Recognition: no theorem link
CraterBench-R: Instance-Level Crater Retrieval for Planetary Scale
Pith reviewed 2026-05-10 19:29 UTC · model grok-4.3
The pith
Instance-token aggregation matches full late-interaction accuracy for crater retrieval at K=64 while using far less storage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Instance-token aggregation selects K seed tokens, assigns every remaining token to the nearest seed by cosine similarity, and replaces each cluster with one aggregated representative; at K=64 the resulting representation matches the retrieval accuracy of using all 196 ViT tokens while requiring significantly less storage, and a two-stage shortlist-plus-rerank pipeline recovers 89-94 percent of full late-interaction accuracy.
What carries the argument
Instance-token aggregation: a training-free procedure that selects K seed tokens, clusters the remaining tokens around them via cosine similarity, and collapses each cluster to a single representative token for late-interaction matching.
If this is right
- Self-supervised ViTs with in-domain pretraining outperform generic models that have far more parameters.
- Retaining multiple ViT patch tokens for late interaction raises mAP substantially over standard single-vector pooling.
- At K=16 the aggregation method already improves mAP by 17.9 points over simply selecting 16 raw tokens.
- A two-stage pipeline recovers 89-94 percent of full late-interaction accuracy while examining only a small candidate set.
Where Pith is reading between the lines
- The same aggregation pattern could be tested on other remote-sensing retrieval tasks that currently rely on full ViT token sets.
- If the clusters formed by cosine similarity align with morphological subtypes, the method may also support analog discovery without extra supervision.
- Planetary-science pipelines that already store single embeddings could adopt the two-stage approach with only a modest change to their index.
Load-bearing premise
The manually verified queries and multi-scale gallery views in CraterBench-R are representative of real planetary-scale crater retrieval challenges across diverse contexts.
What would settle it
Measure whether the mAP gap between K=64 aggregated tokens and the full 196-token baseline exceeds 1 point on a new crater dataset drawn from a different planetary body or imaging instrument.
Figures




read the original abstract
Impact craters are a cornerstone of planetary surface analysis. However, while most deep learning pipelines treat craters solely as a detection problem, critical scientific workflows such as catalog deduplication, cross-observation matching, and morphological analog discovery are inherently retrieval tasks. To address this, we formulate crater analysis as an instance-level image retrieval problem and introduce CraterBench-R, a curated benchmark featuring about 25,000 crater identities with multi-scale gallery views and manually verified queries spanning diverse scales and contexts. Our baseline evaluations across various architectures reveal that self-supervised Vision Transformers (ViTs), particularly those with in-domain pretraining, dominate the task, outperforming generic models with significantly more parameters. Furthermore, we demonstrate that retaining multiple ViT patch tokens for late-interaction matching dramatically improves accuracy over standard single-vector pooling. However, storing all tokens per image is operationally inefficient at a planetary scale. To close this efficiency gap, we propose instance-token aggregation, a scalable, training-free method that selects K seed tokens, assigns the remaining tokens to these seeds via cosine similarity, and aggregates each cluster into a single representative token. This approach yields substantial gains: at K=16, aggregation improves mAP by 17.9 points over raw token selection, and at K=64, it matches the accuracy of using all 196 tokens with significantly less storage. Finally, we demonstrate that a practical two-stage pipeline, with single-vector shortlisting followed by instance-token reranking, recovers 89-94% of the full late-interaction accuracy while searching only a small candidate set. The benchmark is publicly available at hf.co/datasets/jfang/CraterBench-R.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates crater analysis as an instance-level image retrieval problem, introduces CraterBench-R (a benchmark with ~25k crater identities, multi-scale gallery views, and manually verified queries), shows that in-domain pretrained ViTs outperform other models, and proposes a training-free instance-token aggregation method (select K seeds, cluster remaining tokens by cosine similarity, aggregate clusters) that at K=64 matches the mAP of using all 196 ViT tokens while reducing storage; a two-stage pipeline (single-vector shortlisting + reranking) recovers 89-94% of full late-interaction accuracy.
