Recognition: 2 theorem links
· Lean TheoremDigital Twin-Assisted In-Network and Edge Collaboration for Joint User Association, Task Offloading, and Resource Allocation in the Metaverse
Pith reviewed 2026-05-13 18:26 UTC · model grok-4.3
The pith
A digital twin-assisted in-network and edge computing framework optimizes joint user association, task offloading, and resource allocation for XR devices in the metaverse by modeling interactions as a Stackelberg Markov game solved via AMRL
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the proposed DT-based INC-assisted MEC framework, by formulating the problem as a Stackelberg Markov game with an exact potential game for offloading strategies possessing a Nash Equilibrium, and employing a Nash-asynchronous hybrid multi-agent reinforcement learning algorithm, enables optimal joint optimization of user association, offloading mode selection, and power allocation, thereby improving system utility, uplink rate, and energy efficiency in metaverse environments.
What carries the argument
The Nash-asynchronous hybrid multi-agent reinforcement learning (AMRL) algorithm that predicts UL user association and DL transmission power to achieve the Nash Equilibrium in the exact potential game formed by offloading strategies.
Load-bearing premise
The assumption that the interactions between XR user devices and the network operator can be accurately modeled as a Stackelberg Markov game whose offloading strategy forms an exact potential game possessing a Nash Equilibrium that the AMRL algorithm reliably reaches.
What would settle it
A simulation or real deployment in which the AMRL algorithm fails to converge to the expected Nash Equilibrium or the claimed gains in system utility, uplink rate, and energy efficiency do not appear under realistic metaverse traffic loads and device counts.
Figures







read the original abstract
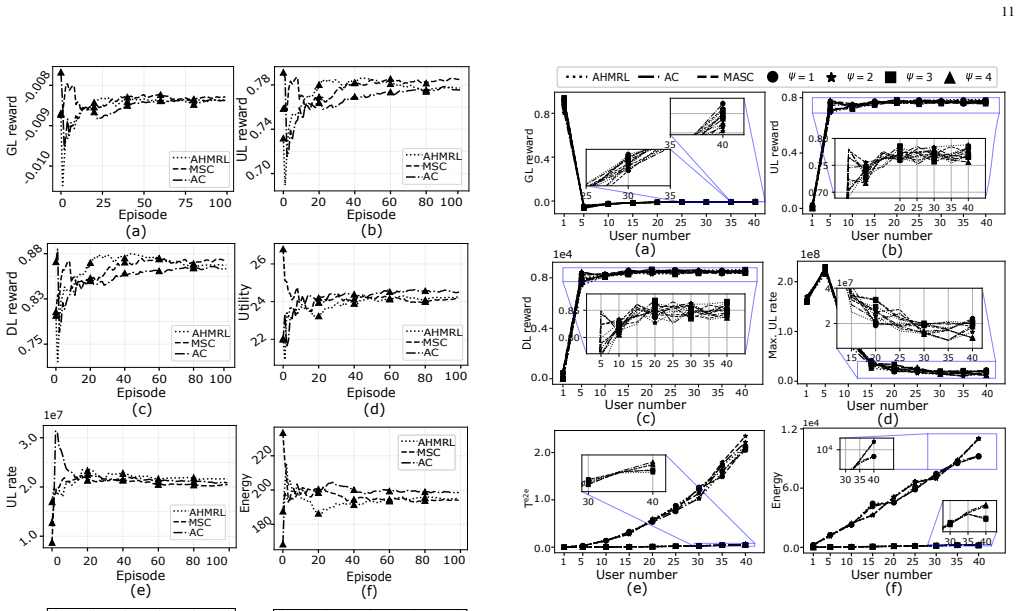
Advancements in extended reality (XR) are driving the development of the metaverse, which demands efficient real-time transformation of 2D scenes into 3D objects, a computation-intensive process that necessitates task offloading because of complex perception, visual, and audio processing. This challenge is further compounded by asymmetric uplink (UL) and downlink (DL) data characteristics, where 2D data are transmitted in the UL and 3D content is rendered in the DL. To address this issue, we propose a digital twin (DT)-based in-network computing (INC)-assisted multi-access edge computing (MEC) framework that enables real-time synchronization and collaborative computing via URLLC. In this framework, a network operator manages wireless and computational resources for XR user devices (XUDs), while XUDs autonomously offload tasks to maximize their utilities. We model the interactions between XUDs and the operator as a Stackelberg Markov game, where the optimal offloading strategy constitutes an exact potential game with a Nash Equilibrium (NE), and the operator's problem is formulated as an asynchronous Markov decision process (MDP). We further propose a decentralized solution in which XUDs determine offloading decisions based on the operator's joint UL-DL optimization of offloading mode (INC-E or MEC only) and DL power allocation. A Nash-asynchronous hybrid multi-agent reinforcement learning (AMRL) algorithm is developed to predict the UL user-associated and DL transmission power, thereby achieving NE. Simulation results demonstrate that the proposed approach considerably improves system utility, uplink rate, and energy efficiency by reducing latency and optimizing resource utilization in metaverse environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a digital twin-assisted in-network computing (INC) and multi-access edge computing (MEC) framework for joint user association, task offloading, and resource allocation in metaverse XR environments. It models interactions between XR user devices and the network operator as a Stackelberg Markov game in which offloading decisions form an exact potential game possessing a Nash Equilibrium; the operator's joint UL-DL optimization (mode selection and power allocation) is formulated as an asynchronous MDP. A decentralized Nash-asynchronous hybrid multi-agent reinforcement learning (AMRL) algorithm is introduced to reach the equilibrium, with simulation results claiming substantial gains in system utility, uplink rate, and energy efficiency via reduced latency.
