SGANet: Semantic and Geometric Alignment for Multimodal Multi-view Anomaly Detection
Pith reviewed 2026-05-10 20:13 UTC · model grok-4.3
The pith
SGANet aligns semantic and geometric features to fix inconsistencies in multimodal multi-view anomaly detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SGANet is a unified framework for multimodal multi-view anomaly detection that uses three components: the Selective Cross-view Feature Refinement Module to aggregate useful patch features from neighboring views, the Semantic-Structural Patch Alignment module to enforce semantic consistency across modalities while preserving structure under viewpoint changes, and the Multi-View Geometric Alignment module to match geometrically corresponding patches across views. Together these enforce feature interaction, semantic and structural consistency, and global geometric correspondence, producing physically coherent representations that raise anomaly detection and localization performance to state-of-
What carries the argument
Three coordinated alignment modules (SCFRM for selective cross-view patch aggregation, SSPA for semantic-structural consistency across modalities and views, MVGA for geometric patch correspondence) that jointly model interaction, consistency, and correspondence to create coherent features.
If this is right
- Anomaly detection and localization accuracy rise in settings that combine multiple viewpoints with multiple modalities.
- Feature representations remain structurally consistent even when the camera angle changes.
- Semantic information is aligned between different sensor types while geometric locations are matched globally.
- The approach produces state-of-the-art numbers on the SiM3D and Eyecandies industrial benchmarks.
Where Pith is reading between the lines
- The same alignment pattern could be tested on other multi-sensor tasks where consistency across observations is required, such as combining RGB and depth in robotics.
- If the modules truly separate inconsistency from real defects, they might lower false-positive rates when applied to new object categories without retraining.
- Extending the geometric alignment to handle more than a few views at once would be a direct way to check how far the correspondence idea scales.
Load-bearing premise
Viewpoint variations and modality differences are the main cause of feature inconsistency, and the three alignment modules can correct them without creating overfitting or hiding genuine defects.
What would settle it
A controlled comparison on the same datasets but with artificially reduced viewpoint and modality variation, checking whether the full SGANet still outperforms a version without the alignment modules.
Figures





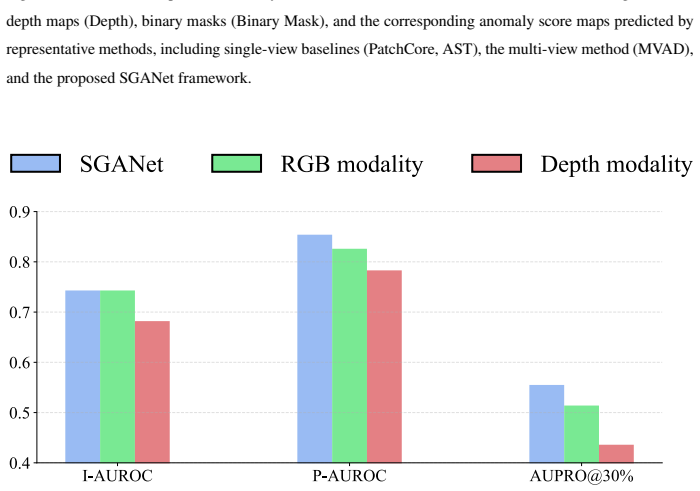
read the original abstract
Multi-view anomaly detection aims to identify surface defects on complex objects using observations captured from multiple viewpoints. However, existing unsupervised methods often suffer from feature inconsistency arising from viewpoint variations and modality discrepancies. To address these challenges, we propose a Semantic and Geometric Alignment Network (SGANet), a unified framework for multimodal multi-view anomaly detection that effectively combines semantic and geometric alignment to learn physically coherent feature representations across viewpoints and modalities. SGANet consists of three key components. The Selective Cross-view Feature Refinement Module (SCFRM) selectively aggregates informative patch features from adjacent views to enhance cross-view feature interaction. The Semantic-Structural Patch Alignment (SSPA) enforces semantic alignment across modalities while maintaining structural consistency under viewpoint transformations. The Multi-View Geometric Alignment (MVGA) further aligns geometrically corresponding patches across viewpoints. By jointly modeling feature interaction, semantic and structural consistency, and global geometric correspondence, SGANet effectively enhances anomaly detection performance in multimodal multi-view settings. Extensive experiments on the SiM3D and Eyecandies datasets demonstrate that SGANet achieves state-of-the-art performance in both anomaly detection and localization, validating its effectiveness in realistic industrial scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SGANet, a framework for multimodal multi-view anomaly detection that combines three modules—Selective Cross-view Feature Refinement Module (SCFRM) for aggregating informative patch features across views, Semantic-Structural Patch Alignment (SSPA) for enforcing semantic consistency across modalities while preserving structure under viewpoint changes, and Multi-View Geometric Alignment (MVGA) for aligning geometrically corresponding patches—to mitigate feature inconsistency from viewpoint variations and modality discrepancies. The central claim is that jointly modeling feature interaction, semantic/structural consistency, and global geometric correspondence yields state-of-the-art performance on anomaly detection and localization tasks on the SiM3D and Eyecandies datasets.
