A Unified Foundation Model for All-in-One Multi-Modal Remote Sensing Image Restoration and Fusion with Language Prompting
Pith reviewed 2026-05-10 18:29 UTC · model grok-4.3
The pith
LLaRS provides a single foundation model for handling eleven remote sensing restoration and fusion tasks using language prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLaRS is presented as the first unified foundation model for multi-modal and multi-task remote sensing low-level vision. It aligns heterogeneous bands using Sinkhorn-Knopp optimal transport, routes features via three complementary mixture-of-experts layers for spatial patterns, spectral fidelity, and global context with low-rank adapters, and stabilizes training with step-level dynamic weight adjustment. Trained on the LLaRS1M dataset with eleven tasks and language prompts, it consistently outperforms seven competitive models and shows strong transfer capability through parameter-efficient finetuning on unseen data.
What carries the argument
The LLaRS architecture, which uses Sinkhorn-Knopp optimal transport for band alignment combined with three complementary mixture-of-experts layers and dynamic weighting for joint multi-task optimization.
If this is right
- LLaRS can replace multiple task-specific models for remote sensing image restoration and fusion.
- It achieves better performance than seven existing competitive models across the tasks.
- Parameter-efficient finetuning enables effective adaptation to new data and unseen tasks.
- The use of language prompts allows flexible control over the restoration process.
- Joint training on the LLaRS1M dataset supports consistent performance without major trade-offs between tasks.
Where Pith is reading between the lines
- Operational remote sensing systems could integrate this model to reduce the complexity of handling diverse degradation types in a single pipeline.
- Natural language interfaces might enable users without deep technical expertise to request specific image enhancements directly.
- The band alignment technique could be tested for applicability in other multi-spectral domains such as hyperspectral medical imaging.
- Further scaling of the model size or dataset might lead to even broader generalization across sensors and conditions.
Load-bearing premise
The combination of Sinkhorn-Knopp band alignment, three complementary MoE layers, and step-level dynamic weighting can jointly optimize across eleven heterogeneous restoration tasks without requiring separate models due to performance trade-offs.
What would settle it
If separate models trained individually for each of the eleven tasks outperform LLaRS on a standard benchmark test set, or if LLaRS shows degraded performance on some tasks compared to specialized approaches, the unified model's advantage would be disproven.
Figures




















read the original abstract
Remote sensing imagery suffers from clouds, haze, noise, resolution limits, and sensor heterogeneity. Existing restoration and fusion approaches train separate models per degradation type. In this work, we present Language-conditioned Large-scale Remote Sensing restoration model (LLaRS), the first unified foundation model for multi-modal and multi-task remote sensing low-level vision. LLaRS employs Sinkhorn-Knopp optimal transport to align heterogeneous bands into semantically matched slots, routes features through three complementary mixture-of-experts layers (convolutional experts for spatial patterns, channel-mixing experts for spectral fidelity, and attention experts with low-rank adapters for global context), and stabilizes joint training via step-level dynamic weight adjustment. To train LLaRS, we construct LLaRS1M, a million-scale multi-task dataset spanning eleven restoration and enhancement tasks, integrating real paired observations and controlled synthetic degradations with diverse natural language prompts. Experiments show LLaRS consistently outperforms seven competitive models, and parameter-efficient finetuning experiments demonstrate strong transfer capability and adaptation efficiency on unseen data. Repo: https://github.com/yc-cui/LLaRS
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LLaRS, the first unified foundation model for multi-modal and multi-task remote sensing low-level vision tasks including restoration and fusion. It employs Sinkhorn-Knopp optimal transport for aligning heterogeneous bands, routes features through three complementary mixture-of-experts layers (convolutional for spatial patterns, channel-mixing for spectral fidelity, and attention with low-rank adapters for global context), and uses step-level dynamic weight adjustment for stable joint training. A new million-scale dataset LLaRS1M is constructed covering eleven tasks with real and synthetic degradations plus language prompts. Experiments claim consistent outperformance over seven competitive models and strong transfer via parameter-efficient finetuning on unseen data.
