Recognition: no theorem link
Geometrical Cross-Attention and Nonvoid Voxelization for Efficient 3D Medical Image Segmentation
Pith reviewed 2026-05-10 20:03 UTC · model grok-4.3
The pith
GCNV-Net achieves state-of-the-art 3D medical image segmentation accuracy with over 50 percent less computation by focusing on informative voxels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GCNV-Net integrates the Tri-directional Dynamic Nonvoid Voxel Transformer (3DNVT) that dynamically partitions voxels along transverse, sagittal, and coronal planes, the Geometrical Cross-Attention (GCA) module that incorporates geometric positional information during multi-scale feature fusion, and Nonvoid Voxelization to process only informative regions, delivering state-of-the-art segmentation on BraTS2021, ACDC, MSD Prostate, MSD Pancreas, and AMOS2022 while reducing FLOPs by 56.13 percent and inference latency by 68.49 percent.
What carries the argument
The Tri-directional Dynamic Nonvoid Voxel Transformer (3DNVT) together with the Geometrical Cross-Attention (GCA) module, supported by Nonvoid Voxelization that retains only informative regions.
Load-bearing premise
Nonvoid voxelization can reliably detect and keep every voxel needed for accurate boundaries even in low-contrast or unusual anatomies.
What would settle it
A new test set containing many subtle low-contrast boundaries where GCNV-Net misses critical edges that a dense full-voxel baseline captures accurately.
Figures











read the original abstract
Accurate segmentation of 3D medical scans is crucial for clinical diagnostics and treatment planning, yet existing methods often fail to achieve both high accuracy and computational efficiency across diverse anatomies and imaging modalities. To address these challenges, we propose GCNV-Net, a novel 3D medical segmentation framework that integrates a Tri-directional Dynamic Nonvoid Voxel Transformer (3DNVT), a Geometrical Cross-Attention module (GCA), and Nonvoid Voxelization. The 3DNVT dynamically partitions relevant voxels along the three orthogonal anatomical planes, namely the transverse, sagittal, and coronal planes, enabling effective modeling of complex 3D spatial dependencies. The GCA mechanism explicitly incorporates geometric positional information during multi-scale feature fusion, significantly enhancing fine-grained anatomical segmentation accuracy. Meanwhile, Nonvoid Voxelization processes only informative regions, greatly reducing redundant computation without compromising segmentation quality, and achieves a 56.13% reduction in FLOPs and a 68.49% reduction in inference latency compared to conventional voxelization. We evaluate GCNV-Net on multiple widely used benchmarks: BraTS2021, ACDC, MSD Prostate, MSD Pancreas, and AMOS2022. Our method achieves state-of-the-art segmentation performance across all datasets, outperforming the best existing methods by 0.65% on Dice, 0.63% on IoU, 1% on NSD, and relatively 14.5% on HD95. All results demonstrate that GCNV-Net effectively balances accuracy and efficiency, and its robustness across diverse organs, disease conditions, and imaging modalities highlights strong potential for clinical deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GCNV-Net, a 3D medical image segmentation framework that integrates a Tri-directional Dynamic Nonvoid Voxel Transformer (3DNVT) for modeling spatial dependencies along transverse, sagittal, and coronal planes, a Geometrical Cross-Attention (GCA) module to incorporate geometric positional information during multi-scale feature fusion, and Nonvoid Voxelization to process only informative regions. It evaluates the method on BraTS2021, ACDC, MSD Prostate, MSD Pancreas, and AMOS2022, claiming state-of-the-art performance with average gains of 0.65% Dice, 0.63% IoU, 1% NSD, and 14.5% relative HD95 over prior best methods, plus 56.13% FLOPs and 68.49% latency reductions.
Significance. If the results hold under scrutiny, the work could be significant for advancing efficient 3D segmentation in clinical settings by addressing the accuracy-efficiency trade-off across diverse anatomies and modalities. The directional transformer and geometric attention ideas, combined with selective voxelization, offer a concrete path to lower computational demands while maintaining or improving boundary accuracy, and the multi-benchmark evaluation provides a reasonable test of generalizability.
major comments (2)
- [§3] §3 (Nonvoid Voxelization): No equation, threshold, or pseudocode is given for the criterion that identifies 'informative' or 'nonvoid' voxels. This is load-bearing for the central claims because both the 56.13% FLOPs reduction and the assertion that segmentation quality is preserved (including on low-contrast boundaries and small lesions) depend on this step being lossless on the exact datasets where the 0.65% Dice and 14.5% HD95 margins are reported. Without the explicit rule, performance gains cannot be unambiguously attributed to 3DNVT or GCA rather than to the voxel-selection heuristic.
