Recognition: no theorem link
JZ-Tree: GPU friendly neighbour search and friends-of-friends with dual tree walks in JAX plus CUDA
Pith reviewed 2026-05-10 19:30 UTC · model grok-4.3
The pith
Morton plane-based trees let dual-tree algorithms run efficiently on GPUs
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
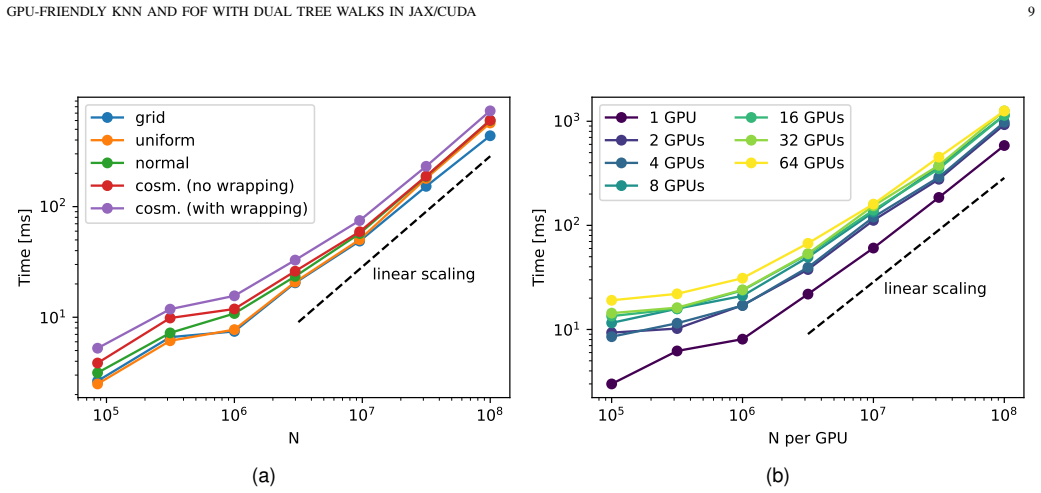
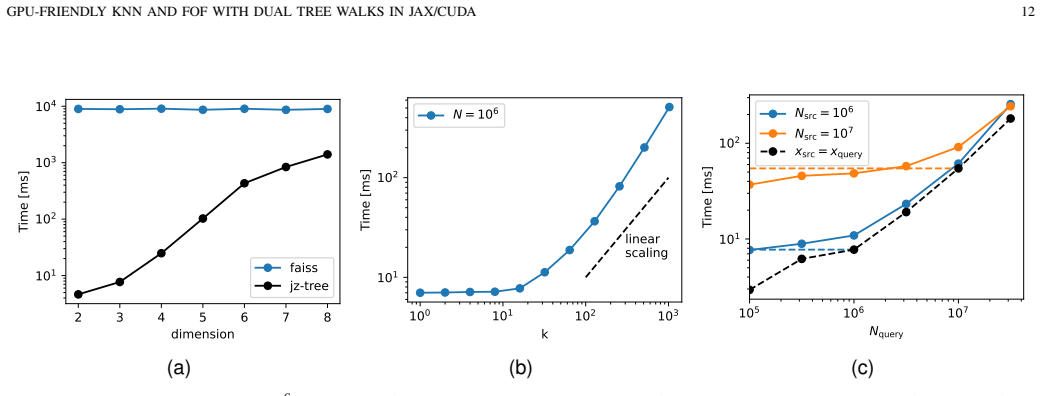
The authors establish that their Morton plane-based tree hierarchy creates a data layout allowing highly coalesced memory accesses and low divergence during dual-tree traversal with collaborative threads. This yields GPU implementations of k-nearest neighbour search and friends-of-friends that improve performance by more than an order of magnitude over competing libraries for large N and scale to distributed multi-GPU setups.
What carries the argument
Morton (z-order) plane-based tree hierarchy that flattens the spatial tree for GPU-optimized dual traversal.
If this is right
- kNN search runs over 10x faster on GPUs for N greater than 10 million.
- FoF clustering achieves similar speedups and multi-GPU scaling.
- The framework can support a broad class of tree-based spatial algorithms on GPUs.
- Strong scaling enables handling of even larger datasets across distributed systems.
