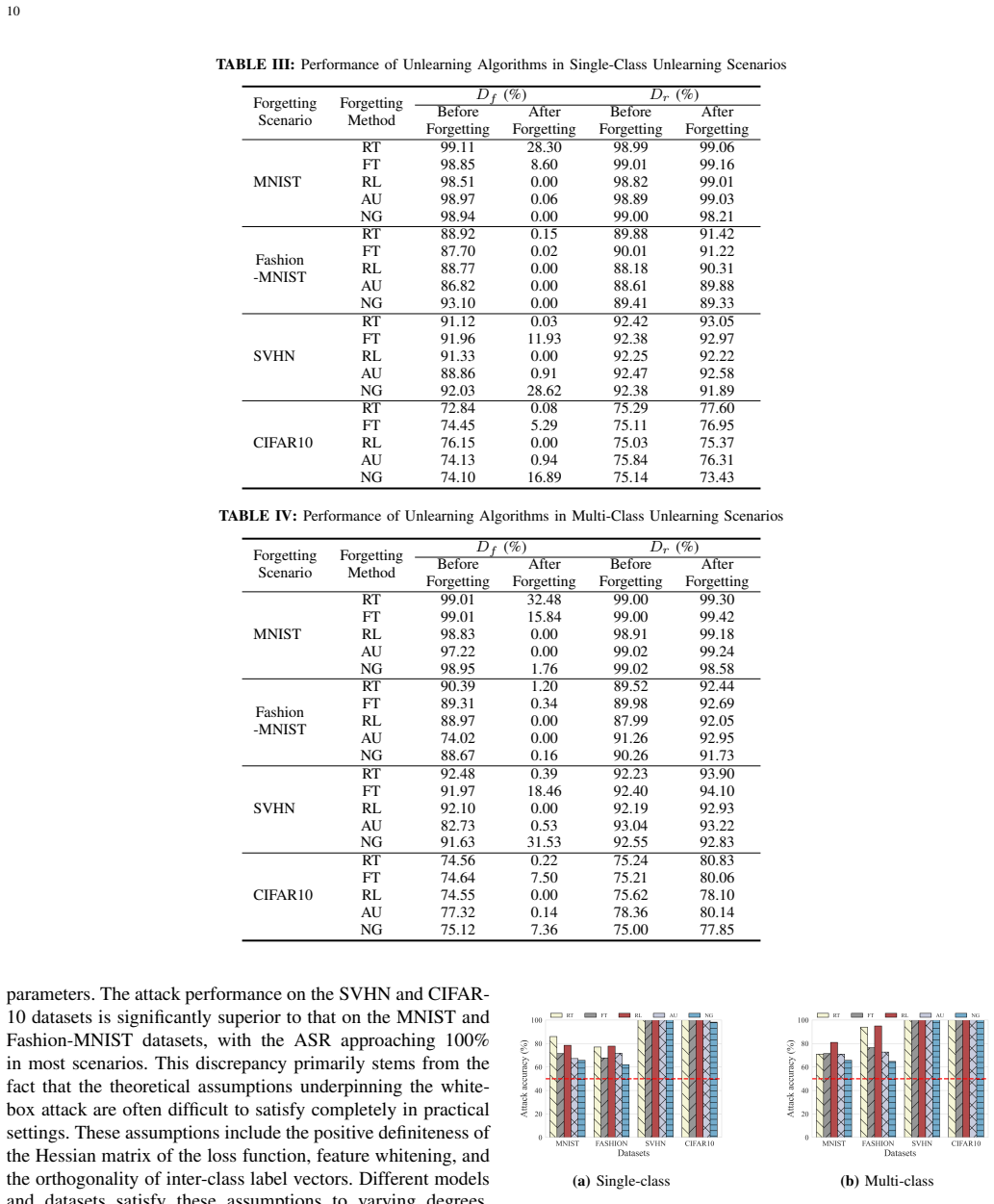
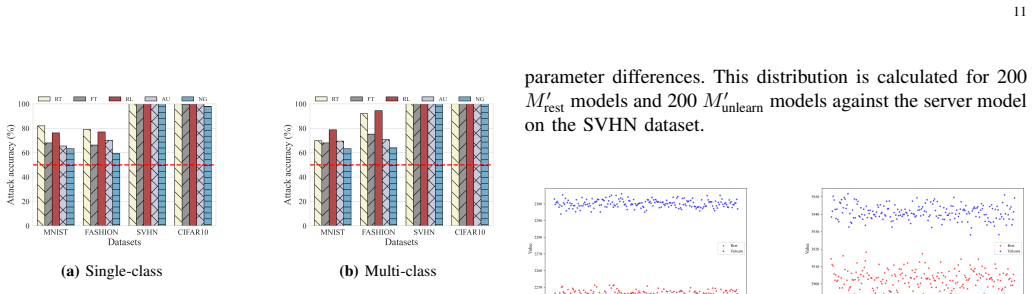
Recognition: no theorem link
Label Leakage Attacks in Machine Unlearning: A Parameter and Inversion-Based Approach
Pith reviewed 2026-05-10 18:00 UTC · model grok-4.3
The pith
Attackers can infer forgotten classes from machine-unlearned models by comparing parameters to auxiliary models or inverting samples to check prediction profiles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that discriminative features extracted from the dot product or vector difference between the target unlearned model's parameters and those of auxiliary models (trained on retained or unrelated data) can be fed to k-means, Youden's Index, or decision trees to identify the forgotten class; separately, white-box gradient optimization and black-box genetic-algorithm inversion can synthesize class-prototypical samples whose prediction profiles, judged by threshold or entropy criteria, also reveal the forgotten class.