Significance. If the modeling is accurate and AMRL reliably attains the claimed equilibrium, the work would provide a practical decentralized mechanism for latency-critical metaverse workloads that combines game-theoretic structure with RL, potentially improving resource utilization in URLLC edge settings. The explicit use of an exact potential game and asynchronous MDP formulation offers a structured path for analyzing incentives in asymmetric UL/DL scenarios.
major comments (2)
- [AMRL algorithm description] The section describing the AMRL algorithm: the central claim that AMRL reliably reaches the Nash Equilibrium of the exact potential game under the Stackelberg Markov model lacks any convergence proof, regret bound, or analysis of the effects of asynchrony and partial observability. Without this, the reported simulation improvements in utility, rate, and energy efficiency rest on an unverified assumption that the learned policy consistently finds the equilibrium rather than a local or approximate solution.
- [Simulation results] The simulation results section (and associated tables/figures): the abstract states considerable improvements, yet the provided description gives no information on the choice of baselines, number of Monte Carlo runs, error bars, ablation studies on the potential-game property, or the specific XR task and channel models used. This makes it impossible to determine whether the gains are robust or attributable to the proposed framework.
minor comments (2)
- [Game formulation] Clarify the precise definition of the potential function for the offloading game and confirm that it is indeed exact (rather than ordinal) under the asymmetric UL/DL data model.
- [Notation and figures] Ensure consistent notation for INC-E versus MEC-only modes and for the digital-twin synchronization delay throughout the text and figures.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below and indicate the planned revisions.
read point-by-point responses
-
Referee: [AMRL algorithm description] The section describing the AMRL algorithm: the central claim that AMRL reliably reaches the Nash Equilibrium of the exact potential game under the Stackelberg Markov model lacks any convergence proof, regret bound, or analysis of the effects of asynchrony and partial observability. Without this, the reported simulation improvements in utility, rate, and energy efficiency rest on an unverified assumption that the learned policy consistently finds the equilibrium rather than a local or approximate solution.
Authors: We acknowledge that the current version does not contain a formal convergence proof or regret analysis for AMRL. In the revised manuscript we will add a dedicated subsection deriving convergence to the Nash Equilibrium by exploiting the exact potential game property of the offloading decisions together with the asynchronous MDP structure. We will also provide a regret bound for the hybrid multi-agent updates and explicitly analyze the impact of asynchrony and partial observability under the Stackelberg Markov game formulation. revision: yes
-
Referee: [Simulation results] The simulation results section (and associated tables/figures): the abstract states considerable improvements, yet the provided description gives no information on the choice of baselines, number of Monte Carlo runs, error bars, ablation studies on the potential-game property, or the specific XR task and channel models used. This makes it impossible to determine whether the gains are robust or attributable to the proposed framework.
Authors: We agree that additional experimental details are required. The revised simulation section will specify the baselines (centralized joint optimization, random offloading, and standard multi-agent DRL without the potential-game structure), report results averaged over 5000 Monte Carlo runs with error bars showing one standard deviation, include ablation studies that isolate the contribution of the exact potential game property, and provide explicit descriptions of the XR task model (2D-to-3D rendering with defined computational complexity) and channel model (3GPP URLLC Rayleigh fading with the adopted path-loss and latency parameters). revision: yes
Circularity Check
AMRL 'prediction' of NE reduces to simulation-fitted policy; equilibrium attainment unverified beyond training data
specific steps
-
fitted input called prediction
[Abstract]
"A Nash-asynchronous hybrid multi-agent reinforcement learning (AMRL) algorithm is developed to predict the UL user-associated and DL transmission power, thereby achieving NE. Simulation results demonstrate that the proposed approach considerably improves system utility, uplink rate, and energy efficiency by reducing latency and optimizing resource utilization in metaverse environments."