Significance. If the empirical results hold, the work is significant for establishing a single model capable of handling eleven heterogeneous remote sensing restoration and fusion tasks without task-specific retraining, supported by a large-scale multi-task dataset and an architecture designed for joint optimization. This could reduce the proliferation of separate models in the field and enable more efficient adaptation through language prompting and PEFT, advancing foundation-model approaches in remote sensing low-level vision.
major comments (2)
- [§4] §4 (Experiments) and associated tables: the central claim of consistent outperformance and absence of task-specific trade-offs relies on quantitative comparisons across all eleven tasks, but the reported results must include per-task metrics, ablation on the three MoE branches plus dynamic weighting, and direct comparison to task-specific baselines trained on the same LLaRS1M data to confirm no negative transfer occurs.
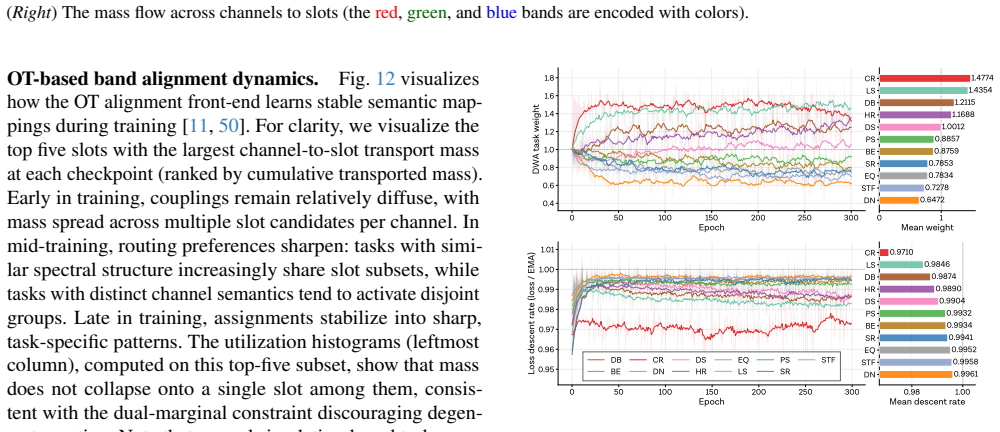
- [§3.2] §3.2 (Architecture): the step-level dynamic weight adjustment is presented as stabilizing joint training, but the paper should provide the exact formulation of the weighting parameters and demonstrate via ablation that they are not merely fitting to the training distribution in a way that reduces the claimed generality.
minor comments (3)
- [Figure 1] Figure 1 and §3: the diagram of the three MoE layers and Sinkhorn-Knopp alignment would benefit from clearer annotation of input/output dimensions and how language prompts are injected at each stage.
- [§5] §5 (Transfer experiments): the parameter-efficient finetuning results on unseen data should report the number of trainable parameters and adaptation steps for transparency.
- [References] References: several recent works on multi-task remote sensing restoration and MoE in vision are missing; add citations to ensure the positioning against prior unified models is complete.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. The points raised strengthen the empirical support for our claims of unified multi-task performance and the role of the dynamic weighting mechanism. We address each major comment below.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and associated tables: the central claim of consistent outperformance and absence of task-specific trade-offs relies on quantitative comparisons across all eleven tasks, but the reported results must include per-task metrics, ablation on the three MoE branches plus dynamic weighting, and direct comparison to task-specific baselines trained on the same LLaRS1M data to confirm no negative transfer occurs.
Authors: We agree that per-task metrics and targeted ablations are necessary to fully substantiate the absence of task-specific trade-offs. The submitted manuscript reported aggregated metrics to highlight overall trends; in the revision we will add complete per-task tables for all eleven tasks. We will also include ablations isolating each of the three MoE branches (convolutional, channel-mixing, and attention with low-rank adapters) and the dynamic weighting component. In addition, we will train task-specific baselines on the identical LLaRS1M data and report direct comparisons, thereby confirming that joint training yields no negative transfer relative to specialized models. revision: yes
-
Referee: [§3.2] §3.2 (Architecture): the step-level dynamic weight adjustment is presented as stabilizing joint training, but the paper should provide the exact formulation of the weighting parameters and demonstrate via ablation that they are not merely fitting to the training distribution in a way that reduces the claimed generality.
