DIA-HARM: Dialectal Disparities in Harmful Content Detection Across 50 English Dialects
Pith reviewed 2026-05-10 19:54 UTC · model grok-4.3
The pith
Disinformation detectors show reduced performance on non-Standard American English dialects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
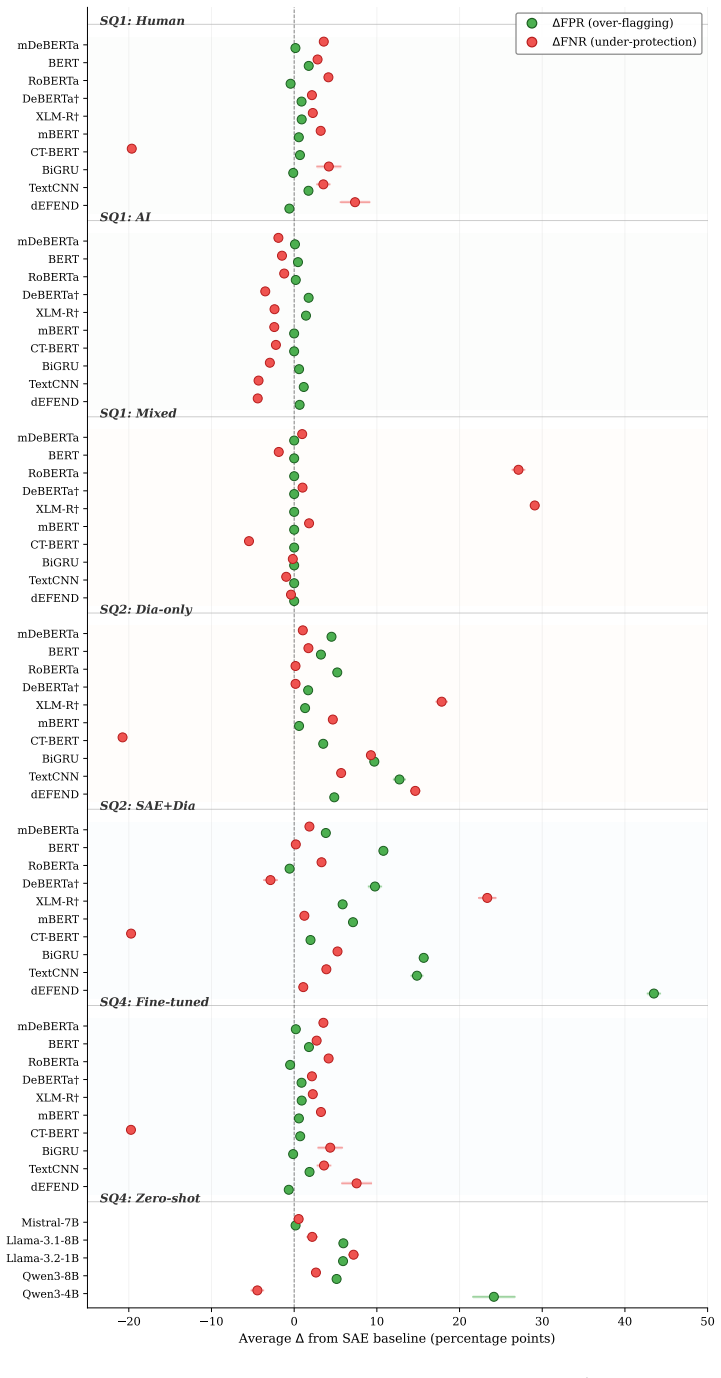
Evaluations using the DIA-HARM benchmark and the D3 corpus of 195K dialectal samples show that human-written dialectal content degrades F1 scores by 1.4-3.6 percent across 16 models while AI-generated dialectal content stays stable, with some models exhibiting over 33 percent degradation on mixed content. Fine-tuned transformers reach best-case F1 of 96.6 percent versus 78.3 percent for zero-shot LLMs, and cross-dialect analysis of 2450 pairs finds that multilingual models such as mDeBERTa average 97.2 percent F1 while monolingual models like RoBERTa fail on dialectal inputs.
