ModuSeg: Decoupling Object Discovery and Semantic Retrieval for Training-Free Weakly Supervised Segmentation
Pith reviewed 2026-05-10 19:02 UTC · model grok-4.3
The pith
Decoupling object discovery from semantic retrieval lets weakly supervised segmentation run training-free while keeping fine boundaries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
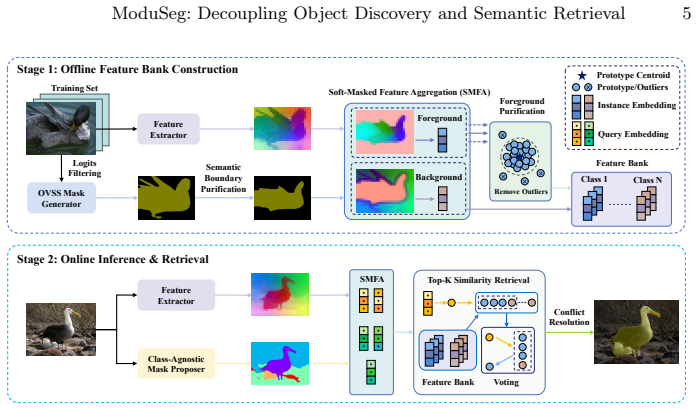
ModuSeg decouples object discovery and semantic assignment by feeding a general mask proposer to produce geometric proposals with reliable boundaries while semantic foundation models build an offline feature bank; segmentation then reduces to non-parametric feature retrieval, with semantic boundary purification and soft-masked feature aggregation used to extract high-quality category prototypes without any fine-tuning.
What carries the argument
The decoupled architecture that separates a general mask proposer for geometric proposals from an offline feature bank for non-parametric semantic retrieval.
If this is right
- Segmentation no longer requires joint optimization or retraining stages, reducing instability from pseudo-label noise.
- Fine object boundaries are preserved because geometric proposals are generated separately from semantic assignment.
- The pipeline becomes fully training-free, enabling direct use of pretrained foundation models on new datasets.
- Category prototypes extracted via soft-masked aggregation become more reliable for downstream retrieval tasks.
Where Pith is reading between the lines
- The same separation could be tested on instance segmentation or video tasks where boundary accuracy matters more than pixel-wise semantics.
- If mask proposers improve further, the need for any semantic fine-tuning might disappear entirely in additional vision domains.
- Offline feature banks suggest a path toward zero-shot adaptation for other label-scarce problems by swapping in different foundation models.
Load-bearing premise
A general mask proposer will reliably produce geometric proposals with accurate boundaries and semantic foundation models will supply an offline feature bank good enough for high-quality non-parametric retrieval and prototype extraction without any adaptation.
What would settle it
Running ModuSeg on a held-out benchmark dataset and observing that boundary F-scores fall below those of standard weakly-supervised baselines or that mean intersection-over-union drops more than 5 points would falsify the claim that decoupling preserves fine boundaries and delivers competitive results.
Figures


read the original abstract
Weakly supervised semantic segmentation aims to achieve pixel-level predictions using image-level labels. Existing methods typically entangle semantic recognition and object localization, which often leads models to focus exclusively on sparse discriminative regions. Although foundation models show immense potential, many approaches still follow the tightly coupled optimization paradigm, struggling to effectively alleviate pseudo-label noise and often relying on time-consuming multi-stage retraining or unstable end-to-end joint optimization. To address the above challenges, we present ModuSeg, a training-free weakly supervised semantic segmentation framework centered on explicitly decoupling object discovery and semantic assignment. Specifically, we integrate a general mask proposer to extract geometric proposals with reliable boundaries, while leveraging semantic foundation models to construct an offline feature bank, transforming segmentation into a non-parametric feature retrieval process. Furthermore, we propose semantic boundary purification and soft-masked feature aggregation strategies to effectively mitigate boundary ambiguity and quantization errors, thereby extracting high-quality category prototypes. Extensive experiments demonstrate that the proposed decoupled architecture better preserves fine boundaries without parameter fine-tuning and achieves highly competitive performance on standard benchmark datasets. Code is available at https://github.com/Autumnair007/ModuSeg.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ModuSeg, a training-free framework for weakly supervised semantic segmentation that explicitly decouples object discovery (via a general mask proposer generating geometric proposals) from semantic assignment (via non-parametric retrieval against an offline feature bank built from semantic foundation models). It introduces semantic boundary purification and soft-masked feature aggregation to address boundary ambiguity and quantization errors when extracting category prototypes. The central claims are that this decoupled architecture preserves fine boundaries better than entangled methods and achieves highly competitive performance on standard benchmarks without any parameter fine-tuning or retraining.
