Cardinality Estimation for High Dimensional Similarity Queries with Adaptive Bucket Probing
Pith reviewed 2026-05-10 19:56 UTC · model grok-4.3
The pith
A locality-sensitive hashing framework with adaptive probing and progressive sampling estimates the number of similar items in high-dimensional data accurately and efficiently.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The proposed framework partitions high-dimensional space with locality-sensitive hashing, then applies adaptive multi-probe exploration of neighboring buckets scaled to the query distance threshold; progressive sampling combined with asymmetric distance computation in product quantization reduces the cost of each estimate, while dedicated update algorithms maintain the structure under data changes.
What carries the argument
Adaptive multi-probe locality-sensitive hashing that selects buckets according to distance thresholds, paired with progressive sampling to limit distance computations.
If this is right
- Query optimizers in database systems can use the estimates to select execution strategies for similarity searches.
- The same structure supports both static collections and large-scale dynamic datasets through its update procedures.
- Fewer distance calculations are needed during estimation, improving online response times in high-dimensional settings.
- Cardinality estimates remain usable even when the similarity threshold changes between queries.
Where Pith is reading between the lines
- The approach might be combined with other index structures to estimate result sizes for approximate nearest-neighbor queries.
- Similar sampling ideas could be tested for estimating the number of points inside range queries in metric spaces beyond vectors.
- Performance on datasets whose dimensionality greatly exceeds those used in the experiments would indicate whether the sampling bias grows with dimension.
Load-bearing premise
Locality-sensitive hashing and the chosen sampling strategy preserve enough distance information that estimates remain accurate across different thresholds and data distributions.
What would settle it
Compute both the estimated and the exact cardinality for the same set of high-dimensional queries on a public vector dataset; a large, consistent gap between the two values at any threshold would show the method fails to deliver accurate estimates.
Figures




read the original abstract
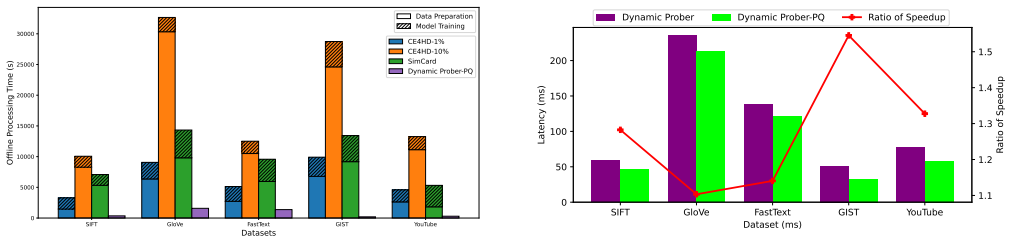
In this work, we address the problem of cardinality estimation for similarity search in high-dimensional spaces. Our goal is to design a framework that is lightweight, easy to construct, and capable of providing accurate estimates with satisfying online efficiency. We leverage locality-sensitive hashing (LSH) to partition the vector space while preserving distance proximity. Building on this, we adopt the principles of classical multi-probe LSH to adaptively explore neighboring buckets, accounting for distance thresholds of varying magnitudes. To improve online efficiency, we employ progressive sampling to reduce the number of distance computations and utilize asymmetric distance computation in product quantization to accelerate distance calculations in high-dimensional spaces. In addition to handling static datasets, our framework includes updating algorithm designed to efficiently support large-scale dynamic scenarios of data updates.Experiments demonstrate that our methods can accurately estimate the cardinality of similarity queries, yielding satisfying efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a framework for cardinality estimation of similarity queries in high-dimensional spaces. It partitions the space with locality-sensitive hashing (LSH), applies adaptive multi-probe exploration of neighboring buckets to handle varying distance thresholds, uses progressive sampling and asymmetric product quantization to reduce distance computations, and includes an update algorithm for dynamic data. The central claim is that experiments demonstrate accurate cardinality estimates with satisfying efficiency.
Significance. If the experimental claims hold with strong quantitative support, the work could offer a practical, lightweight approach to cardinality estimation for high-dimensional similarity search in databases, extending established LSH and quantization techniques to both static and dynamic settings. The adaptive probing and sampling components address a relevant efficiency challenge, but the absence of concrete metrics, baselines, or dataset details in the provided description limits assessment of improvement over prior methods.
major comments (2)
- [Abstract] Abstract: The assertion that 'Experiments demonstrate that our methods can accurately estimate the cardinality of similarity queries, yielding satisfying efficiency' supplies no quantitative results (e.g., relative error, recall, or runtime), no baselines, no error metrics, and no dataset details. This is load-bearing for the paper's empirical contribution and prevents evaluation of the central claim.
