Improving Random Testing via LLM-powered UI Tarpit Escaping for Mobile Apps
Pith reviewed 2026-05-10 18:16 UTC · model grok-4.3
The pith
Monitoring UI similarity and querying LLMs for escape events lets random GUI testing tools cover more code and find more bugs in mobile apps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
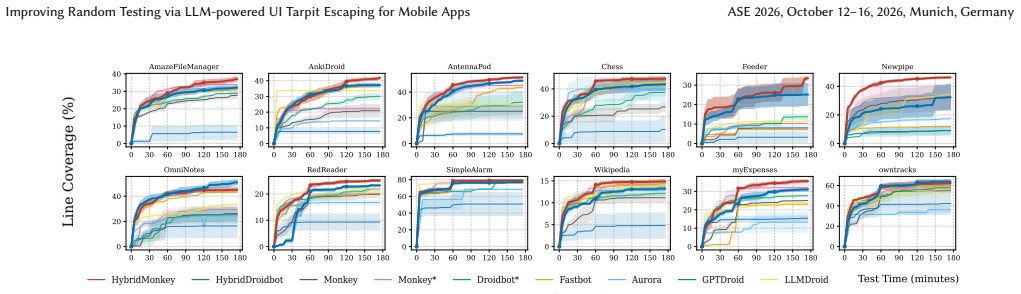
By continuously measuring UI similarity to detect exploration stalls and prompting an LLM to propose concrete events that break out of those stalls, the hybrid testers achieve average coverage gains of 54.8 percent for HybridMonkey and 44.8 percent for HybridDroidbot over their pure-random baselines while also surfacing the highest counts of unique crashes on the evaluated apps.
What carries the argument
UI-similarity monitoring that flags tarpits followed by LLM queries that return suggested events to resume broader exploration.
If this is right
- The hybrid approach can be layered on top of any existing random input generator without replacing its core logic.
- Industrial-scale apps such as WeChat show both higher activity coverage and additional bugs when the same tarpit-escaping mechanism is applied.
- The combination of similarity detection plus LLM suggestions yields more unique crashes than either pure random testing or other baseline augmentation strategies evaluated in the study.
- Twenty-six of the seventy-five discovered bugs have already been confirmed and fixed by the app developers.
Where Pith is reading between the lines
- The same tarpit-escaping pattern could be tested on iOS or web GUI testing frameworks that also rely on random event generation.
- If LLM response latency becomes a bottleneck, caching common escape suggestions for repeated UI patterns might preserve most of the coverage gain.
- The method leaves open whether cheaper, locally hosted models can match the escape quality of the cloud-based LLMs used in the experiments.
Load-bearing premise
The LLM will usually return events that actually move the tester out of a tarpit rather than suggesting actions that remain inside it or repeat useless behavior.
What would settle it
On the same twelve apps, if the hybrid versions produce no measurable coverage increase over the unmodified Monkey and Droidbot baselines when the same tarpit-prone sequences occur, the central claim is false.
Figures








read the original abstract
Random GUI testing is a widely-used technique for testing mobile apps. However, its effectiveness is limited by the notorious issue -- UI exploration tarpits, where the exploration is trapped in local UI regions, thus impeding test coverage and bug discovery. In this experience paper, we introduce LLM-powered random GUI Testing, a novel hybrid testing approach to mitigating UI tarpits during random testing. Our approach monitors UI similarity to identify tarpits and query LLMs to suggest promising events for escaping the encountered tarpits. We implement our approach on top of two different automated input generation (AIG) tools for mobile apps: (1) HybridMonkey upon Monkey, a state-of-the-practice tool; and (2) HybridDroidbot upon Droidbot, a state-of-the-art tool. We evaluated them on 12 popular, real-world apps. The results show that HybridMonkey and HybridDroidbot outperform all baselines, achieving average coverage improvements of 54.8% and 44.8%, respectively, and detecting the highest number of unique crashes. In total, we found 75 unique bugs, including 34 previously unknown bugs. To date, 26 bugs have been confirmed and fixed. We also applied HybridMonkey on WeChat, a popular industrial app with billions of monthly active users. HybridMonkey achieved higher activity coverage and found more bugs than random testing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LLM-powered random GUI testing to mitigate UI exploration tarpits in mobile apps. It detects tarpits via UI similarity monitoring and queries LLMs for event suggestions to escape them. The approach is realized as HybridMonkey (on Monkey) and HybridDroidbot (on Droidbot), evaluated on 12 real-world apps where the hybrids achieve 54.8% and 44.8% average coverage gains over baselines, detect the most unique crashes, and uncover 75 unique bugs (34 previously unknown, 26 confirmed/fixed). A case study on WeChat further shows gains over plain random testing.
