What is Human in Judgment? Comparing Automation Bias and Algorithm Aversion Between the United States Military Academy and the General Public
Pith reviewed 2026-05-10 20:23 UTC · model grok-4.3
The pith
West Point cadets display better calibrated trust in algorithmic advice than the general public in a target identification task.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
West Point cadets are less prone to cognitive distortion than members of the general public, displaying better calibrated trust in algorithmic decision support systems. The experiment directly measured changes in identification after receiving advice, revealing that cadets adjusted their assessments in line with the quality of the input more effectively than civilians.
What carries the argument
Survey experiment with a target identification task where participants receive advice from an algorithm or human analyst and have the chance to reassess their initial judgment.
If this is right
- Military personnel may be less likely to err due to automation bias or algorithm aversion when using AI in operational settings.
- AI integration in militaries could be managed with lower risk of miscalculation if training emphasizes calibrated trust.
- Exposure to AI through education influences how humans interact with decision support in high-stakes environments.
- The role of human judgment in war may evolve differently in professional military forces than in civilian contexts.
Where Pith is reading between the lines
- Similar training approaches could be adapted for other high-stakes AI users like doctors or pilots to improve calibration.
- These findings point to education as a lever for shaping AI's impact on international security.
- Further studies could test if the effect holds in more complex, realistic military scenarios beyond the lab task.
Load-bearing premise
The target identification task and survey responses capture real-world susceptibility to automation bias and algorithm aversion in military decision-making.
What would settle it
A study observing actual military operators using AI decision support in field exercises or simulations to check if their trust calibration matches the cadet results.
Figures
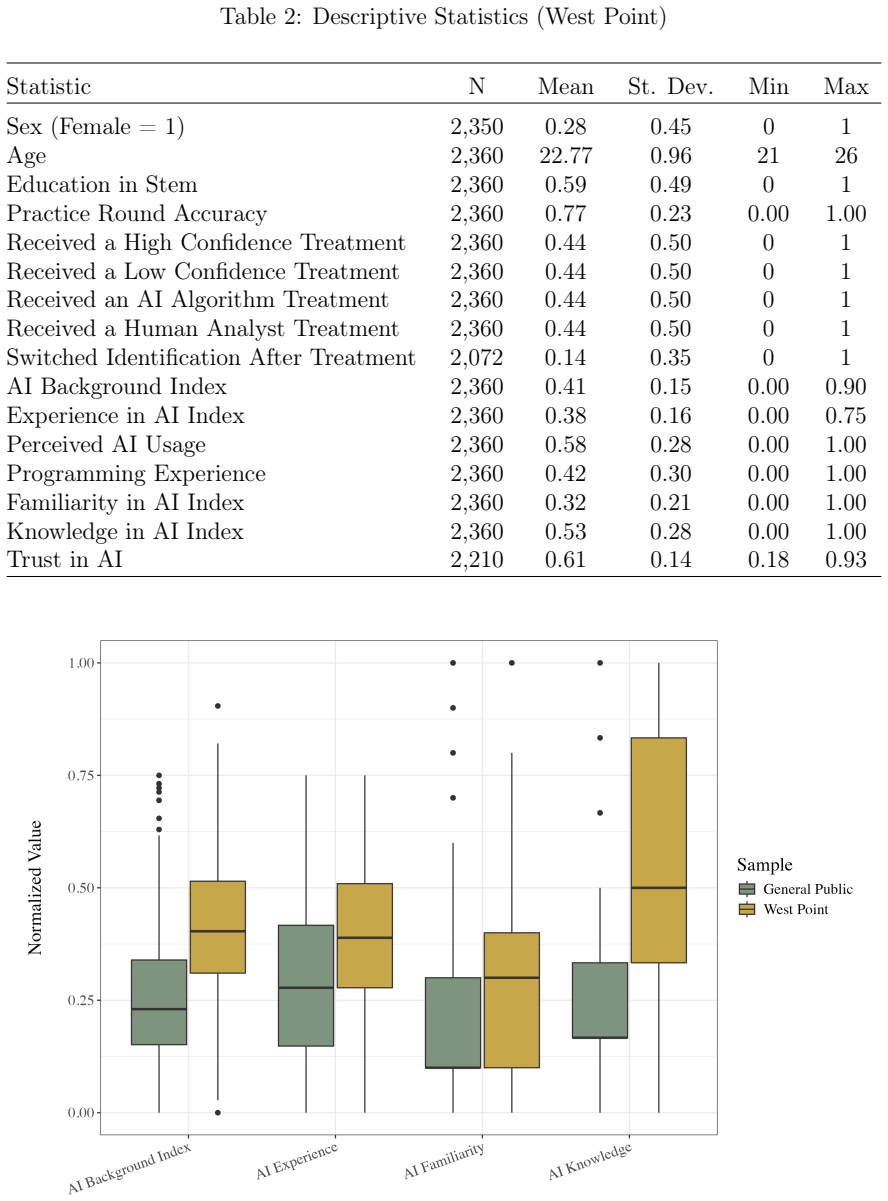



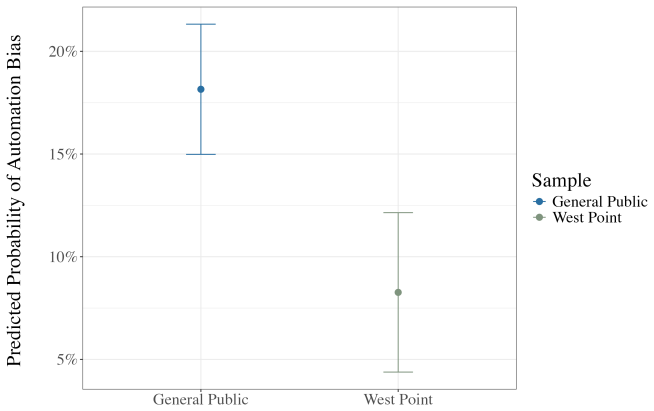
read the original abstract
