Fast Heterogeneous Serving: Scalable Mixed-Scale LLM Allocation for SLO-Constrained Inference
Pith reviewed 2026-05-10 17:57 UTC · model grok-4.3
The pith
Two heuristics allocate mixed-scale LLMs on heterogeneous GPUs in under one second while meeting SLOs and approaching optimal cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
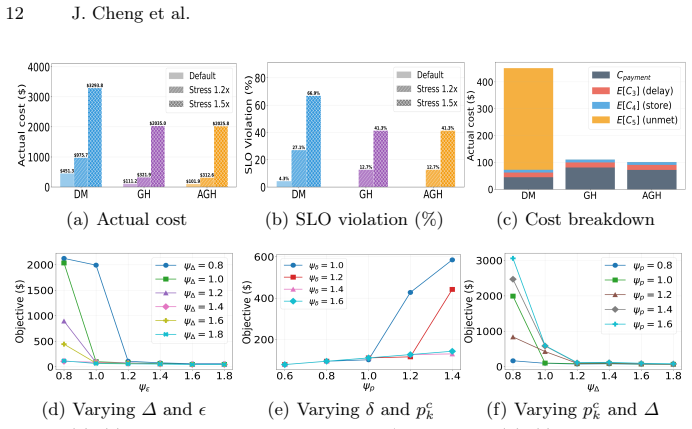
The Adaptive Greedy Heuristic, built from a basic greedy pass plus multi-start construction, relocate local search, and consolidation, together with TP-aware feasibility selection, cost-per-effective-coverage ranking, and TP upgrade, yields feasible allocations in under one second that closely match MILP optimal cost and preserve controlled SLO violations under 1.5x parameter inflation, while the exact solver degrades sharply.
What carries the argument
The Adaptive Greedy Heuristic (AGH) with multi-start construction, relocate-based local search, GPU consolidation, and the three constraint-aware mechanisms of TP-aware feasibility selection, cost-per-effective-coverage ranking, and TP upgrade.
If this is right
- Real-time reallocation becomes feasible for continuously arriving inference requests.
- Operational cost stays near the theoretical minimum without long computation delays.
- Deployments remain stable when model parameter counts shift after initial planning.
- Exact solvers can be reserved for small problems while heuristics handle production scale.
Where Pith is reading between the lines
- The same structure could support online scheduling in cloud systems that adjust GPU pools every few minutes.
- Similar local-search refinements might transfer to other heterogeneous hardware allocation settings such as mixed CPU-GPU training clusters.
- Pre-computing a small library of good starting allocations could cut the multi-start overhead even further.
Load-bearing premise
The three constraint-aware mechanisms can always produce feasible allocations when memory, delay, error, and budget constraints are tightly coupled.
What would settle it
A workload instance where the heuristics output an allocation that violates SLOs or budget while the exact MILP solver finds a feasible lower-cost solution, or where either heuristic takes more than one second on the paper's large-scale instances.
Figures

read the original abstract
Deploying large language model (LLM) inference at scale requires jointly selecting base models, provisioning heterogeneous GPUs, configuring parallelism, and distributing workloads under tight latency, accuracy, and budget constraints. Exact mixed-integer linear programming (MILP) approaches guarantee optimality but scale poorly. We propose two constraint-aware heuristics: a Greedy Heuristic (GH) for single-pass allocation, and an Adaptive Greedy Heuristic (AGH) that enhances GH via multi-start construction, relocate-based local search, and GPU consolidation. Three constraint-aware mechanisms -- TP-aware feasibility selection, cost-per-effective-coverage ranking, and TP upgrade -- ensure feasibility under tightly coupled memory, delay, error, and budget constraints. On workloads calibrated with the Azure LLM Inference Trace (2025), both heuristics produce feasible solutions in under one second, with AGH closely approaching optimal cost while achieving over 260x speedup on large-scale instances. Under out-of-sample stress tests with up to 1.5x parameter inflation, AGH maintains controlled SLO violations and stable cost, whereas the exact solver's placement degrades sharply.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes two constraint-aware heuristics—a single-pass Greedy Heuristic (GH) and an Adaptive Greedy Heuristic (AGH) that adds multi-start construction, relocate-based local search, and GPU consolidation—for jointly selecting base models, heterogeneous GPUs, parallelism degrees, and workload distributions under coupled memory, latency, accuracy, and budget constraints. On workloads derived from the Azure LLM Inference Trace (2025), both heuristics return feasible solutions in under one second; AGH approaches the cost of an exact MILP solver while delivering >260× speedup on large instances. Under out-of-sample stress tests with up to 1.5× parameter inflation, AGH keeps SLO violations controlled and cost stable, whereas the exact solver degrades.