The AMRL algorithm is trained on simulation trajectories to output the offloading and power decisions that are asserted to reach the NE; the same simulation environment is then used to measure the claimed improvements in utility, rate, and energy efficiency. Consequently the reported gains are the direct output of the fitted policy rather than an independent prediction from the game model.
full rationale
The paper models the interaction as a Stackelberg Markov game and states that the offloading strategy forms an exact potential game possessing a NE. It then introduces the AMRL algorithm specifically 'to predict the UL user-associated and DL transmission power, thereby achieving NE' and reports simulation improvements in utility, rate, and energy efficiency. Because the AMRL training process itself is not accompanied by a convergence proof, regret bound, or external verification, the reported performance gains are obtained from the same class of simulated trajectories used to train the policy. This makes the 'prediction' of NE attainment and the consequent system improvements statistically dependent on the fitted agent rather than independently derived from the game-theoretic model.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The optimal offloading strategy constitutes an exact potential game with a Nash Equilibrium
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A Nash-asynchronous hybrid multi-agent reinforcement learning (AMRL) algorithm is developed to predict the UL user-associated and DL transmission power, thereby achieving NE
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
I. Aliyu, A. Arigi, S. Oh, T.-W. Um, and J. Kim, “Towards a partial computation offloading in in-networking computing-assisted mec: A digital twin approach,” inNOMS 2024-2024 IEEE Network Operations and Management Symposium. IEEE, 2024, pp. 1–9
work page 2024
-
[3]
I. A. et al., “Toward a dynamic tasks offloading and resource alloca- tion for the metaverse in in-network computing,” in2023 Fourteenth International Conference on Ubiquitous and Future Networks (ICUFN). IEEE, 2023, pp. 798–803
work page 2023
-
[4]
Dynamic task software caching-assisted computation offloading for multi-access edge computing,
Z. Chen, W. Yi, A. S. Alam, and A. Nallanathan, “Dynamic task software caching-assisted computation offloading for multi-access edge computing,”IEEE Transactions on Communications, vol. 70, no. 10, pp. 6950–6965, 2022
work page 2022
-
[5]
X.-Q. Pham, T. Huynh-The, E.-N. Huh, and D.-S. Kim, “Partial com- putation offloading in parked vehicle-assisted multi-access edge com- puting: A game-theoretic approach,”IEEE Transactions on Vehicular Technology, vol. 71, no. 9, pp. 10 220–10 225, 2022
work page 2022
-
[6]
Monster mash: a single-view approach to casual 3d modeling and animation,
M. Dvoro ˇzˇn´ak, D. S `ykora, C. Curtis, B. Curless, O. Sorkine-Hornung, and D. Salesin, “Monster mash: a single-view approach to casual 3d modeling and animation,”ACM Transactions on Graphics (ToG), vol. 39, no. 6, pp. 1–12, 2020
work page 2020
-
[7]
Sample-efficient learning for edge resource allocation and pricing with bnn approximators,
F. T ¨ut¨unc¨uoglu and G. D´an, “Sample-efficient learning for edge resource allocation and pricing with bnn approximators,” inin Proc. of IEEE INFOCOM Workshops (ICCN), 2024, pp. 37–42
work page 2024
-
[8]
Pricing-driven service caching and task offloading in mobile edge computing,
J. Yan, S. Bi, L. Duan, and Y .-J. A. Zhang, “Pricing-driven service caching and task offloading in mobile edge computing,”IEEE Trans- actions on Wireless Communications, vol. 20, no. 7, pp. 4495–4512, 2021
work page 2021
-
[9]
Digital twin assisted task offloading for aerial edge computing and networks,
B. Li, Y . Liu, L. Tan, H. Pan, and Y . Zhang, “Digital twin assisted task offloading for aerial edge computing and networks,”IEEE Transactions on Vehicular Technology, vol. 71, no. 10, pp. 10 863–10 877, 2022
work page 2022
-
[10]
Digital twin for 6g: Taxonomy, research challenges, and the road ahead,