Where Pith is reading between the lines
- This hierarchy might apply to other algorithms like Barnes-Hut n-body simulations for faster gravity calculations.
- Performance could be further tested with varying data distributions to confirm robustness.
- Integration in JAX opens possibilities for end-to-end differentiable spatial processing in ML models.
Load-bearing premise
The proposed Morton plane-based tree hierarchy will generate memory access patterns regular enough and thread divergence low enough on modern GPUs to achieve the reported speedups without major costs from building the tree or balancing the load.
What would settle it
Running a benchmark on a standard GPU with 10^7 particles where the k-nearest neighbor query time with JZ-Tree is not at least 10 times lower than with the best alternative GPU library.
Figures





read the original abstract
Algorithms based on spatial tree traversal are widely regarded as among the most efficient and flexible approaches for many problems in CPU-based high-performance computing (HPC). However, directly transferring these algorithms to GPU architectures often yields substantially smaller performance gains than expected in light of the high computational throughput of modern GPUs. The branching nature of tree algorithms leads to thread divergence and irregular memory access patterns -- both of which may severely limit GPU performance. To address these challenges, we propose a Morton (z-order) 'plane-based tree hierarchy' that is specifically designed for GPU architectures. The resulting flattened data layout enables efficient dual-tree traversal with collaborative execution across thread groups, leading to highly coalesced memory access patterns. Based on this framework we present implementations of two important spatial algorithms -- exact $k$-nearest neighbour search and friends-of-friends (FoF) clustering. For both cases, we observe more than an order-of-magnitude performance improvement over the closest competing GPU libraries for large problem sizes ($N \gtrsim 10^7$), together with strong scaling to distributed multi-GPU systems. We provide an open-source implementation, 'JZ-Tree' (JAX z-order tree), which serves as a foundation for efficient GPU implementations of a broad class of tree-based algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces JZ-Tree, a Morton (z-order) plane-based tree hierarchy optimized for GPU architectures to support efficient collaborative dual-tree walks. It provides JAX+CUDA implementations of exact k-nearest neighbor search and friends-of-friends clustering, claiming >10x speedups over competing GPU libraries for N ≳ 10^7 together with strong multi-GPU scaling, and releases the code as open source.
Significance. If the performance and scaling results hold, the work would be a useful practical advance for GPU-accelerated spatial algorithms in HPC, addressing thread divergence and memory irregularity via the specialized flattened layout. Strengths include the detailed kernel pseudocode, separate timing of tree construction, benchmarks up to N=10^8 with explicit library comparisons, and the reproducible open-source release.
minor comments (3)
- [§4.2] §4.2: the description of the collaborative dual-tree walk would benefit from an additional sentence clarifying how thread-group synchronization avoids divergence in the plane-based traversal.
- [Figure 7] Figure 7: the multi-GPU scaling plot axes and legend are difficult to read at print size; consider increasing font size or splitting into separate panels.
- [§5.1] §5.1: while tree-build costs are stated to be sub-dominant, a short table summarizing build vs. query times across the tested N range would make this explicit.
Simulated Author's Rebuttal
We thank the referee for their positive review and recommendation for minor revision. The report accurately captures the key contributions of JZ-Tree, including the Morton plane-based hierarchy, collaborative dual-tree walks, performance claims for N ≳ 10^7, and the open-source release. No major comments were raised.