Authors: We will insert the exact mathematical formulation of the step-level dynamic weight adjustment, including the update rules for the weighting parameters, into §3.2. To address the concern about potential overfitting, we will add an ablation that trains the model both with and without dynamic weighting. Performance will be reported on held-out validation splits of LLaRS1M as well as on completely unseen tasks and data distributions. These results will show that the mechanism improves training stability while maintaining or improving generalization, rather than trading generality for in-distribution fit. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an empirical architecture for a unified remote sensing restoration model using standard components (Sinkhorn-Knopp alignment, mixture-of-experts layers, dynamic weighting) trained on a newly constructed million-scale dataset LLaRS1M. No equations, derivations, or self-referential definitions are provided that reduce claimed performance or unification to fitted parameters or prior self-citations by construction. Central claims rest on experimental outperformance and transfer results rather than internal circular logic.
Axiom & Free-Parameter Ledger
free parameters (1)
- step-level dynamic weight adjustment parameters
Reference graph
Works this paper leans on
-
[1]
SatlasPretrain: A large-scale dataset for remote sensing image understanding
Favyen Bastani, Piper Wolters, Ritwik Gupta, Joe Ferdinando, and Aniruddha Kembhavi. SatlasPretrain: A large-scale dataset for remote sensing image understanding. InICCV, pages 16726–16736, 2023. 2
work page 2023
-
[2]
BitFit: Simple parameter-efficient fine-tuning for transformer-based masked language-models
Elad Ben Zaken, Yoav Goldberg, and Shauli Ravfogel. BitFit: Simple parameter-efficient fine-tuning for transformer-based masked language-models. InACL, pages 1–9, Dublin, Ireland,
-
[3]
Association for Computational Linguistics. 7
-
[4]
Unsupervised learn- ing of visual features by contrasting cluster assignments
Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, and Armand Joulin. Unsupervised learn- ing of visual features by contrasting cluster assignments. In NeurIPS, pages 9912–9924, 2020. 2
work page 2020
-
[5]
Pre-trained image processing transformer
Hanting Chen, Yunhe Wang, Tianyu Guo, Chang Xu, Yiping Deng, Zhenhua Liu, Siwei Ma, Chunjing Xu, Chao Xu, and Wen Gao. Pre-trained image processing transformer. In CVPR, pages 12294–12305, 2021. 2
work page 2021
-
[6]
Dynamic convolution: Attention over convolution kernels
Yinpeng Chen, Xiyang Dai, Mengchen Liu, Dongdong Chen, Lu Yuan, and Zicheng Liu. Dynamic convolution: Attention over convolution kernels. InCVPR, pages 11030–11039,
-
[7]
GradNorm: Gradient normalization for adaptive loss balancing in deep multitask networks
Zhao Chen, Vijay Badrinarayanan, Chen-Yu Lee, and Andrew Rabinovich. GradNorm: Gradient normalization for adaptive loss balancing in deep multitask networks. InICML, pages 794–803. PMLR, 2018. 15
work page 2018
-
[8]
Kaichen Chi, Yuan Yuan, and Qi Wang. Trinity-Net: Gradient- guided swin transformer-based remote sensing image dehaz- ing and beyond.IEEE Trans. Geosci. Remote Sens., 61:1–14,
-
[9]
Conde, Gregor Geigle, and Radu Timofte