Significance. If the empirical results hold, the work offers a practical, low-overhead enhancement to widely used random testing tools by integrating LLMs for targeted tarpit escape. The concrete coverage deltas, crash counts, and industrial validation on WeChat provide evidence of improved bug-finding effectiveness for mobile apps, which could influence tool adoption in practice.
major comments (2)
- [§4] §4 (Evaluation): The reported average coverage improvements (54.8% for HybridMonkey, 44.8% for HybridDroidbot) are presented without the number of independent runs per app, standard deviations, or statistical significance tests (e.g., Wilcoxon or t-tests). This makes it impossible to determine whether the gains are robust or could arise from run-to-run variance in random testing.
- [§3.2] §3.2 (Tarpit Detection): The UI similarity threshold used to identify tarpits is a free parameter with no sensitivity analysis or ablation study across values. Because tarpit detection directly triggers LLM queries and determines when the hybrid deviates from the base tool, the lack of justification undermines claims that the observed improvements stem specifically from reliable tarpit escaping rather than incidental changes in exploration behavior.
minor comments (2)
- [Abstract and §3] The abstract and §3 omit the exact prompt templates, number of LLM calls per tarpit, and any fallback strategy when LLM suggestions are invalid or repetitive; these details are needed for reproducibility.
- [§4] Table or figure presenting per-app coverage and crash numbers should include the raw baseline values alongside the hybrid results to allow direct computation of the reported percentages.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation for minor revision. The comments highlight important aspects of empirical rigor that we will address to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [§4] §4 (Evaluation): The reported average coverage improvements (54.8% for HybridMonkey, 44.8% for HybridDroidbot) are presented without the number of independent runs per app, standard deviations, or statistical significance tests (e.g., Wilcoxon or t-tests). This makes it impossible to determine whether the gains are robust or could arise from run-to-run variance in random testing.
Authors: We agree that details on run count, variability, and statistical tests are necessary to establish robustness, given the stochastic nature of random GUI testing. Our experiments used multiple independent runs per app-tool pair; we will revise §4 to explicitly state the number of runs, report standard deviations alongside the averages, and add Wilcoxon signed-rank tests with p-values comparing the hybrid tools to baselines. This will confirm the improvements are statistically significant rather than attributable to variance. revision: yes
-
Referee: [§3.2] §3.2 (Tarpit Detection): The UI similarity threshold used to identify tarpits is a free parameter with no sensitivity analysis or ablation study across values. Because tarpit detection directly triggers LLM queries and determines when the hybrid deviates from the base tool, the lack of justification undermines claims that the observed improvements stem specifically from reliable tarpit escaping rather than incidental changes in exploration behavior.
Authors: We acknowledge that the threshold is a tunable parameter and that a sensitivity analysis would better isolate the contribution of tarpit escaping. The value was selected via preliminary tuning on a subset of apps to detect genuine tarpits without excessive LLM invocations. In the revision, we will add an ablation study in §3.2 (or a new subsection) varying the threshold across a range (e.g., 0.7–0.9) and report impacts on coverage, LLM query frequency, and unique bugs found. This will provide justification and demonstrate that gains are tied to the tarpit-escaping mechanism. revision: yes
Circularity Check
No circularity: empirical comparison on fixed benchmarks
full rationale
The paper is an experience report that implements two hybrid tools (HybridMonkey, HybridDroidbot) by adding LLM-based tarpit escape to existing random testers (Monkey, Droidbot), then measures coverage and crashes on a fixed set of 12 apps. No equations, fitted parameters, or first-principles derivations are present. All reported deltas (54.8%, 44.8% coverage gains, 75 bugs) are direct experimental outcomes, not quantities defined by the authors' own choices or reduced via self-citation. The evaluation design is standard and self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- UI similarity threshold
- LLM prompt template
axioms (1)
- domain assumption UI similarity computed from screen elements or layout is a reliable indicator of exploration stall.