A. Masaracchia, V . Sharma, B. Canberk, O. A. Dobre, and T. Q. Duong, “Digital twin for 6g: Taxonomy, research challenges, and the road ahead,”IEEE Open Journal of the Communications Society, vol. 3, pp. 2137–2150, 2022
work page 2022
-
[11]
Intelligent task offloading and resource allocation in digital twin based aerial computing networks,
H. Guo, X. Zhou, J. Wang, J. Liu, and A. Benslimane, “Intelligent task offloading and resource allocation in digital twin based aerial computing networks,”IEEE Journal on Selected Areas in Communications, 2023. 14
work page 2023
-
[12]
A device-edge- cloud collaborative framework for hierarchical computation offloading,
W. Hou, H. Wen, N. Zhang, W. Lei, and X. Chen, “A device-edge- cloud collaborative framework for hierarchical computation offloading,” in2022 IEEE 19th International Conference on Mobile Ad Hoc and Smart Systems (MASS). IEEE, 2022, pp. 254–255
work page 2022
-
[13]
Y . Yang, L. Feng, Y . Sun, Y . Li, F. Zhou, W. Li, and S. Wang, “Decentralized cooperative caching and offloading for virtual reality task based on gan-powered multi-agent reinforcement learning,”IEEE Transactions on Services Computing, 2023
work page 2023
-
[14]
D. V . H. et al., “Urllc edge networks with joint optimal user association, task offloading and resource allocation: A digital twin approach,”IEEE Transactions on Communications, vol. 70, no. 11, pp. 7669–7682, 2022
work page 2022
-
[15]
Digital twin-aided intelligent offloading with edge selection in mobile edge computing,
T. Do-Duy, D. V . Huynh, O. A. Dobre, B. Canberk, and T. Q. Duong, “Digital twin-aided intelligent offloading with edge selection in mobile edge computing,”IEEE Wireless Communications Letters, vol. 11, no. 4, pp. 806–810, 2022
work page 2022
-
[16]
L. Fang and L. B. Milstein, “Performance of successive interference cancellation in convolutionally coded multicarrier ds/cdma systems,” IEEE Transactions on Communications, vol. 49, no. 12, pp. 2062–2067, 2001
work page 2062
-
[17]
Joint pilot and payload power allocation for massive-mimo-enabled urllc iiot networks,
H. Ren, C. Pan, Y . Deng, M. Elkashlan, and A. Nallanathan, “Joint pilot and payload power allocation for massive-mimo-enabled urllc iiot networks,”IEEE Journal on Selected Areas in Communications, vol. 38, no. 5, pp. 816–830, 2020
work page 2020
-
[18]
Radio resource management for ultra-reliable and low-latency communications,
C. She, C. Yang, and T. Q. Quek, “Radio resource management for ultra-reliable and low-latency communications,”IEEE Communications Magazine, vol. 55, no. 6, pp. 72–78, 2017
work page 2017
-
[19]
W. Yu, T. J. Chua, and J. Zhao, “Asynchronous hybrid reinforcement learning for latency and reliability optimization in the metaverse over wireless communications,”IEEE Journal on Selected Areas in Commu- nications, vol. 41, no. 7, pp. 2138–2157, 2023
work page 2023
-
[20]
Y . Xiao, Y . Song, and J. Liu, “Collaborative multi-agent deep reinforce- ment learning for energy-efficient resource allocation in heterogeneous mobile edge computing networks,”IEEE Transactions on Wireless Communications, 2023
work page 2023
-
[21]
T. J. Chua, W. Yu, and J. Zhao, “Play to earn in augmented reality with mobile edge computing over wireless networks: A deep reinforcement learning approach,”IEEE Transactions on Wireless Communications, 2024
work page 2024
-
[22]
Y . Cui, L. Du, H. Wang, D. Wu, and R. Wang, “Reinforcement learning for joint optimization of communication and computation in vehicular networks,”IEEE Transactions on Vehicular Technology, vol. 70, no. 12, pp. 13 062–13 072, 2021
work page 2021
-
[23]
Resource allocation and beamforming design in the short blocklength regime for urllc,
A. A. Nasir, H. D. Tuan, H. H. Nguyen, M. Debbah, and H. V . Poor, “Resource allocation and beamforming design in the short blocklength regime for urllc,”IEEE Transactions on Wireless Communications, vol. 20, no. 2, pp. 1321–1335, 2020
work page 2020
-
[24]
Neuralrecon: Real-time coherent 3d reconstruction from monocular video,