Circularity Check
No significant circularity; algorithmic implementation with external benchmarks
full rationale
The manuscript describes a Morton plane-based tree hierarchy, flattened layout, collaborative dual-tree walk, and CUDA kernels for kNN and FoF, supported by pseudocode, timing breakdowns, and direct comparisons to external libraries (nanoflann, cuML). Performance claims rest on empirical measurements for N up to 10^8 and multi-GPU scaling, not on any fitted parameters, self-referential predictions, or load-bearing self-citations. Tree construction costs are separately quantified and shown sub-dominant. The open-source JAX+CUDA release provides an independent reproduction path. No equations or uniqueness theorems reduce to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Morton (z-order) curves preserve spatial locality sufficiently for tree-based neighbor queries
invented entities (1)
-
plane-based tree hierarchy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2020, Proceedings of the National Academy of Science, 117, 30055, doi: 10.1073/pnas.1912789117
K. Cranmer, J. Brehmer, and G. Louppe, “The frontier of simulation- based inference,”Proceedings of the National Academy of Sciences, vol. 117, no. 48, pp. 30 055–30 062, 2020. [Online]. Available: https://www.pnas.org/doi/abs/10.1073/pnas.1912789117
-
[2]
Jax: composable transformations of python+numpy pro- grams,
J. Bradbury, R. Frostig, P. Hawkins, M. Johnson, C. Leary, D. Maclau- rin, G. Necula, A. Paszke, J. VanderPlas, S. Wanderman-Milne, and Q. Zhang, “Jax: composable transformations of python+numpy pro- grams,” https://github.com/google/jax, 2018
2018
-
[3]
Cuda c++ programming guide,
NVIDIA Corporation, “Cuda c++ programming guide,” https://docs. nvidia.com/cuda/, 2024
2024
-
[4]
Cuda c++ best practices guide,
——, “Cuda c++ best practices guide,” https://docs.nvidia.com/cuda/ cuda-c-best-practices-guide/, 2024
2024
-
[6]
de Berg, O
M. de Berg, O. Cheong, M. van Kreveld, and M. Overmars,Computa- tional Geometry: Algorithms and Applications. Springer, 2008. GPU-FRIENDLY KNN AND FOF WITH DUAL TREE W ALKS IN JAX/CUDA 13
2008
-
[7]
Multidimensional binary search trees used for associative searching,
J. L. Bentley, “Multidimensional binary search trees used for associative searching,”Communications of the ACM, vol. 18, no. 9, pp. 509–517, 1975
1975
-
[8]
A hierarchical o(n log n) force-calculation algorithm,
J. Barnes and P. Hut, “A hierarchical o(n log n) force-calculation algorithm,”Nature, vol. 324, pp. 446–449, 1986
1986
-
[9]
A fast algorithm for particle simulations,
L. Greengard and V . Rokhlin, “A fast algorithm for particle simulations,” Journal of Computational Physics, vol. 73, pp. 325–348, 1987
1987
-
[10]
Maximizing parallelism in the construction of bvhs, octrees, and k-d trees,
T. Karras, “Maximizing parallelism in the construction of bvhs, octrees, and k-d trees,”High Performance Graphics, 2012
2012
-
[11]
Fast bvh construction on gpus,
C. Lauterbach, M. Garland, S. Sengupta, D. Luebke, and D. Manocha, “Fast bvh construction on gpus,” inEurographics, 2009
2009
-
[12]
Real-time kd-tree construction on graphics hardware,
K. Zhou, Q. Hou, R. Wang, and B. Guo, “Real-time kd-tree construction on graphics hardware,” inACM SIGGRAPH Asia, 2008
2008
-
[13]
Optimizing lbvh-construction and hierarchy- traversal to accelerate knn queries on point clouds using the gpu,
J. Jakob and M. Guthe, “Optimizing lbvh-construction and hierarchy- traversal to accelerate knn queries on point clouds using the gpu,” in Computer Graphics Forum, vol. 40, no. 1. Wiley Online Library, 2021, pp. 124–137
2021
-
[14]
’n-body’ problems in statistical learn- ing,
A. G. Gray and A. W. Moore, “’n-body’ problems in statistical learn- ing,” inProceedings of the 14th International Conference on Neural Information Processing Systems, ser. NIPS’00. Cambridge, MA, USA: MIT Press, 2000, p. 500–506
2000
-
[15]
Tree-independent dual-tree algorithms,
R. R. Curtin, W. B. March, P. Ram, D. V . Anderson, A. G. Gray, and C. L. Isbell, “Tree-independent dual-tree algorithms,” inProceedings of the 30th International Conference on International Conference on Machine Learning - Volume 28, ser. ICML’13. JMLR.org, 2013, p. III–1435–III–1443
2013
-
[16]
R. W. Hockney and J. W. Eastwood,Computer Simulation Using Particles. CRC Press, 1988
