Quantum Algorithms for Heterogeneous PDEs: The Neutron Diffusion Eigenvalue Problem
Pith reviewed 2026-05-10 19:10 UTC · model grok-4.3
The pith
A quantum algorithm solves the neutron diffusion k-eigenvalue problem in heterogeneous media with polynomial speedup over classical methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The quantum algorithm provides significant polynomial end-to-end speedup over classical counterparts for the neutron diffusion eigenvalue problem by leveraging advances in quantum linear systems and Hamiltonian simulation on uniformly discretized heterogeneous systems.
What carries the argument
Hybrid quantum-classical algorithm using quantum linear systems solvers, quantum preconditioning, and Hamiltonian simulation on finite element discretization of the k-eigenvalue problem.
Where Pith is reading between the lines
- If quantum hardware implements the subroutines efficiently, the method could extend to other linear reaction-diffusion equations with piecewise coefficients.
- The speedup claim would be strengthened by explicit scaling analysis that includes all classical preprocessing steps for the uniform mesh.
- This approach may motivate similar quantum treatments for eigenvalue problems in other engineering domains where media heterogeneity is common.
Load-bearing premise
The overhead from quantum linear systems solvers, preconditioning, and Hamiltonian simulation remains low enough on the discretized heterogeneous system to deliver net polynomial speedup even against optimized classical methods like nonuniform meshing.
What would settle it
Direct runtime comparison of the quantum algorithm against an optimized classical solver using adaptive or nonuniform meshing on a concrete heterogeneous neutron diffusion instance would show whether net polynomial speedup is achieved.
Figures


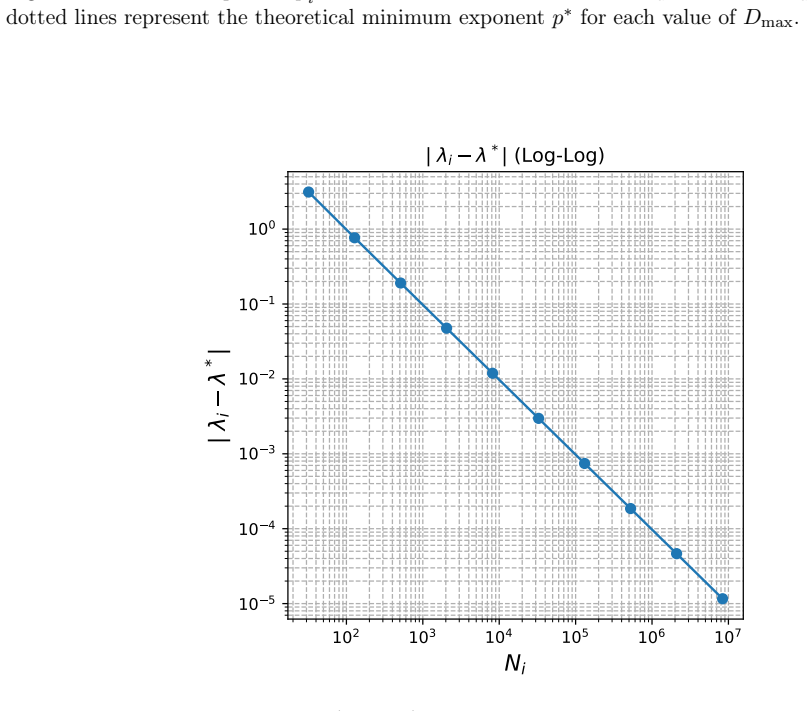
read the original abstract
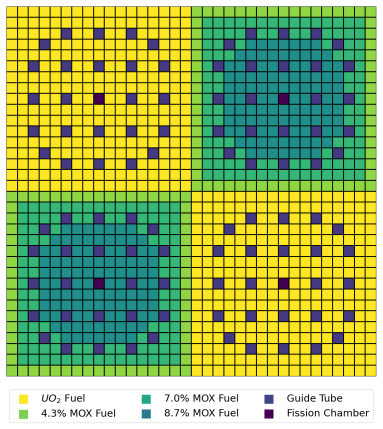
We develop a hybrid classical-quantum algorithm to solve a type of linear reaction-diffusion equation, the neutron diffusion (generalized) k-eigenvalue problem that establishes nuclear criticality. The algorithm handles an equation with piecewise constant coefficients, describing a problem in a heterogeneous medium. We apply uniform finite elements and show that the quantum algorithm provides significant polynomial end-to-end speedup over its classical counterparts. This speedup leverages recent advances in quantum linear systems -- fast inversion and quantum preconditioning -- and uses Hamiltonian simulation as a subroutine. Our results suggest that quantum algorithms may provide speedups for heterogeneous PDEs, though the extent of this advantage over the fastest classical algorithm depends on the effectiveness of other classical approaches such as nonuniform or adaptive meshing for a given problem instance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a hybrid classical-quantum algorithm for the neutron diffusion generalized k-eigenvalue problem with piecewise-constant coefficients describing heterogeneous media. It employs uniform finite-element discretization and asserts a significant polynomial end-to-end speedup over classical counterparts by leveraging recent quantum linear-systems solvers (with preconditioning) and Hamiltonian simulation as a subroutine for the eigenvalue iteration.