What carries the argument
The central mechanism is the construction of parameter-difference features or reconstructed class prototypes whose statistical or predictive signatures distinguish the unlearned class from retained ones.
If this is right
- The parameter attacks succeed with only black-box or white-box access to the target model plus auxiliary training data.
- Inversion attacks reconstruct usable class prototypes that expose the forgotten label via simple entropy or threshold rules.
- All four attacks are shown to work against five current unlearning methods on four standard datasets.
- The paper supplies a comparative analysis of each attack's accuracy, assumptions, and failure modes.
Where Pith is reading between the lines
- Unlearning verification should include explicit tests against parameter-difference and inversion-based label inference.
- Similar leakage risks may appear in other forgetting techniques such as data deletion or selective retraining.
- System designers could add noise to parameters or constrain inversion gradients as a defense, though the paper does not test such countermeasures.
- The work implies that regulatory compliance checks for the right to be forgotten must move beyond accuracy metrics to include leakage resistance.
Load-bearing premise
The attacker can train or obtain auxiliary models on subsets of retained or unrelated data and that unlearning leaves measurable parameter or invertibility traces.
What would settle it
Running the four attacks on a held-out unlearning algorithm and dataset combination and finding that class-inference accuracy stays at random-guessing levels across repeated trials would falsify the leakage claim.
Figures












read the original abstract
With the widespread application of artificial intelligence technologies in face recognition and other fields, data privacy security issues have received extensive attention, especially the \textit{right to be forgotten} emphasized by numerous privacy protection laws. Existing technologies have proposed various unlearning methods, but they may inadvertently leak the categories of unlearned data. This paper focuses on the category unlearning scenario, analyzes the potential problems of category leakage of unlearned data in multiple scenarios, and proposes four attack methods from the perspectives of model parameters and model inversion based on attackers with different knowledge backgrounds. At the level of model parameters, we construct discriminative features by computing either dot products or vector differences between the parameters of the target model and those of auxiliary models trained on subsets of retained data and unrelated data, respectively. These features are then processed via k-means clustering, Youden's Index, and decision tree algorithms to achieve accurate identification of the forgotten class. In the model inversion domain, we design a gradient optimization-based white-box attack and a genetic algorithm-based black-box attack to reconstruct class-prototypical samples. The prediction profiles of these synthesized samples are subsequently analyzed using a threshold criterion and an information entropy criterion to infer the forgotten class. We evaluate the proposed attacks on four standard datasets against five state-of-the-art unlearning algorithms, providing a detailed analysis of the strengths and limitations of each method. Experimental results demonstrate that our approach can effectively infer the classes forgotten by the target model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes four attack methods to infer forgotten classes in machine unlearning for category unlearning scenarios. Two parameter-based attacks construct discriminative features using dot products or vector differences between the target model's parameters and auxiliary models trained on retained and unrelated data subsets, then apply k-means, Youden's Index, and decision trees for classification. Two inversion-based attacks use gradient optimization (white-box) and genetic algorithms (black-box) to reconstruct prototypical samples and analyze their prediction profiles with threshold and entropy criteria. The attacks are evaluated on four datasets against five unlearning algorithms, claiming effective inference of forgotten classes.
