Recognition: 1 theorem link
· Lean TheoremGram-MMD: A Texture-Aware Metric for Image Realism Assessment
Pith reviewed 2026-05-13 20:02 UTC · model grok-4.3
The pith
Gram-MMD judges generated image realism by measuring correlations between feature maps instead of semantic content.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Gram-MMD computes symmetric Gram matrices from activations at chosen layers of backbones such as DINOv2, VGG19, or Stable Diffusion VAE, extracts their upper-triangular elements, and reports the MMD distance to an anchor distribution of real images, thereby encoding textural and structural correlations at a granularity finer than global embeddings.
What carries the argument
Gram matrices formed from outer products of feature-map vectors at intermediate backbone layers, with MMD computed on their flattened upper-triangular parts.
If this is right
- GMMD can flag textural artifacts in generated images that FID and CMMD overlook.
- In domain-shift settings such as real versus synthetic driving scenes, GMMD maintains the expected ranking of realism.
- The same Gram-MMD formulation works across multiple backbone architectures without retraining.
- Meta-metric selection on controlled degradations produces hyperparameters that transfer to unseen datasets.
Where Pith is reading between the lines
- Combining GMMD scores with a semantic metric could yield a two-axis realism evaluation that separates texture failures from semantic failures.
- The approach might extend to video or 3D assets where frame-to-frame texture consistency matters.
- Layer selection could be automated by maximizing the meta-metric correlation rather than fixed by hand.
Load-bearing premise
Gram matrices computed from intermediate activations of pretrained networks reliably encode the textural and structural differences that separate real photographs from generated images.
What would settle it
A controlled test set in which images differ only in fine-grained texture statistics while semantic content and global statistics remain matched, with human preference labels available; if GMMD scores show no correlation with those labels while semantic metrics do, the claim fails.
Figures











read the original abstract
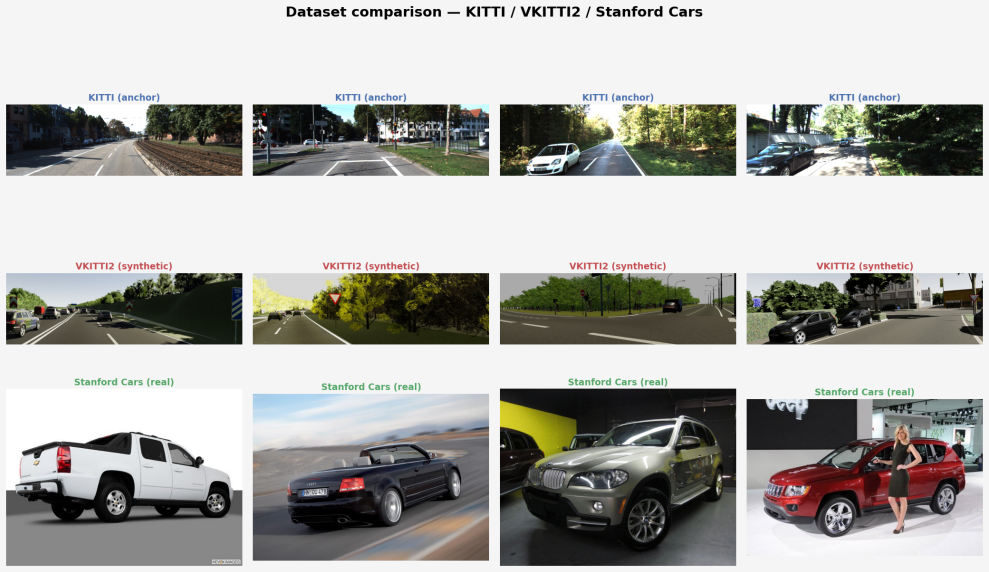
Evaluating the realism of generated images remains a fundamental challenge in generative modeling. Existing distributional metrics such as the Frechet Inception Distance (FID) and CLIP-MMD (CMMD) compare feature distributions at a semantic level but may overlook fine-grained textural information that can be relevant for distinguishing real from generated images. We introduce Gram-MMD (GMMD), a realism metric that leverages Gram matrices computed from intermediate activations of pretrained backbone networks to capture correlations between feature maps. By extracting the upper-triangular part of these symmetric Gram matrices and measuring the Maximum Mean Discrepancy (MMD) between an anchor distribution of real images and an evaluation distribution, GMMD produces a representation that encodes textural and structural characteristics at a finer granularity than global embeddings. To select the hyperparameters of the metric, we employ a meta-metric protocol based on controlled degradations applied to MS-COCO images, measuring monotonicity via Spearman's rank correlation and Kendall's tau. We conduct experiments on both the KADID-10k database and the RAISE realness assessment dataset using various backbone architectures, including DINOv2, DC-AE, Stable Diffusion's VAE encoder, VGG19, and the AlexNet backbone from LPIPS, among others. We also demonstrate on a cross-domain driving scenario (KITTI / Virtual KITTI / Stanford Cars) that CMMD can incorrectly rank real images as less realistic than synthetic ones due to its semantic bias, while GMMD preserves the correct ordering. Our results suggest that GMMD captures complementary information to existing semantic-level metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Gram-MMD (GMMD), a realism metric that extracts upper-triangular Gram matrices from intermediate activations of pretrained backbones (DINOv2, VGG19, LPIPS-AlexNet, etc.) and computes MMD against an anchor real-image distribution. Hyperparameters (backbone, layer, kernel) are chosen via a meta-metric that maximizes Spearman/Kendall monotonicity under controlled degradations on MS-COCO. Experiments on KADID-10k and RAISE report positive trends, and a cross-domain example (KITTI/Virtual KITTI/Stanford Cars) shows GMMD preserving correct real-vs-synthetic ordering where CMMD fails due to semantic bias. The central claim is that GMMD supplies complementary textural information to semantic metrics such as FID and CMMD.
