DRIFT: Deep Restoration, ISP Fusion, and Tone-mapping
Pith reviewed 2026-05-13 18:13 UTC · model grok-4.3
The pith
DRIFT uses a multi-frame neural network and tunable tone-mapping to create high-quality RGB images from raw smartphone captures efficiently.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
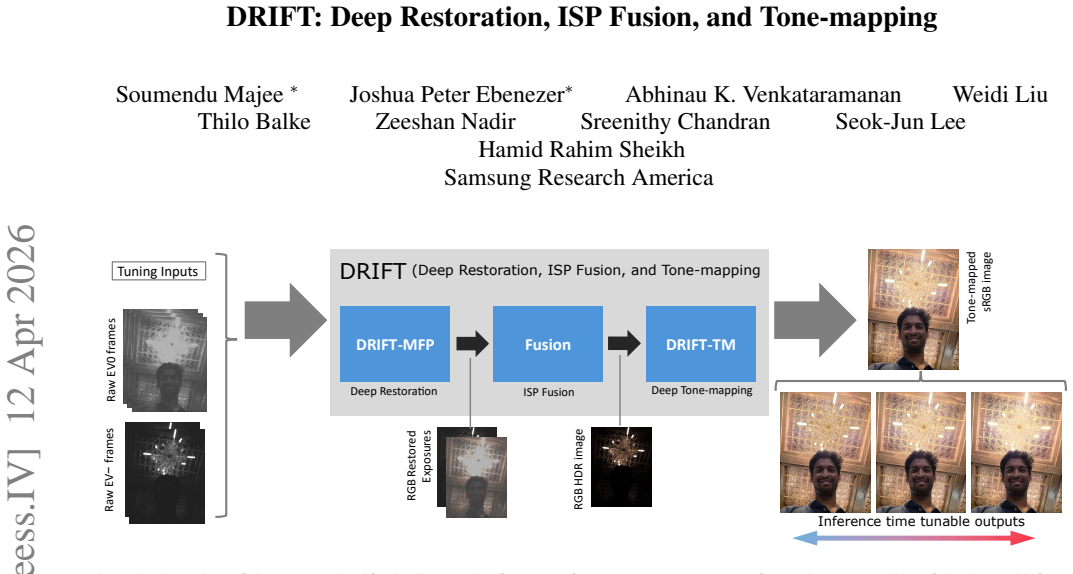
DRIFT is an efficient AI mobile camera pipeline with a Multi-Frame Processing network that uses adversarial perceptual loss for multi-frame alignment, denoising, demosaicing, and super-resolution, followed by a deep-learning tone-mapping solution that provides tunability and reference consistency.
What carries the argument
The Multi-Frame Processing (MFP) network trained with adversarial perceptual loss, followed by the DRIFT-TM tone-mapping network.
If this is right
- High-resolution images can be generated from raw captures on mobile devices with reduced computational cost.
- The tone-mapping allows adjustments while maintaining consistency across different scenes.
- Performance exceeds state-of-the-art methods in both qualitative and quantitative evaluations for restoration tasks.
- Overall pipeline enables better handling of high-dynamic range imaging in smartphones.
Where Pith is reading between the lines
- If the method generalizes well, it could replace parts of traditional ISP hardware with learned models.
- Extensions might include applying similar fusion to video sequences for temporal consistency.
- Testing across multiple device models would reveal if tone consistency holds universally.
Load-bearing premise
That the networks trained on the authors' data and loss will perform well on arbitrary real-world handheld raw captures without losing tone consistency with the reference across all scenes and devices.
What would settle it
Running DRIFT on raw captures from a new smartphone model or challenging lighting condition and observing if the output matches or exceeds the reference pipeline in visual quality and tone.
Figures










read the original abstract
Smartphone cameras have gained immense popularity with the adoption of high-resolution and high-dynamic range imaging. As a result, high-performance camera Image Signal Processors (ISPs) are crucial in generating high-quality images for the end user while keeping computational costs low. In this paper, we propose DRIFT (Deep Restoration, ISP Fusion, and Tone-mapping): an efficient AI mobile camera pipeline that generates high quality RGB images from hand-held raw captures. The first stage of DRIFT is a Multi-Frame Processing (MFP) network that is trained using a adversarial perceptual loss to perform multi-frame alignment, denoising, demosaicing, and super-resolution. Then, the output of DRIFT-MFP is processed by a novel deep-learning based tone-mapping (DRIFT-TM) solution that allows for tone tunability, ensures tone-consistency with a reference pipeline, and can be run efficiently for high-resolution images on a mobile device. We show qualitative and quantitative comparisons against state-of-the-art MFP and tone-mapping methods to demonstrate the effectiveness of our approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DRIFT, an efficient AI mobile camera pipeline that generates high-quality RGB images from handheld raw captures. It consists of a Multi-Frame Processing (MFP) network trained with adversarial perceptual loss to perform multi-frame alignment, denoising, demosaicing, and super-resolution, followed by a novel deep tone-mapping module (DRIFT-TM) that provides tone tunability, reference-pipeline consistency, and mobile efficiency for high-resolution images. Qualitative and quantitative comparisons against state-of-the-art MFP and tone-mapping methods are presented to demonstrate effectiveness.