What carries the argument
The DIA-HARM benchmark applies linguistically grounded transformations to create 50 English dialect variants of disinformation samples for testing detection robustness.
If this is right
- Fine-tuned transformers substantially outperform zero-shot LLMs on dialectal disinformation inputs.
- Multilingual models generalize across dialects far better than monolingual models such as RoBERTa.
- Human-written dialect content triggers larger performance losses than AI-generated dialect content.
- Current detectors may produce unequal results for hundreds of millions of non-Standard American English speakers.
Where Pith is reading between the lines
- Moderation pipelines may need explicit dialect coverage during training to reduce uneven error rates.
- The observed stability on AI-generated text suggests detectors may rely on cues that differ between synthetic and natural language.
- Similar robustness gaps could appear in related tasks such as hate-speech or toxicity detection.
- Global deployment of these models would benefit from routine testing on authentic regional English data.
Load-bearing premise
The transformed dialect samples accurately match real-world usage and keep the original disinformation label without adding separate changes that alter model behavior.
What would settle it
Running the same 16 models on naturally collected disinformation examples written in the target dialects and finding no drop in detection scores relative to Standard American English.
Figures




read the original abstract
Harmful content detectors-particularly disinformation classifiers-are predominantly developed and evaluated on Standard American English (SAE), leaving their robustness to dialectal variation unexplored. We present DIA-HARM, the first benchmark for evaluating disinformation detection robustness across 50 English dialects spanning U.S., British, African, Caribbean, and Asia-Pacific varieties. Using Multi-VALUE's linguistically grounded transformations, we introduce D3 (Dialectal Disinformation Detection), a corpus of 195K samples derived from established disinformation benchmarks. Our evaluation of 16 detection models reveals systematic vulnerabilities: human-written dialectal content degrades detection by 1.4-3.6% F1, while AI-generated content remains stable. Fine-tuned transformers substantially outperform zero-shot LLMs (96.6% vs. 78.3% best-case F1), with some models exhibiting catastrophic failures exceeding 33% degradation on mixed content. Cross-dialectal transfer analysis across 2,450 dialect pairs shows that multilingual models (mDeBERTa: 97.2% average F1) generalize effectively, while monolingual models like RoBERTa and XLM-RoBERTa fail on dialectal inputs. These findings demonstrate that current disinformation detectors may systematically disadvantage hundreds of millions of non-SAE speakers worldwide. We release the DIA-HARM framework, D3 corpus, and evaluation tools: https://github.com/jsl5710/dia-harm
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DIA-HARM, the first benchmark for disinformation detection robustness across 50 English dialects (U.S., British, African, Caribbean, Asia-Pacific). It constructs the D3 corpus (195K samples) by applying Multi-VALUE linguistically grounded transformations to existing disinformation benchmarks. Evaluation of 16 models (fine-tuned transformers and zero-shot LLMs) reports F1 degradations of 1.4-3.6% on human-written dialectal content (with some mixed cases >33%), better performance from multilingual models (e.g., mDeBERTa at 97.2% average F1), and cross-dialectal transfer results over 2,450 pairs. The authors conclude that current detectors may systematically disadvantage non-SAE speakers and release the framework, D3 corpus, and tools.
Significance. If the D3 corpus validly represents real-world dialectal disinformation, the work identifies a practically important robustness gap in harmful-content detection systems that could affect hundreds of millions of speakers. The empirical scale (50 dialects, 16 models, large corpus), release of code/data, and cross-dialect transfer analysis are strengths that would support follow-on research in fairness and multilingual NLP.
major comments (2)
- [D3 corpus construction] Corpus construction / D3 creation section: The central claim that detectors 'systematically disadvantage' non-SAE speakers rests on performance drops observed after Multi-VALUE transformations. No quantitative validation (human naturalness ratings, semantic equivalence checks against authentic dialect corpora, or label-preservation verification) is reported for the 50 dialects. If transformations introduce unnatural phrasing or alter surface cues that models rely on, the measured F1 gaps (1.4-3.6% and >33%) may reflect artifacts rather than dialectal robustness failure.