Reference graph
Works this paper leans on
-
[1]
Domenico Amalfitano, Anna Rita Fasolino, Porfirio Tramontana, Salvatore De Carmine, and Atif M Memon. 2012. Using GUI ripping for automated test- ing of Android applications. InProceedings of the 27th IEEE/ACM International Conference on Automated Software Engineering. 258–261
work page 2012
-
[2]
Antennapod Team. 2025. AntennaPod. https://antennapod.org/de/. Retrieved 2025-10-25
work page 2025
-
[3]
Young-Min Baek and Doo-Hwan Bae. 2016. Automated model-based Android GUI testing using multi-level GUI comparison criteria. InProceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering. 238–249
work page 2016
-
[4]
Farnaz Behrang and Alessandro Orso. 2020. Seven reasons why: an in-depth study of the limitations of random test input generation for Android. InProceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering. 1066–1077
work page 2020
-
[5]
Shauvik Roy Choudhary, Alessandra Gorla, and Alessandro Orso. 2015. Au- tomated test input generation for android: Are we there yet?(e). In2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 429–440
work page 2015
- [6]
-
[7]
Arilo C Dias Neto, Rajesh Subramanyan, Marlon Vieira, and Guilherme H Travas- sos. 2007. A survey on model-based testing approaches: a systematic review. InProceedings of the 1st ACM international workshop on Empirical assessment of software engineering languages and technologies: held in conjunction with the 22nd IEEE/ACM International Conference on Auto...
work page 2007
-
[8]
Zhen Dong, Marcel Böhme, Lucia Cojocaru, and Abhik Roychoudhury. 2020. Time-travel testing of android apps. InProceedings of the ACM/IEEE 42nd interna- tional conference on software engineering. 481–492
work page 2020
-
[9]
Dr. Neal Krawetz. 2011. Perceptual hash algorithm. https://www.hackerfactor. com/blog/index.php?/archives/432-Looks-Like-It.html. Accessed: 2025-06-23
work page 2011
-
[10]
Sidong Feng and Chunyang Chen. 2024. Prompting is all you need: Automated an- droid bug replay with large language models. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering. 1–13
work page 2024
-
[11]
Sidong Feng, Mulong Xie, and Chunyang Chen. 2023. Efficiency matters: Speed- ing up automated testing with gui rendering inference. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 906–918
work page 2023
-
[12]
Yuhao Gao, Chenbin Zhao, Guosheng Xu, and Pan Xie. 2025. LLM-Powered Automated Testing Framework for Multi-Scenario Mobile Apps Across Platforms. In2025 4th International Conference on Artificial Intelligence, Internet of Things and Cloud Computing Technology (AIoTC). IEEE, 753–756
work page 2025
-
[13]
Google. [n. d.]. Android Logcat. Accessed: 2025-06-23
work page 2025
-
[14]
Google. 2023. UI/Application Exerciser Monkey. https://developer.android.com/ studio/test/other-testing-tools/monkey. Accessed: 2025-06-23
work page 2023
-
[15]
Google. 2025. AccessibilityService. https://developer.android.com/reference/ android/accessibilityservice/AccessibilityService. Accessed: 2025-06-23
work page 2025
-
[16]
Google. 2025. UiAutomation. https://developer.android.com/reference/android/ app/UiAutomation. Accessed: 2025-06-23
work page 2025
-
[17]
Qianyu Guo, Xiaofei Xie, Yi Li, Xiaoyu Zhang, Yang Liu, Xiaohong Li, and Chao Shen. 2020. Audee: Automated testing for deep learning frameworks. InPro- ceedings of the 35th IEEE/ACM international conference on automated software engineering. 486–498
work page 2020
-
[18]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large language models for software engineering: A systematic literature review.ACM Transactions on Software Engineering and Methodology33, 8 (2024), 1–79
work page 2024
-
[19]
Han Hu, Han Wang, Ruiqi Dong, Xiao Chen, and Chunyang Chen. 2024. Enhanc- ing GUI exploration coverage of Android apps with deep link-integrated Monkey. ACM Transactions on Software Engineering and Methodology33, 6 (2024), 1–31