Significance. If the central claims hold with proper experimental validation, DRIFT could offer a practical integrated deep-learning solution for smartphone ISPs, combining restoration tasks in a single efficient network while maintaining tone consistency and tunability, which would be valuable for real-world mobile imaging applications.
major comments (2)
- [Abstract] Abstract: the claim of quantitative superiority is asserted without any reported metrics, datasets, error bars, ablation results, or cross-device evaluations, leaving the central claim of effectiveness and generalization unsupported by evidence in the manuscript description.
- [Abstract] Abstract: the assumption that a single MFP network trained on unspecified handheld raw data with adversarial perceptual loss will generalize to arbitrary real-world captures (varying sensors, motion, and ISP differences) while DRIFT-TM preserves tone consistency is load-bearing but lacks supporting cross-device test sets or quantitative tone-deviation measures.
minor comments (1)
- Define all acronyms (e.g., MFP, ISP, DRIFT-TM) on first use and ensure consistent notation throughout the full manuscript.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We agree that the abstract requires strengthening with concrete evidence and have revised it accordingly. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of quantitative superiority is asserted without any reported metrics, datasets, error bars, ablation results, or cross-device evaluations, leaving the central claim of effectiveness and generalization unsupported by evidence in the manuscript description.
Authors: We agree that the abstract should include specific quantitative support. In the revised version we have updated the abstract to report key metrics (PSNR, SSIM, LPIPS) from the MFP and tone-mapping comparisons, name the primary evaluation datasets, and reference the ablation studies and error-bar analysis that appear in Sections 4.2–4.3. Full cross-device results and additional ablations are retained in the main text and supplementary material. revision: yes
-
Referee: [Abstract] Abstract: the assumption that a single MFP network trained on unspecified handheld raw data with adversarial perceptual loss will generalize to arbitrary real-world captures (varying sensors, motion, and ISP differences) while DRIFT-TM preserves tone consistency is load-bearing but lacks supporting cross-device test sets or quantitative tone-deviation measures.
Authors: Section 3.1 describes the training set as multi-device handheld raw bursts collected from several smartphone sensors under varied motion and lighting. Generalization is quantified on held-out test bursts exhibiting different motion magnitudes and dynamic ranges; DRIFT-TM tone consistency is measured via mean ΔE and histogram-correlation scores against the reference pipeline (Table 3). We acknowledge that exhaustive coverage of every sensor/ISP combination is impractical. The revised manuscript adds results from one additional unseen device and a limitations paragraph discussing remaining generalization gaps. revision: partial
Circularity Check
No circularity: standard supervised training on external data with no self-referential reductions
full rationale
The paper describes a two-stage pipeline (MFP network trained via adversarial perceptual loss for alignment/denoising/demosaicing/super-resolution, followed by DRIFT-TM for tunable tone-mapping). No equations, derivations, or fitted parameters are presented that reduce to the inputs by construction. Training is described as occurring on external handheld raw data with standard losses; no self-citation chains, uniqueness theorems, or ansatzes are invoked to justify the central claims. Generalization concerns exist but are unrelated to circularity. The derivation chain is self-contained and non-circular.