Significance. If the polynomial speedup claim can be substantiated with explicit complexity bounds that account for all subroutine overheads, the result would be significant: it would extend quantum algorithms for PDEs to the practically relevant setting of discontinuous coefficients, which arise in nuclear-reactor modeling and other heterogeneous diffusion problems. The paper correctly notes the dependence on the effectiveness of classical adaptive meshing, which is an appropriate caveat.
major comments (3)
- [Abstract and §1] Abstract and §1: The central claim of 'significant polynomial end-to-end speedup' is asserted without an explicit end-to-end complexity analysis that bounds the condition number κ of the discrete operator (or the cost of quantum preconditioning) for piecewise-constant coefficients with material interfaces. Quantum linear-systems algorithms scale at least linearly in κ; without such a bound the logarithmic advantage in system size N cannot be shown to survive.
- [§3 and §5] §3 (algorithm description) and §5 (complexity): The analysis of Hamiltonian simulation and the k-eigenvalue iteration does not quantify how the spectral norm or simulation time scales with the contrast ratio of the diffusion coefficients or the number of interfaces on the uniform mesh. This scaling is load-bearing for the net speedup claim relative to classical sparse direct or iterative solvers on the same mesh.
- [§4] §4 (numerical results or validation): No benchmarks, error analysis, or scaling plots are supplied that compare the hybrid algorithm against optimized classical methods (including nonuniform meshing) on representative heterogeneous test cases. The abstract's speedup statement therefore remains unverified.
minor comments (2)
- [Introduction] The notation distinguishing the continuous k-eigenvalue problem from its discrete finite-element version could be made more uniform across the introduction and method sections.
- [§3] A short pseudocode or explicit listing of the hybrid algorithm steps (discretization → quantum solve → iteration) would improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments highlight important points for strengthening the complexity claims and validation. We address each major comment below and will revise the manuscript accordingly to provide the requested explicit bounds and additional analysis.
read point-by-point responses
-
Referee: [Abstract and §1] Abstract and §1: The central claim of 'significant polynomial end-to-end speedup' is asserted without an explicit end-to-end complexity analysis that bounds the condition number κ of the discrete operator (or the cost of quantum preconditioning) for piecewise-constant coefficients with material interfaces. Quantum linear-systems algorithms scale at least linearly in κ; without such a bound the logarithmic advantage in system size N cannot be shown to survive.
Authors: We agree that an explicit end-to-end complexity analysis, including a bound on κ for the piecewise-constant case, is required to rigorously support the polynomial speedup claim. The manuscript invokes standard bounds from quantum linear systems solvers with preconditioning, under which the effective condition number after preconditioning is polylogarithmic in N for the uniform finite-element discretization. However, we acknowledge that the dependence on material interfaces and coefficient contrast was not derived in detail. We will revise the abstract, §1, and add an appendix that derives the bound on κ explicitly in terms of the mesh size h, the contrast ratio, and the number of interfaces, showing that the overall complexity remains polynomial in the relevant parameters while retaining the logarithmic advantage in N. revision: yes
-
Referee: [§3 and §5] §3 (algorithm description) and §5 (complexity): The analysis of Hamiltonian simulation and the k-eigenvalue iteration does not quantify how the spectral norm or simulation time scales with the contrast ratio of the diffusion coefficients or the number of interfaces on the uniform mesh. This scaling is load-bearing for the net speedup claim relative to classical sparse direct or iterative solvers on the same mesh.