work page 2024
- [20]
-
[21]
Yongxiang Hu, Yu Zhang, Xuan Wang, Yingjie Liu, Shiyu Guo, Chaoyi Chen, Xin Wang, and Yangfan Zhou. 2025. KuiTest: Leveraging Knowledge in the Wild as GUI Testing Oracle for Mobile Apps. In2025 IEEE/ACM 47th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). IEEE, 34–45
work page 2025
-
[22]
Zongze Jiang, Ming Wen, Jialun Cao, Xuanhua Shi, and Hai Jin. 2024. Towards understanding the effectiveness of large language models on directed test input generation. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 1408–1420
work page 2024
-
[23]
Bangyan Ju, Jin Yang, Tingting Yu, Tamerlan Abdullayev, Yuanyuan Wu, Ding- bang Wang, and Yu Zhao. 2024. A study of using multimodal llms for non-crash functional bug detection in android apps. In2024 31st Asia-Pacific Software Engi- neering Conference (APSEC). IEEE, 61–70
work page 2024
-
[24]
Safwat Ali Khan, Wenyu Wang, Yiran Ren, Bin Zhu, Jiangfan Shi, Alyssa Mc- Gowan, Wing Lam, and Kevin Moran. 2024. AURORA: Navigating UI Tarpits via Automated Neural Screen Understanding. In2024 IEEE Conference on Software Testing, Verification and Validation (ICST). IEEE, 221–232
work page 2024
-
[25]
Pavneet Singh Kochhar, Ferdian Thung, Nachiappan Nagappan, Thomas Zim- mermann, and David Lo. 2015. Understanding the test automation culture of app developers. In2015 IEEE 8th International Conference on Software Testing, Verification and Validation (ICST). IEEE, 1–10
work page 2015
-
[26]
Pingfan Kong, Li Li, Jun Gao, Kui Liu, Tegawendé F Bissyandé, and Jacques Klein
-
[27]
Automated testing of android apps: A systematic literature review.IEEE Transactions on Reliability68, 1 (2018), 45–66
work page 2018
-
[28]
Qichao Kong, Zhengwei Lv, Yiheng Xiong, Jingling Sun, Ting Su, Dingchun Wang, Letao Li, Xu Yang, and Gang Huo. [n. d.]. ProphetAgent: Automatically Synthesizing GUI Tests from Test Cases in Natural Language for Mobile Apps. ([n. d.])
-
[29]
Yuanhong Lan, Yifei Lu, Zhong Li, Minxue Pan, Wenhua Yang, Tian Zhang, and Xuandong Li. 2024. Deeply reinforcing android gui testing with deep reinforce- ment learning. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering. 1–13
work page 2024
-
[30]
Yuanhong Lan, Yifei Lu, Minxue Pan, and Xuandong Li. 2024. Navigating mobile testing evaluation: A comprehensive statistical analysis of android GUI test- ing metrics. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 944–956
work page 2024
-
[31]
Yuanchun Li, Ziyue Yang, Yao Guo, and Xiangqun Chen. 2017. Droidbot: a lightweight ui-guided test input generator for android. In2017 IEEE/ACM 39th International Conference on Software Engineering Companion (ICSE-C). IEEE, 23– 26
work page 2017
-
[32]
Yuanchun Li, Ziyue Yang, Yao Guo, and Xiangqun Chen. 2019. Humanoid: A deep learning-based approach to automated black-box android app testing. In 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 1070–1073
work page 2019
-
[33]
Mario Linares-Vásquez, Carlos Bernal-Cárdenas, Kevin Moran, and Denys Poshy- vanyk. 2017. How do developers test android applications?. In2017 IEEE In- ternational Conference on Software Maintenance and Evolution (ICSME). IEEE, 613–622
work page 2017
-
[34]
Ruofan Liu, Xiwen Teoh, Yun Lin, Guanjie Chen, Ruofei Ren, Denys Poshyvanyk, and Jin Song Dong. 2025. GUIPilot: A Consistency-Based Mobile GUI Testing Approach for Detecting Application-Specific Bugs.Proceedings of the ACM on Software Engineering2, ISSTA (2025), 753–776
work page 2025
-
[35]
Zhe Liu, Chunyang Chen, Junjie Wang, Xing Che, Yuekai Huang, Jun Hu, and Qing Wang. 2023. Fill in the blank: Context-aware automated text input genera- tion for mobile gui testing. In2023 IEEE/ACM 45th International Conference on ASE 2026, October 12–16, 2026, Munich, Germany Mengqian Xu, Yiheng Xiong, Le Chang, Ting Su, Chengcheng Wan, and Weikai Miao So...
