Recognition: no theorem link
Bootstrapping Sign Language Annotations with Sign Language Models
Pith reviewed 2026-05-10 17:46 UTC · model grok-4.3
The pith
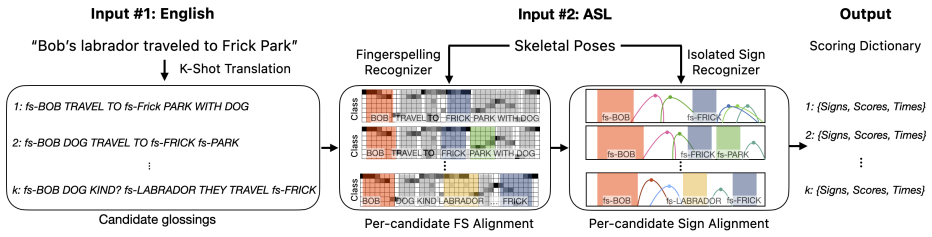
A pseudo-annotation pipeline uses fingerspelling and isolated sign recognizers plus LLM ranking to label large signed video datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes a pipeline that takes signed video and English as input and outputs a ranked set of likely annotations, including time intervals, for glosses, fingerspelled words, and sign classifiers, using sparse predictions from fingerspelling and isolated sign recognizers along with a K-Shot LLM approach.
What carries the argument
The pseudo-annotation pipeline that fuses sparse outputs from a fingerspelling recognizer and an isolated sign recognizer with K-shot large language model ranking.
If this is right
- The pipeline allows generation of over 300 hours of pseudo-annotations for datasets like ASL STEM Wiki.
- Baseline models reach state-of-the-art 6.7% CER on FSBoard for fingerspelling and 74% top-1 accuracy on ASL Citizen for isolated signs.
- New human annotations on nearly 500 videos provide a benchmark for the pseudo-annotations.
- Releasing both human and pseudo labels supports further research on sign language annotation.
- Improved annotation would enable better training of sign language interpretation models.
Where Pith is reading between the lines
- If the method generalizes, it could reduce annotation costs for sign language datasets in other languages by using similar base models.
- The approach might be extended to continuous sign language recognition tasks by incorporating more temporal modeling.
- Releasing the annotations creates an opportunity to test how well LLM ranking performs on other sequence annotation problems.
Load-bearing premise
Sparse predictions from the recognizers combined with K-Shot LLM ranking will yield annotations accurate enough to be useful without extensive human correction.
What would settle it
If the pseudo-annotations show low overlap or accuracy when compared directly to the professional human annotations on the nearly 500 videos, the utility of the pipeline would be called into question.
Figures


read the original abstract
AI-driven sign language interpretation is limited by a lack of high-quality annotated data. New datasets including ASL STEM Wiki and FLEURS-ASL contain professional interpreters and 100s of hours of data but remain only partially annotated and thus underutilized, in part due to the prohibitive costs of annotating at this scale. In this work, we develop a pseudo-annotation pipeline that takes signed video and English as input and outputs a ranked set of likely annotations, including time intervals, for glosses, fingerspelled words, and sign classifiers. Our pipeline uses sparse predictions from our fingerspelling recognizer and isolated sign recognizer (ISR), along with a K-Shot LLM approach, to estimate these annotations. In service of this pipeline, we establish simple yet effective baseline fingerspelling and ISR models, achieving state-of-the-art on FSBoard (6.7% CER) and on ASL Citizen datasets (74% top-1 accuracy). To validate and provide a gold-standard benchmark, a professional interpreter annotated nearly 500 videos from ASL STEM Wiki with sequence-level gloss labels containing glosses, classifiers, and fingerspelling signs. These human annotations and over 300 hours of pseudo-annotations are being released in supplemental material.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a pseudo-annotation pipeline for sign language videos that combines sparse outputs from a fingerspelling recognizer and isolated sign recognizer (ISR) with a K-shot LLM ranking step to generate ranked annotations, including time intervals, for glosses, fingerspelled words, and sign classifiers. It reports state-of-the-art results on the FSBoard dataset (6.7% CER) and ASL Citizen dataset (74% top-1 accuracy), releases a new 500-video human-annotated sequence-level gloss benchmark from ASL STEM Wiki, and provides over 300 hours of pseudo-annotations.
Significance. If the pipeline's outputs prove sufficiently accurate to meaningfully reduce human annotation effort, the work would provide a scalable approach to annotating large sign language corpora such as ASL STEM Wiki and FLEURS-ASL, directly addressing a primary bottleneck in training AI systems for sign language interpretation. The release of both the human gold-standard benchmark and the pseudo-annotations constitutes a concrete, reusable resource for the community.
major comments (1)
- [Abstract] Abstract: the central claim that the pipeline 'outputs a ranked set of likely annotations' usable for bootstrapping is unsupported by any quantitative evaluation. No metrics (gloss matching rate, temporal overlap, ranking quality, or human effort reduction) are reported comparing pipeline outputs to the 500-video human benchmark that the authors themselves created and release.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the pipeline 'outputs a ranked set of likely annotations' usable for bootstrapping is unsupported by any quantitative evaluation. No metrics (gloss matching rate, temporal overlap, ranking quality, or human effort reduction) are reported comparing pipeline outputs to the 500-video human benchmark that the authors themselves created and release.