Human judgment has always been central to conflict and escalation, but how will a world of artificial intelligence (AI) change the role of humans in war? As militaries increasingly adopt AI-enabled decision-support systems (DSS), including the United States in the war against Iran, concerns about automation bias -- over-reliance on algorithmic recommendations -- and algorithm aversion -- premature distrust of automated outputs -- raise fears that relying on AI too much could increase the risk of error, miscalculation, and accidents. Yet existing evidence on how militaries actually interact with AI remains limited. We test theories about the susceptibility of militaries to automation bias by comparing the results from a survey experiment conducted with 236 cadets at the United States Military Academy at West Point to a demographically similar cross-national public sample. Respondents completed a target identification task and then received advice from either an algorithm or a human analyst and had the opportunity to re-assess their initial identification, allowing direct measurement of automation bias and algorithm aversion. We find that West Point cadets are less prone to cognitive distortion than members of the general public, displaying better calibrated trust in algorithmic decision support systems. While the findings are limited, they suggest that military education and exposure to AI can meaningfully shape how AI influences international politics in matters of war and peace.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports results from a survey experiment with 236 US Military Academy cadets and a demographically matched public sample. Participants performed a target-identification task, received advice labeled as either algorithmic or human, and were allowed to revise their initial judgment. The central finding is that cadets exhibited better-calibrated trust (lower automation bias and algorithm aversion) than the public sample, suggesting that military education and AI exposure can reduce cognitive distortions in interactions with decision-support systems.
Significance. If the result holds, the work provides rare empirical evidence on how military training shapes human-AI interaction in a domain with high stakes for international security. It directly addresses a gap in the literature on automation bias and algorithm aversion within professional military populations and offers a falsifiable claim that education can produce more calibrated reliance on algorithmic advice.
major comments (2)
- [Methods and Results (target identification task description)] The headline claim that cadets show reduced cognitive distortion rests on the assumption that the low-stakes target-identification task elicits the same mechanisms that operate under operational time pressure, accountability, and lethal consequences. No manipulation checks, high-fidelity simulation arm, or within-cadet correlation with actual training/deployment experience are reported to support this mapping.