Significance. If the benchmark is representative and the efficiency results generalize, the work provides a practical path to scalable retrieval for planetary crater tasks such as deduplication and analog discovery, with the public benchmark release and simple aggregation technique as clear strengths that could support follow-on research in efficient late-interaction ViT retrieval.
major comments (3)
- [Abstract] Abstract: the headline claims (17.9 mAP gain at K=16; K=64 aggregation matching full 196-token accuracy; two-stage pipeline recovering 89-94% of late-interaction performance) are presented without error bars, standard deviations, number of runs, or details on query/gallery splits and statistical testing, leaving the quantitative support for these central efficiency-accuracy results only moderately substantiated.
- [Abstract] Abstract and evaluation sections: the planetary-scale positioning rests on the assumption that CraterBench-R (curated ~25k identities with multi-scale views) captures the distribution of crater appearances, scales, contexts, and distractors across bodies and missions, yet no cross-planet hold-out, synthetic variation, or comparison to operational catalogs (e.g., Mars or lunar databases) is described; this is load-bearing for the scalability claims.
- [Method] Method description of instance-token aggregation: the procedure for selecting the K seed tokens (random sampling? farthest-point? k-means?) and the exact aggregation operator per cluster (mean pooling? weighted?) is not fully specified, which directly affects reproducibility of the reported storage-accuracy trade-off at K=16 and K=64.
minor comments (2)
- [Abstract] Abstract: the phrase 'significantly less storage' at K=64 is not quantified (e.g., bytes per image or factor reduction relative to 196 tokens).
- Consider adding a table or figure showing sensitivity of mAP to the choice of K and to the seed-selection strategy to strengthen the efficiency analysis.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. We address each major comment below and have revised the manuscript to improve statistical reporting, clarify limitations, and enhance reproducibility.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claims (17.9 mAP gain at K=16; K=64 aggregation matching full 196-token accuracy; two-stage pipeline recovering 89-94% of late-interaction performance) are presented without error bars, standard deviations, number of runs, or details on query/gallery splits and statistical testing, leaving the quantitative support for these central efficiency-accuracy results only moderately substantiated.
Authors: We agree that the abstract would benefit from greater statistical transparency. In the revised manuscript we have added standard deviations computed over five independent runs (varying random seeds where applicable) to the reported mAP gains and recovery percentages. We have also specified the query/gallery splits (70 % of crater identities reserved for the gallery, 30 % for queries, with no identity overlap) and noted that formal hypothesis testing was omitted because the retrieval pipeline is deterministic once embeddings are fixed; raw per-run values are now provided in the supplementary material for full transparency. revision: yes
-
Referee: [Abstract] Abstract and evaluation sections: the planetary-scale positioning rests on the assumption that CraterBench-R (curated ~25k identities with multi-scale views) captures the distribution of crater appearances, scales, contexts, and distractors across bodies and missions, yet no cross-planet hold-out, synthetic variation, or comparison to operational catalogs (e.g., Mars or lunar databases) is described; this is load-bearing for the scalability claims.
Authors: We acknowledge that the planetary-scale claims rest on the representativeness of CraterBench-R. The benchmark was deliberately curated from multiple missions and includes multi-scale and multi-context views to approximate appearance variation across bodies. However, we did not perform explicit cross-planet hold-out experiments or direct comparisons with operational catalogs, as the primary source imagery is dominated by a single body and catalog annotation protocols differ substantially. In the revision we have added an explicit limitations paragraph that states this assumption and describes how the curation process (diverse scales, lighting, and background contexts) was intended to support broader applicability. We believe this provides an honest framing without overstating generalizability. revision: partial
-
Referee: [Method] Method description of instance-token aggregation: the procedure for selecting the K seed tokens (random sampling? farthest-point? k-means?) and the exact aggregation operator per cluster (mean pooling? weighted?) is not fully specified, which directly affects reproducibility of the reported storage-accuracy trade-off at K=16 and K=64.