Significance. If the generalization claim holds, GMMD would be a useful addition to the evaluation toolkit for generative models, addressing the known semantic bias of embedding-based distances. The Gram-matrix construction is parameter-light once hyperparameters are fixed and the meta-metric protocol is reproducible in principle, which strengthens the contribution relative to purely empirical metrics.
major comments (3)
- [Abstract] Abstract / meta-metric protocol: the hyperparameter search is driven exclusively by monotonicity under a fixed menu of controlled degradations on MS-COCO. No experiment is reported that verifies whether the selected configuration remains monotonic or correlates with human judgments when the distribution shift is produced by actual diffusion or GAN generators (texture repetition, high-frequency artifacts, color shifts). This assumption is load-bearing for the claim that GMMD generalizes beyond the meta-metric training degradations.
- [Experiments] Cross-domain experiment: the manuscript states that CMMD incorrectly ranks real images below synthetic ones while GMMD preserves the correct ordering, yet no numerical GMMD or CMMD scores, image counts, or backbone/layer choices are supplied for the KITTI/Virtual KITTI/Stanford Cars sets. Without these values it is impossible to judge the magnitude or statistical reliability of the reported ordering difference.
- [Experiments] KADID-10k and RAISE results: the abstract reports “positive experimental trends” but supplies neither error bars, ablation tables across backbones/layers, nor statistical significance tests. The absence of these quantities makes it difficult to determine whether the observed complementarity to CMMD/FID is robust or merely suggestive.
minor comments (2)
- [Abstract] The acronym GMMD is introduced in the title and abstract but the text alternates between Gram-MMD and GMMD; a single consistent abbreviation would reduce reader confusion.
- Backbone names such as “DC-AE” and “Stable Diffusion’s VAE encoder” appear without citation or architectural reference; adding the original papers or a brief description would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract / meta-metric protocol: the hyperparameter search is driven exclusively by monotonicity under a fixed menu of controlled degradations on MS-COCO. No experiment is reported that verifies whether the selected configuration remains monotonic or correlates with human judgments when the distribution shift is produced by actual diffusion or GAN generators (texture repetition, high-frequency artifacts, color shifts). This assumption is load-bearing for the claim that GMMD generalizes beyond the meta-metric training degradations.
Authors: We appreciate this observation regarding the meta-metric protocol. The controlled degradations on MS-COCO were selected to emulate common textural artifacts (e.g., blur, noise, compression) that frequently appear in diffusion and GAN outputs. While we did not conduct separate monotonicity verification on actual generator samples for hyperparameter selection, the reported positive trends on KADID-10k and RAISE—which incorporate human perceptual judgments on real-world distortions—provide supporting evidence for applicability beyond the meta-training set. In the revision we will add a dedicated paragraph clarifying the design rationale for the degradations and their relation to generative artifacts. revision: partial
-
Referee: [Experiments] Cross-domain experiment: the manuscript states that CMMD incorrectly ranks real images below synthetic ones while GMMD preserves the correct ordering, yet no numerical GMMD or CMMD scores, image counts, or backbone/layer choices are supplied for the KITTI/Virtual KITTI/Stanford Cars sets. Without these values it is impossible to judge the magnitude or statistical reliability of the reported ordering difference.
Authors: We agree that the absence of numerical scores, image counts, and exact hyperparameter choices limits evaluation of the cross-domain results. This was an oversight in the current draft. The revised manuscript will include a table reporting GMMD and CMMD scores for KITTI, Virtual KITTI, and Stanford Cars, the number of images sampled from each set, and the specific backbone/layer used for GMMD. revision: yes
-
Referee: [Experiments] KADID-10k and RAISE results: the abstract reports “positive experimental trends” but supplies neither error bars, ablation tables across backbones/layers, nor statistical significance tests. The absence of these quantities makes it difficult to determine whether the observed complementarity to CMMD/FID is robust or merely suggestive.