Significance. If the performance and boundary claims hold under the stated assumptions, the work is significant for WSSS because it avoids pseudo-label noise and multi-stage optimization by treating segmentation as modular, non-parametric retrieval over foundation-model features. The public code release supports reproducibility and allows direct inspection of the pipeline. This modular design could influence subsequent work on leveraging frozen foundation models for dense prediction tasks.
major comments (2)
- [§3.2 and §3.3] §3.2 (semantic boundary purification) and §3.3 (soft-masked feature aggregation): these post-processing steps operate on already-quantized proposals from the mask proposer; if the proposer systematically misses fine structures or produces incomplete boundaries, the purification and aggregation cannot recover them. No ablation or failure-case analysis on mask-proposer quality (e.g., SAM vs. alternatives, or on images with thin structures) is provided, leaving the claim of “better preserves fine boundaries” dependent on an untested external module.
- [Experiments section (4.1–4.3)] Experiments section (4.1–4.3): the abstract and introduction assert “highly competitive performance” and “extensive experiments,” yet the manuscript provides no quantitative tables comparing mIoU on PASCAL VOC 2012 or MS-COCO against recent training-free and weakly-supervised baselines, nor ablations isolating the contribution of boundary purification versus soft-masked aggregation. Without these numbers and controls, the central claim that decoupling yields superior boundary fidelity cannot be verified.
minor comments (2)
- [Abstract] Abstract: the phrase “highly competitive performance on standard benchmark datasets” should be accompanied by at least one concrete mIoU figure and dataset name to allow immediate assessment.
- [§3.1] Notation in §3.1: the construction of the offline feature bank and the exact non-parametric retrieval operation (e.g., cosine similarity threshold or top-k selection) are described only at a high level; explicit equations or pseudocode would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will incorporate revisions to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [§3.2 and §3.3] §3.2 (semantic boundary purification) and §3.3 (soft-masked feature aggregation): these post-processing steps operate on already-quantized proposals from the mask proposer; if the proposer systematically misses fine structures or produces incomplete boundaries, the purification and aggregation cannot recover them. No ablation or failure-case analysis on mask-proposer quality (e.g., SAM vs. alternatives, or on images with thin structures) is provided, leaving the claim of “better preserves fine boundaries” dependent on an untested external module.
Authors: We agree that the post-processing modules build on the geometric proposals and cannot invent structures absent from the initial mask proposer. Our core argument is that explicit decoupling permits the use of high-quality, training-free proposers (such as SAM) whose boundary fidelity is already superior to the coarse localization maps produced by entangled end-to-end models; the purification and aggregation steps then refine these proposals for semantic consistency. To make this dependence explicit and to support the boundary-preservation claim, we will add (i) an ablation replacing the default proposer with alternative mask generators and (ii) qualitative and quantitative failure-case analysis on images containing thin structures. These results will be included in the revised manuscript. revision: yes
-
Referee: [Experiments section (4.1–4.3)] Experiments section (4.1–4.3): the abstract and introduction assert “highly competitive performance” and “extensive experiments,” yet the manuscript provides no quantitative tables comparing mIoU on PASCAL VOC 2012 or MS-COCO against recent training-free and weakly-supervised baselines, nor ablations isolating the contribution of boundary purification versus soft-masked aggregation. Without these numbers and controls, the central claim that decoupling yields superior boundary fidelity cannot be verified.