Marcos V . Conde, Gregor Geigle, and Radu Timofte. In- structIR: High-quality image restoration following human instructions. InECCV, page 1–21, Berlin, Heidelberg, 2024. Springer-Verlag. 1, 2
work page 2024
-
[10]
Yezhen Cong, Samar Khanna, Chenlin Meng, Patrick Liu, Erik Rozi, Yutong He, Marshall Burke, David B. Lobell, and Stefano Ermon. SatMAE: Pre-training transformers for tem- poral and multi-spectral satellite imagery. InNeurIPS, Red Hook, NY , USA, 2022. Curran Associates Inc. 2
work page 2022
-
[11]
Enpowering your pansharpening models with generalizability: Unified distri- bution is all you need
Yongchuan Cui, Peng Liu, and Hui Zhang. Enpowering your pansharpening models with generalizability: Unified distri- bution is all you need. InICCV, pages 11850–11860, 2025. 1
work page 2025
-
[12]
Sinkhorn distances: Lightspeed computation of optimal transport
Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport. InNeurIPS, pages 2292–2300, 2013. 2, 3, 4, 8, 14
work page 2013
-
[13]
TerraFM: A scalable foundation model for unified multisensor earth observation.arXiv, 2025
Muhammad Sohail Danish, Muhammad Akhtar Munir, Syed Roshaan Ali Shah, Muhammad Haris Khan, Rao Muhammad Anwer, Jorma Laaksonen, Fahad Shahbaz Khan, and Salman Khan. TerraFM: A scalable foundation model for unified multisensor earth observation.arXiv, 2025. 2
work page 2025
-
[14]
ImageNet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical image database . InCVPR, pages 248–255, Los Alamitos, CA, USA, 2009. IEEE Computer Society. 2
work page 2009
-
[15]
Machine learning in pansharpening: A benchmark, from shallow to deep networks.IEEE Geosci
Liang-Jian Deng, Gemine Vivone, Mercedes E Paoletti, Giuseppe Scarpa, Jiang He, Yongjun Zhang, Jocelyn Chanus- sot, and Antonio Plaza. Machine learning in pansharpening: A benchmark, from shallow to deep networks.IEEE Geosci. Remote Sens. Mag., 10(3):279–315, 2022. 12, 13, 14
work page 2022
-
[16]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR, 2021. 2
work page 2021
-
[17]
Multisensor Data Fusion for Cloud Removal in Global and All-Season Sentinel-2 Imagery.IEEE Trans
Patrick Ebel, Andrea Meraner, Michael Schmitt, and Xiao Xi- ang Zhu. Multisensor Data Fusion for Cloud Removal in Global and All-Season Sentinel-2 Imagery.IEEE Trans. Geosci. Remote Sens., 59(7):5866–5878, 2021. 12, 13, 14
work page 2021
-
[18]
Irina V . Emelyanova, Tim R. McVicar, Thomas G. Van Niel, Ling Tao Li, and Albert I.J.M. van Dijk. Assessing the accu- racy of blending landsat–modis surface reflectances in two landscapes with contrasting spatial and temporal dynamics: A framework for algorithm selection.Remote Sens. Environ., 133:193–209, 2013. 12, 13, 14
work page 2013
-
[19]
Ro- bust SAR image despeckling by deep learning from near-real datasets.IEEE J
Jianjun Guan, Ping Zhong, Fan Zhang, and Yuhan Liu. Ro- bust SAR image despeckling by deep learning from near-real datasets.IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens., 17:3475–3487, 2024. 12, 13, 14
work page 2024
-
[20]
Xin Guo, Jiangwei Lao, Bo Dang, Yingying Zhang, Lei Yu, Lixiang Ru, Liheng Zhong, Ziyuan Huang, Kang Wu, Dingx- iang Hu, Huimei He, Jian Wang, Jingdong Chen, Ming Yang, Yongjun Zhang, and Yansheng Li. SkySense: A multi-modal remote sensing foundation model towards universal inter- pretation for earth observation imagery. InCVPR, pages 27662–27673, 2024. 2
