiger, Jingyi Yu, and Hao Su. TensoRF: Tensorial radiance fields. InECCV, 2022. 1
work page 2022
-
[4]
Neural radiance flow for 4D view synthesis and video processing
Yilun Du, Yinan Zhang, Hong-Xing Yu, Joshua B Tenen- baum, and Jiajun Wu. Neural radiance flow for 4D view synthesis and video processing. InICCV, 2021. 2
work page 2021
-
[5]
4d-rotor gaussian splatting: towards efficient novel view synthesis for dynamic scenes
Yuanxing Duan, Fangyin Wei, Qiyu Dai, Yuhang He, Wen- zheng Chen, and Baoquan Chen. 4d-rotor gaussian splatting: towards efficient novel view synthesis for dynamic scenes. In SIGGRAPH, 2024. 2
work page 2024
-
[6]
K-planes: Explicit radiance fields in space, time, and appearance
Sara Fridovich-Keil, Giacomo Meanti, Frederik Rahbæk Warburg, Benjamin Recht, and Angjoo Kanazawa. K-planes: Explicit radiance fields in space, time, and appearance. In CVPR, 2023. 2
work page 2023
-
[7]
Dynamic view synthesis from dynamic monocular video
Chen Gao, Ayush Saraf, Johannes Kopf, and Jia-Bin Huang. Dynamic view synthesis from dynamic monocular video. In ICCV, 2021. 2
work page 2021
-
[8]
Monocular dynamic view synthesis: A reality check
Hang Gao, Ruilong Li, Shubham Tulsiani, Bryan Russell, and Angjoo Kanazawa. Monocular dynamic view synthesis: A reality check. InNeurIPS, 2022. 6
work page 2022
-
[9]
FastNeRF: High-fidelity neural rendering at 200FPS
Stephan J Garbin, Marek Kowalski, Matthew Johnson, Jamie Shotton, and Julien Valentin. FastNeRF: High-fidelity neural rendering at 200FPS. InICCV, 2021. 1
work page 2021
-
[10]
GPyTorch: Blackbox matrix- matrix Gaussian process inference with GPU acceleration
Jacob Gardner, Geoff Pleiss, Kilian Q Weinberger, David Bindel, and Andrew G Wilson. GPyTorch: Blackbox matrix- matrix Gaussian process inference with GPU acceleration. In NIPS, 2018. 6
work page 2018
-
[11]
Motion-aware 3d gaussian splatting for effi- cient dynamic scene reconstruction
Zhiyang Guo, Wengang Zhou, Li Li, Min Wang, and Houqiang Li. Motion-aware 3d gaussian splatting for effi- cient dynamic scene reconstruction. InTCSVT, 2024. 2
work page 2024
-
[12]
GP-GS: Gaussian processes for enhanced Gaussian splatting.arXiv preprint arXiv:2502.02283, 2025
Zhihao Guo, Jingxuan Su, Shenglin Wang, Jinlong Fan, Jing Zhang, Liangxiu Han, and Peng Wang. GP-GS: Gaussian processes for enhanced Gaussian splatting.arXiv preprint arXiv:2502.02283, 2025. 2, 3
-
[13]
LRM: Large reconstruction model for single image to 3D
Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan. LRM: Large reconstruction model for single image to 3D. InICLR, 2024. 1
work page 2024
-
[14]
Vivid4d: Improving 4d reconstruction from monocular video by video inpainting
Jiaxin Huang, Sheng Miao, Bangbang Yang, Yuewen Ma, and Yiyi Liao. Vivid4d: Improving 4d reconstruction from monocular video by video inpainting. InICCV, 2025. 6, 7, 12
work page 2025
-
[15]
SC-GS: Sparse-controlled Gaussian splatting for editable dynamic scenes
Yi-Hua Huang, Yang-Tian Sun, Ziyi Yang, Xiaoyang Lyu, Yan-Pei Cao, and Xiaojuan Qi. SC-GS: Sparse-controlled Gaussian splatting for editable dynamic scenes. InCVPR,
-
[16]
3D Gaussian splatting for real-time radiance field rendering
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3D Gaussian splatting for real-time radiance field rendering. InACM TOG, 2023. 1, 2
work page 2023
-
[17]
3D Gaussian splatting as Markov Chain Monte Carlo