- [Evaluation] Evaluation section: The description of experiments must include specific accuracy numbers, comparisons to standard LSH cardinality estimators or sampling baselines, details on datasets and query thresholds, and analysis of bias from sampling or quantization to substantiate the accuracy claim.
minor comments (2)
- [Introduction] Clarify the precise definition of 'cardinality' in the context of similarity queries (e.g., number of points within a radius) and how it differs from standard selectivity estimation.
- [Dynamic Updates] The description of the dynamic update algorithm should specify the time complexity and how it maintains the LSH structure without full rebuilds.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract and evaluation section would benefit from greater specificity to strengthen the empirical claims, and we will revise the manuscript accordingly while preserving the core technical contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'Experiments demonstrate that our methods can accurately estimate the cardinality of similarity queries, yielding satisfying efficiency' supplies no quantitative results (e.g., relative error, recall, or runtime), no baselines, no error metrics, and no dataset details. This is load-bearing for the paper's empirical contribution and prevents evaluation of the central claim.
Authors: We agree that the abstract would be strengthened by including concrete quantitative results. In the revised version we will add specific metrics such as average relative error (typically under 15% across tested thresholds), runtime reductions relative to naive sampling, and references to the datasets and query distance thresholds used. This will make the central empirical claim more self-contained without altering the technical narrative. revision: yes
-
Referee: [Evaluation] Evaluation section: The description of experiments must include specific accuracy numbers, comparisons to standard LSH cardinality estimators or sampling baselines, details on datasets and query thresholds, and analysis of bias from sampling or quantization to substantiate the accuracy claim.
Authors: We acknowledge the need for more explicit experimental detail. The current evaluation already reports results on standard high-dimensional datasets (e.g., SIFT and GloVe) with varying query thresholds and includes comparisons against uniform sampling and basic LSH estimators. In revision we will expand the section with (i) tabulated mean relative error and recall figures, (ii) a new subsection quantifying bias introduced by progressive sampling and asymmetric product quantization (including both theoretical bounds and empirical measurements), and (iii) additional runtime and accuracy plots against the suggested baselines. These additions will directly address the request for substantiation. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical framework for cardinality estimation in high-dimensional spaces using LSH partitioning, adaptive multi-probe exploration, progressive sampling, and product quantization, with experimental validation for accuracy and efficiency on static and dynamic data. No derivation chain, first-principles predictions, or mathematical reductions are claimed or visible in the abstract or method description. All components are standard techniques combined practically, with performance claims resting on experiments rather than any self-referential definitions, fitted inputs renamed as predictions, or load-bearing self-citations. The approach is self-contained without circular steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We leverage locality-sensitive hashing (LSH) to partition the vector space while preserving distance proximity. Building on this, we adopt the principles of classical multi-probe LSH to adaptively explore neighboring buckets... progressive sampling... asymmetric distance computation in product quantization
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experiments demonstrate that our methods can accurately estimate the cardinality of similarity queries, yielding satisfying efficiency.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Alexandr Andoni. [n.d.]. LSH Algorithm and Implementation (E2LSH). https: //www.mit.edu/~andoni/LSH/. Accessed: 2025-08-28
work page 2025
-
[2]