Authors: We thank the referee for highlighting this reproducibility gap. Seed tokens are selected by running k-means clustering on the 196 patch-token embeddings and taking the K centroids as seeds. Remaining tokens are assigned to the nearest seed by cosine similarity, and each resulting cluster is aggregated by simple mean pooling. We have inserted this precise description together with pseudocode into the revised method section so that the K=16 and K=64 trade-offs can be exactly reproduced. revision: yes
Circularity Check
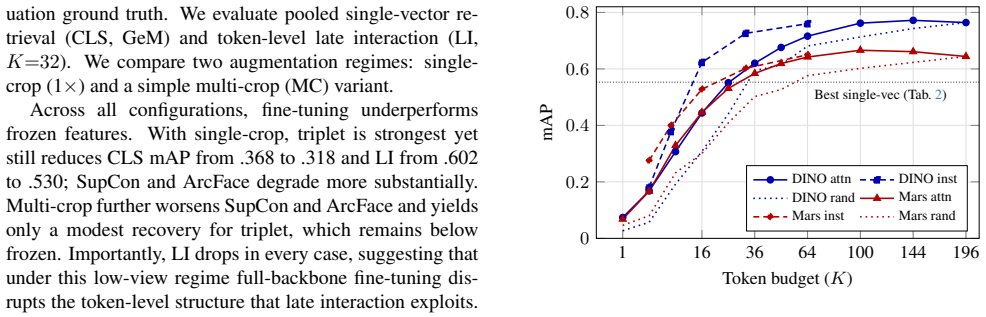
No circularity; empirical benchmark results with independent validation steps
full rationale
The paper introduces CraterBench-R (~25k identities, multi-scale views, verified queries) and reports direct experimental outcomes: ViT dominance, late-interaction gains from multiple tokens, instance-token aggregation (K-seed selection + cosine clustering + aggregation) achieving mAP parity at K=64 vs. 196 tokens, and two-stage shortlist+rerank recovering 89-94% accuracy. These are measured quantities on the held-out benchmark splits, not quantities defined in terms of themselves, fitted parameters renamed as predictions, or load-bearing self-citations. No equations reduce by construction, no uniqueness theorems are imported, and no ansatz is smuggled. The chain is standard benchmark creation followed by ablation-style evaluation and is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Self-supervised Vision Transformers pretrained on in-domain data can be applied effectively to planetary crater images for retrieval.
Reference graph
Works this paper leans on
-
[1]
Jackson, Chen- chong Zhu, and Noah Hammond
Mohamad Ali-Dib, Kristen Menou, Alan P. Jackson, Chen- chong Zhu, and Noah Hammond. Automated crater shape re- trieval using weakly-supervised deep learning.Icarus, 345: 113749, 2021. 1, 2
2021
-
[2]
NetVLAD: CNN architecture for weakly supervised place recognition
Relja Arandjelovi ´c, Petr Gronat, Akihiko Torii, Tom ´aˇs Pa- jdla, and Josef Sivic. NetVLAD: CNN architecture for weakly supervised place recognition. InCVPR, 2016. 2, 5, 6
2016
-
[3]
Token merging: Your ViT but faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your ViT but faster. InICLR, 2023. 3
2023
-
[4]
Unifying deep local and global features for image search
Bingyi Cao, Andr ´e Araujo, and Jack Sim. Unifying deep local and global features for image search. InECCV, 2020. 3
2020
-
[5]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. In ICCV, 2021. 3, 4, 5
2021
-
[6]
Registration of mars remote sensing images under the crater constraint.Planetary and Space Science, 85:13–23, 2013
Liang Cheng, Lei Ma, Kang Yang, Yongxue Liu, and Manchun Li. Registration of mars remote sensing images under the crater constraint.Planetary and Space Science, 85:13–23, 2013. 1
2013
-
[7]
Standard tech- niques for presentation and analysis of crater size-frequency data.Icarus, 37(2):467–474, 1979
Crater Analysis Techniques Working Group. Standard tech- niques for presentation and analysis of crater size-frequency data.Icarus, 37(2):467–474, 1979. 1
1979
-
[8]
DeLatte, Sarah T
Danielle M. DeLatte, Sarah T. Crites, Nicholas Guttenberg, and Takehisa Yairi. Segmentation convolutional neural net- works for automatic crater detection on Mars.IEEE Journal of Selected Topics in Applied Earth Observations and Re- mote Sensing, 12(8):2944–2957, 2019. 1, 2
2019
-
[9]
Arcface: Additive angular margin loss for deep face recognition
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 4690–4699, 2019. 5
2019
-
[10]
A domain-specific vision foundation model for mars: Self-supervised learning for planetary-scale science discov- ery.Authorea Preprints, 2026