1988
-
[17]
M. P. Allen and D. J. Tildesley,Computer Simulation of Liquids. Oxford University Press, 2017
2017
-
[18]
Fast k nearest neighbor search using gpu,
V . Garcia, E. Debreuve, and M. Barlaud, “Fast k nearest neighbor search using gpu,” inIEEE CVPR Workshops, 2008
2008
-
[19]
Billion-scale similarity search with gpus,
J. Johnson, M. Douze, and H. J ´egou, “Billion-scale similarity search with gpus,”IEEE Transactions on Big Data, vol. 7, no. 3, pp. 535–547, 2021
2021
-
[20]
M. Douze, A. Guzhva, C. Deng, J. Johnson, G. Szilvasy, P.-E. Mazar ´e, M. Lomeli, L. Hosseini, and H. J ´egou, “The faiss library,” 2025. [Online]. Available: https://arxiv.org/abs/2401.08281
work page internal anchor Pith review arXiv 2025
-
[21]
Product quantization for nearest neighbor search,
H. J ´egou, M. Douze, and C. Schmid, “Product quantization for nearest neighbor search,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 33, no. 1, pp. 117–128, 2011
2011
-
[22]
Efficient and robust approxi- mate nearest neighbor search using hierarchical navigable small world graphs,
Y . A. Malkov and D. A. Yashunin, “Efficient and robust approxi- mate nearest neighbor search using hierarchical navigable small world graphs,”IEEE Transactions on Pattern Analysis and Machine Intelli- gence, vol. 42, no. 4, pp. 824–836, 2020
2020
-
[23]
Analyzing the Performance of Applications at Exascale,
V . Kamel, H. Yan, and S. Chester, “Clover: A gpu-native, spatio- graph-based approach to exact knn,” inProceedings of the 39th ACM International Conference on Supercomputing, ser. ICS ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 236–249. [Online]. Available: https://doi.org/10.1145/3721145.3730415
-
[24]
A computer oriented geodetic data base and a new technique in file sequencing,
G. M. Morton, “A computer oriented geodetic data base and a new technique in file sequencing,” IBM, Tech. Rep., 1966
1966
-
[25]
Sagan,Space-Filling Curves
H. Sagan,Space-Filling Curves. Springer, 1994
1994
-
[26]
Bader,Space-Filling Curves: An Introduction with Applications in Scientific Computing
M. Bader,Space-Filling Curves: An Introduction with Applications in Scientific Computing. Springer, 2013
2013
-
[27]
Samet,Foundations of Multidimensional and Metric Data Structures
H. Samet,Foundations of Multidimensional and Metric Data Structures. Morgan Kaufmann, 2006
2006
-
[28]
Fast construction of k-nearest neighbor graphs for point clouds,
M. Connor and P. Kumar, “Fast construction of k-nearest neighbor graphs for point clouds,”IEEE Transactions on Visualization and Computer Graphics, vol. 16, no. 4, pp. 599–608, 2010
2010
-
[29]
Ieee standard for floating-point arithmetic,
“Ieee standard for floating-point arithmetic,”IEEE Std 754-2019 (Revi- sion of IEEE 754-2008), pp. 1–84, 2019
2019
-
[30]
Cub: Cuda unbound library,
NVIDIA, “Cub: Cuda unbound library,” 2017. [Online]. Available: https://nvlabs.github.io/cub/
2017
-
[31]
Parallel sorting by regular sampling,
H. Shi and J. Schaeffer, “Parallel sorting by regular sampling,” Journal of Parallel and Distributed Computing, vol. 14, no. 4, pp. 361–372, 1992. [Online]. Available: https://www.sciencedirect.com/ science/article/pii/074373159290075X
-
[32]
Samplesort: A sampling approach to minimal storage tree sorting,
W. D. Frazer and A. C. McKellar, “Samplesort: A sampling approach to minimal storage tree sorting,”J. ACM, vol. 17, no. 3, p. 496–507, Jul. 1970. [Online]. Available: https://doi.org/10.1145/321592.321600
-
[33]
Super scalar sample sort,
P. Sanders and S. Winkel, “Super scalar sample sort,” inAlgorithms – ESA 2004, S. Albers and T. Radzik, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2004, pp. 784–796
2004
-
[34]
Mitzenmacher and E
M. Mitzenmacher and E. Upfal,Probability and Computing: Random- ized Algorithms and Probabilistic Analysis. Cambridge University Press, 2005
2005
-
[35]
Linear-time algorithms for pairwise statistical problems,
P. Ram, D. Lee, W. March, and A. Gray, “Linear-time algorithms for pairwise statistical problems,” inAdvances in Neural Information Processing Systems, Y . Bengio, D. Schuurmans, J. Lafferty, C. Williams, and A. Culotta, Eds., vol. 22. Curran Associates, Inc., 2009. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/2009/file/2421fcb126...