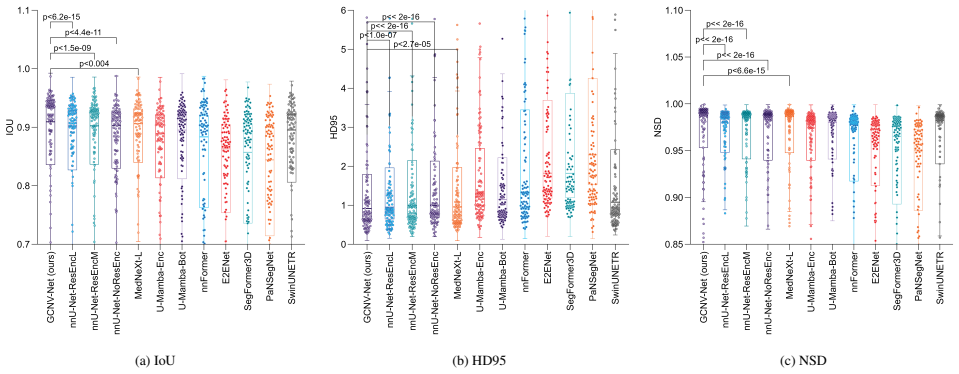
- [§4] §4 (Results tables): The reported SOTA margins are small (0.65% Dice, 0.63% IoU). The manuscript does not report statistical significance tests, standard deviations across runs, or cross-validation details for any of the five datasets. This weakens the ability to judge whether the gains are robust or could be explained by random variation or dataset-specific tuning.
minor comments (2)
- [Abstract] The abstract's phrasing 'relatively 14.5% on HD95' should be clarified as relative improvement to avoid ambiguity.
- [§3.1] Notation for the tri-directional partitioning in 3DNVT would be clearer with an explicit diagram or equation showing how voxels are dynamically selected along each plane.
Simulated Author's Rebuttal
We thank the referee for their thorough and constructive review of our manuscript. We appreciate the opportunity to clarify the details of our Nonvoid Voxelization approach and to enhance the statistical analysis of our experimental results. Below, we provide point-by-point responses to the major comments and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Nonvoid Voxelization): No equation, threshold, or pseudocode is given for the criterion that identifies 'informative' or 'nonvoid' voxels. This is load-bearing for the central claims because both the 56.13% FLOPs reduction and the assertion that segmentation quality is preserved (including on low-contrast boundaries and small lesions) depend on this step being lossless on the exact datasets where the 0.65% Dice and 14.5% HD95 margins are reported. Without the explicit rule, performance gains cannot be unambiguously attributed to 3DNVT or GCA rather than to the voxel-selection heuristic.
Authors: We agree that the manuscript should have included an explicit mathematical description and implementation details for the nonvoid voxel identification criterion, as this is fundamental to validating our efficiency and accuracy claims. The original submission described the concept at a high level but did not provide the necessary equations or pseudocode. In the revised manuscript, we will expand §3 to include the precise criterion for selecting informative voxels (including any thresholds and conditions used), along with pseudocode for the Nonvoid Voxelization procedure. This will allow the community to fully reproduce our results and confirm that the performance improvements stem from the proposed 3DNVT and GCA components rather than the voxel selection alone. revision: yes
-
Referee: [§4] §4 (Results tables): The reported SOTA margins are small (0.65% Dice, 0.63% IoU). The manuscript does not report statistical significance tests, standard deviations across runs, or cross-validation details for any of the five datasets. This weakens the ability to judge whether the gains are robust or could be explained by random variation or dataset-specific tuning.
Authors: We concur that for modest performance margins, it is essential to provide evidence of statistical significance and variability to support the robustness of the claims. The original manuscript presented average metric improvements without accompanying standard deviations or formal statistical tests. In the revised version, we will report results with mean and standard deviation from multiple training runs using different random seeds. Furthermore, we will include cross-validation details where feasible and conduct statistical significance tests (such as the Wilcoxon signed-rank test or paired t-tests) to compare our method against the top-performing baselines, including p-values. These additions will demonstrate that the observed gains are consistent and unlikely due to random variation. revision: yes
Circularity Check
No circularity: empirical results on external benchmarks
full rationale
The paper introduces architectural components (3DNVT, GCA, Nonvoid Voxelization) and reports segmentation metrics on standard public datasets (BraTS2021, ACDC, MSD Prostate, MSD Pancreas, AMOS2022). Performance numbers are presented as direct empirical outcomes rather than derived predictions or first-principles results. No equations, fitted parameters, or self-citations are used to claim that any output is forced by construction from the inputs. The efficiency gains and accuracy margins are therefore independent of any definitional loop.