Jichao Fang, Wei Luo, Qunying Huang, Lei Zhang, Michael Phillips, Venkata Devesh Reddy Seethi, and Iraklis Gian- nakis. A domain-specific vision foundation model for mars: Self-supervised learning for planetary-scale science discov- ery.Authorea Preprints, 2026. 4
2026
-
[11]
Analysis of impact crater populations and the geochronology of planetary surfaces in the inner solar system.Journal of Geophysical Research: Planets, 121(10): 1900–1926, 2016
Caleb I Fassett. Analysis of impact crater populations and the geochronology of planetary surfaces in the inner solar system.Journal of Geophysical Research: Planets, 121(10): 1900–1926, 2016. 1
1900
-
[12]
Crater degradation on the lunar maria: Topographic diffusion and the rate of ero- sion on the moon.Journal of Geophysical Research: Plan- ets, 119(10):2255–2271, 2014
Caleb I Fassett and Bradley J Thomson. Crater degradation on the lunar maria: Topographic diffusion and the rate of ero- sion on the moon.Journal of Geophysical Research: Plan- ets, 119(10):2255–2271, 2014. 1
2014
-
[13]
A flexible deep learning crater detec- tion scheme using segment anything model (sam).Icarus (New York, N.Y
Iraklis Giannakis, Anshuman Bhardwaj, Lydia Sam, and Georgios Leontidis. A flexible deep learning crater detec- tion scheme using segment anything model (sam).Icarus (New York, N.Y. 1962), 2023. 2
1962
-
[14]
Identity mappings in deep residual networks
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual networks. InEuropean conference on computer vision, pages 630–645. Springer,
-
[15]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. InCVPR, 2022. 4
2022
-
[16]
In de- fense of the triplet loss for person re-identification.arXiv preprint arXiv:1703.07737, 2017
Alexander Hermans, Lucas Beyer, and Bastian Leibe. In de- fense of the triplet loss for person re-identification.arXiv preprint arXiv:1703.07737, 2017. 5
-
[17]
Aggregating local descriptors into a compact image representation
Herv ´e J´egou, Matthijs Douze, Cordelia Schmid, and Patrick P´erez. Aggregating local descriptors into a compact image representation. InCVPR, 2010. 5, 6
2010
-
[18]
Prod- uct quantization for nearest neighbor search.IEEE TPAMI,
Herv ´e J´egou, Matthijs Douze, and Cordelia Schmid. Prod- uct quantization for nearest neighbor search.IEEE TPAMI,
-
[19]
Billion- scale similarity search with GPUs.IEEE Transactions on Big Data, 7(3):535–547, 2021
Jeff Johnson, Matthijs Douze, and Herv ´e J ´egou. Billion- scale similarity search with GPUs.IEEE Transactions on Big Data, 7(3):535–547, 2021. 3, 4
2021
-
[20]
ColBERT: Efficient and effective passage search via contextualized late interaction over BERT
Omar Khattab and Matei Zaharia. ColBERT: Efficient and effective passage search via contextualized late interaction over BERT. InSIGIR, 2020. 3, 4, 5
2020
-
[21]
Supervised contrastive learning
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning. InNeurIPS,
-
[22]
Automated crater detection on Mars us- ing deep learning.Planetary and Space Science, 170:16–28,
Christopher Lee. Automated crater detection on Mars us- ing deep learning.Planetary and Space Science, 170:16–28,
-
[23]
A global catalog of mar- tian impact craters with actual boundaries and degradation states.International Journal of Applied Earth Observation and Geoinformation, 131:103952, 2024
Danyang Liu, Weiming Cheng, Zhen Qian, Jia Liu, Jianzhong Liu, and Xunming Wang. A global catalog of mar- tian impact craters with actual boundaries and degradation states.International Journal of Applied Earth Observation and Geoinformation, 131:103952, 2024. 1
2024
-
[24]
Mart ´ınez, F
L. Mart ´ınez, F. Andrieu, Fr´ed´eric Schmidt, Hugues Talbot, and Mark Bentley. Robust automatic crater detection at all latitudes on mars with deep-learning.Planetary and Space Science, 2025. 2
2025
-
[25]
Jay Melosh.Impact Cratering: A Geologic Process