Significance. If the reported speedups and robustness hold, the work would be significant for practical LLM serving systems: it shows that carefully designed, constraint-aware heuristics can make mixed-integer allocation tractable at scale without sacrificing feasibility or solution quality. The explicit use of a public trace for calibration plus controlled out-of-sample inflation provides a reproducible empirical foundation that is stronger than purely synthetic evaluations.
minor comments (3)
- [Abstract] Abstract: the performance claims (sub-second runtimes, 260× speedup, controlled violations) are stated without any reference to the methods section or to the three named mechanisms (TP-aware feasibility selection, cost-per-effective-coverage ranking, TP upgrade); a single sentence summarizing how these mechanisms enforce feasibility would make the abstract self-contained.
- [Evaluation] Evaluation section: while the text describes success on the Azure trace and 1.5× inflation tests, no summary table or figure reports the exact cost ratios, violation counts, or runtime distributions across instance sizes; adding such a table would allow readers to assess the “closely approaching optimal” claim quantitatively.
- [Methods] The manuscript would benefit from a short pseudocode listing or algorithmic sketch of AGH (multi-start + relocate + consolidation) to complement the prose description of the three constraint-aware mechanisms.
Simulated Author's Rebuttal
We thank the referee for the positive and accurate summary of our work on the GH and AGH heuristics for mixed-scale LLM allocation under SLO constraints, as well as for highlighting the significance of the speedups, feasibility guarantees, and reproducible evaluation on the Azure trace with out-of-sample stress tests. The recommendation for minor revision is noted; we will incorporate any editorial or minor clarifications in the revised version.
Circularity Check
No significant circularity
full rationale
The paper presents two new constraint-aware heuristics (GH and AGH) for mixed-scale LLM allocation under SLO constraints and evaluates them empirically against an exact MILP solver on the Azure LLM Inference Trace (2025) plus out-of-sample stress tests. The reported results (feasibility in <1s, 260x speedup, cost proximity, controlled SLO violations) are direct measurements of algorithm runtime and solution quality on external trace data; no equations reduce these outcomes to fitted parameters defined by the same data, no self-citations bear the central claim, and no ansatz or uniqueness theorem is invoked to force the result. The derivation chain consists of algorithmic construction plus benchmark comparison and is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Azure LLM Inference Trace (2025) provides representative workloads for evaluating allocation heuristics under realistic request patterns.
