Recognition: unknown
Dual-Rerank: Fusing Causality and Utility for Industrial Generative Reranking
Pith reviewed 2026-05-10 17:30 UTC · model grok-4.3
The pith
Dual-Rerank fuses autoregressive sequential modeling with non-autoregressive speed and stable reinforcement learning to optimize whole-page utility in large-scale video reranking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
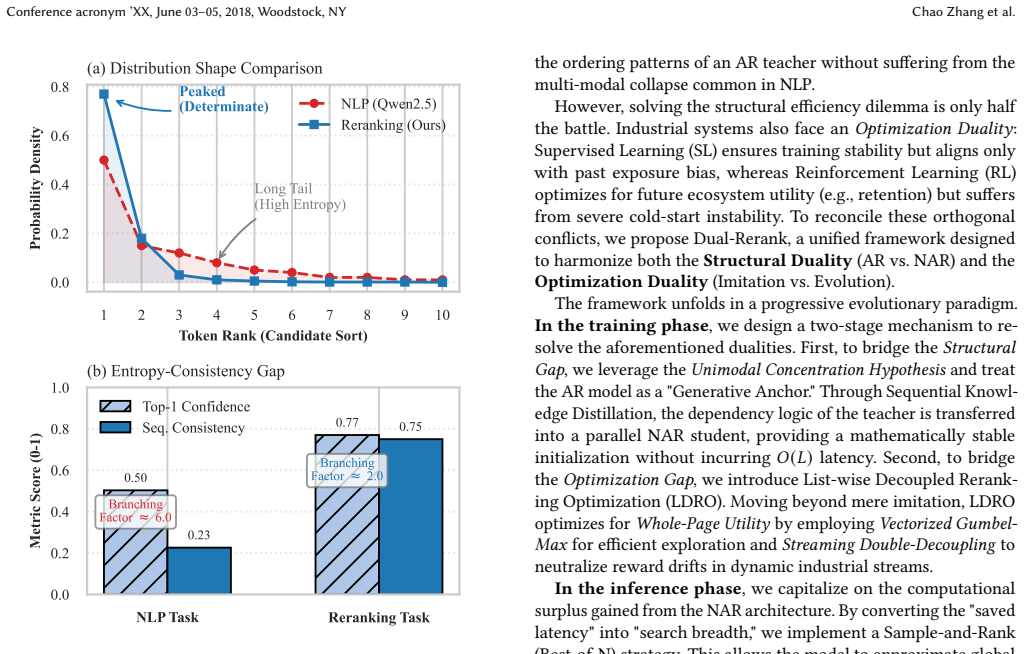
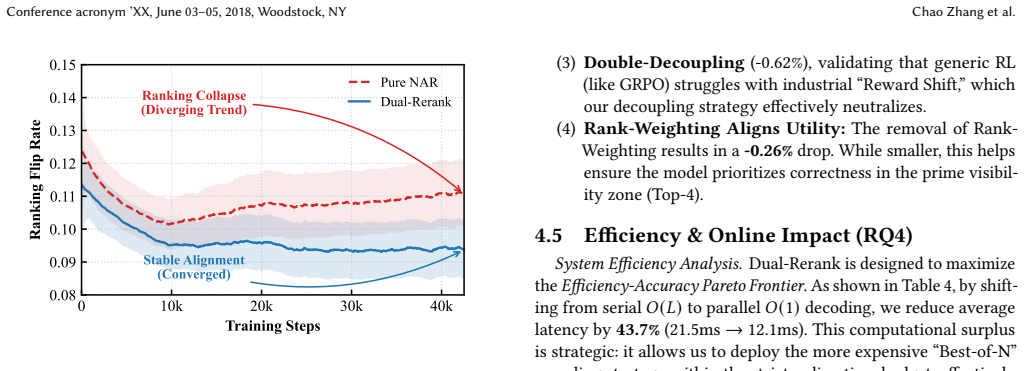
Dual-Rerank resolves the structural trade-off by Sequential Knowledge Distillation, which lets a non-autoregressive model inherit the permutation modeling of an autoregressive teacher, and resolves the optimization trade-off by List-wise Decoupled Reranking Optimization, which enables stable online reinforcement learning that directly maximizes whole-page utility rather than point-wise scores.
What carries the argument
Sequential Knowledge Distillation paired with List-wise Decoupled Reranking Optimization (LDRO), where distillation moves dependency structure into a parallel model and LDRO decouples list-wise ranking signals to stabilize reinforcement learning updates in high-throughput streams.
If this is right
- Non-autoregressive models become viable for dependency-aware reranking once sequential knowledge is distilled from an autoregressive teacher.