- [Abstract and Discussion] The abstract states that 'the findings are limited,' yet the manuscript provides no explicit discussion of how the artificial setting, absence of real-world consequences, or lack of demographic matching on military-specific variables (e.g., prior AI exposure, command experience) might artifactually produce the observed cadet-public difference.
minor comments (2)
- [Abstract] The sample size (N=236 cadets) and exact statistical tests, effect sizes, and confidence intervals for the key cadet-public comparison are not summarized in the abstract or early sections, making it difficult to assess the precision of the 'better calibrated trust' claim.
- [Experimental design] The paper does not report whether the algorithmic advice was actually more accurate than human advice in the task, which is necessary to distinguish calibrated trust from simple accuracy following.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important considerations regarding the generalizability of our findings. We address each major comment below and have revised the manuscript accordingly where feasible.
read point-by-point responses
-
Referee: [Methods and Results (target identification task description)] The headline claim that cadets show reduced cognitive distortion rests on the assumption that the low-stakes target-identification task elicits the same mechanisms that operate under operational time pressure, accountability, and lethal consequences. No manipulation checks, high-fidelity simulation arm, or within-cadet correlation with actual training/deployment experience are reported to support this mapping.
Authors: We acknowledge that the target identification task is a controlled, low-stakes survey experiment and does not replicate operational conditions such as time pressure or lethal consequences. The design was chosen to isolate the effects of advice source (algorithm vs. human) on judgment revision in a standardized manner across both samples, enabling a direct comparison of automation bias and algorithm aversion. No manipulation checks for perceived stakes or high-fidelity simulation arms were included, as the study was a survey-based experiment focused on population differences rather than ecological validity. We will add an expanded limitations subsection in the Discussion to explicitly address the assumptions required to map these results to high-stakes military contexts and note the absence of within-cadet correlations with training experience. revision: partial
-
Referee: [Abstract and Discussion] The abstract states that 'the findings are limited,' yet the manuscript provides no explicit discussion of how the artificial setting, absence of real-world consequences, or lack of demographic matching on military-specific variables (e.g., prior AI exposure, command experience) might artifactually produce the observed cadet-public difference.
Authors: We agree that while the abstract notes the findings are limited, the Discussion would benefit from more explicit treatment of these potential artifacts. We will revise the Discussion to include a dedicated paragraph addressing how the artificial setting and lack of real-world consequences could influence results, as well as the incomplete matching on military-specific variables such as prior AI exposure and command experience. This will clarify possible alternative explanations for the observed differences without overstating generalizability. revision: yes
- We cannot add manipulation checks, a high-fidelity simulation arm, or within-cadet correlations with deployment experience, as these would require new data collection beyond the existing survey experiment.
Circularity Check
No circularity: direct empirical comparison with no derivations or self-referential steps
full rationale
The paper reports results from a survey experiment comparing West Point cadets and a demographically matched public sample on a target identification task with algorithmic or human advice. No mathematical derivations, equations, parameter fitting presented as predictions, uniqueness theorems, or self-citation chains appear in the work. The central finding (better-calibrated trust among cadets) follows directly from observed differences in pre- and post-advice identification changes, without any reduction of outputs to inputs by construction. External validity concerns are separate from circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The target identification task accurately measures susceptibility to automation bias and algorithm aversion.
- domain assumption The cadet sample and demographically similar public sample allow valid causal inference about the effect of military education.
