Recognition: no theorem link
Emergent Compositional Communication for Latent World Properties
Pith reviewed 2026-05-15 08:23 UTC · model grok-4.3
The pith
Multi-agent interaction alone produces compositional codes for hidden physical properties from video.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Agents communicating through a Gumbel-Softmax bottleneck with iterated learning develop positionally disentangled protocols for latent properties without property labels or supervision on message structure, achieving PosDis=0.999 and holdout accuracy of 98.3 percent with four agents across all eighty seeds. Controls isolate the multi-agent structure as the driver rather than bandwidth or temporal coverage. Causal interventions confirm that targeted disruptions affect only the intended property, and the frozen protocols enable action-conditioned planning with counterfactual reasoning.
What carries the argument
The multi-agent iterated learning structure with a Gumbel-Softmax communication bottleneck that forces discrete messages from frozen video features.
Load-bearing premise
The multi-agent iterated learning structure itself, rather than bandwidth, temporal coverage, or other implementation details, is the primary driver of the observed compositionality.
What would settle it
A single-agent control with matched message bandwidth and iterated learning iterations reaching the same PosDis score of 0.999 would falsify the claim that the multi-agent structure is required.
Figures



read the original abstract
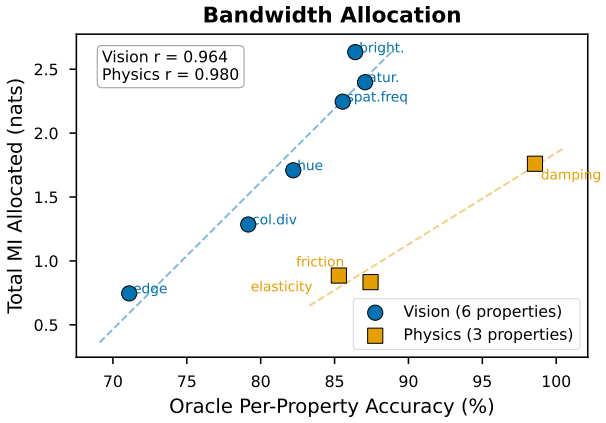
Can multi-agent communication pressure extract discrete, compositional representations of invisible physical properties from frozen video features? We show that agents communicating through a Gumbel-Softmax bottleneck with iterated learning develop positionally disentangled protocols for latent properties (elasticity, friction, mass ratio) without property labels or supervision on message structure. With 4 agents, 100% of 80 seeds converge to near-perfect compositionality (PosDis=0.999, holdout 98.3%). Controls confirm multi-agent structure -- not bandwidth or temporal coverage -- drives this effect. Causal intervention shows surgical property disruption (~15% drop on targeted property, <3% on others). A controlled backbone comparison reveals that the perceptual prior determines what is communicable: DINOv2 dominates on spatially-visible ramp physics (98.3% vs 95.1%), while V-JEPA 2 dominates on dynamics-only collision physics (87.4% vs 77.7%, d=2.74). Scale-matched (d=3.37) and frame-matched (d=6.53) controls attribute this gap entirely to video-native pretraining. The frozen protocol supports action-conditioned planning (91.5%) with counterfactual velocity reasoning (r=0.780). Validation on Physics 101 real camera footage confirms 85.6% mass-comparison accuracy on unseen objects, temporal dynamics contributing +11.2% beyond static appearance, agent-scaling compositionality replicating at 90% for 4 agents, and causal intervention extending to real video (d=1.87, p=0.022).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that multi-agent iterated learning with a Gumbel-Softmax communication bottleneck induces near-perfect compositional protocols for latent physical properties (elasticity, friction, mass ratio) from frozen video features, without any property labels or supervision on message structure. With 4 agents, 100% of 80 seeds converge to PosDis=0.999 and 98.3% holdout accuracy; controls attribute the effect to multi-agent structure rather than bandwidth or temporal coverage; causal interventions show property-specific disruption; backbone comparisons (DINOv2 vs V-JEPA 2) and real-video validation on Physics 101 footage (85.6% mass-comparison accuracy) further support the results, including action-conditioned planning.
Significance. If the results hold, the work demonstrates that communication pressure in a multi-agent iterated-learning regime can extract disentangled representations of invisible dynamics from perceptual features, with implications for unsupervised representation learning, emergent communication, and robotic planning. Strengths include the reported 100% seed convergence, use of causal interventions, explicit backbone ablations showing the role of video-native pretraining, and extension to real camera footage with temporal-dynamics gains.
major comments (2)
- Controls section: The claim that controls isolate multi-agent structure from bandwidth and temporal coverage is load-bearing for the central attribution of compositionality. However, the single-agent baseline protocol is not described in sufficient detail to confirm it employs the identical generational message-passing regime (discrete iterations with message inheritance and refinement). If the single-agent control instead uses a monolithic training loop, the comparison confounds multi-agent pressure with the iterated-learning dynamic itself, leaving open whether iteration alone suffices for the observed PosDis=0.999 and 98.3% holdout performance.