work page 2023
-
[36]
Zhe Liu, Chunyang Chen, Junjie Wang, Mengzhuo Chen, Boyu Wu, Xing Che, Dandan Wang, and Qing Wang. 2024. Make llm a testing expert: Bringing human-like interaction to mobile gui testing via functionality-aware decisions. In Proceedings of the IEEE/ACM 46th International Conference on Software Engineering. 1–13
work page 2024
-
[37]
Zhe Liu, Chunyang Chen, Junjie Wang, Mengzhuo Chen, Boyu Wu, Zhilin Tian, Yuekai Huang, Jun Hu, and Qing Wang. 2024. Testing the limits: Unusual text inputs generation for mobile app crash detection with large language model. In Proceedings of the IEEE/ACM 46th International conference on software engineering. 1–12
work page 2024
-
[38]
Zhe Liu, Cheng Li, Chunyang Chen, Junjie Wang, Mengzhuo Chen, Boyu Wu, Yawen Wang, Jun Hu, and Qing Wang. 2025. Seeing is Believing: Vision-driven Non-crash Functional Bug Detection for Mobile Apps.IEEE Transactions on Software Engineering(2025)
work page 2025
-
[39]
Stephan Lukasczyk and Gordon Fraser. 2022. Pynguin: Automated unit test gen- eration for python. InProceedings of the ACM/IEEE 44th International Conference on Software Engineering: Companion Proceedings. 168–172
work page 2022
-
[40]
Zhengwei Lv, Chao Peng, Zhao Zhang, Ting Su, Kai Liu, and Ping Yang. 2022. Fastbot2: Reusable automated model-based gui testing for android enhanced by reinforcement learning. InProceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering. 1–5
work page 2022
-
[41]
Aravind Machiry, Rohan Tahiliani, and Mayur Naik. 2013. Dynodroid: An input generation system for android apps. InProceedings of the 2013 9th joint meeting on foundations of software engineering. 224–234
work page 2013
-
[42]
Ke Mao, Mark Harman, and Yue Jia. 2016. Sapienz: Multi-objective automated testing for android applications. InProceedings of the 25th international symposium on software testing and analysis. 94–105
work page 2016
-
[43]
Nariman Mirzaei, Joshua Garcia, Hamid Bagheri, Alireza Sadeghi, and Sam Malek
-
[44]
InProceed- ings of the 38th international conference on software engineering
Reducing combinatorics in GUI testing of android applications. InProceed- ings of the 38th international conference on software engineering. 559–570
-
[45]
Mostafa Mohammed, Haipeng Cai, and Na Meng. 2019. An empirical comparison between monkey testing and human testing (wip paper). InProceedings of the 20th ACM SIGPLAN/SIGBED International Conference on Languages, Compilers, and Tools for Embedded Systems. 188–192
work page 2019
-
[46]
Mountainminds GmbH & Co. KG and Contributors. 2009. JaCoCo - Java Code Coverage Library. https://www.eclemma.org/jacoco/trunk/index.html. Accessed: 2025-06-23
work page 2009
-
[47]
Pengyu Nie, Rahul Banerjee, Junyi Jessy Li, Raymond J Mooney, and Milos Gligoric. 2023. Learning deep semantics for test completion. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 2111–2123
work page 2023
-
[48]
Openatx. 2025. UiAutomator2. https://developer.android.com/reference/android/ app/UiAutomation. Accessed: 2025-06-23
work page 2025
-
[49]
OpenCV team. 2000. OpenCV is the world’s biggest computer vision library. https://developer.android.com/reference/android/app/UiAutomation. Accessed: 2025-06-23
work page 2000
-
[50]
Minxue Pan, An Huang, Guoxin Wang, Tian Zhang, and Xuandong Li. 2020. Reinforcement learning based curiosity-driven testing of android applications. In Proceedings of the 29th ACM SIGSOFT international symposium on software testing and analysis. 153–164
work page 2020
-
[51]