- Reinforcement learning can be applied directly to whole-page utility optimization without the instability that previously blocked it in high-volume streams.
- Inference latency drops sharply relative to autoregressive generative rerankers while user metrics improve.
- List-wise optimization replaces point-wise scoring as the practical target for final-stage recommendation.
- Production systems can run full generative reranking at the scale of hundreds of millions of queries per day.
Where Pith is reading between the lines
- The same distillation-plus-decoupled-RL pattern could transfer to other latency-sensitive ranking tasks such as e-commerce product lists or web search results.
- If LDRO generalizes, it offers a route to stable online RL for any list-wise decision problem where data arrives in continuous high-volume streams.
- Hybrid teacher-student generative architectures may become the default choice for industrial reranking whenever both ordering accuracy and sub-second latency are required.
- Future deployments could test whether the same framework improves metrics beyond watch time, such as session length or content diversity.
Load-bearing premise
That distilling sequential dependencies from an autoregressive model into a non-autoregressive one preserves enough ordering information to improve page utility without quality loss, and that the decoupled optimizer keeps reinforcement learning stable under real production traffic volumes.
What would settle it
An A/B test on live traffic in which the Dual-Rerank model shows no statistically significant lift in watch time or user satisfaction, or exhibits higher inference latency than the autoregressive baseline.
Figures




read the original abstract
Kuaishou serves over 400 million daily active users, processing hundreds of millions of search queries daily against a repository of tens of billions of short videos. As the final decision layer, the reranking stage determines user experience by optimizing whole-page utility. While traditional score-and-sort methods fail to capture combinatorial dependencies, Generative Reranking offers a superior paradigm by directly modeling the permutation probability. However, deploying Generative Reranking in such a high-stakes environment faces a fundamental dual dilemma: 1) the structural trade-off where Autoregressive (AR) models offer superior Sequential modeling but suffer from prohibitive latency, versus Non-Autoregressive (NAR) models that enable efficiency but lack dependency capturing; 2) the optimization gap where Supervised Learning faces challenges in directly optimizing whole-page utility, while Reinforcement Learning (RL) struggles with instability in high-throughput data streams. To resolve this, we propose Dual-Rerank, a unified framework designed for industrial reranking that bridges the structural gap via Sequential Knowledge Distillation and addresses the optimization gap using List-wise Decoupled Reranking Optimization (LDRO) for stable online RL. Extensive A/B testing on production traffic demonstrates that Dual-Rerank achieves State-of-the-Art performance, significantly improving User satisfaction and Watch Time while drastically reducing inference latency compared to AR baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Dual-Rerank, a unified framework for industrial generative reranking that bridges the structural gap between autoregressive (AR) and non-autoregressive (NAR) models via Sequential Knowledge Distillation, and addresses the optimization gap between supervised learning and reinforcement learning via List-wise Decoupled Reranking Optimization (LDRO) for stable online RL. It claims state-of-the-art results from extensive A/B testing on Kuaishou production traffic, with gains in user satisfaction and watch time alongside reduced inference latency versus AR baselines.
Significance. If the central claims hold, the work has clear significance for large-scale recommender systems by making generative reranking deployable at industrial scale. The combination of distillation for sequential modeling and a decoupled RL objective targets two practical barriers simultaneously, and the reliance on production A/B tests rather than offline metrics is a methodological strength that grounds the evaluation in real user utility.
major comments (2)
- [Abstract / LDRO description] The abstract states that LDRO resolves the optimization gap by enabling stable online RL through decoupling, yet supplies no derivation, surrogate objective, or variance analysis showing that the decoupled list-wise objective bounds gradient variance relative to standard policy gradients on heavy-tailed, non-stationary rewards such as watch time. This is load-bearing for the claim that ordinary RL fails while LDRO succeeds.
- [Abstract / Experimental evaluation] The abstract asserts SOTA performance and significant improvements in user satisfaction and watch time from A/B tests on production traffic, but provides no information on baselines, number of trials, statistical tests, effect sizes, or ablations isolating the contributions of Sequential Knowledge Distillation versus LDRO. Without these, the empirical support for the dual-gap resolution cannot be evaluated.
minor comments (1)
- [Abstract] Notation for the list-wise utility and the decoupled surrogate could be introduced earlier with explicit definitions to aid readability.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive comments. We address each major point below and clarify the content of the full manuscript while making targeted revisions to improve clarity.
read point-by-point responses
-
Referee: [Abstract / LDRO description] The abstract states that LDRO resolves the optimization gap by enabling stable online RL through decoupling, yet supplies no derivation, surrogate objective, or variance analysis showing that the decoupled list-wise objective bounds gradient variance relative to standard policy gradients on heavy-tailed, non-stationary rewards such as watch time. This is load-bearing for the claim that ordinary RL fails while LDRO succeeds.