Muhammad Imam Luthfi Balaka, David Alexander, Qiming Wang, Yue Gong, Adila Krisnadhi, and Raul Castro Fernandez. 2025. Pneuma: Leveraging LLMs for Tabular Data Representation and Retrieval in an End-to-End System.Proc. ACM Manag. Data3, 3 (2025), 200:1–200:28
work page 2025
-
[3]
Surajit Chaudhuri. 1998. An Overview of Query Optimization in Relational Systems. InPODS. ACM Press, 34–43
work page 1998
-
[4]
Chroma. [n.d.]. Chroma: The Open-Source AI Application Database. https: //www.trychroma.com/. Accessed: 2024-12-05
work page 2024
-
[5]
DeepSeek-AI. 2024. DeepSeek-V3 Technical Report.CoRRabs/2412.19437 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Garofalakis, and Rajeev Rastogi
Amol Deshpande, Minos N. Garofalakis, and Rajeev Rastogi. 2001. Independence is Good: Dependency-Based Histogram Synopses for High-Dimensional Data. In SIGMOD Conference. ACM, 199–210
work page 2001
-
[7]
Rohan Anil et al. 2023. Gemini: A Family of Highly Capable Multimodal Models. CoRRabs/2312.11805 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Lise Getoor, Benjamin Taskar, and Daphne Koller. 2001. Selectivity Estimation using Probabilistic Models. InSIGMOD Conference. ACM, 461–472
work page 2001
-
[9]
PostgreSQL Global Development Group. 2024. PostgreSQL: The World’s Most Advanced Open Source Relational Database. https://www.postgresql.org/. Ac- cessed: 2024-11-28
work page 2024
-
[10]
Tsotras, and Carlotta Domeni- coni
Dimitrios Gunopulos, George Kollios, Vassilis J. Tsotras, and Carlotta Domeni- coni. 2005. Selectivity estimators for multidimensional range queries over real attributes.VLDB J.14, 2 (2005), 137–154
work page 2005
-
[11]
Yuxing Han, Ziniu Wu, Peizhi Wu, Rong Zhu, Jingyi Yang, Liang Wei Tan, Kai Zeng, Gao Cong, Yanzhao Qin, Andreas Pfadler, Zhengping Qian, Jingren Zhou, Jiangneng Li, and Bin Cui. 2021. Cardinality Estimation in DBMS: A Comprehensive Benchmark Evaluation.Proc. VLDB Endow.15, 4 (2021), 752– 765
work page 2021
-
[12]
Llama 2: Open Foundation and Fine-Tuned Chat Models
al. Hugo Touvron et. 2023. Llama 2: Open Foundation and Fine-Tuned Chat Models.CoRRabs/2307.09288 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Yannis E. Ioannidis. 1996. Query optimization.ACM Comput. Surv.28, 1 (March 1996), 121–123. https://doi.org/10.1145/234313.234367
-
[14]
Hervé Jégou, Matthijs Douze, and Cordelia Schmid. 2011. Product Quantization for Nearest Neighbor Search.IEEE Trans. Pattern Anal. Mach. Intell.33, 1 (2011), 117–128
work page 2011
-
[15]
al. Jianguo Wang et. 2021. Milvus: A Purpose-Built Vector Data Management System. InSIGMOD Conference. ACM, 2614–2627
work page 2021
-
[16]
Martin Kiefer, Max Heimel, Sebastian Breß, and Volker Markl. 2017. Estimating Join Selectivities using Bandwidth-Optimized Kernel Density Models.Proc. VLDB Endow.10, 13 (2017), 2085–2096
work page 2017
-
[17]
Kyoungmin Kim, Jisung Jung, In Seo, Wook-Shin Han, Kangwoo Choi, and Jaehyok Chong. 2022. Learned Cardinality Estimation: An In-depth Study. In SIGMOD Conference. ACM, 1214–1227
work page 2022
-
[18]
Hai Lan, Shixun Huang, Zhifeng Bao, and Renata Borovica-Gajic. 2024. Car- dinality Estimation for Similarity Search on High-Dimensional Data Objects: The Impact of Reference Objects.Proc. VLDB Endow.18, 3 (Nov. 2024), 544–556. https://doi.org/10.14778/3712221.3712224
-
[19]
lancedb. [n.d.]. Developer-friendly, database for multimodal AI. https://lancedb. com/. Accessed: 2024-12-05
work page 2024
-
[20]
Jie Li, Haifeng Liu, Chuanghua Gui, Jianyu Chen, Zhenyun Ni, and Ning Wang
-
[21]
The Design and Implementation of a Real Time Visual Search System on JD E-commerce Platform. arXiv:1908.07389 [cs.IR]
-
[22]
Qin Lv, William Josephson, Zhe Wang, Moses Charikar, and Kai Li. 2007. Multi- Probe LSH: Efficient Indexing for High-Dimensional Similarity Search. InVLDB. ACM, 950–961
work page 2007
-
[23]
Yury A. Malkov and Dmitry A. Yashunin. 2020. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs.IEEE Trans. Pattern Anal. Mach. Intell.42, 4 (2020), 824–836
work page 2020
-
[24]
Michael Mattig, Thomas Fober, Christian Beilschmidt, and Bernhard Seeger. 2018. Kernel-Based Cardinality Estimation on Metric Data. InEDBT. OpenProceed- ings.org, 349–360
work page 2018
-
[25]
OpenAI. 2023. GPT-4 Technical Report.CoRRabs/2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