Significance. If the experimental results hold under realistic conditions, this work highlights important privacy leakage risks in existing machine unlearning techniques, which is significant for the development of more robust unlearning methods compliant with privacy regulations. The consideration of different attacker knowledge levels (via parameter and inversion approaches) is a strength. However, the significance is tempered by potential limitations in the threat model for the parameter-based attacks.
major comments (1)
- [Abstract and threat model description] The parameter-based attacks assume the attacker can access or sample from the retained dataset to train auxiliary models on subsets of retained data and unrelated data. This is stated as 'subsets of retained data'. In standard 'right to be forgotten' scenarios, retained data is typically not available to external attackers; only the unlearned model and possibly public data would be accessible. If success rates depend heavily on this access, the effectiveness claim applies only to a strong attacker model not explicitly bounded in the threat analysis. Experiments ablating the retained data access should be provided to clarify the scope.
minor comments (1)
- [Abstract] The abstract mentions evaluation on four datasets and five algorithms but does not include any quantitative results, error bars, or specific success rates, which would help in assessing the strength of the claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment on the threat model below and will revise the manuscript to improve clarity on attacker assumptions.
read point-by-point responses
-
Referee: The parameter-based attacks assume the attacker can access or sample from the retained dataset to train auxiliary models on subsets of retained data and unrelated data. This is stated as 'subsets of retained data'. In standard 'right to be forgotten' scenarios, retained data is typically not available to external attackers; only the unlearned model and possibly public data would be accessible. If success rates depend heavily on this access, the effectiveness claim applies only to a strong attacker model not explicitly bounded in the threat analysis. Experiments ablating the retained data access should be provided to clarify the scope.
Authors: We agree that the parameter-based attacks rely on access to subsets of retained data for training auxiliary models, corresponding to a stronger attacker model (e.g., insider or semi-honest service provider). In purely external 'right to be forgotten' settings, this access may not hold. We will revise the manuscript to explicitly bound the threat model for each attack, distinguish attacker knowledge levels, discuss realistic scenarios where retained data access is plausible (such as collaborative settings or public proxies), and add ablation studies on the quantity and availability of retained data to show when the attacks remain effective. This will clarify the scope of our claims without overstating applicability. revision: yes
Circularity Check
No circularity: empirical attack constructions evaluated against external baselines
full rationale
The paper proposes and empirically tests four attack methods (parameter-based feature construction via dot products/differences followed by k-means/Youden/decision-tree classification, plus gradient and genetic-algorithm inversion attacks) on four datasets against five external unlearning algorithms. No equations, first-principles derivations, or predictions are present that reduce by construction to fitted parameters or self-citations. All components are constructed from standard techniques and tested on independent data, making the work self-contained with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Unlearned models retain detectable statistical differences from models trained without the forgotten class.
Reference graph
Works this paper leans on
-
[1]
Membership inference attacks against machine learning models,
R. Shokri, M. Stronati, C. Song, and V . Shmatikov, “Membership inference attacks against machine learning models,” in2017 IEEE symposium on security and privacy (SP). IEEE, 2017, pp. 3–18
2017
-
[2]
Machine unlearning,
L. Bourtoule, V . Chandrasekaran, C. A. Choquette-Choo, H. Jia, A. Travers, B. Zhang, D. Lie, and N. Papernot, “Machine unlearning,” in2021 IEEE symposium on security and privacy (SP). IEEE, 2021, pp. 141–159
2021
-
[3]
Arcane: An efficient architecture for exact machine unlearning
H. Yan, X. Li, Z. Guo, H. Li, F. Li, and X. Lin, “Arcane: An efficient architecture for exact machine unlearning.” inIjcai, vol. 6, 2022, p. 19