H. Jay Melosh.Impact Cratering: A Geologic Process. Ox- ford University Press, New York, 1989. 1
1989
-
[26]
Yolo-crater model for small crater detection
Lingli Mu, Lina Xian, Lihong Li, Gang Liu, Mi Chen, and Wei Zhang. Yolo-crater model for small crater detection. Remote Sensing, 15(20), 2023. 1
2023
-
[27]
Ivanov, and William K
Gerhard Neukum, Boris A. Ivanov, and William K. Hart- mann. Cratering records in the inner solar system in relation to the lunar reference system.Space Science Reviews, 96 (1–4):55–86, 2001. 1
2001
-
[28]
Large-scale image retrieval with attentive deep local features
Hyeonwoo Noh, Andr ´e Araujo, Jack Sim, Tobias Weyand, and Bohyung Han. Large-scale image retrieval with attentive deep local features. InICCV, 2017. 3
2017
-
[29]
DINOv2: Learning robust visual features without supervi- sion.Transactions on Machine Learning Research, 2024
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. DINOv2: Learning robust visual features without supervi- sion.Transactions on Machine Learning Research, 2024. 3, 4
2024
-
[30]
Control of crater morphology by gravity and target type-mars, earth, moon
Richard J Pike. Control of crater morphology by gravity and target type-mars, earth, moon. InIn: Lunar and Planetary Science Conference, 11th, Houston, TX, March 17-21, 1980, Proceedings. Volume 3.(A82-22351 09-91) New York, Perga- mon Press, 1980, p. 2159-2189. NASA-supported research., pages 2159–2189, 1980. 1
1980
-
[31]
Fine- tuning CNN image retrieval with no human annotation
Filip Radenovi ´c, Giorgos Tolias, and Ond ˇrej Chum. Fine- tuning CNN image retrieval with no human annotation. arXiv preprint arXiv:1711.02512, 2017. 2, 5
-
[32]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InInternational Conference on Machine Learning (ICML), 2021. 4
2021
-
[33]
DynamicViT: Efficient vision transformers with dynamic token sparsification
Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh. DynamicViT: Efficient vision transformers with dynamic token sparsification. InNeurIPS,
-
[34]
Robbins and Brian M
Stuart J. Robbins and Brian M. Hynek. A new global database of Mars impact craters≥1 km: 1. database cre- ation, properties, and parameters.Journal of Geophysical Research: Planets, 117(E5), 2012. 3, 4
2012
-
[35]
Stuart J Robbins, Michelle R Kirchoff, and Rachael H Hoover. Fully controlled 6 meters per pixel equatorial mo- saic of mars from mars reconnaissance orbiter context cam- era images, version 1.Earth and space science, 10(3): e2022EA002443, 2023. 3
2023
-
[36]
Plaid: An efficient engine for late interaction retrieval
Keshav Santhanam, Omar Khattab, Christopher Potts, and Matei Zaharia. Plaid: An efficient engine for late interaction retrieval. InProceedings of CIKM, 2022. 3
2022
-
[37]
Colbertv2: Effec- tive and efficient retrieval via lightweight late interaction
Keshav Santhanam, Omar Khattab, Jon Saad-Falcon, Christopher Potts, and Matei Zaharia. Colbertv2: Effec- tive and efficient retrieval via lightweight late interaction. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3715–3734, 2022. 3, 5, 8
2022
-
[38]
Lunar crater identification via deep learning
Ari Silburt et al. Lunar crater identification via deep learning. Icarus, 317:27–38, 2019. 1, 2
2019
-
[39]
Oriane Sim ´eoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025. 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
A model for small-impact erosion applied to the lunar surface.Journal of Geophysical Re- search, 75(14):2655–2661, 1970
Laurence A Soderblom. A model for small-impact erosion applied to the lunar surface.Journal of Geophysical Re- search, 75(14):2655–2661, 1970. 1
1970
-
[41]
The global resurfacing of venus.Journal of Geophysical Re- search: Planets, 99(E5):10899–10926, 1994