James Jie Pan, Jianguo Wang, and Guoliang Li. 2024. Survey of vector database management systems.VLDB J.33, 5 (2024), 1591–1615
work page 2024
- [27]
-
[28]
pgvector contributors. 2024. pgvector: Open-source extension for vector simi- larity search in PostgreSQL. https://github.com/pgvector/pgvector. Accessed: 2024-11-28
work page 2024
-
[29]
pinecone. [n.d.]. Build knowledgeable AI. https://www.pinecone.io/. Accessed: 2024-12-05
work page 2024
-
[30]
Qdrant. [n.d.]. Qdrant: High-Performance Vector Search at Scale. https://qdrant. tech/. Accessed: 2024-12-05
work page 2024
-
[31]
Jianbin Qin, Yaoshu Wang, Chuan Xiao, Wei Wang, Xuemin Lin, and Yoshiharu Ishikawa. 2018. GPH: Similarity Search in Hamming Space. InICDE. IEEE Computer Society, 29–40
work page 2018
-
[32]
Jianbin Qin and Chuan Xiao. 2018. Pigeonring: A Principle for Faster Thresholded Similarity Search.Proc. VLDB Endow.12, 1 (2018), 28–42
work page 2018
-
[33]
Suraj Shetiya, Saravanan Thirumuruganathan, Nick Koudas, and Gautam Das
-
[34]
VLDB Endow.14, 4 (2020), 471–484
Astrid: Accurate Selectivity Estimation for String Predicates using Deep Learning.Proc. VLDB Endow.14, 4 (2020), 471–484
work page 2020
-
[35]
Ji Sun, Guoliang Li, and Nan Tang. 2021. Learned Cardinality Estimation for Similarity Queries. InSIGMOD Conference. ACM, 1745–1757
work page 2021
-
[36]
Yao Tian, Xi Zhao, and Xiaofang Zhou. 2022. DB-LSH: Locality-Sensitive Hashing with Query-based Dynamic Bucketing. InICDE. IEEE, 2250–2262
work page 2022
-
[37]
Yao Tian, Xi Zhao, and Xiaofang Zhou. 2024. DB-LSH 2.0: Locality-Sensitive Hashing With Query-Based Dynamic Bucketing.IEEE Transactions on Knowledge and Data Engineering36, 3 (2024), 1000–1015. https://doi.org/10.1109/TKDE. 2023.3295831
-
[38]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurélien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lam- ple. 2023. LLaMA: Open and Efficient Foundation Language Models.CoRR abs/2302.13971 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Mengzhao Wang, Xiaoliang Xu, Qiang Yue, and Yuxiang Wang. 2021. A Com- prehensive Survey and Experimental Comparison of Graph-Based Approximate Nearest Neighbor Search.Proc. VLDB Endow.14, 11 (2021), 1964–1978
work page 2021
-
[40]
Yaoshu Wang, Chuan Xiao, Jianbin Qin, Xin Cao, Yifang Sun, Wei Wang, and Makoto Onizuka. 2020. Monotonic Cardinality Estimation of Similarity Selection: A Deep Learning Approach. InSIGMOD Conference. ACM, 1197–1212
work page 2020
-
[41]
Yaoshu Wang, Chuan Xiao, Jianbin Qin, Rui Mao, Makoto Onizuka, Wei Wang, Rui Zhang, and Yoshiharu Ishikawa. 2021. Consistent and Flexible Selectivity Estimation for High-Dimensional Data. InSIGMOD Conference. ACM, 2319–2327
work page 2021
-
[42]
Weaviate. [n.d.]. Weaviate: An Open-Source Vector Database. https://weaviate. io/. Accessed: 2024-12-05
work page 2024
-
[43]
Chuangxian Wei, Bin Wu, Sheng Wang, Renjie Lou, Chaoqun Zhan, Feifei Li, and Yuanzhe Cai. 2020. AnalyticDB-V: A Hybrid Analytical Engine Towards Query Fusion for Structured and Unstructured Data.Proc. VLDB Endow.13, 12 (2020), 3152–3165
work page 2020
-
[44]
Xian Wu, Moses Charikar, and Vishnu Natchu. 2018. Local Density Estimation in High Dimensions. InICML (Proceedings of Machine Learning Research), Vol. 80. PMLR, 5293–5301
work page 2018
-
[45]
Wen Yang, Tao Li, Gai Fang, and Hong Wei. 2020. PASE: PostgreSQL Ultra- High-Dimensional Approximate Nearest Neighbor Search Extension. InSIGMOD Conference. ACM, 2241–2253
work page 2020
-
[46]
Zongheng Yang, Amog Kamsetty, Sifei Luan, Eric Liang, Yan Duan, Xi Chen, and Ion Stoica. 2020. NeuroCard: One Cardinality Estimator for All Tables.Proc. VLDB Endow.14, 1 (2020), 61–73
work page 2020
-
[47]
Hellerstein, Sanjay Krishnan, and Ion Stoica
Zongheng Yang, Eric Liang, Amog Kamsetty, Chenggang Wu, Yan Duan, Xi Chen, Pieter Abbeel, Joseph M. Hellerstein, Sanjay Krishnan, and Ion Stoica
-
[48]
√𝑝− √︂𝑎 2𝑤 2 > ˆ𝑝+ 2𝑎 2𝑤 # (5) =Pr 𝑝−2 √𝑝 √︂𝑎 2𝑤 + 𝑎 2𝑤 > ˆ𝑝+ 2𝑎 2𝑤 (6) ≤Pr
Deep Unsupervised Cardinality Estimation.Proc. VLDB Endow.13, 3 (2019), 279–292. 13 8 APPENDIX 8.1 Definition: Chernoff Bound Consider tossing an unfair coin for𝑛times, we have: •Observation:𝑋 𝑖 –The outcome of the𝑖 th toss –1 for Heads, 0 for Tails •True Probability:𝑝 –The actual probability of obtaining Heads •Error parameter:𝜖 –The margin of error for ...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.