Continuous Interpretive Steering for Scalar Diversity
Pith reviewed 2026-05-10 18:03 UTC · model grok-4.3
The pith
Graded activation steering recovers item-specific differences in scalar implicature strength in language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
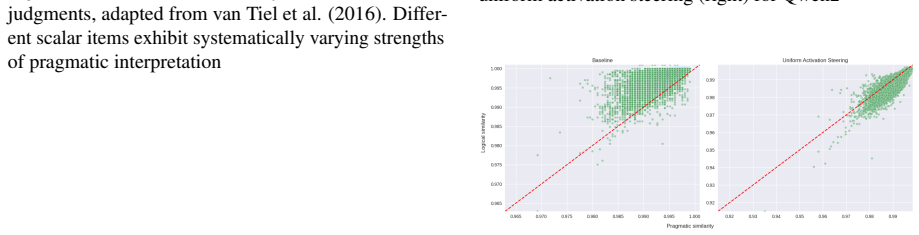
The central claim is that graded sensitivity to scalar diversity is encoded in the representation space of LLMs and can be systematically recovered through controlled intervention: uniform activation steering increases pragmatic interpretations globally but collapses item-level variation, whereas graded activation steering yields differentiated interpretive shifts aligned with scalar diversity grades from the GraSD dataset.
What carries the argument
Continuous Interpretive Steering (CIS), which varies activation steering strength as a continuous experimental variable to induce and measure graded changes in pragmatic interpretation.
If this is right
- Uniform activation steering increases pragmatic interpretations globally across scalar items but erases natural item-level differences in implicature strength.
- Graded activation steering produces interpretive shifts that align with the scalar diversity grades encoded in the GraSD dataset.
- Graded sensitivity to scalar implicatures is represented in the model's activation space in a form recoverable by continuous intervention.
- CIS combined with GraSD supplies a framework for evaluating and manipulating graded pragmatic sensitivity beyond prompt-based methods.
Where Pith is reading between the lines
- The same continuous steering approach could be tested on other graded pragmatic phenomena such as uncertainty expressions or politeness levels to check whether similar internal gradations exist.
- If internal representations encode scalar diversity this way, targeted steering might offer a route to adjust model outputs for context-sensitive inference without retraining.
- The method opens the possibility of using steering strength as a diagnostic tool to compare how different model architectures or training regimes preserve or lose graded pragmatic structure.
Load-bearing premise
Varying activation steering strength produces clean, isolated changes in pragmatic interpretation without confounding effects on other model behaviors, and the human-assigned grades in GraSD accurately reflect the model's internal representations.
What would settle it
If graded steering strength changes produce the same uniform boost and collapsed item variation as uniform steering, or if the resulting interpretive shifts show no correlation with the GraSD grades across models.
Figures



















read the original abstract
Pragmatic inference is inherently graded. Different lexical items give rise to pragmatic enrichment to different degrees. Scalar implicature exemplifies this property through scalar diversity, where implicature strength varies across scalar items. However, evaluations of pragmatic inference in large language models (LLMs) often rely on prompt-based manipulations. Beyond prompt-level effects, this study introduces Continuous Interpretive Steering (CIS), a method that probes graded pragmatic interpretation by treating activation-level steering strength as a continuous experimental variable. To support this analysis, this study introduces a new dataset, GraSD, which encodes graded scalar diversity. Experiments on four LLMs show that uniform activation steering increases pragmatic interpretations globally but collapses item-level variation, whereas graded activation steering yields differentiated interpretive shifts aligned with scalar diversity grades. It indicates that graded sensitivity is encoded in the representation space and can be systematically recovered through controlled intervention. Together, CIS and GraSD provide a principled framework for evaluating graded pragmatic sensitivity in LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Continuous Interpretive Steering (CIS), which treats activation steering strength as a continuous variable to probe graded pragmatic inference (specifically scalar implicature) in LLMs. It also presents the new GraSD dataset encoding graded scalar diversity across items. Experiments on four LLMs are reported to show that uniform steering increases pragmatic interpretations globally while collapsing item-level variation, whereas graded steering produces differentiated shifts that align with the GraSD grades; this is taken to indicate that graded sensitivity is encoded in the representation space and recoverable via intervention.