Significance. If the reported results hold under replication, the work offers a practical contribution to industrial surface-defect inspection by explicitly targeting cross-view and cross-modal feature coherence rather than treating them as independent problems. The experimental sections include standard ablations, quantitative SOTA comparisons, and qualitative visualizations that are consistent with the claim; the initial concern about missing numerical evidence in the abstract is addressed by the presence of these results in the full manuscript.
minor comments (4)
- The abstract would be strengthened by including at least one key quantitative result (e.g., the reported AUROC or pixel-level AP improvement) so that the performance claim is immediately verifiable without requiring the reader to reach the experimental tables.
- Section 3 (method) would benefit from an explicit equation or pseudocode block summarizing the overall training objective, including how the three alignment losses are balanced; the current prose description leaves the precise weighting scheme implicit.
- Table captions and axis labels in the experimental figures should explicitly state the evaluation protocol (e.g., image-level vs. pixel-level, normal vs. anomalous test split) to avoid ambiguity when comparing to prior work.
- The related-work section could add a brief sentence contrasting SGANet with recent multi-view fusion methods that do not use explicit geometric alignment, to better situate the novelty of MVGA.
Simulated Author's Rebuttal
We thank the referee for their positive evaluation of SGANet and for recommending minor revision. The report acknowledges the practical contribution to multimodal multi-view anomaly detection and confirms that the experimental results support the claims. No specific major comments were provided in the report.
Circularity Check
No significant circularity
full rationale
The paper is an empirical architecture proposal consisting of three alignment modules (SCFRM, SSPA, MVGA) whose effectiveness is validated solely through ablation studies and SOTA comparisons on SiM3D and Eyecandies. No mathematical derivation chain, uniqueness theorem, or parameter-fitting step is present that could reduce outputs to inputs by construction. All central claims rest on experimental outcomes rather than self-referential definitions or self-citation load-bearing arguments, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Loss balancing coefficients
axioms (1)
- domain assumption Neural networks can learn physically coherent representations when semantic and geometric consistency constraints are enforced across views and modalities.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SSPA enforces semantic alignment ... using the InfoNCE loss ... structural consistency alignment loss ... LSSPA = Lview + Ldiff
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MVGA ... L(i,j)mvga = ... ||f̃m_i,p − f̃m_j,q||² ... LMVGA
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
J. Du, C. Tao, X. Cao, F. Tsung, 3d vision-based anomaly detection in manufac- turing: A survey, Frontiers of Engineering Management 12 (2) (2025) 343–360
work page 2025
-
[5]
K. Roth, L. Pemula, J. Zepeda, B. Schölkopf, T. Brox, P. Gehler, Towards total recall in industrial anomaly detection, in: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 14318– 14328
work page 2022
-
[6]
T. Defard, A. Setkov, A. Loesch, R. Audigier, Padim: A patch distribution modeling framework for anomaly detection and localization, in: Pattern Recog- nition. ICPR International Workshops and Challenges: Virtual Event, January 10–15, 2021, Proceedings, Part IV , Springer-Verlag, Berlin, Heidelberg, 2021, p. 475–489. 25