work page 2024
-
[21]
Wasserstein wormhole: Scalable optimal transport distance with transformer
Doron Haviv, Russell Zhang Kunes, Thomas Dougherty, Cas- sandra Burdziak, Tal Nawy, Anna Gilbert, and Dana Pe’er. Wasserstein wormhole: Scalable optimal transport distance with transformer. InICML, pages 17697–17718. PMLR, 2024. 2
work page 2024
-
[22]
Diffusion models in low-level vision: A survey, 2024
Chunming He, Yuqi Shen, Chengyu Fang, Fengyang Xiao, Longxiang Tang, Yulun Zhang, Wangmeng Zuo, Zhenhua Guo, and Xiu Li. Diffusion models in low-level vision: A survey, 2024. 1
work page 2024
-
[23]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InCVPR, pages 770–778, 2016. 13
work page 2016
-
[24]
Parameter-efficient transfer learning for NLP
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for NLP. InICML, pages 2790–2799. PMLR, 2019. 7
work page 2019
-
[25]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InICLR,
-
[26]
Binghui Huang, Li Zhi, Chao Yang, Fuchun Sun, and Yixu Song. Single satellite optical imagery dehazing using sar image prior based on conditional generative adversarial net- works. InWACV, pages 1806–1813, 2020. 12, 13, 14
work page 2020
-
[27]
Transformer fusion with optimal transport
Moritz Imfeld, Jacopo Graldi, Marco Giordano, Thomas Hof- mann, Sotiris Anagnostidis, and Sidak Pal Singh. Transformer fusion with optimal transport. InICLR, 2024. 2 9
work page 2024
-
[28]
Optimal transport aggre- gation for visual place recognition
Sergio Izquierdo and Javier Civera. Optimal transport aggre- gation for visual place recognition. InCVPR, pages 17658– 17668, 2024. 2
work page 2024
-
[29]
Robert A. Jacobs, Michael I. Jordan, Steven J. Nowlan, and Geoffrey E. Hinton. Adaptive mixtures of local experts.Neu- ral Comput., 3(1):79–87, 1991. 3, 5
work page 1991
-
[30]
All-In-One Image Restoration for Unknown Corruption
Boyun Li, Xiao Liu, Peng Hu, Zhongqin Wu, Jiancheng Lv, and Xi Peng. All-In-One Image Restoration for Unknown Corruption . InCVPR, pages 17431–17441, Los Alamitos, CA, USA, 2022. IEEE Computer Society. 2
work page 2022
-
[31]
Spatio-temporal fusion for remote sensing data: An overview and new benchmark.Sci
Jun Li, Yunfei Li, Lin He, Jin Chen, and Antonio Plaza. Spatio-temporal fusion for remote sensing data: An overview and new benchmark.Sci. China Inf. Sci., 63(4):140301, 2020. 12, 13, 14
work page 2020
-
[32]
Ruoteng Li, Robby T. Tan, and Loong-Fah Cheong. All in one bad weather removal using architectural search. InCVPR, pages 3172–3182, 2020. 2
work page 2020
-
[33]
Scaling & shifting your features: a new baseline for efficient model tuning
Dongze Lian, Daquan Zhou, Jiashi Feng, and Xinchao Wang. Scaling & shifting your features: a new baseline for efficient model tuning. InNeurIPS, Red Hook, NY , USA, 2022. Curran Associates Inc. 7
work page 2022
-
[34]
A remote sensing image dataset for cloud removal, 2019
Daoyu Lin, Guangluan Xu, Xiaoke Wang, Yang Wang, Xian Sun, and Kun Fu. A remote sensing image dataset for cloud removal, 2019. 12, 13, 14
work page 2019
-
[35]
Conflict-averse gradient descent for multi-task learning
Bo Liu, Xingchao Liu, Xiaojie Jin, Peter Stone, and Qiang Liu. Conflict-averse gradient descent for multi-task learning. InNeurIPS, Red Hook, NY , USA, 2021. Curran Associates Inc. 4, 15
work page 2021
-
[36]