Reference graph
Works this paper leans on
-
[1]
A. Chien, L. Fan, and H. Yeung, “Reducing the carbon impact of generative AI inference (today and in 2035),”arXiv preprint arXiv:2304.03271, 2023
-
[2]
Efficient memory management for large language model serving with PagedAttention,
W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C.H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with PagedAttention,” inProc. SOSP, 2023
work page 2023
-
[3]
DistServe: Disaggregating prefill and decoding for goodput-optimized large language model serving,
Y. Zhong, S. Liu, J. Chen, J. Hu, Y. Zhu, X. Liu, X. Jin, and H. Zhang, “DistServe: Disaggregating prefill and decoding for goodput-optimized large language model serving,” inProc. OSDI, 2024
work page 2024
-
[4]
DynamoLLM: De- signing LLM inference clusters for performance and energy efficiency,
J. Stojkovic, C. Zhang, İ. Goiri, J. Torrellas, and E. Choukse, “DynamoLLM: De- signing LLM inference clusters for performance and energy efficiency,” inProc. HPCA, IEEE, 2025
work page 2025
-
[5]
Helix: Serving large language models over heterogeneous GPUs and network via max-flow,
Y. Mei, Y. Zhuang, X. Miao, J. Yang, Z. Jia, and R. Vinayak, “Helix: Serving large language models over heterogeneous GPUs and network via max-flow,” inProc. ASPLOS, 2025
work page 2025
-
[6]
Demystifyingcost-efficiencyinLLMservingoverheterogeneousGPUs,
Y. Jiang, F. Fu, X. Yao, G. He, X. Miao, A. Klimovic, B. Cui, B. Yuan, and E.Yoneki,“Demystifyingcost-efficiencyinLLMservingoverheterogeneousGPUs,” inProc. ICML, 2025
work page 2025
-
[7]
Greedy randomized adaptive search procedures,
T. A. Feo and M. G. C. Resende, “Greedy randomized adaptive search procedures,” J. Global Optim., vol. 6, pp. 109–133, 1995
work page 1995
-
[8]
Gurobi optimizer reference manual,
Gurobi Optimization, LLC, “Gurobi optimizer reference manual,” 2024. [Online]. Available:https://www.gurobi.com
work page 2024
-
[9]
SeaLLM: Resource sharing for multi-LLM services,
Y. Zhao, J. Chen, P. Sun, L. Li, X. Liu, and X. Jin, “SeaLLM: Resource sharing for multi-LLM services,” inProc. NSDI, 2025
work page 2025
-
[10]
G. Wilkins, S. Keshav, and R. Mortier, “Offline energy-optimal LLM serving,” arXiv preprint arXiv:2407.04014, 2024
-
[11]
SkyLB: Locality-aware cross-region load balancing for LLM serving,
T. Xia, Z. Mao, J. Kerney, E.J. Jackson, Z. Li, J. Xing, S. Shenker, and I. Stoica, “SkyLB: Locality-aware cross-region load balancing for LLM serving,” inProc. SIGCOMM, 2025
work page 2025
-
[12]
Cost-efficient LLM serving with heterogeneous VMs and KV cache offloading,
K. Kim,et al., “Cost-efficient LLM serving with heterogeneous VMs and KV cache offloading,” inProc. EuroSys, 2025
work page 2025
-
[13]
Microsoft Research, “Azure LLM inference trace,” 2025. [Online]. Available:https: //github.com/Azure/AzurePublicDataset
work page 2025
-
[14]
A. Dubey, A. Jauhri, A. Pandey,et al., “The Llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Efficiently scaling transformer inference,
R. Pope, S. Douglas, A. Chowdhery, J. Devlin, J. Bradbury, J. Heek, K. Xiao, S. Agrawal, and J. Dean, “Efficiently scaling transformer inference,” inProc. ML- Sys, vol. 5, 2023
work page 2023
-
[16]
GPTQ: Accurate post- trainingquantizationforgenerativepre-trainedtransformers,
E. Frantar, S. Ashkboos, T. Hoefler, and D. Alistarh, “GPTQ: Accurate post- trainingquantizationforgenerativepre-trainedtransformers,” inProc. ICLR,2023
work page 2023
-
[17]
Splitwise:EfficientgenerativeLLMinferenceusingphasesplitting,
P.Patel,et al.,“Splitwise:EfficientgenerativeLLMinferenceusingphasesplitting,” inProc. ISCA, 2024
work page 2024
-
[18]
Efficientlarge-scalelanguagemodeltrainingonGPUclusters using Megatron-LM,
D.Narayanan,et al.,“Efficientlarge-scalelanguagemodeltrainingonGPUclusters using Megatron-LM,” inProc. SC, 2021
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.