Reference graph
Works this paper leans on
-
[1]
Political declaration on responsible military use of artificial intelli- gence and autonomy
(2023). Political declaration on responsible military use of artificial intelli- gence and autonomy. US Department of State.https://www.state.gov/ political-declaration-on-responsible-military-use-of-artificial-intelligence-and-autonomy-2/. (2025). Young adults are leading the way in AI adoption. Associated Press.https:// apnorc.org/projects/young-adults-...
work page 2023
-
[2]
Bode, IngvildandBhila, Ishmael(2024). Theproblemofalgorithmicbiasinai-basedmilitary decision support systems.Humanitarian Law and Policy, September,
work page 2024
-
[3]
Brooks, Risa A, Robinson, Michael A, and Urben, Heidi A (2022). What makes a military professional? evaluating norm socialization in west point cadets.Armed Forces & Society, 48(4):803–827. Chong, Leah, Zhang, Guanglu, Goucher-Lambert, Kosa, Kotovsky, Kenneth, and Cagan, Jonathan (2022). Human confidence in artificial intelligence and in themselves: The e...
work page 2022
-
[4]
Speeding Up the OODA Loop with AI
31 Daniels, Owen (2021). Speeding Up the OODA Loop with AI. Institute for Defense Analysis. https://www.japcc.org/essays/speeding-up-the-ooda-loop-with-ai/. de Vaal, Johanna H. Kordes (1996). Intention and the omission bias: Omissions perceived as nondecisions.Acta Psychologica, 93(1-3):161–172. Dempsey, Jason K (2009).Our army: Soldiers, politics, and Am...
work page 2021
-
[5]
Ai-enabled decision-support systems in the joint targeting cycle.International Law Studies,
Dorsey, Jessica and Bo, Marta (2025). Ai-enabled decision-support systems in the joint targeting cycle.International Law Studies,
work page 2025
-
[6]
Dramsch, J.S., Kuglitsch, M.M., and Fernández-Torres, MA et al. (2025). Explainability can foster trust in artificial intelligence in geoscience.Nature Geosciences, 18:11–114. Dwoskin, Elizabeth (2024). Israel built an ‘ai factory’ for war. it unleashed it in gaza. The washington Post.https://www.washingtonpost.com/technology/2024/12/29/ ai-israel-war-gaz...
-
[7]
Hicks, Kathleen H. (2023). Statement by deputy secretary of defense 33 kathleen h. hicks marking one year of the defense department’s chief digital and artificial intelligence office (cdao). Department of De- fense.https://www.war.gov/News/Releases/Release/Article/3464007/ statement-by-deputy-secretary-of-defense-kathleen-h-hicks-marking-one-year-of-t/. H...
-
[8]
Maese, Ellyn (2025). Americans use ai in everyday products with- out realizing it.Gallup.https://news.gallup.com/poll/654905/ americans-everyday-products-without-realizing.aspx. Mahmud, Hasan, Najmul Islam, A.K.M., Ahmed, Syed Ishtiaque, and Smolander, Kari (2022). What influences algorithmic decision-making? a systematic literature review on algorithm av...
work page 2025
-
[9]
Manson, Katrina (2026). Us military relying on ai as tool to speed iran op- erations.Bloomberg.https://www.bloomberg.com/news/articles/2026-03-05/ us-military-relying-on-ai-as-key-tool-to-speed-iran-operations. McDermott, Rose (2026). How Emotions Shape Crisis Decision-Making: The Role of Fear, Anger, and Risk. In Clinton, Hillary Rodham and Yarhi-Milo, K...
work page 2026
-
[10]
Notoracles of the battlefield: Safety considerations for ai-based military decision support systems
Probasco, Emelia, Burtell, Matthew, Toner, Helen, andRudner, TimGJ(2024b). Notoracles of the battlefield: Safety considerations for ai-based military decision support systems. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, 7:1157–1165. 37 Puscas, Ioana (2023). AI and International Security: Understanding the Risks and Paving the Path f...
-
[11]
appropri- ate levels of human judgement
Depart- ment of Military Instruction. 39 U.S. Mission Geneva (2016). U.s. delegation statement on "appropri- ate levels of human judgement". US Mission to International Or- ganizations in Geneva.https://geneva.usmission.gov/2016/04/12/ u-s-delegation-statement-on-appropriate-levels-of-human-judgment/. Williams, Major Blair S. (2010). Heuristics and biases...
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.