- [Evaluation of 16 detection models] Evaluation and results section: The abstract and results distinguish human-written vs. AI-generated content and report specific degradation numbers, but provide no statistical tests (e.g., significance of F1 differences, confidence intervals, or controls for transformation-induced label drift) to support that the observed gaps are attributable to dialect rather than other factors. This weakens the load-bearing inference to real-world disadvantage.
minor comments (2)
- [Abstract] Abstract: The phrasing 'first benchmark' should be qualified with citations to prior dialectal robustness studies in related tasks (e.g., sentiment, toxicity) to avoid overstatement.
- [Results tables] Table/figure captions: Ensure all tables reporting F1 scores include the exact number of samples per dialect category and the baseline SAE performance for direct comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline revisions to strengthen the presentation of our results while preserving the core contributions of the DIA-HARM benchmark.
read point-by-point responses
-
Referee: [D3 corpus construction] Corpus construction / D3 creation section: The central claim that detectors 'systematically disadvantage' non-SAE speakers rests on performance drops observed after Multi-VALUE transformations. No quantitative validation (human naturalness ratings, semantic equivalence checks against authentic dialect corpora, or label-preservation verification) is reported for the 50 dialects. If transformations introduce unnatural phrasing or alter surface cues that models rely on, the measured F1 gaps (1.4-3.6% and >33%) may reflect artifacts rather than dialectal robustness failure.
Authors: We appreciate the referee's emphasis on corpus validity. The D3 corpus relies on Multi-VALUE transformations, which were previously validated in the source work for linguistic fidelity, naturalness, and semantic preservation across English dialects through expert linguistic review and human judgments. We did not replicate new human evaluations here to focus on the downstream detection task, but we will add explicit citations to those prior validations, a dedicated paragraph discussing their scope, and a brief acknowledgment that our results inherit the strengths and limitations of the transformation framework. Label preservation follows from the design of the transformations (surface-form changes that retain propositional content), and we will note this explicitly. We agree that fresh verification would be ideal and will include it as a limitation if space allows. revision: partial
-
Referee: [Evaluation of 16 detection models] Evaluation and results section: The abstract and results distinguish human-written vs. AI-generated content and report specific degradation numbers, but provide no statistical tests (e.g., significance of F1 differences, confidence intervals, or controls for transformation-induced label drift) to support that the observed gaps are attributable to dialect rather than other factors. This weakens the load-bearing inference to real-world disadvantage.
Authors: We agree that statistical support would strengthen the claims. In the revised manuscript we will add (1) bootstrap-derived 95% confidence intervals for all reported F1 scores, (2) paired statistical tests (Wilcoxon signed-rank) comparing original vs. dialectal performance per model and dialect group, and (3) a small-scale manual audit of 200 transformed samples to quantify any label drift introduced by the transformations. These additions will be placed in the evaluation section and will directly address whether the observed gaps exceed what could be expected from sampling variation or transformation artifacts. revision: yes
Circularity Check
No circularity: empirical benchmark evaluation with external dependencies
full rationale
The paper constructs the D3 corpus by applying Multi-VALUE transformations (an external prior method) to established disinformation benchmarks and then measures performance of 16 detection models across dialects. No mathematical derivations, equations, or 'predictions' are present that reduce by construction to fitted parameters or self-referential definitions. Central claims rest on observed F1 scores and cross-dialect transfer metrics, which are directly falsifiable via independent replication on the released corpus rather than being forced by internal definitions or self-citation chains. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linguistically grounded transformations from Multi-VALUE produce valid dialectal variants that preserve the original disinformation label.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2006.00885 (2020)
Generating natural language adversarial ex- amples. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2890–2896, Brussels, Belgium. Association for Computational Linguistics. Nida Aslam, Irfan Ullah Khan, Farah Salem Alotaibi, Lama Abdulaziz Aldaej, and Asma Khaled Al- dubaikil. 2021. Fake detect: A deep learn...