Authors: We acknowledge that the experimental presentation in the submitted version lacked the breadth required to fully substantiate the performance claims. The revised manuscript will expand Sections 4.1–4.3 with (i) complete mIoU tables on both PASCAL VOC 2012 and MS-COCO that include the most recent training-free and weakly-supervised baselines and (ii) controlled ablations that separately disable semantic boundary purification and soft-masked feature aggregation. These additions will allow direct verification of the numerical gains and of the contribution of each proposed component to boundary fidelity. revision: yes
Circularity Check
No significant circularity; derivation relies on external pre-trained modules without internal reduction to fitted inputs
full rationale
The paper presents a training-free framework that explicitly decouples object discovery (via an integrated general mask proposer) from semantic assignment (via offline feature bank from semantic foundation models), followed by boundary purification and soft-masked aggregation. No equations, self-referential predictions, or self-citation chains are shown that would reduce outputs to parameters fitted on the same data or to prior author work by construction. Performance is evaluated on standard benchmarks using these external components without adaptation or joint optimization, keeping the derivation independent and self-contained against external benchmarks rather than internally circular.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption General mask proposers extract geometric proposals with reliable boundaries
- domain assumption Semantic foundation models produce feature banks suitable for non-parametric retrieval and prototype construction
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Ahn, J., Kwak, S.: Learning pixel-level semantic affinity with image-level super- vision for weakly supervised semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4981–4990 (2018)
work page 2018
-
[2]
arXiv preprint arXiv:2512.01701 (2025)
Bi, X., Xiao, D., Fan, J., Xiao, B.: Ssr: Semantic and spatial rectification for clip- based weakly supervised segmentation. arXiv preprint arXiv:2512.01701 (2025)
-
[3]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, Z., Sun, Q.: Extracting class activation maps from non-discriminative fea- tures as well. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3135–3144 (2023)
work page 2023
-
[4]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Cho,S.,Shin,H.,Hong,S.,Arnab,A.,Seo,P.H.,Kim,S.:Cat-seg:Costaggregation for open-vocabulary semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4113–4123 (2024)
work page 2024
-
[5]
IEEE Transactions on Big Data (2025)
Douze, M., Guzhva, A., Deng, C., Johnson, J., Szilvasy, G., Mazaré, P.E., Lomeli, M., Hosseini, L., Jégou, H.: The faiss library. IEEE Transactions on Big Data (2025)
work page 2025
-
[6]
Everingham, M., Eslami, S.A., Van Gool, L., Williams, C.K., Winn, J., Zisserman, A.:Thepascalvisualobjectclasseschallenge:Aretrospective.Internationaljournal of computer vision111(1), 98–136 (2015)
work page 2015
-
[7]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Hanna, J., Borth, D.: Know your attention maps: Class-specific token masking for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 23763–23772 (2025)
work page 2025
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Kweon, H., Yoon, K.J.: From sam to cams: Exploring segment anything model for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19499–19509 (2024)
work page 2024
-
[9]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, Y., Cheng, T., Feng, B., Liu, W., Wang, X.: Mask-adapter: The devil is in the masks for open-vocabulary segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14998–15008 (2025)
work page 2025
-
[10]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
work page 2014
-
[11]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Lin, Y., Chen, M., Wang, W., Wu, B., Li, K., Lin, B., Liu, H., He, X.: Clip is also an efficient segmenter: A text-driven approach for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 15305–15314 (2023)
work page 2023
-
[12]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Advances in neural information processing sys- tems32(2019)
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al.: Pytorch: An imperative style, high- performance deep learning library. Advances in neural information processing sys- tems32(2019)
work page 2019
-
[14]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Pinheiro, P.O., Collobert, R.: From image-level to pixel-level labeling with convo- lutional networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1713–1721 (2015)
work page 2015
-
[15]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Qi, L., Kuen, J., Shen, T., Gu, J., Li, W., Guo, W., Jia, J., Lin, Z., Yang, M.H.: High quality entity segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 4047–4056 (October 2023)
work page 2023
-
[16]
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from 16 Q. He et al. natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
work page 2021
-
[17]
arXiv preprint arXiv:2601.17237 (2026) 13
Ranzinger, M., Heinrich, G., McCarthy, C., Kautz, J., Tao, A., Catanzaro, B., Molchanov, P.: C-radiov4 (tech report). arXiv preprint arXiv:2601.17237 (2026)
-
[18]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al.: Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ru, L., Zhan, Y., Yu, B., Du, B.: Learning affinity from attention: End-to-end weakly-supervised semantic segmentation with transformers. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16846– 16855 (2022)
work page 2022
-
[20]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ru, L., Zheng, H., Zhan, Y., Du, B.: Token contrast for weakly-supervised semantic segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3093–3102 (2023)
work page 2023
-
[21]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Shi, Y., Dong, M., Xu, C.: Harnessing vision foundation models for high- performance, training-free open vocabulary segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 23487–23497 (2025)