Robert G Strom, Gerald G Schaber, and Douglas D Dawson. The global resurfacing of venus.Journal of Geophysical Re- search: Planets, 99(E5):10899–10926, 1994. 1
1994
-
[42]
Efficientnet: Rethinking model scaling for convolutional neural networks
Mingxing Tan and Quoc Le. Efficientnet: Rethinking model scaling for convolutional neural networks. InInternational conference on machine learning, pages 6105–6114. PMLR,
-
[43]
Deep learning based systems for crater detection: A review,
Atal Tewari, K Prateek, Amrita Singh, and Nitin Khanna. Deep learning based systems for crater detection: A review,
-
[44]
Particular ob- ject retrieval with integral max-pooling of CNN activations
Giorgos Tolias, Ronan Sicre, and Herv´e J´egou. Particular ob- ject retrieval with integral max-pooling of CNN activations. InICLR, 2016. 2
2016
-
[45]
GroupViT: Semantic segmentation emerges from text supervision
Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, and Xiaolong Wang. GroupViT: Semantic segmentation emerges from text supervision. In CVPR, 2022. 3
2022
-
[46]
Coarse-to-fine crater matching from het- erogeneous surfaces of lroc nac and chang’e-2 dom images
Ze Yang, Zhizhong Kang, Zhen Cao, Juntao Yang, Man Peng, and Bin Liu. Coarse-to-fine crater matching from het- erogeneous surfaces of lroc nac and chang’e-2 dom images. IEEE Geoscience and Remote Sensing Letters, 20:1–5, 2023. 1
2023
-
[47]
A new approach based on crater detection and matching for visual navigation in planetary landing.Advances in Space Research, 53(12): 1810–1821, 2014
Meng Yu, Hutao Cui, and Yang Tian. A new approach based on crater detection and matching for visual navigation in planetary landing.Advances in Space Research, 53(12): 1810–1821, 2014. 1
2014
-
[48]
Crater detection and population statistics in tianwen-1 landing area based on segment any- thing model (sam).Remote Sensing, 2024
Yaqi Zhao and Hongxia Ye. Crater detection and population statistics in tianwen-1 landing area based on segment any- thing model (sam).Remote Sensing, 2024. 2 CraterBench-R: Instance-Level Crater Retrieval for Planetary Scale Supplementary Material
2024
-
[49]
This extends Table 2 in the main pa- per, which shows a representative subset
Complete Baseline Results Table 5 reports retrieval performance for all 30 frozen back- bones evaluated on Curated-5K, using the best pooling strategy per model. This extends Table 2 in the main pa- per, which shows a representative subset
-
[50]
Table 7 reports CNN results with GAP and GeM where applicable
Pooling Ablation Table 6 reports performance for every ViT backbone under all four pooling strategies. Table 7 reports CNN results with GAP and GeM where applicable. Pooling preferences vary by pretraining objective. CLS pooling is strongest for DINO v1 backbones, where the self-supervised objective explicitly trains the CLS to- ken. DINOv2 and DINOv3 fav...
-
[51]
Attention-based strategies (attention, norm×attention) consistently rank first
Token Selection Strategy Comparison Table 8 compares seven token selection strategies atK=64 for both ViT-S/16 backbones. Attention-based strategies (attention, norm×attention) consistently rank first. On DINO, the top three strategies (norm×attention, attention, norm) perform within 1% mAP of each other, while on MarsDINO the attention advantage is large...
-
[52]
4: seed selection, token- to-seed assignment, and matching strategy
Instance-Token Aggregation Ablation We ablate the three design axes of the instance-token aggre- gation pipeline introduced in Sec. 4: seed selection, token- to-seed assignment, and matching strategy. All experiments use late interaction unless otherwise noted. Assignment strategy.Tables 9 and 10 compare four as- signment strategies at eachK, using the be...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.