Multimodal Urban Tree Detection from Satellite and Street-Level Imagery via Annotation-Efficient Deep Learning Strategies
Pith reviewed 2026-05-13 19:28 UTC · model grok-4.3
The pith
Hybrid learning on satellite and street-level images detects urban trees at 0.90 F1-score with a 12 percent gain over baseline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
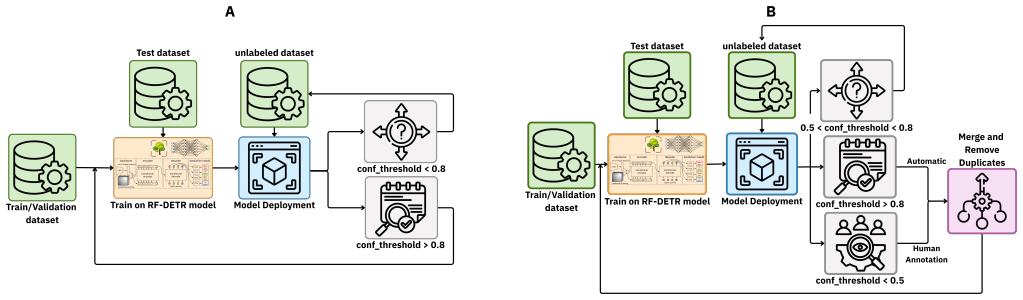
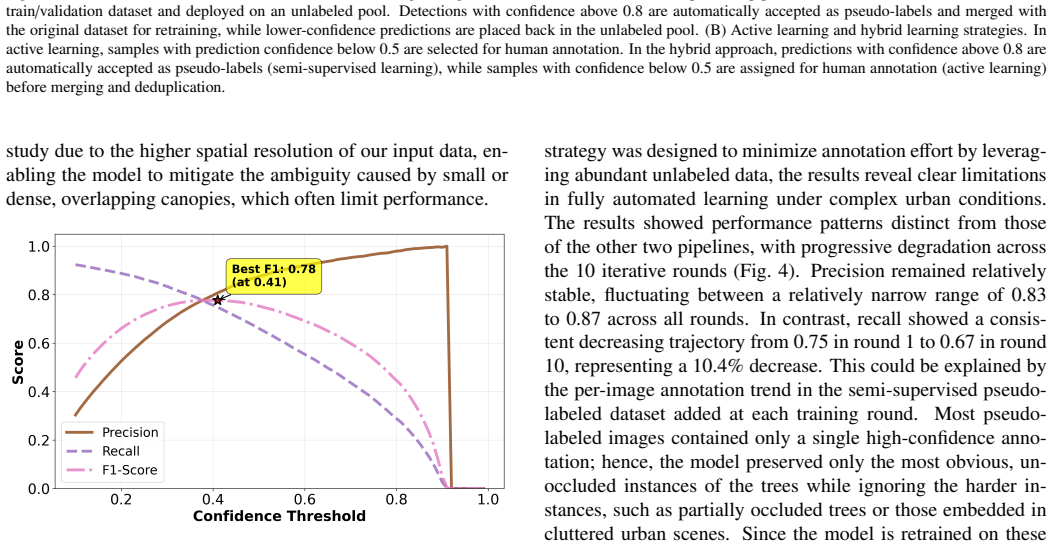
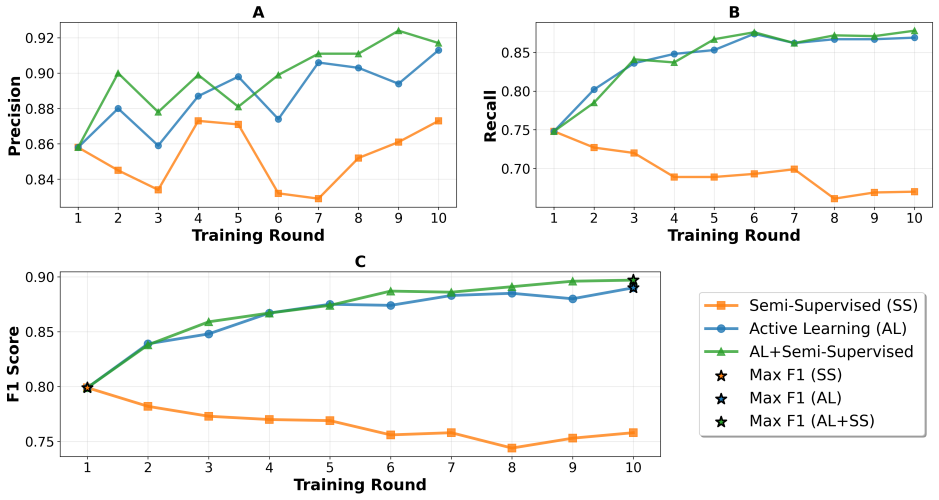
The authors demonstrate that a multimodal pipeline combining satellite imagery for tree candidate localization with ground-level Google Street View images, domain adaptation to transfer knowledge from a source dataset, and a hybrid semi-supervised plus active learning strategy on a transformer-based model achieves an F1-score of 0.90. This result improves 12 percent over the baseline, while pure semi-supervised learning degrades due to confirmation bias and active learning improves steadily through focused human labeling of uncertain cases.