Axiom & Free-Parameter Ledger
free parameters (2)
- adversarial loss weight
- network hyperparameters
axioms (1)
- domain assumption Adversarial perceptual loss produces images preferred by human viewers
invented entities (2)
-
DRIFT-MFP
no independent evidence
-
DRIFT-TM
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josue Anaya and Adrian Barbu. Renoir – a dataset for real low-light image noise reduction.Journal of Visual Commu- nication and Image Representation, 51:144–154, 2018. 4
work page 2018
-
[2]
Goutam Bhat, Martin Danelljan, Luc Van Gool, and Radu Timofte. Deep burst super-resolution. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9209–9218, 2021. 4
work page 2021
-
[3]
Peter J Burt and Edward H Adelson. A multiresolution spline with application to image mosaics.ACM Transactions on Graphics (ToG), 2(4):217–236, 1983. 4
work page 1983
-
[4]
Xim Cerda-Company, C Alejandro Parraga, and Xavier Otazu. Which tone-mapping operator is the best? a com- parative study of perceptual quality.Journal of the Optical Society of America A, 35(4):626–638, 2018. 3
work page 2018
-
[5]
Simple Baselines for Image Restoration
Liangyu Chen, Xiaojie Chu, Xiangyu Zhang, and Jian Sun. Simple Baselines for Image Restoration. InComputer Vision – ECCV 2022, pages 17–33. Springer Nature Switzerland, Cham, 2022. Series Title: Lecture Notes in Computer Sci- ence. 2, 3
work page 2022
-
[6]
Ntire 2025 challenge on raw im- age restoration and super-resolution
Marcos Conde et al. Ntire 2025 challenge on raw im- age restoration and super-resolution. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1148–1171, 2025. 2, 3
work page 2025
-
[7]
Mobile computational photography: A tour.Annual review of vision science, 7(1):571–604, 2021
Mauricio Delbracio, Damien Kelly, Michael S Brown, and Peyman Milanfar. Mobile computational photography: A tour.Annual review of vision science, 7(1):571–604, 2021. 1, 3
work page 2021
-
[8]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. 2
work page 2009
-
[9]
Burst image restoration and enhancement
Akshay Dudhane, Syed Waqas Zamir, Salman Khan, Fa- had Shahbaz Khan, and Ming-Hsuan Yang. Burst image restoration and enhancement. InProceedings of the ieee/cvf Conference on Computer Vision and Pattern Recognition, pages 5759–5768, 2022. 2, 6
work page 2022
-
[10]
Burstormer: Burst image restoration and enhancement transformer
Akshay Dudhane, Syed Waqas Zamir, Salman Khan, Fa- had Shahbaz Khan, and Ming-Hsuan Yang. Burstormer: Burst image restoration and enhancement transformer. In 2023 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 5703–5712. IEEE, 2023. 2, 6
work page 2023
-
[11]
Ntire 2025 challenge on night photogra- phy rendering
Egor Ershov et al. Ntire 2025 challenge on night photogra- phy rendering. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 1505–1515, 2025. 3
work page 2025
-
[12]
Martin A Fischler and Robert C Bolles. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.Communications of the ACM, 24(6):381–395, 1981. 4
work page 1981
-
[13]
Edge-aware deep image deblurring
Zhichao Fu, Yingbin Zheng, Tianlong Ma, Hao Ye, Jing Yang, and Liang He. Edge-aware deep image deblurring. Neurocomputing, 502:37–47, 2022. 3
work page 2022
-
[14]
Eduardo S. L. Gastal and Manuel M. Oliveira. Domain transform for edge-aware image and video processing.ACM Trans. Graph., 30(4), 2011. 3
work page 2011
- [15]
-
[16]
Generative adversarial nets.Advances in neural information processing systems, 27, 2014
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Advances in neural information processing systems, 27, 2014. 2
work page 2014
-
[17]
Cheng Guo and Xiuhua Jiang. Deep tone-mapping opera- tor using image quality assessment inspired semi-supervised learning.IEEE Access, 9:73873–73889, 2021. 3, 7
work page 2021
-
[18]
Image-to-image translation with conditional adver- sarial networks
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adver- sarial networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1125–1134,
-
[19]
Perceptual losses for real-time style transfer and super-resolution
Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In European conference on computer vision, pages 694–711. Springer, 2016. 2
work page 2016
-
[20]
Mfsr-gan: Multi-frame super-resolution with handheld motion modeling
Fadeel Sher Khan, Joshua Ebenezer, Hamid Sheikh, and Seok-Jun Lee. Mfsr-gan: Multi-frame super-resolution with handheld motion modeling. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 800–809,