-
[2]
Nirosh Jayakody, Azeem Mohammad, and Malka N Halgamuge
Robust fake news detection over time and attack.ACM Transactions on Intelligent Systems and Technology, 11(1). Nirosh Jayakody, Azeem Mohammad, and Malka N Halgamuge. 2022. Fake news detection using a de- centralized deep learning model and federated learn- ing. InIECON 2022 – 48th Annual Conference of the IEEE Industrial Electronics Society, pages 1–6. I...
work page 2022
-
[3]
InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 7226–7245, Singapore
Quantifying the dialect gap and its correlates across languages. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 7226–7245, Singapore. Association for Computa- tional Linguistics. Vijay Keswani and L Elisa Celis. 2021. Dialect diversity in text summarization on twitter. InProceedings of the web conference 2021, pages 3802–38...
work page 2023
-
[4]
Hu Linmei, Tianchi Yang, Chuan Shi, Houye Ji, and Xiaoli Li
Mm-covid: A multilingual and multimodal data repository for combating covid-19 disinforma- tion.Preprint, arXiv:2011.04088. Chin-Yew Lin. 2004. ROUGE: A package for auto- matic evaluation of summaries. InText Summariza- tion Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics. Hanmeng Liu, Ruoxi Ning, Zhiyang Teng, Jian ...
-
[5]
Fighting fire with fire: The dual role of LLMs in crafting and detecting elusive disinformation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 14279–14305, Singapore. Association for Compu- tational Linguistics. Jason S. Lucas, Barani Maung Maung, Maryam Tabar, Keegan McBride, and Dongwon Lee. 2024. The l...
work page 2023
-
[6]
Rejected dialects: Biases against african amer- ican language in reward models. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 7468–7487. Van-Hoang Nguyen, Kazunari Sugiyama, Preslav Nakov, and Min-Yen Kan. 2020. FANG: Leveraging social context for fake news detection using graph representation. InProceedings of the 29th AC...
-
[7]
AlignScore: Evaluating factual consistency with a unified alignment function. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11328–11348, Toronto, Canada. Association for Computational Linguistics. Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2020. B...
-
[8]
SAE-trained metrics encode SAE grammat- ical norms, treating deviations as errors rather than valid variation
-
[9]
SAE-adjacent dialects suffer disproportion- atelybecause their subtle features are inter- preted as noise or mistakes
-
[10]
Strict filtering would create SAE-biased benchmarksby systematically excluding va- rieties closest to SAE. Our lenient thresholds preserve the full spectrum of dialectal variation, enabling evaluation of de- tector robustness across both SAE-adjacent and SAE-distant varieties. This design choice is itself a methodological contribution: future dialect benc...
work page 2023
-
[11]
Over-flagging dominates.Dialect-induced false positives outnumber false negatives 6.5:1 (27,020 vs. 4,169). The primary harm is that authentic dialectal speech, including legitimate public health information and political dis- course, is systematically flagged as disinforma- tion
-
[12]
Morphological markers are the primary trig- ger.The most frequent false-positive mech- anism is dialectal morphology: pluralthem- suffixing,a-prefixing, and non-standard deter- miner use create surface tokens that models have learned to associate with fabricated content, likely because such patterns are absent from SAE-dominated training data
-
[13]
Short-form content is most vulnerable.Twit- ter posts account for 71.7% of false positives despite representing only 33% of the test data. In shorter texts, dialectal features constitute a larger fraction of total tokens, amplifying their influence on model representations
-
[14]
Morphosyntactically distant dialects are most affected.Fiji (Basilectal), Rural AA VE, and Bahamian English rank highest for over- flagging, while closer varieties (SE England, Chicano) show fewer errors, consistent with a linguistic-distance gradient
-
[15]
Errors are confidently wrong, not uncer- tain.81.4% of false positives and 75.5% of false negatives are made with >0.95 confidence. RoBERTa achieves 99.5% mean confidence on false positives, ruling out calibration-based fixes and indicating that dialectal features are en- coded as class-discriminative in the learned rep- resentations
-
[16]
Disinformation evasion targets specific do- mains.False negatives concentrate in political fact-checking (LIAR, 32.0%) and COVID misin- formation (MMCOVID, 58.5%), with TextCNN as the most vulnerable model (24.9% of all FNs). This suggests that dialectal transfor- mation of topical disinformation can exploit domain-specific detection heuristics. P Prompt ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.