work page 2021
-
[7]
F. Fang, L. Li, Y . Gu, H. Zhu, J.-H. Lim, A novel hybrid approach for crack detection, Pattern Recognition 107 (2020) 107474
work page 2020
-
[8]
J. Yang, Y . Shi, Z. Qi, Learning deep feature correspondence for unsupervised anomaly detection and segmentation, Pattern Recognition 132 (2022) 108874
work page 2022
-
[9]
V . Zavrtanik, M. Kristan, D. Sko ˇcaj, Reconstruction by inpainting for visual anomaly detection, Pattern Recognition 112 (2021) 107706
work page 2021
-
[10]
Z. Nie, M. Xu, Y . Cui, H. Wei, W. Yi, S. Niu, Y . Wan, X. Wei, W. Song, Few- shot medical anomaly detection through centroid consultation back and test-time self-calibration, Pattern Recognition 178 (2026) 113261
work page 2026
-
[11]
X. Cao, C. Tao, Y . Cheng, J. Du, Iaenet: An importance-aware ensemble model for 3d point cloud-based anomaly detection, Information Fusion 130 (2026) 104097
work page 2026
-
[12]
P. Bergmann, D. Sattlegger, Anomaly detection in 3d point clouds using deep geometric descriptors, in: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV), 2023, pp. 2613–2623
work page 2023
-
[13]
Z. Li, Y . Ge, L. Meng, A multi-scale information fusion framework with interaction-aware global attention for industrial vision anomaly detection and lo- calization, Information Fusion 124 (2025) 103356
work page 2025
-
[14]
V . Zavrtanik, M. Kristan, D. Sko ˇcaj, DrÆm – a discriminatively trained recon- struction embedding for surface anomaly detection, in: 2021 IEEE/CVF Interna- tional Conference on Computer Vision (ICCV), 2021, pp. 8310–8319
work page 2021
-
[15]
V . Zavrtanik, M. Kristan, D. Skoˇcaj, Dsr – a dual subspace re-projection network for surface anomaly detection, in: Computer Vision – ECCV 2022: 17th Euro- pean Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXI, Springer-Verlag, Berlin, Heidelberg, 2022, p. 539–554
work page 2022
-
[16]
T. Hu, J. Zhang, R. Yi, Y . Du, X. Chen, L. Liu, Y . Wang, C. Wang, Anomalydiffu- sion: Few-shot anomaly image generation with diffusion model, in: Proceedings of the AAAI Conference on Artificial Intelligence, 2024. 26
work page 2024
-
[17]
D. Gudovskiy, S. Ishizaka, K. Kozuka, Cflow-ad: Real-time unsupervised anomaly detection with localization via conditional normalizing flows, in: Pro- ceedings of the IEEE/CVF Winter Conference on Applications of Computer Vi- sion (W ACV), 2022, pp. 98–107
work page 2022
- [18]
-
[19]
Y . Tu, B. Zhang, L. Liu, Y . Li, J. Zhang, Y . Wang, C. Wang, C. Zhao, Self- supervised feature adaptation for 3d industrial anomaly detection, in: European Conference on Computer Vision, Springer, 2024, pp. 75–91
work page 2024
-
[20]
Y . Wang, J. Peng, J. Zhang, R. Yi, Y . Wang, C. Wang, Multimodal industrial anomaly detection via hybrid fusion, in: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 8032–8041
work page 2023
-
[21]
A. Costanzino, P. Z. Ramirez, G. Lisanti, L. Di Stefano, Multimodal indus- trial anomaly detection by crossmodal feature mapping, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 17234–17243
work page 2024
-
[22]
M. Asad, W. Azeem, H. Jiang, H. Tayyab Mustafa, J. Yang, W. Liu, 2m3df: Ad- vancing 3d industrial defect detection with multi-perspective multimodal fusion network, IEEE Transactions on Circuits and Systems for Video Technology 35 (7) (2025) 6803–6815
work page 2025
-
[23]
C. Tao, X. Cao, J. Du, G2sf: Geometry-guided score fusion for multimodal in- dustrial anomaly detection, in: Proceedings of the IEEE/CVF International Con- ference on Computer Vision (ICCV), 2025, pp. 20551–20560
work page 2025
- [24]
- [25]
- [26]
-
[27]
