Recognition: 2 theorem links
· Lean TheoremNeuReasoner: Towards Explainable, Controllable, and Unified Reasoning via Mixture-of-Neurons
Pith reviewed 2026-05-13 19:36 UTC · model grok-4.3
The pith
NeuReasoner detects reasoning failures through specific neuron patterns and corrects them using special tokens for unified control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
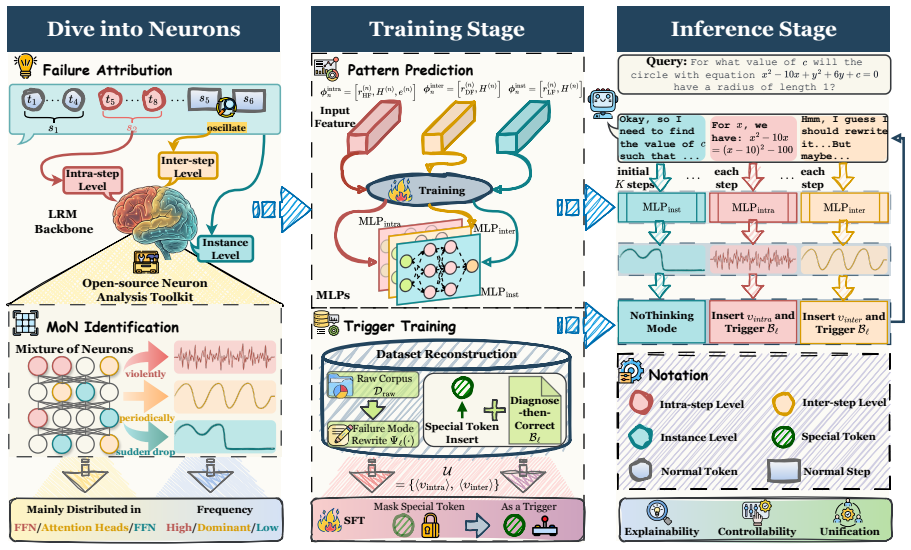
The central claim is that distinct failure modes in reasoning models correspond to identifiable fluctuation patterns in specific neurons, and that a Mixture-of-Neurons driven system can detect these patterns with MLPs and invoke remedial behaviors through special token insertion during inference, resulting in improved reasoning accuracy and efficiency.
What carries the argument
Mixture of Neurons (MoN): the set of key neurons whose fluctuation patterns are linked to distinct reasoning failure modes, used to drive detection and correction mechanisms.
If this is right
- Performance on complex reasoning tasks increases by as much as 27 percent compared to baselines.
- Token consumption during inference drops between 19.6 and 63.3 percent across tested models.
- The framework applies to backbone models ranging from 8B to 70B parameters without major changes.
- Reasoning becomes more explainable because interventions trace back to specific neuron behaviors.
Where Pith is reading between the lines
- Similar neuron-based detection could extend to other language tasks like planning or code generation.
- Controllable correction might reduce the need for extensive reinforcement learning in model training.
- Real-time failure intervention could make deployed reasoning systems more reliable in practice.
Load-bearing premise
The white-box analysis correctly identifies causal neurons whose fluctuation patterns are reliably linked to the three failure modes, and inserting special tokens triggers stable remedial behaviors without introducing new failures or hurting non-failure cases.
What would settle it
An experiment that ablates the identified neurons or prevents their fluctuation and checks whether failure detection fails, or one that inserts the special tokens in non-failure scenarios and measures if performance degrades.
Figures




read the original abstract
Large Reasoning Models (LRMs) have recently achieved remarkable success in complex reasoning tasks. However, closer scrutiny reveals persistent failure modes compromising performance and cost: I) Intra-step level, marked by calculation or derivation errors; II) Inter-step level, involving oscillation and stagnation; and III) Instance level, causing maladaptive over-thinking. Existing endeavors target isolated levels without unification, while their black-box nature and reliance on RL hinder explainability and controllability. To bridge these gaps, we conduct an in-depth white-box analysis, identifying key neurons (Mixture of Neurons, MoN) and their fluctuation patterns associated with distinct failures. Building upon these insights, we propose NeuReasoner, an explainable, controllable, and unified reasoning framework driven by MoN. Technically, NeuReasoner integrates lightweight MLPs for failure detection with a special token-triggered self-correction mechanism learned via SFT. During inference, special tokens are inserted upon failure detection to actuate controllable remedial behaviors. Extensive evaluations across six benchmarks, six backbone models (8B~70B) against nine competitive baselines, demonstrate that NeuReasoner achieves performance gains of up to 27.0% while reducing token consumption by 19.6% ~ 63.3%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NeuReasoner, a unified framework for Large Reasoning Models that performs white-box analysis to identify Mixture of Neurons (MoN) whose fluctuation patterns correlate with three failure modes (intra-step calculation errors, inter-step oscillation/stagnation, and instance-level over-thinking). It then trains lightweight MLPs to detect these failures and uses a special-token mechanism, learned via supervised fine-tuning, to trigger controllable self-correction during inference, claiming up to 27% accuracy gains and 19.6–63.3% token reductions across six benchmarks, six backbone models (8B–70B), and nine baselines.