2009
-
[36]
Leonardo: A pan-european pre-exascale supercomputer for hpc and ai applications,
M. Turisini, M. Cestari, and G. Amati, “Leonardo: A pan-european pre-exascale supercomputer for hpc and ai applications,”Journal of Large-Scale Research Facilities, vol. 8, p. A186, 2024. [Online]. Available: https://doi.org/10.17815/jlsrf-8-186
-
[37]
Scipy 1.0: Fundamental algorithms for scientific computing in python,
P. e. a. Virtanen, “Scipy 1.0: Fundamental algorithms for scientific computing in python,”Nature Methods, vol. 17, pp. 261–272, 2020
2020
-
[38]
jaxkd: Minimal JAX implementation of k-nearest neighbors using a k-d tree,
B. Dodge, “jaxkd: Minimal JAX implementation of k-nearest neighbors using a k-d tree,” Jul. 2024. [Online]. Available: https: //github.com/dodgebc/jaxkd
2024
-
[39]
jaxkd-cuda: Custom CUDA kernels for JAX k-d tree operations,
——, “jaxkd-cuda: Custom CUDA kernels for JAX k-d tree operations,” 2024, used via the jaxkd interface. [Online]. Available: https://github.com/dodgebc/jaxkd-cuda
2024
-
[40]
A stack-free traversal algorithm for left-balanced k-d trees,
I. Wald, “A stack-free traversal algorithm for left-balanced k-d trees,” Journal of Computer Graphics Techniques (JCGT), vol. 14, no. 1, pp. 40–54, 2025. [Online]. Available: http://jcgt.org/published/0014/01/03/
2025
-
[41]
DISCO-DJ II: a differentiable particle-mesh code for cosmology,
F. List, O. Hahn, T. Fl ¨oss, and L. Winkler, “DISCO-DJ II: a differentiable particle-mesh code for cosmology,”arXiv e-prints, p. arXiv:2510.05206, Oct. 2025
-
[42]
Planck 2018 results. VI. Cosmological parameters,
Planck Collaboration et al., “Planck 2018 results. VI. Cosmological parameters,”A&A, vol. 641, p. A6, Sep. 2020
2018
-
[43]
The evolution of large-scale structure in a universe dominated by cold dark matter,
M. Davis, G. Efstathiou, C. S. Frenk, and S. D. M. White, “The evolution of large-scale structure in a universe dominated by cold dark matter,” The Astrophysical Journal, vol. 292, pp. 371–394, May 1985
1985
-
[44]
Groups of Galaxies. I. Nearby groups,
J. P. Huchra and M. J. Geller, “Groups of Galaxies. I. Nearby groups,” The Astrophysical Journal, vol. 257, pp. 423–437, Jun. 1982
1982
-
[45]
Merger Rates in Hierarchical Models of Galaxy Formation - Part Two - Comparison with N-Body Simulations,
C. Lacey and S. Cole, “Merger Rates in Hierarchical Models of Galaxy Formation - Part Two - Comparison with N-Body Simulations,”Monthly Notices of the Royal Astronomical Society, vol. 271, p. 676, Dec. 1994
1994
-
[46]
Tree-less 3d friends-of-friends using spatial hashing,
P. Creasey, “Tree-less 3d friends-of-friends using spatial hashing,” Astronomy and Computing, vol. 25, p. 159–167, Oct. 2018. [Online]. Available: http://dx.doi.org/10.1016/j.ascom.2018.09.010
-
[47]
Simulating cosmic structure formation with the GADGET-4 code,
V . Springel, R. Pakmor, O. Zier, and M. Reinecke, “Simulating cosmic structure formation with the GADGET-4 code,”Monthly Notices of the Royal Astronomical Society, vol. 506, no. 2, pp. 2871–2949, Sep. 2021
2021
-
[48]
jFoF: GPU Cluster Finding with Gradient Propagation,
B. Horowitz and A. E. Bayer, “jFoF: GPU Cluster Finding with Gradient Propagation,”arXiv e-prints, p. arXiv:2510.26851, Oct. 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.