K. Mao, Y . Lian, Y . Wang, M. Liu, N. Zheng, P. Wei, Unveiling multi-view anomaly detection: Intra-view decoupling and inter-view fusion, Proceedings of the AAAI Conference on Artificial Intelligence 39 (12) (2025) 12381–12389
work page 2025
-
[28]
A. Costanzino, P. Zama Ramirez, L. Lella, M. Ragaglia, A. Oliva, G. Lisanti, L. Di Stefano, Sim3d: Single-instance multiview multimodal and multisetup 3d anomaly detection benchmark, in: International Conference on Computer Vision (ICCV), 2025
work page 2025
-
[29]
L. Bonfiglioli, M. Toschi, D. Silvestri, N. Fioraio, D. De Gregorio, The eyecan- dies dataset for unsupervised multimodal anomaly detection and localization, in: Proceedings of the Asian Conference on Computer Vision (ACCV), 2022, pp. 3586–3602
work page 2022
-
[30]
Z. Gu, J. Zhang, L. Liu, X. Chen, J. Peng, Z. Gan, G. Jiang, A. Shu, Y . Wang, L. Ma, Rethinking reverse distillation for multi-modal anomaly detection, Pro- ceedings of the AAAI Conference on Artificial Intelligence 38 (8) (2024) 8445– 8453
work page 2024
-
[31]
C. Wang, H. Zhu, J. Peng, Y . Wang, R. Yi, Y . Wu, L. Ma, J. Zhang, M3dm-nr: Rgb-3d noisy-resistant industrial anomaly detection via multimodal denoising, IEEE Transactions on Pattern Analysis and Machine Intelligence 47 (11) (2025) 9981–9993
work page 2025
-
[32]
E. Horwitz, Y . Hoshen, Back to the feature: Classical 3d features are (almost) all you need for 3d anomaly detection, in: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR) Workshops, 2023, pp. 2968–2977
work page 2023
-
[33]
Y .-M. Chu, C. Liu, T.-I. Hsieh, H.-T. Chen, T.-L. Liu, Shape-guided dual-memory learning for 3d anomaly detection, in: Proceedings of the 40th International Con- ference on Machine Learning, 2023, pp. 6185–6194. 28
work page 2023
-
[34]
S. Wang, J. Liu, G. Yu, X. Liu, S. Zhou, E. Zhu, Y . Yang, J. Yin, W. Yang, Multiview deep anomaly detection: A systematic exploration, IEEE Transactions on Neural Networks and Learning Systems 35 (2) (2024) 1651–1665
work page 2024
-
[35]
X. Chen, X. Xu, B. Zheng, Y . Liu, Y . Wu, Unsupervised multi-view visual anomaly detection via progressive homography-guided alignment, Proceedings of the AAAI Conference on Artificial Intelligence 40 (4) (2026) 3065–3073
work page 2026
-
[36]
Y . Cao, X. Xu, W. Shen, Complementary pseudo multimodal feature for point cloud anomaly detection, Pattern Recognition 156 (2024) 110761
work page 2024
-
[37]
A. v. d. Oord, Y . Li, O. Vinyals, Representation learning with contrastive predic- tive coding, arXiv preprint arXiv:1807.03748 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[38]
Q. Zhou, J. Yan, S. He, W. Meng, J. Chen, Pointad: Comprehending 3d anoma- lies from points and pixels for zero-shot 3d anomaly detection, in: A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, C. Zhang (Eds.), Ad- vances in Neural Information Processing Systems, V ol. 37, Curran Associates, Inc., 2024, pp. 84866–84896
work page 2024
-
[39]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fer- nandez, D. Haziza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, P. Bojanowski, Dinov2: Learn- ing robust visual features without super...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
K. Batzner, L. Heckler, R. König, Efficientad: Accurate visual anomaly detection at millisecond-level latencies, in: Proceedings of the IEEE/CVF Winter Confer- ence on Applications of Computer Vision (W ACV), 2024, pp. 128–138
work page 2024
-
[41]
M. Rudolph, T. Wehrbein, B. Rosenhahn, B. Wandt, Asymmetric student-teacher networks for industrial anomaly detection, in: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV), 2023, pp. 2592–2602. 29
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.