Significance. If the causal attribution holds, the work would be significant for moving beyond black-box RL-based fixes toward explainable, controllable reasoning systems that address multiple failure levels in a single framework. The scale of evaluation (multiple model sizes and benchmarks) and the efficiency claims would be valuable contributions to the field if properly substantiated with ablations and statistical controls.
major comments (2)
- [White-box analysis / Method] White-box analysis section: the central attribution of performance gains to MoN-driven detection rests on correlational fluctuation patterns without reported causal interventions (e.g., targeted activation patching or neuron ablation); this leaves open the possibility that the MLP detector learns a proxy signal rather than a causally responsible mechanism, directly undermining the claim that special-token insertion produces stable remedial behavior.
- [Experiments / Evaluation] Evaluation section: the headline quantitative claims (up to +27% accuracy, token reductions of 19.6–63.3%) are presented without details on statistical significance testing, exact baseline re-implementations, or ablation studies isolating the contribution of the MoN detector versus the special-token mechanism; this makes it impossible to verify that the reported improvements are load-bearing on the proposed components rather than on other factors.
minor comments (2)
- [Abstract / Method] The abstract and method description would benefit from a concise diagram or pseudocode showing the exact inference-time flow of failure detection and special-token insertion.
- [Introduction] Notation for the three failure modes (I, II, III) is introduced but not consistently referenced in later sections; a short table mapping modes to neuron patterns would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the evidentiary standards needed for our claims. We respond to each major comment below and commit to revisions that directly address the identified gaps.
read point-by-point responses
-
Referee: [White-box analysis / Method] White-box analysis section: the central attribution of performance gains to MoN-driven detection rests on correlational fluctuation patterns without reported causal interventions (e.g., targeted activation patching or neuron ablation); this leaves open the possibility that the MLP detector learns a proxy signal rather than a causally responsible mechanism, directly undermining the claim that special-token insertion produces stable remedial behavior.
Authors: We agree that correlational evidence alone leaves room for alternative interpretations of the MLP detector. While the manuscript demonstrates that MoN fluctuation patterns reliably precede the three failure modes and that intervening via special-token insertion yields consistent remedial behavior, we did not include explicit causal interventions such as activation patching or ablation. In the revised manuscript we will add targeted neuron ablation experiments on the identified MoN sets, measuring the resulting change in failure rates and downstream accuracy to establish a more direct causal link. revision: yes
-
Referee: [Experiments / Evaluation] Evaluation section: the headline quantitative claims (up to +27% accuracy, token reductions of 19.6–63.3%) are presented without details on statistical significance testing, exact baseline re-implementations, or ablation studies isolating the contribution of the MoN detector versus the special-token mechanism; this makes it impossible to verify that the reported improvements are load-bearing on the proposed components rather than on other factors.
Authors: We acknowledge that the current presentation lacks the requested statistical controls and component-wise ablations. The revised version will report paired statistical significance tests (bootstrap and t-tests) across all benchmarks, provide exact hyper-parameter and implementation details for each baseline to ensure reproducibility, and include ablation tables that separately disable the MoN detector and the special-token mechanism while holding all other factors fixed. These additions will isolate the load-bearing contributions of each proposed component. revision: yes
Circularity Check
No circularity: empirical pipeline with no self-referential derivations
full rationale
The paper describes a white-box analysis to identify Mixture-of-Neurons (MoN) fluctuation patterns linked to failure modes, followed by training lightweight MLPs for detection and SFT for special-token self-correction. No equations, fitted parameters renamed as predictions, or self-citation chains are presented that reduce the claimed accuracy gains or token reductions to quantities defined by construction within the same work. Performance numbers are reported from external benchmark evaluations against baselines, making the central claims falsifiable and independent of internal redefinitions.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Mixture of Neurons (MoN)
no independent evidence
Forward citations
Cited by 4 Pith papers
-
Agent-ValueBench: A Comprehensive Benchmark for Evaluating Agent Values
Agent-ValueBench is the first dedicated benchmark for agent values, showing they diverge from LLM values, form a homogeneous 'Value Tide' across models, and bend under harnesses and skill steering.