Axiom & Free-Parameter Ledger
invented entities (3)
-
Tri-directional Dynamic Nonvoid Voxel Transformer (3DNVT)
no independent evidence
-
Geometrical Cross-Attention module (GCA)
no independent evidence
-
Nonvoid Voxelization
no independent evidence
Reference graph
Works this paper leans on
-
[1]
B. H. Menze, A. Jakab, S. Bauer, J. Kalpathy-Cramer, K. Farahani, J. Kirby, Y . Burren, N. Porz, J. Slotboom, R. Wiest, et al., The multimodal brain tumor image seg- mentation benchmark (brats), IEEE transactions on medi- cal imaging 34 (10) (2014) 1993–2024
2014
-
[2]
Ronneberger, P
O. Ronneberger, P. Fischer, T. Brox, U-net: Convolutional networks for biomedical image segmentation, in: Medi- cal image computing and computer-assisted intervention– MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18, Springer, 2015, pp. 234–241
2015
-
[3]
Çiçek, A
Ö. Çiçek, A. Abdulkadir, S. S. Lienkamp, T. Brox, O. Ronneberger, 3d u-net: learning dense volumet- ric segmentation from sparse annotation, in: Medical Image Computing and Computer-Assisted Intervention– MICCAI 2016: 19th International Conference, Athens, Greece, October 17-21, 2016, Proceedings, Part II 19, Springer, 2016, pp. 424–432
2016
-
[4]
Attention U-Net: Learning Where to Look for the Pancreas
O. Oktay, J. Schlemper, L. L. Folgoc, M. Lee, M. Hein- rich, K. Misawa, K. Mori, S. McDonagh, N. Y . Hammerla, B. Kainz, et al., Attention u-net: Learning where to look for the pancreas, arXiv preprint arXiv:1804.03999 (2018)
work page internal anchor Pith review arXiv 2018
-
[5]
Isensee, P
F. Isensee, P. F. Jaeger, S. A. Kohl, J. Petersen, K. H. Maier-Hein, nnu-net: a self-configuring method for deep learning-based biomedical image segmentation, Nature methods 18 (2) (2021) 203–211
2021
-
[6]
Hatamizadeh, Y
A. Hatamizadeh, Y . Tang, V . Nath, D. Yang, A. Myro- nenko, B. Landman, H. R. Roth, D. Xu, Unetr: Trans- formers for 3d medical image segmentation, in: Proceed- ings of the IEEE/CVF winter conference on applications of computer vision, 2022, pp. 574–584
2022
-
[7]
Hatamizadeh, V
A. Hatamizadeh, V . Nath, Y . Tang, D. Yang, H. R. Roth, D. Xu, Swin unetr: Swin transformers for semantic seg- mentation of brain tumors in mri images, in: International MICCAI brainlesion workshop, Springer, 2021, pp. 272– 284
2021
-
[8]
Wenxuan, C
W. Wenxuan, C. Chen, D. Meng, Y . Hong, Z. Sen, L. Jiangyun, Transbts: Multimodal brain tumor segmen- tation using transformer, in: International Conference on Medical Image Computing and Computer-Assisted Inter- vention, Springer, 2021, pp. 109–119
2021
-
[9]
H.-Y . Zhou, J. Guo, Y . Zhang, X. Han, L. Yu, L. Wang, Y . Yu, nnformer: volumetric medical image segmentation via a 3d transformer, IEEE transactions on image process- ing 32 (2023) 4036–4045
2023
-
[10]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al., An image is worth 16x16 words: Transformers for image recognition at scale, arXiv preprint arXiv:2010.11929 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[11]
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, Y . Liu, Ro- former: Enhanced transformer with rotary position em- bedding, Neurocomputing 568 (2024) 127063
2024
-
[12]