Authors: We concur that error bars, ablations, and significance testing are needed to substantiate the claims of complementarity. The revised version will add error bars to the KADID-10k and RAISE results, include ablation tables across the tested backbones and layers, and report statistical significance tests (e.g., p-values on rank correlations) to demonstrate robustness. revision: yes
Circularity Check
Gram-MMD definition is direct from Gram matrices and MMD; no reduction to inputs by construction
full rationale
The paper defines GMMD explicitly via extraction of upper-triangular Gram matrices from intermediate activations of pretrained backbones followed by MMD computation between real and evaluation distributions. Hyperparameter selection (backbone, layer, kernel) occurs via an external meta-metric protocol measuring monotonicity under controlled degradations on MS-COCO; this choice is made once and does not enter the final metric equation or reduce any reported score to a fitted parameter by construction. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked to justify the core formulation. The derivation chain remains self-contained against the stated assumptions about what Gram matrices encode.
Axiom & Free-Parameter Ledger
free parameters (1)
- hyperparameters of GMMD
axioms (1)
- domain assumption Gram matrices from intermediate activations capture textural and structural correlations relevant to image realism
Reference graph
Works this paper leans on
- [1]
-
[2]
S. Jayasumana, S. Ramalingam, A. Veit, D. Glasner, A. Chakrabarti, and S. Kumar. Rethinking FID: To- wards a better evaluation metric for image generation. InCVPR, 2024
work page 2024
-
[3]
H. Lin, V . Hosu, and D. Saupe. KADID-10k: A large- scale artificially distorted IQA database. InQoMEX, 2019
work page 2019
- [4]
-
[5]
A. Mukherjee, S. Dubey, and S. Paul. RAISE: Real- ness assessment for image synthesis and evaluation. arXiv preprint arXiv:2505.19233, 2025
-
[6]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni,et al.DINOv2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [7]
-
[8]
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with la- tent diffusion models. InCVPR, 2022
work page 2022
-
[9]
K. Simonyan and A. Zisserman. Very deep convolu- tional networks for large-scale image recognition. In ICLR, 2015
work page 2015
-
[10]
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Ben- gio. Generative adversarial nets. InNeurIPS, 2014
work page 2014
-
[11]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. InNeurIPS, 2020
work page 2020
-
[12]
T. Salimans, I. Goodfellow, W. Zaremba, V . Cheung, A. Radford, and X. Chen. Improved techniques for training GANs. InNeurIPS, 2016
work page 2016
- [13]
-
[14]
A. Gretton, K. M. Borgwardt, M. J. Rasch, B. Schölkopf, and A. Smola. A kernel two-sample test. JMLR, 13:723–773, 2012
work page 2012
-
[15]
A. Radford, J. W. Kim, C. Hallacy,et al.Learning transferable visual models from natural language su- pervision. InICML, 2021
work page 2021
-
[16]
L. A. Gatys, A. S. Ecker, and M. Bethge. A neural algorithm of artistic style.arXiv preprint arXiv:1508.06576, 2015
work page Pith review arXiv 2015
-
[17]
D.-T. Dang-Nguyen, C. Pasquini, V . Conotter, and G. Boato. RAISE: A raw images dataset for digital im- age forensics. InProc. 6th ACM MMSys, pp. 219–224, 2015
work page 2015
-
[18]
M. Bi ´nkowski, D. J. Sutherland, M. Arbel, and A. Gretton. Demystifying MMD GANs. InICLR, 2018
work page 2018
- [19]
-
[20]
S. Jayasumana, R. Hartley, M. Salzmann, H. Li, and M. Harandi. Kernel methods on the Riemannian mani- fold of symmetric positive definite matrices. InCVPR, 2013
work page 2013
-
[21]
A. Han, B. Mishra, P. Jawanpuria, and J. Gao. On Riemannian optimization over positive definite matri- ces with the Bures-Wasserstein geometry. InNeurIPS, 2021
work page 2021
-
[22]
Video Quality Experts Group (VQEG). Final report from the VQEG on the validation of objective mod- els of video quality assessment, phase II. Technical report, 2003
work page 2003
-
[23]
M. D. Zeiler and R. Fergus. Visualizing and under- standing convolutional networks. InECCV, 2014
work page 2014
-
[24]
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick. Microsoft COCO: Common objects in context. InECCV, 2014
work page 2014
-
[25]
M. G. Kendall. A new measure of rank correlation. Biometrika, 30(1/2):81–93, 1938
work page 1938
- [26]
- [27]
- [28]
-
[29]
M. Raghu, T. Unterthiner, S. Kornblith, C. Zhang, and A. Dosovitskiy. Do vision transformers see like con- volutional neural networks? InNeurIPS, 2021. 10 Appendix Table 2: 20 synthetic degradation types×10 severity levels applied to the MS-COCO anchor images. Linear interpolation: level 1→minimal parameter, level 10→maximal parameter. # KADID Nom Param. ...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.