Significance. If the central experimental claims hold after addressing controls, the work supplies a new activation-level intervention paradigm for studying graded pragmatic phenomena in LLMs that goes beyond prompt engineering. The GraSD dataset is a concrete, reusable resource that could standardize evaluation of scalar diversity. These elements would strengthen the toolkit for mechanistic interpretability of pragmatics, provided the method isolates the intended representational effect.
major comments (2)
- [Abstract / Experiments] Abstract and experimental description: the claim that graded steering produces differentiated shifts 'aligned with scalar diversity grades' and thereby shows encoded graded sensitivity is load-bearing for the paper's conclusion, yet the text provides no evidence of controls for nonspecific effects of steering strength (e.g., changes in perplexity, output entropy, response length, or accuracy on non-pragmatic tasks at matched strength levels). Without such checks, the alignment could arise from broad distributional shifts rather than item-specific recovery of internal representations.
- [Method] Method section: the precise definition of 'graded activation steering' (how multipliers are assigned per item from GraSD grades, which layers or heads are steered, and whether strength variation was pre-registered) is not detailed enough to evaluate whether the intervention cleanly modulates the targeted sensitivity or introduces confounds that could artifactually produce the reported differentiation.
minor comments (1)
- [Abstract] The abstract would be clearer if it stated the number of items in GraSD, the four specific LLMs tested, and the exact metric used to quantify 'pragmatic interpretations.'
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments identify important gaps in controls and methodological transparency that we will address through targeted revisions. We respond to each point below.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and experimental description: the claim that graded steering produces differentiated shifts 'aligned with scalar diversity grades' and thereby shows encoded graded sensitivity is load-bearing for the paper's conclusion, yet the text provides no evidence of controls for nonspecific effects of steering strength (e.g., changes in perplexity, output entropy, response length, or accuracy on non-pragmatic tasks at matched strength levels). Without such checks, the alignment could arise from broad distributional shifts rather than item-specific recovery of internal representations.
Authors: We agree that the absence of explicit controls for nonspecific steering effects weakens the ability to attribute differentiated shifts specifically to recovery of graded representations. The current manuscript relies on the contrast between uniform and graded conditions to argue for item-specific effects, but this does not fully rule out broad distributional changes at varying strengths. In the revised manuscript we will add analyses of perplexity, output entropy, response length, and accuracy on matched non-pragmatic tasks (e.g., factual recall and sentiment classification) across the same range of steering strengths used in the graded condition. These results will be reported in a new subsection of the Experiments section and referenced in the abstract. revision: yes
-
Referee: [Method] Method section: the precise definition of 'graded activation steering' (how multipliers are assigned per item from GraSD grades, which layers or heads are steered, and whether strength variation was pre-registered) is not detailed enough to evaluate whether the intervention cleanly modulates the targeted sensitivity or introduces confounds that could artifactually produce the reported differentiation.
Authors: We acknowledge that the current Method section is insufficiently precise on these operational details. In the revision we will expand the description to specify: (1) multipliers are computed by linearly scaling each item's GraSD grade to the interval [0, 1] and applying the resulting value as the steering coefficient; (2) steering is performed on the same set of layers and heads previously identified via activation patching on a held-out subset of scalar items; and (3) the decision to vary strength continuously was made after pilot experiments rather than through formal pre-registration, as the study is exploratory. These additions will allow readers to assess potential confounds directly. revision: yes
Circularity Check
No significant circularity in experimental framework
full rationale
The paper introduces Continuous Interpretive Steering (CIS) as a new method and GraSD as a new dataset, then reports empirical results from activation steering experiments on four LLMs. No mathematical derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or described content. The central claim that graded sensitivity is encoded in representation space is presented as an interpretation of experimental outcomes rather than a reduction to inputs by construction. The work is self-contained as an empirical probe and does not rely on load-bearing self-citations or ansatzes smuggled from prior work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Olmo: Accelerating the science of language models. InProceedings of the 62nd annual meet- ing of the association for computational linguistics (volume 1: Long papers), pages 15789–15809. Bertram Højer, Oliver Jarvis, and Stefan Heinrich. 2025. Improving reasoning performance in large language models via representation engineering. In13th In- ternational C...
-
[2]
Interpretable steering of large language mod- els with feature guided activation additions.arXiv preprint arXiv:2501.09929. Charles Spearman. 1987. The proof and measurement of association between two things.The American journal of psychology, 100(3/4):441–471. Fang-Yi Su, Gia-Han Ngo, Ben Phan, and Jung-Hsien Chiang. 2025. Cas: enhancing implicit constra...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.