Y . Xie, J. Zhang, C. Shen, Y . Xia, Cotr: Efficiently bridging cnn and transformer for 3d medical image seg- mentation, in: Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International 11 Conference, Strasbourg, France, September 27–October 1, 2021, Proceedings, Part III 24, Springer, 2021, pp. 171– 180
2021
- [13]
- [14]
-
[15]
Perera, P
S. Perera, P. Navard, A. Yilmaz, Segformer3d: an effi- cient transformer for 3d medical image segmentation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 4981–4988
2024
-
[16]
B. Wu, Q. Xiao, S. Liu, L. Yin, M. Pechenizkiy, D. C. Mocanu, M. Keulen, E. Mocanu, E2enet: Dynamic sparse feature fusion for accurate and efficient 3d medical image segmentation, Advances in Neural Information Process- ing Systems 37 (2024) 118483–118512
2024
-
[17]
Z. Zhu, M. Sun, G. Qi, Y . Li, X. Gao, Y . Liu, Sparse dynamic volume transunet with multi-level edge fusion for brain tumor segmentation, Computers in Biology and Medicine (2024) 108284
2024
-
[18]
X. Zhu, W. Su, L. Lu, B. Li, X. Wang, J. Dai, Deformable detr: Deformable transformers for end-to-end object de- tection, arXiv preprint arXiv:2010.04159 (2020)
work page internal anchor Pith review arXiv 2010
-
[19]
H. Zhao, L. Jiang, J. Jia, P. H. Torr, V . Koltun, Point trans- former, in: Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 16259–16268
2021
-
[20]
Graham, M
B. Graham, M. Engelcke, L. Van Der Maaten, 3d seman- tic segmentation with submanifold sparse convolutional networks, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 9224– 9232
2018
-
[21]
C. Choy, J. Gwak, S. Savarese, 4d spatio-temporal con- vnets: Minkowski convolutional neural networks, in: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 3075–3084
2019
-
[22]
H. Tang, Z. Liu, S. Zhao, Y . Lin, J. Lin, H. Wang, S. Han, Searching efficient 3d architectures with sparse point- voxel convolution, in: European conference on computer vision, Springer, 2020, pp. 685–702
2020
-
[23]
H. Wang, C. Shi, S. Shi, M. Lei, S. Wang, D. He, B. Schiele, L. Wang, Dsvt: Dynamic sparse voxel trans- former with rotated sets, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 13520–13529
2023
-
[24]
Kolodiazhnyi, A
M. Kolodiazhnyi, A. V orontsova, A. Konushin, D. Rukhovich, Oneformer3d: One transformer for unified point cloud segmentation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 20943–20953
2024
-
[25]
M. Antonelli, A. Reinke, S. Bakas, et al., The medical segmentation decathlon, Nature Communications (2022). doi:10.1038/s41467-022-30695-9
-
[26]
U. Baid, S. Ghodasara, S. Mohan, M. Bilello, E. Cal- abrese, E. Colak, K. Farahani, J. Kalpathy-Cramer, F. C. Kitamura, S. Pati, L. M. Prevedello, J. D. Rudie, C. Sako, R. T. Shinohara, T. Bergquist, R. Chai, J. Eddy, J. El- liott, W. Reade, T. Schaffter, T. Yu, J. Zheng, A. W. Moawad, L. O. Coelho, O. McDonnell, E. Miller, F. E. Moron, M. C. Oswood, R. Y...
work page internal anchor Pith review arXiv 2021
-
[27]
O. Bernard, A. Lalande, C. Zotti, F. Cervenansky, X. Yang, P.-A. Heng, I. Cetin, K. Lekadir, O. Ca- mara, M. A. Gonzalez Ballester, G. Sanroma, S. Napel, S. Petersen, G. Tziritas, E. Grinias, M. Khened, V . A. Kollerathu, G. Krishnamurthi, M.-M. Rohé, X. Pennec, M. Sermesant, F. Isensee, P. Jäger, K. H. Maier-Hein, P. M. Full, I. Wolf, S. Engelhardt, C. F...