Authors: The abstract is a concise summary. The full manuscript derives the LDRO surrogate objective in Section 3.2, showing how list-wise decoupling separates reward estimation from the policy update to reduce variance on non-stationary rewards such as watch time. We include the mathematical formulation, comparison to standard REINFORCE-style gradients, and online stability results. We will revise the abstract to briefly reference this variance-reduction property. revision: yes
-
Referee: [Abstract / Experimental evaluation] The abstract asserts SOTA performance and significant improvements in user satisfaction and watch time from A/B tests on production traffic, but provides no information on baselines, number of trials, statistical tests, effect sizes, or ablations isolating the contributions of Sequential Knowledge Distillation versus LDRO. Without these, the empirical support for the dual-gap resolution cannot be evaluated.
Authors: Detailed information on baselines (AR and NAR generative models plus standard RL), A/B test protocol (multiple independent production runs), statistical tests, effect sizes, and ablations that isolate Sequential Knowledge Distillation from LDRO appears in Section 5. We will update the abstract to include the main quantitative gains and a short statement on the ablation findings. revision: partial
Circularity Check
No circularity: methods presented as standard combinations with external A/B validation
full rationale
The paper introduces Dual-Rerank via Sequential Knowledge Distillation and LDRO without any equations, derivations, or parameter-fitting steps shown in the provided text. These are described as applications of existing distillation and RL techniques to address structural and optimization gaps, with claims resting on production A/B tests rather than self-referential reductions. No load-bearing self-citations, ansatzes, or renamings of known results are evident. The derivation chain is self-contained and externally falsifiable via real-world metrics.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bruce Croft
Qingyao Ai, Keping Bi, Jiafeng Guo, and W. Bruce Croft. 2018. Learning a Deep Listwise Context Model for Ranking Refinement. InProceedings of the 41st International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR). 135–144
2018
- [2]
-
[3]
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al
-
[4]
InProceedings of the 1st Workshop on Deep Learning for Recommender Systems (DLRS@RecSys)
Wide & Deep Learning for Recommender Systems. InProceedings of the 1st Workshop on Deep Learning for Recommender Systems (DLRS@RecSys). 7–10
-
[5]
Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio. 2014. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555(2014)
work page internal anchor Pith review arXiv 2014
-
[6]
Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep Neural Networks for YouTube Recommendations. InProceedings of the 10th ACM Conference on Recommender Systems (RecSys). 191–198
2016
- [7]
- [8]
-
[9]
Jingtong Gao, Bo Chen, Xiangyu Zhao, Weiwen Liu, Xiangyang Li, Yichao Wang, Wanyu Wang, Huifeng Guo, and Ruiming Tang. [n. d.]. LLM4Rerank: LLM-based Auto-Reranking Framework for Recommendations. InTHE WEB CONFERENCE 2025
2025
-
[10]
Jingtong Gao, Bo Chen, Xiangyu Zhao, Weiwen Liu, Xiangyang Li, Yichao Wang, Wanyu Wang, Huifeng Guo, and Ruiming Tang. 2025. LLM4Rerank: LLM-based Auto-Reranking Framework for Recommendations. InProceedings of the Web Conference 2025 (WWW)
2025
-
[11]
Xudong Gong, Qinlin Feng, Yuan Zhang, Jiangling Qin, Weijie Ding, Biao Li, Peng Jiang, and Kun Gai. 2022. Real-time Short Video Recommendation on Mobile Devices. InProceedings of the 31st ACM International Conference on Information and Knowledge Management (CIKM). 3103–3112
2022
-
[12]
Li, and Richard Socher
Jiatao Gu, James Bradbury, Caiming Xiong, Victor O.K. Li, and Richard Socher
-
[13]
InInternational Confer- ence on Learning Representations
Non-Autoregressive Neural Machine Translation. InInternational Confer- ence on Learning Representations. https://openreview.net/forum?id=B1l8BtlCb
-
[14]