- Methods and Results sections: Full methodological details, error-bar reporting across the 80 seeds, and explicit data-exclusion criteria are missing for the convergence statistics, holdout evaluations, and causal-intervention drops (~15% targeted vs <3% others). These omissions prevent independent verification of the 100% convergence rate and the specificity of the interventions.
minor comments (2)
- The acronym PosDis and the precise definition of the positionally disentangled metric should be introduced and formalized in the main text at first use rather than assumed from the abstract.
- Figure captions for the backbone comparisons should explicitly state the effect sizes (d=2.74, d=3.37, d=6.53) and the statistical tests used to attribute gaps to video-native pretraining.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and have updated the manuscript accordingly to enhance clarity and reproducibility.
read point-by-point responses
-
Referee: Controls section: The claim that controls isolate multi-agent structure from bandwidth and temporal coverage is load-bearing for the central attribution of compositionality. However, the single-agent baseline protocol is not described in sufficient detail to confirm it employs the identical generational message-passing regime (discrete iterations with message inheritance and refinement). If the single-agent control instead uses a monolithic training loop, the comparison confounds multi-agent pressure with the iterated-learning dynamic itself, leaving open whether iteration alone suffices for the observed PosDis=0.999 and 98.3% holdout performance.
Authors: We agree that additional detail is needed for the single-agent baseline to confirm the fairness of the comparison. The single-agent control in our experiments does employ the identical generational message-passing regime, including discrete iterations with message inheritance and refinement across generations, but with a single agent per generation instead of four. To address this, we have revised the Methods section to include a full description of the single-agent protocol, along with pseudocode illustrating the generational process. This ensures that the control isolates the multi-agent interaction rather than the iterated-learning aspect. revision: yes
-
Referee: Methods and Results sections: Full methodological details, error-bar reporting across the 80 seeds, and explicit data-exclusion criteria are missing for the convergence statistics, holdout evaluations, and causal-intervention drops (~15% targeted vs <3% others). These omissions prevent independent verification of the 100% convergence rate and the specificity of the interventions.
Authors: We acknowledge that the original submission lacked sufficient detail in these areas. In the revised version, we have expanded the Methods section with complete methodological details, including all hyperparameters, training procedures, and data handling steps. We now report mean and standard deviation (error bars) across all 80 seeds for convergence statistics, PosDis, holdout accuracy, and intervention effects. No data were excluded; all seeds are included in the reported figures. For causal interventions, we provide per-property drop statistics with full distributions to demonstrate specificity. revision: yes
Circularity Check
No circularity: empirical claims rest on measured controls and interventions
full rationale
The paper reports experimental outcomes from multi-agent iterated learning with Gumbel-Softmax communication, quantifying compositionality via directly computed metrics (PosDis=0.999, holdout 98.3%) across 80 seeds and 4 agents. Controls are described as isolating multi-agent structure from bandwidth and temporal coverage, with additional causal interventions and backbone comparisons (DINOv2 vs V-JEPA) presented as falsifiable measurements rather than derivations. No equations or self-citations reduce the central result to a fitted parameter or prior ansatz by construction; the reported convergence and planning accuracies are external to the training loss and are validated on held-out data and real footage. The derivation chain is therefore self-contained in its experimental design.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Gumbel-Softmax provides a differentiable relaxation of discrete categorical sampling suitable for end-to-end training
Reference graph
Works this paper leans on
-
[1]
Andreas, J. (2019). Measuring compositionality in representation learning.ICLR
work page 2019
-
[2]
Assran, M., et al. (2025). V-JEPA 2: Self-supervised video models enable understanding, prediction and planning.arXiv:2506.09985