J. Sun, Y . Xie, L. Chen, X. Zhou, and H. Bao, “Neuralrecon: Real-time coherent 3d reconstruction from monocular video,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 15 598–15 607
work page 2021
-
[25]
Reinforcement learning- based optimal computing and caching in mobile edge network,
Y . Qian, R. Wang, J. Wu, B. Tan, and H. Ren, “Reinforcement learning- based optimal computing and caching in mobile edge network,”IEEE Journal on Selected Areas in Communications, vol. 38, no. 10, pp. 2343– 2355, 2020
work page 2020
-
[26]
Joint pushing and caching for bandwidth utilization maximization in wireless networks,
Y . Sun, Y . Cui, and H. Liu, “Joint pushing and caching for bandwidth utilization maximization in wireless networks,”IEEE Transactions on Communications, vol. 67, no. 1, pp. 391–404, 2018
work page 2018
-
[27]
Digital twin networks: A survey,
Y . Wu, K. Zhang, and Y . Zhang, “Digital twin networks: A survey,”IEEE Internet of Things Journal, vol. 8, no. 18, pp. 13 789–13 804, 2021
work page 2021
-
[28]
The digital twin: Realizing the cyber-physical production system for industry 4.0,
T. H.-J. Uhlemann, C. Lehmann, and R. Steinhilper, “The digital twin: Realizing the cyber-physical production system for industry 4.0,” Procedia Cirp, vol. 61, pp. 335–340, 2017
work page 2017
-
[29]
L. Gu, M. Cui, L. Xu, and X. Xu, “Collaborative offloading method for digital twin empowered cloud edge computing on internet of vehicles,” Tsinghua Science and Technology, vol. 28, no. 3, pp. 433–451, 2022
work page 2022
-
[30]
Adaptive edge association for wireless digital twin networks in 6g,
Y . Lu, S. Maharjan, and Y . Zhang, “Adaptive edge association for wireless digital twin networks in 6g,”IEEE Internet of Things Journal, vol. 8, no. 22, pp. 16 219–16 230, 2021
work page 2021
-
[31]
Digital-twin-assisted task offloading based on edge collaboration in the digital twin edge network,
T. Liu, L. Tang, W. Wang, Q. Chen, and X. Zeng, “Digital-twin-assisted task offloading based on edge collaboration in the digital twin edge network,”IEEE Internet of Things Journal, vol. 9, no. 2, pp. 1427– 1444, 2021
work page 2021
-
[32]
H. Zhou, L. Chen, K. Jiang, and Y . Wu, “Energy-efficient dependency- aware task offloading in mobile edge computing: A digital twin empow- ered approach,” in2022 IEEE 10th International Conference on Smart City and Informatization (iSCI). IEEE, 2022, pp. 57–62
work page 2022
-
[33]
J. Gao, L. Feng, F. Zhou, M. Dong, P. Yu, K. Ota, and X. Qiu, “Deterministic delay-aware task scheduling over in-network computing: A graph embedding-based drl approach,”IEEE Transactions on Network and Service Management, 2026
work page 2026
-
[34]
Dida: Distributed in-network intelligent data plane for machine learning applications,
G. Sidoretti, L. Bracciale, S. Salsano, H. Elbakoury, and P. Loreti, “Dida: Distributed in-network intelligent data plane for machine learning applications,”IEEE Transactions on Network and Service Management, 2025
work page 2025
-
[35]
Hybrid reward architecture for reinforcement learning,
H. Van Seijen, M. Fatemi, J. Romoff, R. Laroche, T. Barnes, and J. Tsang, “Hybrid reward architecture for reinforcement learning,” Advances in Neural Information Processing Systems, vol. 30, 2017
work page 2017
-
[36]
Handover control in wireless systems via asynchronous multiuser deep reinforcement learning,
Z. Wang, L. Li, Y . Xu, H. Tian, and S. Cui, “Handover control in wireless systems via asynchronous multiuser deep reinforcement learning,”IEEE Internet of Things Journal, vol. 5, no. 6, pp. 4296–4307, 2018. Ibrahim Aliyu(Member, IEEE) received a PhD in computer science and engineering from Chonnam National University in Gwangju, South Korea, in
work page 2018
-
[37]
He also holds BEng (2014) and MEng (2018) degrees in computer engineering from the Federal University of Technology in Minna, Nigeria. He is currently a researcher with the Hyper Intelligence Media Network Platform Lab in the Department of Intelligent Electronics and Computer System Engi- neering at Chonnam National University. His re- search focuses on d...
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.