-
[21]
Convolutional neural net- works considering local and global features for image en- hancement
Yuma Kinoshita and Hitoshi Kiya. Convolutional neural net- works considering local and global features for image en- hancement. In2019 IEEE International Conference on Im- age Processing (ICIP), pages 2110–2114. IEEE, 2019. 3
work page 2019
-
[22]
Artifact generation when using perceptual loss for image deblurring.TechRxiv, 2023
Patrick Krawczyk, Marvin Gaertner, Andreas Jansche, Timo Bernthaler, and Gerhard Schneider. Artifact generation when using perceptual loss for image deblurring.TechRxiv, 2023. 3
work page 2023
-
[23]
Ntire 2025 challenge on efficient burst hdr and restoration: Datasets, methods, and results
Sangmin Lee et al. Ntire 2025 challenge on efficient burst hdr and restoration: Datasets, methods, and results. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 1002–1017, 2025. 2
work page 2025
-
[24]
Hy- brid synthesis for exposure fusion from hand-held camera inputs
Ru Li, Shuaicheng Liu, Guanghui Liu, and Bing Zeng. Hy- brid synthesis for exposure fusion from hand-held camera inputs. In2019 IEEE International Conference on Image Processing (ICIP), pages 4639–4643. IEEE, 2019. 5
work page 2019
-
[25]
Kede Ma, Hojatollah Yeganeh, Kai Zeng, and Zhou Wang. High dynamic range image compression by optimizing tone mapped image quality index.IEEE Transactions on Image Processing, 24(10):3086–3097, 2015. 2, 3
work page 2015
-
[26]
Mobile aware denoiser net- work (madnet) for quad bayer images
Pavan C Madhusudana, Jing Li, Zeeshan Nadir, Hamid R Sheikh, and Seok-Jun Lee. Mobile aware denoiser net- work (madnet) for quad bayer images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 44–52, 2024. 4
work page 2024
-
[27]
Display adaptive tone mapping.ACM Trans
Rafał Mantiuk, Scott Daly, and Louis Kerofsky. Display adaptive tone mapping.ACM Trans. Graph., 27(3):1–10,
-
[28]
Tom Mertens, Jan Kautz, and Frank Van Reeth. Exposure fusion. In15th Pacific Conference on Computer Graphics and Applications (PG’07), pages 382–390. IEEE, 2007. 3, 5
work page 2007
-
[29]
Exposure fusion: A simple and practical alternative to high dynamic range photography
Tom Mertens, Jan Kautz, and Frank Van Reeth. Exposure fusion: A simple and practical alternative to high dynamic range photography. InComputer graphics forum, pages 161–
-
[30]
Wiley Online Library, 2009. 4 9
work page 2009
-
[31]
Josselin Petit and Rafał K Mantiuk. Assessment of video tone-mapping: Are cameras’ s-shaped tone-curves good enough?Journal of Visual Communication and Image Rep- resentation, 24(7):1020–1030, 2013. 3
work page 2013
-
[32]
Gustav Grund Pihlgren, Konstantina Nikolaidou, Prakash Chandra Chhipa, Nosheen Abid, Rajkumar Saini, Fredrik Sandin, and Marcus Liwicki. A systematic performance analysis of deep perceptual loss networks: Breaking transfer learning conventions.arXiv preprint arXiv:2302.04032, 2023. 3
-
[33]
Nikolay Ponomarenko, Lina Jin, Oleg Ieremeiev, Vladimir Lukin, Karen Egiazarian, Jaakko Astola, Benoit V ozel, Kacem Chehdi, Marco Carli, Federica Battisti, and C.-C. Jay Kuo. Image database TID2013: Peculiarities, results and perspectives.Signal Processing: Image Communication, 30: 57–77, 2015. 4
work page 2015
-
[34]
Qualcomm. Qualcomm AI Runtime SDK. https : / / docs . qualcomm . com / bundle / publicresource / topics / 80 - 63442 - 10 / SNPE _ general _ revision _ history . html,,
-
[35]
Accessed: 2025-11-13. 4
work page 2025
-
[36]
Aakanksha Rana, Praveer Singh, Giuseppe Valenzise, Fred- eric Dufaux, Nikos Komodakis, and Aljosa Smolic. Deep tone mapping operator for high dynamic range images.IEEE Transactions on Image Processing, 29:1285–1298, 2019. 3
work page 2019
-
[37]
Erik Reinhard. High dynamic range imaging. InComputer Vision: A Reference Guide, pages 558–563. Springer, 2021. 3
work page 2021
-
[38]
Improved techniques for training gans.Advances in neural information processing systems, 29, 2016
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans.Advances in neural information processing systems, 29, 2016. 3, 4
work page 2016
-
[39]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convo- lutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556, 2014. 2
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[40]
Multi-frame image denoising and stabilization