Dora: weight-decomposed low-rank adaptation
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. Dora: weight-decomposed low-rank adaptation. InICML. JMLR.org, 2024. 7
work page 2024
-
[37]
Degae: A new pretraining paradigm for low-level vision
Yihao Liu, Jingwen He, Jinjin Gu, Xiangtao Kong, Yu Qiao, and Chao Dong. Degae: A new pretraining paradigm for low-level vision. InCVPR, pages 23292–23303, 2023. 2
work page 2023
-
[38]
Ai foundation models in remote sensing: A survey, 2024
Siqi Lu, Junlin Guo, James R Zimmer-Dauphinee, Jordan M Nieusma, Xiao Wang, Parker VanValkenburgh, Steven A Wernke, and Yuankai Huo. Ai foundation models in remote sensing: A survey, 2024. 1
work page 2024
-
[39]
Gustafsson, Zheng Zhao, Jens Sj¨olund, and Thomas B
Ziwei Luo, Fredrik K. Gustafsson, Zheng Zhao, Jens Sj¨olund, and Thomas B. Sch¨on. Controlling vision-language models for multi-task image restoration. InICLR, 2024. 2
work page 2024
-
[40]
Visualizing data using t-SNE.J
Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-SNE.J. Mach. Learn. Res., 9(86):2579–2605,
-
[41]
Armin Mehri, Parichehr B. Ardakani, and Angel D. Sappa. MPRNet: Multi-path residual network for lightweight image super resolution. InWACV, pages 2703–2712, 2021. 6, 13, 16
work page 2021
-
[42]
Xiangchao Meng, Yiming Xiong, Feng Shao, Huanfeng Shen, Weiwei Sun, Gang Yang, Qiangqiang Yuan, Randi Fu, and Hongyan Zhang. A large-scale benchmark data set for evalu- ating pansharpening performance: Overview and implementa- tion.IEEE Geosci. Remote Sens. Mag., 9(1):18–52, 2021. 12, 13, 14
work page 2021
-
[43]
Sen2ven µs, a dataset for the training of sentinel-2 super-resolution algorithms.Data, 7(7):96, 2022
Julien Michel, Juan Vinasco-Salinas, Jordi Inglada, and Olivier Hagolle. Sen2ven µs, a dataset for the training of sentinel-2 super-resolution algorithms.Data, 7(7):96, 2022. 12, 13, 14
work page 2022
-
[44]
Multi-task learning as a bargaining game
Aviv Navon, Aviv Shamsian, Idan Achituve, Haggai Maron, Kenji Kawaguchi, Gal Chechik, and Ethan Fetaya. Multi-task learning as a bargaining game. InICML, pages 16428–16446. PMLR, 2022. 4, 15
work page 2022
-
[45]
Learning dual convolutional neural networks for low-level vision
Jinshan Pan, Sifei Liu, Deqing Sun, Jiawei Zhang, Yang Liu, Jimmy Ren, Zechao Li, Jinhui Tang, Huchuan Lu, Yu-Wing Tai, and Ming-Hsuan Yang. Learning dual convolutional neural networks for low-level vision. InCVPR, pages 3070– 3079, 2018. 2
work page 2018
-
[46]
PromptIR: prompting for all-in-one blind image restoration
Vaishnav Potlapalli, Syed Waqas Zamir, Salman Khan, and Fahad Shahbaz Khan. PromptIR: prompting for all-in-one blind image restoration. InNeurIPS, Red Hook, NY , USA,
- [47]
-
[48]
U-Net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-Net: Convolutional networks for biomedical image segmentation. InMICCAI, pages 234–241, Cham, 2015. Springer Interna- tional Publishing. 3, 13
work page 2015
-
[49]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter, 2019
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter, 2019. 13
work page 2019
-
[50]
SuperGlue: Learning feature match- ing with graph neural networks
Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. SuperGlue: Learning feature match- ing with graph neural networks. InCVPR, pages 4938–4947,
-
[51]
Multi-task learning as multi- objective optimization