What carries the argument
Multimodal candidate localization from satellite imagery followed by targeted street-view verification, powered by domain adaptation and a hybrid active-semi-supervised learning loop on a transformer detector.
Load-bearing premise
Domain adaptation successfully bridges the gap between the source annotated dataset and the target region without introducing significant biases or performance drops.
What would settle it
Running the hybrid model on a new urban region with no further active-learning labels and measuring whether the F1-score stays at or above 0.90 or falls below the original baseline.
Figures

read the original abstract
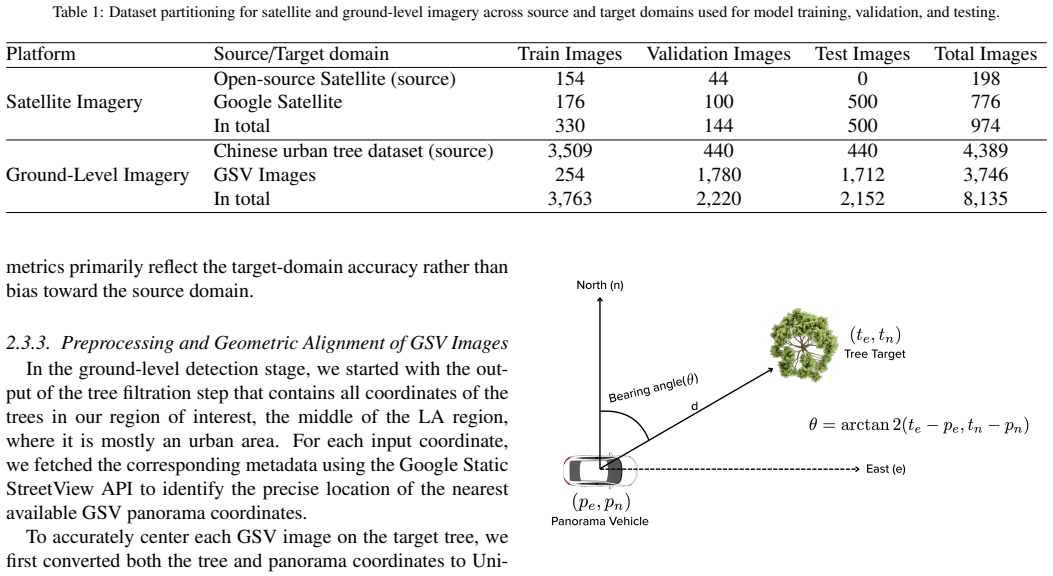
Beyond the immediate biophysical benefits, urban trees play a foundational role in environmental sustainability and disaster mitigation. Precise mapping of urban trees is essential for environmental monitoring, post-disaster assessment, and strengthening policy. However, the transition from traditional, labor-intensive field surveys to scalable automated systems remains limited by high annotation costs and poor generalization across diverse urban scenarios. This study introduces a multimodal framework that integrates high-resolution satellite imagery with ground-level Google Street View to enable scalable and detailed urban tree detection under limited-annotation conditions. The framework first leverages satellite imagery to localize tree candidates and then retrieves targeted ground-level views for detailed detection, significantly reducing inefficient street-level sampling. To address the annotation bottleneck, domain adaptation is used to transfer knowledge from an existing annotated dataset to a new region of interest. To further minimize human effort, we evaluated three learning strategies: semi-supervised learning, active learning, and a hybrid approach combining both, using a transformer-based detection model. The hybrid strategy achieved the best performance with an F1-score of 0.90, representing a 12% improvement over the baseline model. In contrast, semi-supervised learning exhibited progressive performance degradation due to confirmation bias in pseudo-labeling, while active learning steadily improved results through targeted human intervention to label uncertain or incorrect predictions. Error analysis further showed that active and hybrid strategies reduced both false positives and false negatives. Our findings highlight the importance of a multimodal approach and guided annotation for scalable, annotation-efficient urban tree mapping to strengthen sustainable city planning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a multimodal framework for urban tree detection that first uses high-resolution satellite imagery to localize candidate trees and then retrieves targeted Google Street View images for detailed classification. Domain adaptation transfers knowledge from an existing annotated source dataset to a new target region, while three annotation-efficient strategies (semi-supervised learning, active learning, and their hybrid) are evaluated with a transformer-based detector. The central empirical claim is that the hybrid strategy attains an F1-score of 0.90, a 12% improvement over the baseline, accompanied by reduced false positives and negatives.