Priyam Patel, Gokul Srinivasan, Sydur Rahaman, and Iulian Neamtiu. 2018. On the effectiveness of random testing for Android: or how i learned to stop worrying and love the monkey. InProceedings of the 13th International Workshop on Automation of Software Test. 34–37
work page 2018
-
[52]
Andrea Romdhana, Alessio Merlo, Mariano Ceccato, and Paolo Tonella. 2022. Deep reinforcement learning for black-box testing of android apps.ACM Trans- actions on Software Engineering and Methodology (TOSEM)31, 4 (2022), 1–29
work page 2022
-
[53]
Konstantin Rubinov and Luciano Baresi. 2018. What are we missing when testing our android apps?Computer51, 4 (2018), 60–68
work page 2018
-
[54]
Raimondas Sasnauskas and John Regehr. 2014. Intent fuzzer: crafting intents of death. InProceedings of the 2014 Joint International Workshop on Dynamic Analysis (WODA) and Software and System Performance Testing, Debugging, and Analytics (PERTEA). 1–5
work page 2014
-
[55]
Muhammad Shafique and Yvan Labiche. 2010. A systematic review of model based testing tool support. (2010)
work page 2010
-
[56]
Ting Su, Guozhu Meng, Yuting Chen, Ke Wu, Weiming Yang, Yao Yao, Geguang Pu, Yang Liu, and Zhendong Su. 2017. Guided, stochastic model-based GUI testing of Android apps. InProceedings of the 2017 11th joint meeting on foundations of software engineering. 245–256
work page 2017
-
[57]
Ting Su, Jue Wang, and Zhendong Su. 2021. Benchmarking automated gui testing for android against real-world bugs. InProceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 119–130
work page 2021
-
[58]
Ting Su, Yichen Yan, Jue Wang, Jingling Sun, Yiheng Xiong, Geguang Pu, Ke Wang, and Zhendong Su. 2021. Fully automated functional fuzzing of Android apps for detecting non-crashing logic bugs.Proceedings of the ACM on Programming Languages5, OOPSLA (2021), 1–31
work page 2021
-
[59]
Tommi Takala, Mika Katara, and Julian Harty. 2011. Experiences of system- level model-based GUI testing of an Android application. In2011 Fourth IEEE International Conference on Software Testing, Verification and Validation. IEEE, 377–386
work page 2011
-
[60]
WeChat Team. 2025. WeChat. https://www.wechat.com. Retrieved 2025-6-27
work page 2025
-
[61]
testinging6. 2023. GPTDroid. https://github.com/testinging6/GPTDroid. Ac- cessed: 2025-06-23
work page 2023
-
[62]
András Vargha and Harold D Delaney. 2000. A critique and improvement of the CL common language effect size statistics of McGraw and Wong.Journal of Educational and Behavioral Statistics25, 2 (2000), 101–132
work page 2000
-
[63]
Chenxu Wang, Tianming Liu, Yanjie Zhao, Minghui Yang, and Haoyu Wang. 2025. LLMDroid: Enhancing Automated Mobile App GUI Testing Coverage with Large Language Model Guidance.Proceedings of the ACM on Software Engineering2, FSE (2025), 1001–1022
work page 2025
-
[64]
Dingbang Wang, Yu Zhao, Sidong Feng, Zhaoxu Zhang, William GJ Halfond, Chunyang Chen, Xiaoxia Sun, Jiangfan Shi, and Tingting Yu. 2024. Feedback- driven automated whole bug report reproduction for android apps. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Anal- ysis. 1048–1060
work page 2024
-
[65]
Fei Wang, Kamakshi Kodur, Michael Micheletti, Shu-Wei Cheng, Yogalakshmi Sadasivam, Yue Hu, and Zening Li. 2024. Large language model driven automated software application testing. (2024)
work page 2024
-
[66]
Junjie Wang, Yuchao Huang, Chunyang Chen, Zhe Liu, Song Wang, and Qing Wang. 2024. Software testing with large language models: Survey, landscape, and vision.IEEE Transactions on Software Engineering50, 4 (2024), 911–936