Shakiba Kheradmand, Daniel Rebain, Gopal Sharma, Wei- wei Sun, Yang-Che Tseng, Hossam Isack, Abhishek Kar, Andrea Tagliasacchi, and Kwang Moo Yi. 3D Gaussian splatting as Markov Chain Monte Carlo. InNeurIPS, 2024. 2, 3
work page 2024
-
[18]
InfoNeRF: Ray entropy minimization for few-shot neural volume ren- dering
Mijeong Kim, Seonguk Seo, and Bohyung Han. InfoNeRF: Ray entropy minimization for few-shot neural volume ren- dering. InCVPR, 2022. 1
work page 2022
-
[19]
4D Gaus- sian splatting in the wild with uncertainty-aware regulariza- tion
Mijeong Kim, Jongwoo Lim, and Bohyung Han. 4D Gaus- sian splatting in the wild with uncertainty-aware regulariza- tion. InNeurIPS, 2024. 2, 8
work page 2024
-
[20]
DynMF: Neural motion factorization for real-time dynamic view synthesis with 3D Gaussian splatting
Agelos Kratimenos, Jiahui Lei, and Kostas Daniilidis. DynMF: Neural motion factorization for real-time dynamic view synthesis with 3D Gaussian splatting. InECCV, 2024. 2
work page 2024
-
[21]
MoSca : Dynamic gaussian fusion from casual videos via 4D motion scaffolds
Jiahui Lei, Yijia Weng, Adam Harley, Leonidas Guibas, and Kostas Daniilidis. Mosca: Dynamic gaussian fusion from casual videos via 4d motion scaffolds, 2024. arXiv preprint arXiv:2405.17421. 2
-
[22]
DynIBaR: Neural dynamic image-based rendering
Zhengqi Li, Qianqian Wang, Forrester Cole, Richard Tucker, and Noah Snavely. DynIBaR: Neural dynamic image-based rendering. InCVPR, 2023. 6
work page 2023
-
[23]
Spacetime Gaussian feature splatting for real-time dynamic view syn- thesis
Zhan Li, Zhang Chen, Zhong Li, and Yi Xu. Spacetime Gaussian feature splatting for real-time dynamic view syn- thesis. InCVPR, 2024. 2, 3, 6
work page 2024
-
[24]
MegaSaM: Accurate, fast and robust structure and motion from casual dynamic videos
Zhengqi Li, Richard Tucker, Forrester Cole, Qianqian Wang, Linyi Jin, Vickie Ye, Angjoo Kanazawa, Aleksander Holyn- ski, and Noah Snavely. MegaSaM: Accurate, fast and robust structure and motion from casual dynamic videos. InCVPR,
-
[25]
Gaufre: Gaussian deformation fields for real-time dynamic novel view synthesis
Yiqing Liang, Numair Khan, Zhengqin Li, Thu Nguyen- Phuoc, Douglas Lanman, James Tompkin, and Lei Xiao. Gaufre: Gaussian deformation fields for real-time dynamic novel view synthesis. InWACV, 2025. 2
work page 2025
-
[26]
Gaussian-flow: 4d reconstruction with dynamic 3d gaussian particle
Youtian Lin, Zuozhuo Dai, Siyu Zhu, and Yao Yao. Gaussian-flow: 4d reconstruction with dynamic 3d gaussian particle. InCVPR, 2024
work page 2024
-
[27]
Modgs: Dy- namic gaussian splatting from casually-captured monocular videos
Qingming Liu, Yuan Liu, Jiepeng Wang, Xianqiang Lyv, Peng Wang, Wenping Wang, and Junhui Hou. Modgs: Dy- namic gaussian splatting from casually-captured monocular videos. InICLR, 2025. 2
work page 2025
-
[28]
VL-Grasp: a 6-Dof interactive grasp policy for language-oriented objects in cluttered indoor scenes
Yuhao Lu, Yixuan Fan, Beixing Deng, Fangfu Liu, Yali Li, and Shengjin Wang. VL-Grasp: a 6-Dof interactive grasp policy for language-oriented objects in cluttered indoor scenes. InIROS, 2023. 1
work page 2023
-
[29]
3d geometry-aware deformable gaussian splatting for dynamic view synthesis
Zhicheng Lu, Xiang Guo, Le Hui, Tianrui Chen, Min Yang, Xiao Tang, Feng Zhu, and Yuchao Dai. 3d geometry-aware deformable gaussian splatting for dynamic view synthesis. InCVPR, 2024. 2
work page 2024
-
[30]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: Representing scenes as neural radiance fields for view syn- thesis. InECCV, 2020. 1, 2