-
[28]
S. Duchesne, L. Dieumegarde, I. Chouinard, F. Farokhian, A. Badhwar, P. Bellec, P. T ˘00e9trault, M. Descoteaux, C. Beaulieu, O. Potvin, Structural and functional multi- platform mri series of a single human volunteer over more than fifteen years, Scientific Data 6 (2019) 245. doi:10.1038/s41597-019-0262-8. 12
-
[29]
J. W. van der Graaf, M. L. van Hooff, C. F. Buckens, M. Rutten, J. L. van Susante, R. J. Kroeze, M. de Kleuver, B. van Ginneken, N. Lessmann, Lumbar spine segmenta- tion in mr images: a dataset and a public benchmark, Sci- entific Data 11 (2024). doi:10.1038/s41597-024-03090-w
-
[30]
M. R. Hernandez Petzsche, E. de la Rosa, U. Hanning, R. Wiest, W. Valenzuela, M. Reyes, M. Meyer, S.-L. Liew, F. Kofler, I. Ezhov, et al., Isles 2022: A multi-center magnetic resonance imaging stroke lesion segmentation dataset, Scientific data 9 (1) (2022) 762
2022
-
[31]
A. L. Simpson, M. Antonelli, S. Bakas, M. Bilello, K. Farahani, B. van Ginneken, A. Kopp-Schneider, B. A. Landman, G. Litjens, B. Menze, O. Ronneberger, R. M. Summers, P. Bilic, P. F. Christ, R. K. G. Do, M. Gollub, J. Golia-Pernicka, S. H. Heckers, W. R. Jarnagin, M. K. McHugo, S. Napel, E. V orontsov, L. Maier-Hein, M. J. Cardoso, A large annotated medi...
work page Pith review arXiv 2019
-
[32]
D. Jiang, W. Dou, L. V osters, X. Xu, Y . Sun, T. Tan, Denoising of 3d magnetic resonance images with multi- channel residual learning of convolutional neural net- work, Japanese Journal of Radiology 36 (2018) 566–574. doi:10.1007/s11604-018-0758-8
-
[33]
X. Zhao, Y . Liao, J. Xie, X. He, S. Zhang, M. Li, R. Chen, F. Wang, Breastdm: A dce-mri dataset for breast tumor image segmentation and classification, Computers in Biology and Medicine 157 (2023) 107255. doi:10.1016/j.compbiomed.2023.107255. URLhttps://doi.org/10.1016/j.compbiomed.2023.107255
- [34]
-
[35]
Zhang, E
Z. Zhang, E. Keles, G. Durak, Y . Taktak, O. Susladkar, V . Gorade, D. Jha, A. C. Ormeci, A. Medetalibeyoglu, L. Yao, et al., Large-scale multi-center ct and mri seg- mentation of pancreas with deep learning, Medical image analysis 99 (2025) 103382
2025
- [36]
-
[37]
Segmentation Results To complement the segmentation performance summaries reported in the main manuscript, this section presents a de- tailed per-class quantitative analysis across five benchmark datasets: BraTS2021, ACDC, MSD Prostate, MSD Pancreas, and AMOS2022. By reporting Dice, IoU, HD95, and NSD for individual anatomical structures, these results pr...
-
[38]
2 provides additional qualitative comparisons across all evaluated datasets
Qualitative Visualization Results In addition to the representative examples shown in the main manuscript, Fig. 2 provides additional qualitative comparisons across all evaluated datasets. On BraTS2021, GCNV-Net more accurately delineates irreg- ular and heterogeneous tumor subregions, particularly for en- hancing tumor areas, where competing methods ofte...
-
[39]
Radar Chart Details To jointly evaluate segmentation quality and computational efficiency, radar charts are constructed using normalized Dice, IoU, HD95, NSD, memory consumption, FLOPs, latency, and parameter size. For a given segmentation methodmwith Dice scoreDice m (the greater the better) and FLOPsFLOPs m (the smaller the better), we define their norm...
-
[40]
Specifically, dataset fingerprint- ing, target spacing, resampling, and intensity normaliza- tion are all determined by nnU-Net’s automated preprocess- ing
Training Details All experiments are implemented within the nnU-Net v2 framework (v2.5.1 codebase), following its standard 3D full-resolution pipeline. Specifically, dataset fingerprint- ing, target spacing, resampling, and intensity normaliza- tion are all determined by nnU-Net’s automated preprocess- ing. During training, patch-based online sampling and...
-
[41]
(2) of the main manuscript determines whether an embedded voxel is classified as nonvoid or void
Analysis on Hyperparameter Sensitivity of Nonvoid Vox- elization The occupancy thresholdϵin Eq. (2) of the main manuscript determines whether an embedded voxel is classified as nonvoid or void. As discussed in Section 3.1,ϵis designed to serve as a numerical guard against floating-point rounding rather than a tunable hyperparameter. To empirically verify ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.