work page 2025
-
[22]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Tang, F., Xu, Z., Qu, Z., Feng, W., Jiang, X., Ge, Z.: Hunting attributes: Con- text prototype-aware learning for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 3324–3334 (2024)
work page 2024
-
[24]
IEEE Transactions on Image Processing34, 1036–1047 (2025)
Tang, Q., Liu, C., Liu, F., Jiang, J., Zhang, B., Chen, C.P., Han, K., Wang, Y.: Re- thinking feature reconstruction via category prototype in semantic segmentation. IEEE Transactions on Image Processing34, 1036–1047 (2025)
work page 2025
-
[25]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wang, J., Dai, T., Zhang, B., Yu, S., Lim, E.G., Xiao, J.: Class token as proxy: Optimal transport-assisted proxy learning for weakly supervised semantic segmen- tation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 21645–21654 (2025)
work page 2025
-
[26]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, J., Dai, T., Zhang, B., Yu, S., Lim, E.G., Xiao, J.: Pot: Prototypical optimal transport for weakly supervised semantic segmentation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 15055–15064 (2025)
work page 2025
-
[27]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Wu, Y., Li, X., Li, J., Yang, K., Zhu, P., Zhang, S.: Dino is also a semantic guider: Exploiting class-aware affinity for weakly supervised semantic segmentation. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 1389– 1397 (2024)
work page 2024
-
[28]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wu, Y., Ye, X., Yang, K., Li, J., Li, X.: Dupl: Dual student with trustworthy pro- gressive learning for robust weakly supervised semantic segmentation. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3534–3543 (2024)
work page 2024
-
[29]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xie, J., Hou, X., Ye, K., Shen, L.: Clims: Cross language image matching for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4483–4492 (2022)
work page 2022
-
[30]
IEEE transactions on pattern analysis and machine intelligence46(12), 8380–8395 (2024)
Xu, L., Bennamoun, M., Boussaid, F., Laga, H., Ouyang, W., Xu, D.: Mctformer+: Multi-class token transformer for weakly supervised semantic segmentation. IEEE transactions on pattern analysis and machine intelligence46(12), 8380–8395 (2024)
work page 2024
-
[31]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xu, X., Zhang, P., Huang, W., Shen, Y., Chen, H., Lin, J., Li, W., He, G., Xie, J., Lin, S.: Weakly supervised semantic segmentation via progressive confidence ModuSeg: Decoupling Object Discovery and Semantic Retrieval 17 region expansion. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 9829–9838 (2025)
work page 2025
-
[32]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Xu, Z., Tang, F., Chen, Z., Su, Y., Zhao, Z., Zhang, G., Su, J., Ge, Z.: Toward modality gap: Vision prototype learning for weakly-supervised semantic segmenta- tion with clip. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 9023–9031 (2025)
work page 2025
-
[33]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Xuan, X., Deng, Z., Ma, K.L.: Reme: A data-centric framework for training-free open-vocabulary segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 20954–20965 (2025)
work page 2025
-
[34]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yang, Z., Fu, K., Duan, M., Qu, L., Wang, S., Song, Z.: Separate and conquer: De- coupling co-occurrence via decomposition and representation for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3606–3615 (2024)
work page 2024
-
[35]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yang, Z., Meng, Y., Fu, K., Tang, F., Wang, S., Song, Z.: Exploring clip’s dense knowledge for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 20223– 20232 (2025)
work page 2025
-
[36]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Yang, Z., Meng, Y., Fu, K., Wang, S., Song, Z.: More: Class patch attention needs regularization for weakly supervised semantic segmentation. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 9400–9408 (2025)
work page 2025
-
[37]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yoon, S.H., Kwon, H., Kim, H., Yoon, K.J.: Class tokens infusion for weakly su- pervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3595–3605 (2024)
work page 2024
-
[38]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhang, B., Yu, S., Wei, Y., Zhao, Y., Xiao, J.: Frozen clip: A strong backbone for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3796–3806 (2024)
work page 2024
-
[39]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhang, D., Liu, F., Tang, Q.: Corrclip: Reconstructing patch correlations in clip for open-vocabulary semantic segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 24677–24687 (2025)
work page 2025
-
[40]
IEEE Signal Processing Letters (2025)
Zhang, D., Tang, Q., Liu, F., Mei, H., Chen, C.P.: Exploring token-level augmenta- tion in vision transformer for semi-supervised semantic segmentation. IEEE Signal Processing Letters (2025)
work page 2025
-
[41]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., Torralba, A.: Learning deep features for discriminative localization. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2921–2929 (2016)
work page 2016
-
[42]
In: European conference on computer vision
Zhou, C., Loy, C.C., Dai, B.: Extract free dense labels from clip. In: European conference on computer vision. pp. 696–712. Springer (2022)
work page 2022
-
[43]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhou, T., Wang, W., Konukoglu, E., Van Gool, L.: Rethinking semantic segmenta- tion: A prototype view. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2582–2593 (2022)
work page 2022
-
[44]
Interna- tional Journal of Computer Vision133(3), 1085–1105 (2025)
Zhu, L., Wang, X., Feng, J., Cheng, T., Li, Y., Jiang, B., Zhang, D., Han, J.: Weakclip: Adapting clip for weakly-supervised semantic segmentation. Interna- tional Journal of Computer Vision133(3), 1085–1105 (2025)
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.