2022
-
[4]
Eternal sunshine of the spotless net: Selective forgetting in deep networks,
A. Golatkar, A. Achille, and S. Soatto, “Eternal sunshine of the spotless net: Selective forgetting in deep networks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 9304–9312
2020
-
[5]
Forgetting outside the box: Scrubbing deep networks of informa- tion accessible from input-output observations,
——, “Forgetting outside the box: Scrubbing deep networks of informa- tion accessible from input-output observations,” inEuropean Conference on Computer Vision. Springer, 2020, pp. 383–398
2020
-
[6]
Mixed-privacy forgetting in deep networks,
A. Golatkar, A. Achille, A. Ravichandran, M. Polito, and S. Soatto, “Mixed-privacy forgetting in deep networks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 792–801
2021
-
[7]
arXiv preprint arXiv:1911.03030 (2019)
C. Guo, T. Goldstein, A. Hannun, and L. Van Der Maaten, “Cer- tified data removal from machine learning models,”arXiv preprint arXiv:1911.03030, 2019
-
[8]
Understanding black-box predictions via influence functions,
P. W. Koh and P. Liang, “Understanding black-box predictions via influence functions,” inInternational conference on machine learning. PMLR, 2017, pp. 1885–1894
2017
-
[9]
Our data, ourselves: Privacy via distributed noise generation,
C. Dwork, K. Kenthapadi, F. McSherry, I. Mironov, and M. Naor, “Our data, ourselves: Privacy via distributed noise generation,” inAnnual international conference on the theory and applications of cryptographic techniques. Springer, 2006, pp. 486–503
2006
-
[10]
Puma: Performance unchanged model augmentation for training data removal,
G. Wu, M. Hashemi, and C. Srinivasa, “Puma: Performance unchanged model augmentation for training data removal,” inProceedings of the AAAI conference on artificial intelligence, vol. 36, no. 8, 2022, pp. 8675– 8682
2022
-
[11]
Enhancing ai safety of machine unlearning for ensembled models,
H. Ye, J. Guo, Z. Liu, Y . Jiang, and K.-Y . Lam, “Enhancing ai safety of machine unlearning for ensembled models,”Applied Soft Computing, vol. 174, p. 113011, 2025
2025
-
[12]
When machine unlearning jeopardizes privacy,
M. Chen, Z. Zhang, T. Wang, M. Backes, M. Humbert, and Y . Zhang, “When machine unlearning jeopardizes privacy,” inProceedings of the 2021 ACM SIGSAC conference on computer and communications security, 2021, pp. 896–911
2021
-
[13]
Learn what you want to unlearn: Unlearning inversion attacks against machine unlearning,
H. Hu, S. Wang, T. Dong, and M. Xue, “Learn what you want to unlearn: Unlearning inversion attacks against machine unlearning,” in2024 IEEE Symposium on Security and Privacy (SP). IEEE, 2024, pp. 3257–3275
2024
-
[14]
General data protection regulation (gdpr),
European Union, “General data protection regulation (gdpr),”
-
[15]
Available: https://eur-lex.europa.eu/legal-content/EN/ TXT/PDF/?uri=CELEX:32016R0679
[Online]. Available: https://eur-lex.europa.eu/legal-content/EN/ TXT/PDF/?uri=CELEX:32016R0679
-
[16]
California consumer privacy act (ccpa),
California Department of Justice, “California consumer privacy act (ccpa),” 2018. [Online]. Available: https://oag.ca.gov/privacy/ccpa
2018
-
[17]
Data security law of the people’s republic of china,
Standing Committee of the National People’s Congress, “Data security law of the people’s republic of china,” National People’s Congress Website, 2021, [Online; accessed 2023-10-01]. [Online]. Available: http://www.npc.gov.cn/npc/c2/c30834/202106/t20210610_311888.html
2021
-
[18]
Towards making systems forget with machine unlearning,
Y . Cao and J. Yang, “Towards making systems forget with machine unlearning,” in2015 IEEE symposium on security and privacy. IEEE, 2015, pp. 463–480
2015
-
[19]
Amnesiac machine learning,
L. Graves, V . Nagisetty, and V . Ganesh, “Amnesiac machine learning,” inProceedings of the AAAI conference on artificial intelligence, vol. 35, no. 13, 2021, pp. 11 516–11 524
2021
-
[20]
Deltagrad: Rapid retraining of machine learning models,
Y . Wu, E. Dobriban, and S. Davidson, “Deltagrad: Rapid retraining of machine learning models,” inInternational Conference on Machine Learning. PMLR, 2020, pp. 10 355–10 366
2020
-
[21]
Model sparsity can simplify machine unlearning,
J. Jia, J. Liu, P. Ram, Y . Yao, G. Liu, Y . Liu, P. Sharma, and S. Liu, “Model sparsity can simplify machine unlearning,”Advances in Neural Information Processing Systems, vol. 36, pp. 51 584–51 605, 2023
2023
-
[22]
Accurate and fast machine unlearning with hessian-guided overfitting approximation,