work page 2020
-
[31]
DriveWorld: 4D pre-trained scene understanding via world models for au- tonomous driving
Chen Min, Dawei Zhao, Liang Xiao, Jian Zhao, Xinli Xu, Zheng Zhu, Lei Jin, Jianshu Li, Yulan Guo, Junliang Xing, Liping Jing, Yiming Nie, and Bin Dai. DriveWorld: 4D pre-trained scene understanding via world models for au- tonomous driving. InCVPR, 2024. 1
work page 2024
-
[32]
Instant neural graphics primitives with a multires- olution hash encoding.ACM TOG, 2022
Thomas M ¨uller, Alex Evans, Christoph Schied, and Alexan- der Keller. Instant neural graphics primitives with a multires- olution hash encoding.ACM TOG, 2022. 1
work page 2022
-
[33]
Barron, Sofien Bouaziz, Dan B Goldman, Steven M
Keunhong Park, Utkarsh Sinha, Jonathan T. Barron, Sofien Bouaziz, Dan B Goldman, Steven M. Seitz, and Ricardo Martin-Brualla. Nerfies: Deformable neural radiance fields. ICCV, 2021. 2
work page 2021
-
[34]
Barron, Sofien Bouaziz, Dan B Goldman, Ricardo Martin- Brualla, and Steven M
Keunhong Park, Utkarsh Sinha, Peter Hedman, Jonathan T. Barron, Sofien Bouaziz, Dan B Goldman, Ricardo Martin- Brualla, and Steven M. Seitz. HyperNeRF: A higher- dimensional representation for topologically varying neural radiance fields.ACM TOG, 40(6):1–12, 2021. 6
work page 2021
-
[35]
Yuxin Peng et al. DeSiRe-GS: 4D street gaussians for static- dynamic decomposition and surface reconstruction for urban driving scenes. InCVPR, 2025. 1
work page 2025
-
[36]
The 2017 DAVIS Challenge on Video Object Segmentation
Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Ar- bel´aez, Alex Sorkine-Hornung, and Luc Van Gool. The 2017 DA VIS challenge on video object segmentation.arXiv preprint arXiv:1704.00675, 2017. 6
work page internal anchor Pith review arXiv 2017
-
[37]
Gaussian Processes for Machine Learning
Carl Edward Rasmussen and Christopher KI Williams. Gaussian Processes for Machine Learning. MIT Press, 2006. 1, 2
work page 2006
-
[38]
Rig3DGS: Creating controllable portraits from ca- sual monocular videos.arXiv:2402.03723, 2024
Alfredo Rivero, ShahRukh Athar, Zhixin Shu, and Dimitris Samaras. Rig3DGS: Creating controllable portraits from ca- sual monocular videos.arXiv:2402.03723, 2024. 2
-
[39]
NeRF- SLAM: Real-time dense monocular SLAM with neural radi- ance fields
Antoni Rosinol, John J Leonard, and Luca Carlone. NeRF- SLAM: Real-time dense monocular SLAM with neural radi- ance fields. InIROS, 2023. 1
work page 2023
-
[40]
Mod- eling uncertainty for Gaussian splatting.arXiv preprint arXiv:2403.18476, 2024
Luca Savant, Diego Valsesia, and Enrico Magli. Mod- eling uncertainty for Gaussian splatting.arXiv preprint arXiv:2403.18476, 2024. 2, 8
-
[41]
Tensor4D: Efficient neural 4D decomposition for high-fidelity dynamic reconstruction and rendering
Ruizhi Shao, Zerong Zheng, Hanzhang Tu, Boning Liu, Hongwen Zhang, and Yebin Liu. Tensor4D: Efficient neural 4D decomposition for high-fidelity dynamic reconstruction and rendering. InCVPR, 2023. 2
work page 2023
-
[42]
Dynamic gaussian marbles for novel view synthesis of casual monocular videos
Colton Stearns, Adam Harley, Mikaela Uy, Florian Dubost, Federico Tombari, Gordon Wetzstein, and Leonidas Guibas. Dynamic gaussian marbles for novel view synthesis of casual monocular videos. InSIGGRAPH, 2024. 2, 6, 7, 13
work page 2024
-
[43]
Variational learning of inducing variables in sparse Gaussian processes