Significance. If the reported gains are shown to be robust and directly attributable to the hybrid strategy, the work would provide a practical, scalable route to annotation-light urban tree mapping with clear relevance to environmental monitoring, disaster assessment, and sustainable city planning. The multimodal fusion and guided annotation components address real deployment bottlenecks in remote-sensing computer vision.
major comments (2)
- [Abstract and Results] Abstract and Results section: The headline claim of F1 = 0.90 with a 12% improvement is presented without the numerical baseline F1 value, without the number of experimental runs or standard deviations, and without any statistical significance test (e.g., paired t-test p-value). These omissions prevent verification that the observed gain is reliable and attributable to the hybrid strategy rather than to unstated experimental choices.
- [Methods and Results] Methods and Results sections: No quantitative evidence is supplied for the success of domain adaptation (e.g., before/after F1 on the target domain, maximum mean discrepancy, or pseudo-label accuracy on held-out target samples). Without such diagnostics or an ablation that isolates the adaptation step from the semi-supervised and active-learning components, the central attribution of performance gains to the proposed hybrid pipeline cannot be substantiated.
minor comments (2)
- [Abstract] The abstract states that semi-supervised learning exhibited 'progressive performance degradation' but supplies no iteration-wise F1 curve or confirmation-bias metric to quantify the effect.
- [Results] Error-analysis discussion would be strengthened by a table or figure that directly compares false-positive and false-negative rates across all four conditions (baseline, semi-supervised, active, hybrid).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and will revise the manuscript to strengthen the reporting of results and the substantiation of the domain adaptation component.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and Results section: The headline claim of F1 = 0.90 with a 12% improvement is presented without the numerical baseline F1 value, without the number of experimental runs or standard deviations, and without any statistical significance test (e.g., paired t-test p-value). These omissions prevent verification that the observed gain is reliable and attributable to the hybrid strategy rather than to unstated experimental choices.
Authors: We agree that the current presentation lacks sufficient detail for independent verification. In the revised manuscript we will explicitly state the numerical baseline F1 value, report results averaged over multiple independent runs with standard deviations, and include a paired t-test (or equivalent) with p-value to confirm that the observed improvement is statistically significant and attributable to the hybrid strategy rather than experimental variability. revision: yes
-
Referee: [Methods and Results] Methods and Results sections: No quantitative evidence is supplied for the success of domain adaptation (e.g., before/after F1 on the target domain, maximum mean discrepancy, or pseudo-label accuracy on held-out target samples). Without such diagnostics or an ablation that isolates the adaptation step from the semi-supervised and active-learning components, the central attribution of performance gains to the proposed hybrid pipeline cannot be substantiated.
Authors: We acknowledge the value of explicit diagnostics for the domain adaptation step. We will add before/after F1 scores on the target domain and include a dedicated ablation study that isolates the contribution of domain adaptation from the semi-supervised and active-learning components. These additions will be placed in the Methods and Results sections to directly substantiate the attribution of gains to the overall hybrid pipeline. revision: yes
Circularity Check
No circularity; claims rest on direct empirical evaluation
full rationale
The paper reports experimental F1-scores (hybrid strategy reaching 0.90, +12% over baseline) obtained from applying domain adaptation, semi-supervised learning, active learning, and a hybrid combination to a transformer-based detector on satellite and Street View imagery. No equations, parameter fits, or predictions are presented that reduce to the inputs by construction; performance numbers are measured outcomes on held-out data rather than self-definitional or self-cited derivations. No load-bearing self-citations or uniqueness theorems are invoked to justify core results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Domain adaptation can effectively transfer knowledge from an existing annotated dataset to a new region of interest
Reference graph
Works this paper leans on
-
[1]
12 Maas, J., van Dillen, S.M., Verheij, R.A., Groenewegen, P.P.,
doi:10.1016/J.ISPRSJPRS.2021.01.016. 12 Maas, J., van Dillen, S.M., Verheij, R.A., Groenewegen, P.P.,
-
[2]
Social contacts as a possible mechanism behind the relation between green space and health. Health & Place 15, 586–595. doi:10.1016/J.HEALTHPLACE.2008.09.006. Morgenroth, J., Doick, K., Hauer, R., Locke, D.H., Barona, C.O., Roman, L.A., Conway, T.M., Dobbs, C., Duinker, P., Gulsrud, N.M., Jim, C.Y ., Koeser, A.K., Landry, S., Livesley, S., Nesbitt, L., Sh...
-
[3]
Cataloging public objects using aerial and street-level images — urban trees, in: 2016 IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR), pp. 6014–
work page 2016
-
[4]
Xie, Q., Luong, M.T., Hovy, E., Le, Q.V ., 2020
doi:10.1109/CVPR.2016.647. Xie, Q., Luong, M.T., Hovy, E., Le, Q.V ., 2020. Self- training with noisy student improves imagenet classification, in: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 10684–10695. doi:10. 1109/CVPR42600.2020.01070. Yang, T., Zhou, S., Huang, Z., Xu, A., Ye, J., Yin, J., 2023. Ur- ban street tree...
-
[5]
Deformable detr: Deformable transformers for end- to-end object detection, in: ICLR 2021 Conference. URL: https://github. 13
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.