-
Beyond Semantic Relevance: Counterfactual Risk Minimization for Robust Retrieval-Augmented Generation
CoRM-RAG uses a cognitive perturbation protocol to simulate biases and trains an Evidence Critic to retrieve documents that support correct decisions even under adversarial query changes.
-
HABIT: Chrono-Synergia Robust Progressive Learning Framework for Composed Image Retrieval
HABIT improves robustness in composed image retrieval under noisy triplets by quantifying sample cleanliness via mutual information transition rates and applying dual-consistency progressive learning to retain good pa...
-
Think in Latent Thoughts: A New Paradigm for Gloss-Free Sign Language Translation
A new SLT framework uses latent thoughts as a middle reasoning layer and plan-then-ground decoding to improve coherence and faithfulness in gloss-free sign language translation.
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code.CoRR, abs/2107.03374. Qiguang Chen, Libo Qin, Jinhao Liu, Dengyun Peng, Jiannan Guan, Peng Wang, Mengkang Hu, Yuhang Zhou, Te Gao, and Wanxiang Che. 2025. To- wards reasoning era: A survey of long chain-of- thought for reasoning large language models.CoRR, abs/2503.09567. Xingyu Chen, Jiahao Xu, Tian Liang,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.arXiv preprint arXiv:2110.14168. Alexis Conneau, German Kruszewski, Guillaume Lam- ple, Loïc Barrault, and Marco Baroni. 2018. What you can cram into a single $&!#* vector: Probing sentence embeddings for linguistic properties. In Proceedings of the 56th Annual Meeting of the As- sociation for Computational...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Let’s verify step by step.Preprint, arXiv:2305.20050. Zhan Ling, Yunhao Fang, Xuanlin Li, Zhiao Huang, Mingu Lee, Roland Memisevic, and Hao Su. 2023. Deductive verification of chain-of-thought reason- ing. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Informa- tion Processing Systems 2023, NeurIPS 2023, New Orleans, L...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
How do autoregressive transformers solve full addition? InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 12743–12767, Suzhou, China. Association for Computational Linguistics. Leonardo Ranaldi, Marco Valentino, and André Fre- itas. 2025. Improving chain-of-thought reasoning via quasi-symbolic abstractions. In...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Layer by layer: Uncovering hidden representa- tions in language models. InForty-second Interna- tional Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025. OpenRe- view.net. Alessandro Stolfo, Yonatan Belinkov, and Mrinmaya Sachan. 2023. A mechanistic interpretation of arith- metic reasoning in language models using causal m...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Math-shepherd: Verify and reinforce llms step- by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, pages 9426–9439. Association for Computational Linguistics. Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le,...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Tree of thoughts: Deliberate problem solving with large language models. InAdvances in Neural Information Processing Systems 36: Annual Confer- ence on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023. Zijun Yao, Yantao Liu, Yanxu Chen, Jianhui Chen, Jun- feng Fang, Lei Hou, Juanzi Li, and Tat-Seng Chua
work page 2023
-
[8]
Are reasoning models more prone to hallucination? arXiv preprint arXiv:2505.23646, 2025
Are reasoning models more prone to halluci- nation?CoRR, abs/2505.23646. Kun Yi, Qi Zhang, Wei Fan, Shoujin Wang, Pengyang Wang, Hui He, Ning An, Defu Lian, Longbing Cao, and Zhendong Niu. 2023. Frequency-domain mlps are more effective learners in time series forecast- ing. InAdvances in Neural Information Processing 12 Systems 36: Annual Conference on Ne...