W. Zheng, W. Zhang, K. Chen, T. Liang, F. Yang, H. Lu, and Y . Pang, “Accurate and fast machine unlearning with hessian-guided overfitting approximation,”Neurocomputing, p. 133369, 2026
2026
-
[23]
Towards safe machine unlearning: A paradigm that mitigates performance degradation,
S. Ye, J. Lu, and G. Zhang, “Towards safe machine unlearning: A paradigm that mitigates performance degradation,” inProceedings of the ACM on Web Conference 2025, 2025, pp. 4635–4652
2025
-
[24]
Feature-based machine unlearning for vertical federated learning in iot networks,
Z. Pan, Z. Ying, Y . Wang, C. Zhang, W. Zhang, W. Zhou, and L. Zhu, “Feature-based machine unlearning for vertical federated learning in iot networks,”IEEE Transactions on Mobile Computing, 2025. 14
2025
-
[25]
Blindu: Blind machine un- learning without revealing erasing data,
W. Wang, Z. Tian, C. Zhang, and S. Yu, “Blindu: Blind machine un- learning without revealing erasing data,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
2026
-
[26]
Selective forgetting: Advancing machine unlearning techniques and evaluation in language models,
L. Wang, X. Zeng, J. Guo, K.-F. Wong, and G. Gottlob, “Selective forgetting: Advancing machine unlearning techniques and evaluation in language models,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 1, 2025, pp. 843–851
2025
-
[27]
Hard to forget: Poisoning attacks on certified machine unlearning,
N. G. Marchant, B. I. Rubinstein, and S. Alfeld, “Hard to forget: Poisoning attacks on certified machine unlearning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 7, 2022, pp. 7691–7700
2022
-
[28]
Hidden poison: Machine unlearning enables camouflaged poisoning attacks,
J. Z. Di, J. Douglas, J. Acharya, G. Kamath, and A. Sekhari, “Hidden poison: Machine unlearning enables camouflaged poisoning attacks,” in NeurIPS ML Safety Workshop, 2022
2022
- [29]
-
[30]
The illusion of unlearning: The unstable nature of machine unlearning in text-to-image diffusion models,
N. George, K. N. Dasaraju, R. R. Chittepu, and K. R. Mopuri, “The illusion of unlearning: The unstable nature of machine unlearning in text-to-image diffusion models,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 13 393–13 402
2025
-
[31]
Model inversion attacks that exploit confidence information and basic countermeasures,
M. Fredrikson, S. Jha, and T. Ristenpart, “Model inversion attacks that exploit confidence information and basic countermeasures,” in Proceedings of the 22nd ACM SIGSAC conference on computer and communications security, 2015, pp. 1322–1333
2015
-
[32]
Reading digits in natural images with unsupervised feature learning,
Y . Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, A. Y . Nget al., “Reading digits in natural images with unsupervised feature learning,” inNIPS workshop on deep learning and unsupervised feature learning, vol. 2011, no. 2. Granada, 2011, p. 4
2011
-
[33]
Cifar-10 dataset (canadian institute for advanced research, 10 classes),
A. Krizhevsky, V . Nair, and G. Hinton, “Cifar-10 dataset (canadian institute for advanced research, 10 classes),” University of Toronto, Department of Computer Science, 2009, [Online; accessed 2023-10-01]. [Online]. Available: http://www.cs.toronto.edu/~kriz/cifar.html
2009
-
[34]
The mnist database of handwritten digits,
Y . LeCun, C. Cortes, and C. J. C. Burges, “The mnist database of handwritten digits,” AT&T Labs, 1998, [Online; accessed 2023-10-01]. [Online]. Available: http://yann.lecun.com/exdb/mnist/
1998
-
[35]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
H. Xiao, K. Rasul, and R. V ollgraf, “Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms,”arXiv preprint arXiv:1708.07747, 2017
work page internal anchor Pith review arXiv 2017
-
[36]
Catastrophic forgetting in connectionist networks,
R. M. French, “Catastrophic forgetting in connectionist networks,” Trends in cognitive sciences, vol. 3, no. 4, pp. 128–135, 1999
1999
-
[37]
An Empirical Investigation of Catastrophic Forgetting in Gradient-Based Neural Networks
I. J. Goodfellow, M. Mirza, D. Xiao, A. Courville, and Y . Bengio, “An empirical investigation of catastrophic forgetting in gradient-based neural networks,”arXiv preprint arXiv:1312.6211, 2013
work page Pith review arXiv 2013
-
[38]
Backdoor defense with machine unlearning,
Y . Liu, M. Fan, C. Chen, X. Liu, Z. Ma, L. Wang, and J. Ma, “Backdoor defense with machine unlearning,” inIEEE INFOCOM 2022-IEEE conference on computer communications. IEEE, 2022, pp. 280–289
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.