Michalis K Titsias. Variational learning of inducing variables in sparse Gaussian processes. InAISTATS, 2009. 4
work page 2009
-
[44]
Variational bayes gaussian splatting
Toon Van de Maele, Ozan Catal, Alexander Tschantz, Christopher L Buckley, and Tim Verbelen. Variational bayes gaussian splatting. InNeurIPS, 2025. 2, 3
work page 2025
-
[45]
D-miso: Editing dynamic 3d scenes using multi-gaussians soup
Joanna Waczynska, Piotr Borycki, Joanna Kaleta, Slawomir Tadeja, and Przemysław Spurek. D-miso: Editing dynamic 3d scenes using multi-gaussians soup. InNeurIPS, 2024. 2
work page 2024
-
[46]
Shape of Mo- tion: 4D reconstruction from a single video
Qianqian Wang, Vickie Ye, Hang Gao, Weijia Zeng, Jake Austin, Zhengqi Li, and Angjoo Kanazawa. Shape of Mo- tion: 4D reconstruction from a single video. InICCV, 2025. 2, 3, 6, 7, 13
work page 2025
-
[47]
Gflow: Recovering 4D world from monocular video
Shizun Wang, Xingyi Yang, Qiuhong Shen, Zhenxiang Jiang, and Xinchao Wang. Gflow: Recovering 4D world from monocular video. InAAAI, 2025
work page 2025
-
[48]
4d gaussian splatting for real-time dynamic scene rendering
Guanjun Wu, Taoran Yi, Jiemin Fang, Lingxi Xie, Xiaopeng Zhang, Wei Wei, Wenyu Liu, Qi Tian, and Xinggang Wang. 4d gaussian splatting for real-time dynamic scene rendering. InCVPR, 2024. 2, 3, 6
work page 2024
-
[49]
Deblur4DGS: 4D Gaussian splatting from blurry monocular video.arXiv preprint arXiv:2412.06424,
Renlong Wu, Zhilu Zhang, Mingyang Chen, Zifei Yan, and Wangmeng Zuo. Deblur4DGS: 4D Gaussian splatting from blurry monocular video.arXiv preprint arXiv:2412.06424,
-
[50]
DrivingSphere: Building a high-fidelity 4D world for closed- loop simulation
Tianyi Yan, Dongming Wu, Wencheng Han, Junpeng Jiang, Xia Zhou, Kun Zhan, Cheng-zhong Xu, and Jianbing Shen. DrivingSphere: Building a high-fidelity 4D world for closed- loop simulation. InCVPR, 2025. 1
work page 2025
-
[51]
Deformable 3D Gaussians for high-fidelity monocular dynamic scene reconstruction
Ziyi Yang, Xinyu Gao, Wen Zhou, Shaohui Jiao, Yuqing Zhang, and Xiaogang Jin. Deformable 3D Gaussians for high-fidelity monocular dynamic scene reconstruction. In CVPR, 2024. 2, 3, 6
work page 2024
-
[52]
Yijun Yuan and Andreas N ¨uchter. Online learning of neural surface light fields alongside real-time incremental 3D re- construction.IEEE Robotics and Automation Letters, 8(6): 3844–3851, 2023. 1
work page 2023
-
[53]
GeoLRM: Geometry-aware large recon- struction model for high-quality 3D Gaussian generation
Chubin Zhang, Hongliang Song, Yi Wei, Chen Yu, Jiwen Lu, and Yansong Tang. GeoLRM: Geometry-aware large recon- struction model for high-quality 3D Gaussian generation. In NeuIPS, 2024. 1
work page 2024
-
[54]
DrivingGaussian: Composite gaussian splatting for surrounding dynamic au- tonomous driving scenes
Xiaoyu Zhou, Zhiwei Lin, Xiaojun Shan, Yongtao Wang, Deqing Sun, and Ming-Hsuan Yang. DrivingGaussian: Composite gaussian splatting for surrounding dynamic au- tonomous driving scenes. InCVPR, 2024. 1
work page 2024
-
[55]
On the continuity of rotation representations in neural networks
Yi Zhou, Connelly Barnes, Jingwan Lu, Jimei Yang, and Hao Li. On the continuity of rotation representations in neural networks. InCVPR, 2019. 4 A. Effect of Time-series Feature Extractor MotivationIn Variational Gaussian Processes (VGPs), the initialization of inducing pointsZis a key factor in summarizing the 4D deformation field. To represent com- plex ...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.