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Baradel, F., Neverova, N., Mille, J., Mori, G., & Wolf, C. (2020). CoPhy: Counterfactual learning of physical dynamics.ICLR
work page 2020
-
[4]
Battaglia, P., Hamrick, J., & Tenenbaum, J. (2013). Simulation as an engine of physical scene understanding. PNAS, 110(45), 18327–18332
work page 2013
-
[5]
Bear, D., etal.(2021).Physion: Evaluatingphysicalpredictionfromvisioninhumansandmachines.NeurIPS Datasets and Benchmarks
work page 2021
-
[6]
Brighton, H. & Kirby, S. (2006). Understanding linguistic evolution by visualizing the emergence of topo- graphic mappings.Artificial Life, 12(2), 229–242
work page 2006
-
[7]
Chaabouni, R., Kharitonov, E., Bouchacourt, D., Dupoux, E., & Baroni, M. (2020). Compositionality and generalization in emergent languages.ACL
work page 2020
-
[8]
Choi, E., Lazaridou, A., & de Freitas, N. (2018). Compositional obverter communication learning from raw visual input.ICLR
work page 2018
-
[9]
Cover, T. M. & Thomas, J. A. (2006).Elements of Information Theory. Wiley-Interscience, 2nd edition
work page 2006
-
[10]
Das, A., Gervet, T., Romoff, J., Batra, D., Parikh, D., Rabbat, M., & Pineau, J. (2019). TarMAC: Targeted multi-agent communication.ICML. 20
work page 2019
- [11]
-
[12]
Greff, K., et al. (2022). Kubric: A scalable dataset generator.CVPR
work page 2022
-
[13]
Havrylov, S. & Titov, I. (2017). Emergence of language with multi-agent games: Learning to communicate with sequences of symbols.NeurIPS
work page 2017
-
[14]
Jang, E., Gu, S., & Poole, B. (2017). Categorical reparameterization with Gumbel-Softmax.ICLR
work page 2017
-
[15]
Kharitonov, E. & Baroni, M. (2020). Emergent language generalization and acquisition speed are not tied to compositionality.arXiv:2004.03420
-
[16]
Kirby, S., Griffiths, T., & Smith, K. (2014). Iterated learning and the evolution of language.Current Opinion in Neurobiology, 28, 108–114
work page 2014
-
[17]
Kottur, S., Moura, J., Lee, S., & Batra, D. (2017). Natural language does not emerge ‘naturally’ in multi- agent dialog.EMNLP
work page 2017
-
[18]
Lazaridou, A., Peysakhovich, A., & Baroni, M. (2017). Multi-agent cooperation and the emergence of (nat- ural) language.ICLR
work page 2017
-
[19]
Lazaridou, A. & Baroni, M. (2020). Emergent multi-agent communication in the deep learning era. arXiv:2006.02419
-
[20]
Li, F. & Bowling, M. (2019). Ease-of-teaching and language structure from emergent communication. NeurIPS
work page 2019
-
[21]
LeCun, Y. (2022). A path towards autonomous machine intelligence.Technical report, Courant Institute of Mathematical Sciences, NYU & Meta AI
work page 2022
-
[22]
Mordatch, I. & Abbeel, P. (2018). Emergence of grounded compositional language in multi-agent populations. AAAI
work page 2018
-
[23]
Rita, M., Strub, F., Grill, J.-B., Pietquin, O., & Dupoux, E. (2020). “LazImpa”: Lazy and impatient neural agents learn to communicate efficiently.CoNLL
work page 2020
-
[24]
Oquab, M., et al. (2023). DINOv2: Learning robust visual features without supervision.arXiv:2304.07193
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Piloto, L., et al. (2022). Intuitive physics learning in a deep-learning model inspired by developmental psychology.Nature Human Behaviour, 6(9), 1257–1267
work page 2022
-
[26]
Ren, Y., et al. (2020). Compositional languages emerge in a neural iterated learning model.ICLR
work page 2020
-
[27]
Y., Bernard, M., Lerer, A., Fergus, R., Izard, V., & Dupoux, E
Riochet, R., Castro, M. Y., Bernard, M., Lerer, A., Fergus, R., Izard, V., & Dupoux, E. (2022). IntPhys 2019: A benchmark for visual intuitive physics understanding.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(9), 5016–5025
work page 2022
-
[28]
Rita, M., Strub, F., Grill, J.-B., Pietquin, O., & Dupoux, E. (2022). On the role of population heterogeneity in emergent communication.ICLR
work page 2022
- [29]
-
[30]
Wu, J., Yildirim, I., Lim, J. J., Freeman, W. T., & Tenenbaum, J. B. (2016). Physics 101: Learning physical object properties from unlabeled videos.BMVC
work page 2016
-
[31]
Wu, J., Lu, E., Kohli, P., Freeman, B., & Tenenbaum, J. (2017). Learning to see physics via visual de- animation.NeurIPS
work page 2017
-
[32]
Ye, T., et al. (2018). Interpretable intuitive physics model.ECCV. 21 A Hyperparameters Table 13: Hyperparameters used across all experiments unless otherwise noted. Hyperparameter Value DINOv2 model ViT-S/14 (frozen) V-JEPA 2 model ViT-L/16 (frozen) Frames per scene (ramp) 8 (evenly spaced from 24) Frames per scene (collision) 24 (evenly spaced from 48) ...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.