Eugene Ie, Vihan Jain, Jing Wang, Sanmit Narvekar, Ritesh Agarwal, Rui Wu, Heng-Tze Cheng, Tushar Chandra, and Craig Boutilier. 2019. SlateQ: A Tractable Decomposition for Reinforcement Learning with Recommendation Sets. InPro- ceedings of the 28th International Joint Conference on Artificial Intelligence (IJCAI). 2592–2599
2019
-
[15]
Ray Jiang, Sven Gowal, Timothy A. Mann, and Danilo J. Rezende. 2018. Be- yond Greedy Ranking: Slate Optimization via List-CVAE.arXiv preprint arXiv:1803.01682(2018)
-
[16]
Xiao Lin, Xiaokai Chen, Chenyang Wang, Hantao Shu, Linfeng Song, Biao Li, and Peng Jiang. 2024. Discrete Conditional Diffusion for Reranking in Rec- ommendation. InCompanion Proceedings of the Web Conference 2024 (WWW). 161–169
2024
- [17]
-
[18]
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le
-
[19]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [20]
- [21]
- [22]
-
[23]
Xiangyu Liu, Chuan Yu, Zhilin Zhang, Zhenzhe Zheng, Yu Rong, Hongtao Lv, and Fuchun Sun. 2021. Variation Control and Evaluation for Generative Slate Recommendations. InProceedings of The Web Conference 2021 (WWW). 436–448
2021
-
[24]
Yue Meng, Cheng Guo, Yi Cao, Tong Liu, and Bo Zheng. 2025. A Generative Re- ranking Model for List-level Multi-objective Optimization at Taobao. InProceed- ings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 4213–4218
2025
-
[25]
Liang Pang, Jun Xu, Qingyao Ai, Yanyan Lan, Xueqi Cheng, and Jirong Wen
-
[26]
InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval
SetRank: Learning a Permutation-Invariant Ranking Model for Informa- tion Retrieval. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 499–508
-
[27]
Changhua Pei, Yi Zhang, Yongfeng Zhang, Fei Sun, Xiao Lin, Hanxiao Sun, Jian Wu, Peng Jiang, Junfeng Ge, and Wenwu Ou. 2019. Personalized Re-ranking for Recommendation. InProceedings of the 13th ACM Conference on Recommender Systems (RecSys). 3–11
2019
-
[28]
Changle Qu, Sunhao Dai, Ke Guo, Liqin Zhao, Yanan Niu, Xiao Zhang, and Jun Xu. 2025. KuaiLive: A Real-time Interactive Dataset for Live Streaming Recommendation.arXiv preprint arXiv:2508.05633(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Yuxin Ren, Qiya Yang, Yichun Wu, Wei Xu, Yalong Wang, and Zhiqiang Zhang
-
[30]
InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD)
Non-autoregressive Generative Models for Reranking Recommendation. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD). 5625–5634
-
[31]
Xiaowen Shi, Fan Yang, Ze Wang, Xiaoxu Wu, Muzhi Guan, Guogang Liao, Yongkang Wang, Xingxing Wang, and Dong Wang. 2023. PIER: Permutation-Level Interest-Based End-to-End Re-ranking Framework in E-commerce. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD). 4823–4831
2023
-
[32]
Ilya Sutskever, Oriol Vinyals, and Quoc V Le. 2014. Sequence to sequence learning with neural networks.Advances in neural information processing systems27 (2014)
2014
-
[33]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[34]
Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017. Deep & Cross Network for Ad Click Predictions. InProceedings of the ADKDD’17. 1–7
2017
-
[35]
Shuli Wang, Xue Wei, Senjie Kou, Chi Wang, Wenshuai Chen, Qi Tang, Yinhua Zhu, Xiong Xiao, and Xingxing Wang. 2025. NLGR: Utilizing Neighbor Lists for Generative Rerank in Personalized Recommendation Systems. InCompanion Proceedings of the ACM on Web Conference 2025. 530–537
2025
- [36]
- [37]
-
[38]
Hailan Yang, Zhenyu Qi, Shuchang Liu, Xiaoyu Yang, Xiaobei Wang, Xiang Li, Lantao Hu, Han Li, and Kun Gai. 2025. Comprehensive List Generation for Multi-Generator Reranking. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2025, Padua, Italy, July 13-18, 2025. 2298–2308
2025
- [39]
-
[40]
Haobo Zhang, Qiannan Zhu, and Zhicheng Dou. 2025. Enhancing Reranking for Recommendation with LLMs through User Preference Retrieval. InProceedings of the 31st International Conference on Computational Linguistics. 658–671
2025
- [41]
-
[42]
Tao Zhuang, Wenwu Ou, and Zhirong Wang. 2018. Globally Optimized Mutual Influence Aware Ranking in E-commerce Search.arXiv preprint arXiv:1805.08524 (2018). A Theoretical Analysis In this section, we provide the rigorous mathematical proofs for the feasibility and stability of the Dual-Rerank framework proposed in the main text. A.1 Proof of Feasibility: ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.