-
[9]
is a continuously updated coding benchmark explicitly designed to mitigate test-set contami- nation by collecting newly released competitive- programming problems over time. Beyond code generation, it emphasizes holistic coding abilities (e.g., self-repair, execution, test-output prediction) and provides time-stamped releases (e.g., hundreds of problems s...
work page 2023
-
[12]
<CONTROL> error_length: {short|medium| long} error_type: {dropped_case| invalid_division|sign_error| algebra_simplification_error| mistaken_assumption| domain_violation} style: LRM_natural_first_person </CONTROL> ### INSTRUCTIONS Produce a single reasoning trace following these steps strictly:
-
[14]
Do not introduce multiple errors
**Error Injection:** Identify the next critical step and rewrite it to be plausibly * wrong* based on the`error_type `. Do not introduce multiple errors
-
[15]
**Trigger Insertion:** Immediately after the wrong step, insert this exact block: <INTRA> [FAILURE_INTRA] A key reasoning error surfaced a few steps back. I should identify the mistaken span, briefly analyze it, and correct it before continuing. −**error span**: "<quote the wrong text span>" −**analysis**: <1−3 sentences explaining why it is wrong>
-
[16]
**Correct & Continue:** After the block, "back up" logically, apply the correction, and continue reasoning to the correct final answer
-
[17]
**Format:** Use natural first− person reasoning. Return ONLY the reconstructed reasoning trace (no meta commentary, no JSON, no extra headers). INTER-STEPLEVELRECONSTRUCTION ### SYSTEM You are a data−construction assistant for SFT. Your task is to generate reasoning trajectories containing an " Inter−step Level" stagnation− and−repair pattern. ### INPUT FORMAT
- [18]
- [19]
-
[20]
<CONTROL> loop_length_paragraphs: {3|4|5} loop_theme: {mod_checks|bounds| symmetry_observations| equivalent_reformulations} style: LRM_natural_first_person </CONTROL> ### INSTRUCTIONS Produce a single reasoning trace following these steps strictly:
-
[21]
**Context:** Copy the first 2−4 steps of the < REFERENCE_REASONING> verbatim
-
[22]
− The model must oscillate between strategies related to` loop_theme`
**Loop Generation:** Create a realistic stagnation loop of` loop_length_paragraphs`. − The model must oscillate between strategies related to` loop_theme`. − It should sound logical but fail to make decisive progress (spinning wheels). − Do not generate nonsense; simulate a model trying but failing to break through
-
[23]
Let me summarize the loop, then pivot to a genuinely different route
**Trigger Insertion:** Immediately after the loop, 19 insert this exact block: <INTER> [FAILURE_INTER] I'm stuck in an inter−step loop: I keep revisiting the same near equivalent checks and switching between them whenever one stalls, without any progress. Let me summarize the loop, then pivot to a genuinely different route. −**past attempts summary:** <2−...
-
[24]
**Pivot & Finish:** Define a pivot plan (1−2 sentences naming a different framework and the next concrete step). Insert this plan into the block above, then immediately execute it and continue reasoning to the correct final answer
-
[25]
**Format:** Use natural first− person reasoning. Return ONLY the reconstructed reasoning trace (no meta commentary, no JSON, no extra headers). INTRA-STEPLEVELFAILUREDETECTION ### SYSTEM You are an expert Logic Verifier. Your goal is to strictly evaluate a reasoning trace for **Local Validity**. You will be given a <PROBLEM> and a <REASONING_TRACE>. You m...
-
[26]
**Calculation/Algebra**: Sign errors, invalid simplification, arithmetic mistakes (e.g., 2+2=5)
-
[27]
**Domain Violation**: Dividing by zero, taking the log of a negative, applying a theorem outside its valid conditions
-
[28]
**Logic Non−sequitur**: The conclusion of step N does not logically follow from step N−1
-
[29]
**Hallucination**: Inventing constraints or values not present in the problem context
-
[30]
**Dropped Case**: Arbitrarily narrowing the scope (e.g., assuming x is positive without proof). **CRITICAL NOTE**: − Ignore "inefficient" steps or " circular" reasoning (that is a separate check). − Focus ONLY on whether the specific statement is * factually* or *mathematically* false. ### OUTPUT FORMAT Return valid JSON only. { "has_error": boolean, "fir...
-
[31]
**Equivalent Reformulations**: Rewriting the same equation in different forms without isolating new variables (e.g., x=5−y −> y=5−x −> x+y=5)
-
[32]
**Strategy Oscillation**: Switching back and forth between two approaches (e.g., Modular Arithmetic −> Bounds −> 20 Modular Arithmetic) without ruling anything out
-
[33]
**Empty Verbosification**: Long explanations that restate the goal or definitions without deriving new data
-
[34]
**Repetitive Checks**: Testing values or cases that were already implicitly or explicitly handled. **CRITICAL NOTE**: − A long derivation is NOT a loop if it is making progress towards a solution. − A "stagnation" means the* Information Entropy* is not decreasing (the search space isn't shrinking). ### OUTPUT FORMAT Return valid JSON only. { "is_stagnant"...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.