Marius Tico. Multi-frame image denoising and stabilization. In2008 16th European Signal Processing Conference, pages 1–4. IEEE, 2008. 2
work page 2008
-
[41]
Learning a self-supervised tone mapping operator via feature contrast masking loss
Chao Wang, Bin Chen, Hans-Peter Seidel, Karol Myszkowski, and Ana Serrano. Learning a self-supervised tone mapping operator via feature contrast masking loss. InComputer Graphics Forum, pages 71–84. Wiley Online Library, 2022. 3, 7
work page 2022
-
[42]
High-resolution image syn- thesis and semantic manipulation with conditional gans
Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. High-resolution image syn- thesis and semantic manipulation with conditional gans. In 2018 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 8798–8807, 2018. 3, 4
work page 2018
-
[43]
Esrgan: En- hanced super-resolution generative adversarial networks
Xintao Wang, Ke Yu, Shixiang Wu, Jinjin Gu, Yihao Liu, Chao Dong, Yu Qiao, and Chen Change Loy. Esrgan: En- hanced super-resolution generative adversarial networks. In Proceedings of the European conference on computer vision (ECCV) workshops, pages 0–0, 2018. 4
work page 2018
-
[44]
Towards real- world burst image super-resolution: Benchmark and method
Pengxu Wei, Yujing Sun, Xingbei Guo, Chang Liu, Guanbin Li, Jie Chen, Xiangyang Ji, and Liang Lin. Towards real- world burst image super-resolution: Benchmark and method. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13233–13242, 2023. 6
work page 2023
-
[45]
Handheld multi-frame super- resolution.ACM Transactions on Graphics (ToG), 38(4):1– 18, 2019
Bartlomiej Wronski, Ignacio Garcia-Dorado, Manfred Ernst, Damien Kelly, Michael Krainin, Chia-Kai Liang, Marc Levoy, and Peyman Milanfar. Handheld multi-frame super- resolution.ACM Transactions on Graphics (ToG), 38(4):1– 18, 2019. 1, 2
work page 2019
-
[46]
Multi-Exposure Image Fusion Techniques: A Com- prehensive Review.Remote Sensing, 14(3):771, 2022
Fang Xu, Jinghong Liu, Yueming Song, Hui Sun, and Xuan Wang. Multi-Exposure Image Fusion Techniques: A Com- prehensive Review.Remote Sensing, 14(3):771, 2022. Num- ber: 3 Publisher: Multidisciplinary Digital Publishing Insti- tute. 4
work page 2022
-
[47]
Qirui Yang, Yinbo Li, Yihao Liu, Peng-Tao Jiang, Fangpu Zhang, Qihua Cheng, Huanjing Yue, and Jingyu Yang. Learning differential pyramid representation for tone map- ping.arXiv preprint arXiv:2412.01463, 2024. 3
-
[48]
Xuejie Yang, Huamiao Zheng, and Yonggang Su. High dy- namic range image tone mapping based on variational image decomposition and color correction.Optics & Laser Tech- nology, 181:111873, 2025. 5
work page 2025
-
[49]
Hojatollah Yeganeh and Zhou Wang. Objective quality as- sessment of tone-mapped images.IEEE Transactions on Im- age Processing, 22(2):657–667, 2013. 7
work page 2013
-
[50]
Multi-stage progressive image restoration
Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, Ming-Hsuan Yang, and Ling Shao. Multi-stage progressive image restoration. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14821–14831, 2021. 6
work page 2021
-
[51]
Restormer: Efficient transformer for high-resolution image restoration
Syed Waqas Zamir, Aditya Arora, Salman Khan, Mu- nawar Hayat, Fahad Shahbaz Khan, and Ming-Hsuan Yang. Restormer: Efficient transformer for high-resolution image restoration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5728–5739, 2022. 2, 6
work page 2022
-
[52]
Feng Zhang, Ming Tian, Zhiqiang Li, Bin Xu, Qingbo Lu, Changxin Gao, and Nong Sang. Lookup table meets lo- cal laplacian filter: pyramid reconstruction network for tone mapping.Advances in Neural Information Processing Sys- tems, 36:57558–57569, 2023. 3
work page 2023
-
[53]
Feng Zhang, Haoyou Deng, Zhiqiang Li, Lida Li, Bin Xu, Qingbo Lu, Zisheng Cao, Minchen Wei, Changxin Gao, Nong Sang, et al. High-resolution photo enhancement in real-time: A laplacian pyramid network.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. 3, 8
work page 2025
-
[54]
A generative adversarial network based tone mapping operator for 4k hdr images
Junbin Zhang, Yixiao Wang, Hamidreza Tohidypour, Mahsa T Pourazad, and Panos Nasiopoulos. A generative adversarial network based tone mapping operator for 4k hdr images. In2023 international conference on computing, networking and communications (ICNC), pages 473–477. IEEE, 2023. 3, 7, 8
work page 2023
-
[55]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 586–595, 2018. 3 10
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.