Ozan Sener and Vladlen Koltun. Multi-task learning as multi- objective optimization. InNeurIPS, page 525–536, Red Hook, NY , USA, 2018. Curran Associates Inc. 15
work page 2018
-
[52]
Concerning nonnegative matrices and doubly stochastic matrices.Pac
Richard Sinkhorn and Paul Knopp. Concerning nonnegative matrices and doubly stochastic matrices.Pac. J. Math., 21(2): 343–348, 1967. 2, 3, 4, 8, 14
work page 1967
-
[53]
Diffusion enhancement for cloud removal in ultra-resolution remote sensing imagery.IEEE Trans
Jialu Sui, Yiyang Ma, Wenhan Yang, Xiaokang Zhang, Man- On Pun, and Jiaying Liu. Diffusion enhancement for cloud removal in ultra-resolution remote sensing imagery.IEEE Trans. Geosci. Remote Sens., 62:1–14, 2024. 12, 13, 14
work page 2024
-
[54]
RingMo: A remote sensing foundation model with masked image modeling.IEEE Trans
Xian Sun, Peijin Wang, Wanxuan Lu, Zicong Zhu, Xiao- nan Lu, Qibin He, Junxi Li, Xuee Rong, Zhujun Yang, Hao Chang, Qinglin He, Guang Yang, Ruiping Wang, Jiwen Lu, and Kun Fu. RingMo: A remote sensing foundation model with masked image modeling.IEEE Trans. Geosci. Remote Sens., 61:1–22, 2023. 2
work page 2023
-
[55]
Jeya Maria Jose Valanarasu, Rajeev Yasarla, and Vishal M. Patel. Transweather: Transformer-based restoration of images degraded by adverse weather conditions. InCVPR, pages 2353–2363, 2022. 2
work page 2022
-
[56]
Labeled dataset for training despeckling filters for SAR imagery.Data Brief., 53:110065, 2024
Rub´en Dar´ıo V´asquez-Salazar, Ahmed Alejandro Cardona- Mesa, Luis G´omez, Carlos M Travieso-Gonz´alez, Andr´es F Garavito-Gonz´alez, and Esteban V ´asquez-Cano. Labeled dataset for training despeckling filters for SAR imagery.Data Brief., 53:110065, 2024. 12, 13, 14
work page 2024
-
[57]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InNeurIPS, pages 6000–6010, Red Hook, NY , USA, 2017. Curran Associates Inc. 2
work page 2017
-
[58]
Multisensor remote sensing 10 imagery super-resolution with conditional gan.J
Junwei Wang, Kun Gao, Zhenzhou Zhang, Chong Ni, Zibo Hu, Dayu Chen, and Qiong Wu. Multisensor remote sensing 10 imagery super-resolution with conditional gan.J. Remote Sens., 2021, 2021. 12, 13, 14
work page 2021
-
[59]
Tao Wang, Kaihao Zhang, Ziqian Shao, Wenhan Luo, Bjorn Stenger, Tong Lu, Tae-Kyun Kim, Wei Liu, and Hongdong Li. GridFormer: Residual dense transformer with grid structure for image restoration in adverse weather conditions.IJCV, 132(10):4541–4563, 2024. 6, 13, 16
work page 2024
-
[60]
Gradient as conditions: Rethinking HOG for all-in-one image restoration
Jiawei Wu, Zhifei Yang, Zhe Wang, and Zhi Jin. Gradient as conditions: Rethinking HOG for all-in-one image restoration. AAAI, 40(13):10682–10690, 2026. 6, 13, 16
work page 2026
-
[61]
mHC: Manifold-constrained hyper-connections.arXiv, 2025
Zhenda Xie, Yixuan Wei, Huanqi Cao, Chenggang Zhao, Chengqi Deng, Jiashi Li, Damai Dai, Huazuo Gao, Jiang Chang, Kuai Yu, Liang Zhao, Shangyan Zhou, Zhean Xu, Zhengyan Zhang, Wangding Zeng, Shengding Hu, Yuqing Wang, Jingyang Yuan, Lean Wang, and Wenfeng Liang. mHC: Manifold-constrained hyper-connections.arXiv, 2025. 2
work page 2025
-
[62]
Condconv: Conditionally parameterized convolutions for efficient inference
Brandon Yang, Gabriel Bender, Quoc V Le, and Jiquan Ngiam. Condconv: Conditionally parameterized convolutions for efficient inference. InNeurIPS, 2019. 4