work page 2024
-
[67]
Jue Wang, Yanyan Jiang, Chang Xu, Chun Cao, Xiaoxing Ma, and Jian Lu. 2020. Combodroid: generating high-quality test inputs for android apps via use case combinations. InProceedings of the ACM/IEEE 42nd International Conference on Software Engineering. 469–480
work page 2020
-
[68]
Wenyu Wang, Dengfeng Li, Wei Yang, Yurui Cao, Zhenwen Zhang, Yuetang Deng, and Tao Xie. 2018. An empirical study of android test generation tools in industrial cases. InProceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering. 738–748
work page 2018
-
[69]
Wenyu Wang, Wei Yang, Tianyin Xu, and Tao Xie. 2021. Vet: identifying and avoiding UI exploration tarpits. InProceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 83–94
work page 2021
-
[70]
Hao Wen, Yuanchun Li, Guohong Liu, Shanhui Zhao, Tao Yu, Toby Jia-Jun Li, Shiqi Jiang, Yunhao Liu, Yaqin Zhang, and Yunxin Liu. 2024. Autodroid: Llm-powered task automation in android. InProceedings of the 30th Annual International Con- ference on Mobile Computing and Networking. 543–557
work page 2024
-
[71]
Frank Wilcoxon. 1992. Individual comparisons by ranking methods. InBreak- throughs in statistics: Methodology and distribution. Springer, 196–202
work page 1992
-
[72]
Yiheng Xiong, Ting Su, Jue Wang, Jingling Sun, Geguang Pu, and Zhendong Su. 2024. General and Practical Property-based Testing for Android Apps. In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 53–64
work page 2024
-
[73]
Zhiyi Xue, Liangguo Li, Senyue Tian, Xiaohong Chen, Pingping Li, Liangyu Chen, Tingting Jiang, and Min Zhang. 2024. Llm4fin: Fully automating llm-powered test case generation for fintech software acceptance testing. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 1643–1655
work page 2024
-
[74]
Jiwei Yan, Hao Liu, Linjie Pan, Jun Yan, Jian Zhang, and Bin Liang. 2020. Multiple- entry testing of android applications by constructing activity launching contexts. InProceedings of the ACM/IEEE 42nd international conference on software engi- neering. 457–468
work page 2020
-
[75]
Lin Yang, Chen Yang, Shutao Gao, Weijing Wang, Bo Wang, Qihao Zhu, Xiao Chu, Jianyi Zhou, Guangtai Liang, Qianxiang Wang, et al. 2024. On the evaluation of large language models in unit test generation. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 1607–1619
work page 2024
-
[76]
Shengqian Yang, Haowei Wu, Hailong Zhang, Yan Wang, Chandrasekar Swami- nathan, Dacong Yan, and Atanas Rountev. 2018. Static window transition graphs for Android.Automated Software Engineering25, 4 (2018), 833–873
work page 2018
-
[77]
Wei Yang, Mukul R Prasad, and Tao Xie. 2013. A grey-box approach for automated GUI-model generation of mobile applications. InInternational Conference on Fundamental Approaches to Software Engineering. Springer, 250–265
work page 2013
-
[78]
Husam N Yasin, Siti Hafizah Ab Hamid, and Raja Jamilah Raja Yusof. 2021. Droidbotx: Test case generation tool for android applications using Q-learning. Symmetry13, 2 (2021), 310
work page 2021
-
[79]
Hui Ye, Shaoyin Cheng, Lanbo Zhang, and Fan Jiang. 2013. Droidfuzzer: Fuzzing the android apps with intent-filter tag. InProceedings of International Conference on Advances in Mobile Computing & Multimedia. 68–74
work page 2013
-
[80]
Juyeon Yoon, Robert Feldt, and Shin Yoo. 2024. Intent-driven mobile gui test- ing with autonomous large language model agents. In2024 IEEE Conference on Software Testing, Verification and Validation (ICST). IEEE, 129–139
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.