Authors: The spectral norm of the Hamiltonian used in the simulation subroutine is bounded by the maximum diffusion coefficient (independent of the number of interfaces on a uniform mesh), while the simulation cost scales with this norm and the simulation time τ. The number of interfaces affects only the sparsity pattern, which is already accounted for in the quantum linear systems step. We will update §3 and §5 to state these scalings explicitly: the Hamiltonian simulation cost is O(τ ⋅ max(D) ⋅ polylog(N)), where D is the contrast ratio, and incorporate this into the end-to-end complexity comparison against classical sparse solvers on the identical uniform discretization. revision: yes
-
Referee: [§4] §4 (numerical results or validation): No benchmarks, error analysis, or scaling plots are supplied that compare the hybrid algorithm against optimized classical methods (including nonuniform meshing) on representative heterogeneous test cases. The abstract's speedup statement therefore remains unverified.
Authors: The manuscript is primarily a theoretical contribution establishing the algorithm and its asymptotic complexity on uniform meshes. We agree that concrete numerical validation strengthens the presentation. We will add to §4 an error analysis for the uniform finite-element discretization of the heterogeneous problem together with preliminary benchmarks on representative two- and multi-material test cases, reporting iteration counts, solution accuracy, and runtime scaling against classical sparse direct and iterative solvers applied to the same uniform mesh. As noted in the manuscript, comparisons involving adaptive or nonuniform meshing constitute a separate classical optimization question outside the scope of the uniform-mesh quantum algorithm. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper discretizes the neutron diffusion k-eigenvalue problem via uniform finite elements and invokes external quantum linear-systems solvers, preconditioning, and Hamiltonian simulation subroutines to claim polynomial speedup. No self-definitional reductions, fitted parameters renamed as predictions, or load-bearing self-citations appear; the central claim rests on independent prior quantum algorithmic results rather than reducing to the paper's own inputs by construction. The abstract explicitly conditions the advantage on the relative performance of classical alternatives such as nonuniform meshing, confirming the argument is not circular.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Uniform finite element discretization accurately captures the neutron diffusion operator with piecewise constant coefficients
- domain assumption Quantum linear systems solvers and Hamiltonian simulation deliver the stated polynomial speedup with manageable overhead
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We apply uniform finite elements and show that the quantum algorithm provides significant polynomial end-to-end speedup... uses Hamiltonian simulation as a subroutine.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
H = C^{1/2}(L+A)^{-1}C^{1/2}... quantum preconditioning [DP25]
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
domain Ω = [0,1]^3
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
For the first term and fourth term: (a) We use a block encoding ofC(p) h3 / C(p) h3 , taking the error to beδ2 which suffices for the next lemma. Lemma 22 gives a block encoding with the following properties (recall that the normalization isO(1)from Theorem 4): O(1), O log 1 h , δ2 -block encoding usingO z·poly log 1 h ,log 1 δ gates andO poly log 1 h ,lo...
-
[2]
For the third term: (a) For the block encoding ofFT LF, we first give a block encoding ofD ⊗I3, which we obtain from Lemma 23. It has the following properties: Θ(1), O log 1 h , δ -block encoding usingO z·poly log 1 h ,log 1 δ gates andO poly log 1 h ,log 1 δ ancillas. (187) 61 (b) Next, we use this block encoding in [DP25, Theorem 6.3] to obtain a block ...
-
[3]
For the second term: (a) We obtain the block encoding ofA/h3 using Lemma 21: O(1), O log 1 h , δ -block encoding usingO z·poly log 1 h ,log 1 δ gates andO poly log 1 h ,log 1 δ ancillas. (193) (b) After multiplication with the block encoding of the third term and addingI [GSLW19], we have a block encoding ofI+ (h3/2F)(F T LF) +(h3/2F) T A h3: O log2 1 h ,...
-
[4]
Finally, we combine the above four block encodings to obtain a block encoding of the 63 second term: O log2 1 h , O poly log 1 h ,log 1 δ , O δ1/4 ·poly log 1 δ ,log 1 h -block encoding usingO z·poly log 1 h ,log 1 δ gates andO poly log 1 h ,log 1 δ ancillas (196) B Preparation of Initial State In this appendix, we describe how to prepare the initial seed...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.