work page 2019
-
[63]
mHC-lite: You Don’t Need 20 Sinkhorn-Knopp Iterations.arXiv, 2026
Yongyi Yang and Jianyang Gao. mHC-lite: You Don’t Need 20 Sinkhorn-Knopp Iterations.arXiv, 2026. 2
work page 2026
-
[64]
All-In-One Medical Image Restoration via Task-Adaptive Routing
Zhiwen Yang, Haowei Chen, Ziniu Qian, Yang Yi, Hui Zhang, Dan Zhao, Bingzheng Wei, and Yan Xu. All-In-One Medical Image Restoration via Task-Adaptive Routing . InMICCAI. Springer Nature Switzerland, 2024. 6, 7, 13, 16
work page 2024
-
[65]
Gradient surgery for multi-task learning
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. Gradient surgery for multi-task learning. InNeurIPS, Red Hook, NY , USA, 2020. Curran Associates Inc. 4, 15
work page 2020
-
[66]
Z. Yuan, Z. Xiong, L. Mou, and X. X. Zhu. Chatearthnet: a global-scale image–text dataset empowering vision–language geo-foundation models.Earth Syst. Sci. Data, 17(3):1245– 1263, 2025. 2
work page 2025
-
[67]
Com- plexity experts are task-discriminative learners for any image restoration
Eduard Zamfir, Zongwei Wu, Nancy Mehta, Yuedong Tan, Danda Pani Paudel, Yulun Zhang, and Radu Timofte. Com- plexity experts are task-discriminative learners for any image restoration. InCVPR, pages 12753–12763, 2025. 6, 7, 13, 16
work page 2025
-
[68]
Restormer: Efficient transformer for high-resolution image restoration
Syed Waqas Zamir, Aditya Arora, Salman Khan, Mu- nawar Hayat, Fahad Shahbaz Khan, and Ming-Hsuan Yang. Restormer: Efficient transformer for high-resolution image restoration. InCVPR, pages 5728–5739, 2022. 6, 7, 13, 16
work page 2022
-
[69]
Libao Zhang and Shan Wang. Dense haze removal based on dynamic collaborative inference learning for remote sensing images.IEEE Trans. Geosci. Remote Sens., 60:1–16, 2022. 12, 13, 14
work page 2022
-
[70]
Zilun Zhang, Tiancheng Zhao, Yulong Guo, and Jianwei Yin. RS5M and GeoRSCLIP: A large scale vision-language dataset and a large vision-language model for remote sensing.IEEE Trans. Geosci. Remote Sens., 62:1–23, 2024. 2
work page 2024
-
[71]
Towards vision-language geo- foundation model: A survey, 2024
Yue Zhou, Litong Feng, Yiping Ke, Xue Jiang, Junchi Yan, Xue Yang, and Wayne Zhang. Towards vision-language geo- foundation model: A survey, 2024. 1
work page 2024
-
[72]
Zeng-Hui Zhu, Wei Lu, Si-Bao Chen, Chris H. Q. Ding, Jin Tang, and Bin Luo. Real-world remote sensing image dehaz- ing: Benchmark and baseline.IEEE Trans. Geosci. Remote Sens., 63:1–14, 2025. 12, 13, 14 11 A. MoRA and softmax mixture approximation This section gives the full tensor definitions behind the com- pact MoT/MoRA update in the main paper. With r...
work page 2025
-
[73]
Remove the cloud layer to improve visibility of the surface
-
[74]
Apply SAR technology to mitigate cloud interference
-
[75]
The dense cloud cover is obstructing the view; remove it for clarity
-
[76]
Can you enhance the clarity of this image by removing the clouds? Prompt examples HR
-
[77]
Apply haze removal techniques to reveal the landscape below
-
[78]
The hazes are blocking the view; please remove them
-
[79]
Remove the haze from this remote sensing image to improve visibility
-
[80]
Apply dehazing to this remote sensing image for better interpretation. SR
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.