Authors: We acknowledge that the manuscript does not include a direct quantitative comparison of the full pipeline outputs against the new 500-video human benchmark. The current version validates the pipeline components via state-of-the-art results on FSBoard and ASL Citizen and releases both the human annotations and the pseudo-annotations to support community evaluation. We agree that adding explicit metrics would better substantiate the bootstrapping claim. In the revised manuscript we will include an evaluation on the 500-video set reporting gloss matching rate, temporal overlap for time intervals, ranking quality, and a discussion of human effort reduction, and we will update the abstract to reference these results. revision: yes
Circularity Check
No significant circularity in the pseudo-annotation pipeline derivation
full rationale
The paper constructs its pseudo-annotation pipeline from independently trained fingerspelling and isolated sign recognizers (reporting SOTA on separate external benchmarks FSBoard and ASL Citizen) plus a K-shot LLM ranking step. These inputs are not defined in terms of the pipeline outputs, and no prediction reduces to a fitted parameter or self-definition by construction. The new 500-video human-annotated gold standard is created separately by a professional interpreter and is not used to derive or fit the pipeline itself. No load-bearing self-citations, uniqueness theorems, or ansatz smuggling appear in the derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Fox, Necati Cihan Camgoz, and Richard Bowden
Mohamed Al-Badrashiny, Marco Tanti, Neil C. Fox, Necati Cihan Camgoz, and Richard Bowden. BOBSL: BBC- Oxford british sign language dataset. InEuropean Confer- ence on Computer Vision (ECCV), pages 40–58, 2022. 2
2022
-
[2]
NLTK: The natural language toolkit
Steven Bird and Edward Loper. NLTK: The natural language toolkit. InProceedings of the ACL Interactive Poster and Demonstration Sessions, pages 214–217, Barcelona, Spain, July 2004. Association for Computational Linguistics. 6
2004
-
[3]
Sign Language Recog- nition, Generation, and Translation: An Interdisciplinary Perspective
Danielle Bragg, Oscar Koller, Mary Bellard, Larwan Berke, Patrick Boudreault, Annelies Braffort, Naomi Caselli, Matt Huenerfauth, Hernisa Kacorri, Tessa Verhoef, Christian V ogler, and Meredith Ringel Morris. Sign Language Recog- nition, Generation, and Translation: An Interdisciplinary Perspective. InThe 21st International ACM SIGACCESS Conference on Com...
2019
-
[4]
Neural sign language trans- lation
Necati Cihan Camgoz, Simon Hadfield, Oscar Koller, Her- mann Ney, and Richard Bowden. Neural sign language trans- lation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 7784–7793,
-
[5]
Quo vadis, action recognition? A new model and the kinetics dataset
Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? A new model and the kinetics dataset. InPro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6299–6308, 2017. 2
2017
-
[6]
Asl-lex: A lexical database of american sign language.Behavior research methods, 49(2):784–801, 2017
Naomi K Caselli, Zed Sevcikova Sehyr, Ariel M Cohen- Goldberg, and Karen Emmorey. Asl-lex: A lexical database of american sign language.Behavior research methods, 49(2):784–801, 2017. 6
2017
-
[7]
Factorized learn- ing assisted with large language model for gloss-free sign language translation
Zhigang Chen, Benjia Zhou, Jun Li, Jun Wan, Zhen Lei, Ning Jiang, Quan Lu, and Guoqing Zhao. Factorized learn- ing assisted with large language model for gloss-free sign language translation. In Nicoletta Calzolari, Min-Yen Kan, Veronique Hoste, Alessandro Lenci, Sakriani Sakti, and Ni- anwen Xue, editors,Proceedings of the 2024 Joint Interna- tional Conf...
2024
-
[8]
Google - american sign language fingerspelling recognition, 2023
Ashley Chow, Manfred Georg, Mark Sherwood, Phil Cul- liton, Sam Sepah, Sohier Dane, Thad Starner, and Glenn Cameron. Google - american sign language fingerspelling recognition, 2023. Kaggle Competition. 7
2023
-
[9]
Fleurs: Few-shot learning evaluation of uni- versal representations of speech
Alexis Conneau, Min Ma, Simran Khanuja, Yu Zhang, Vera Axelrod, Siddharth Dalmia, Jason Riesa, Clara Rivera, and Ankur Bapna. Fleurs: Few-shot learning evaluation of uni- versal representations of speech. In2022 IEEE Spoken Lan- guage Technology Workshop (SLT), pages 798–805. IEEE,
-
[10]
Asl cit- izen: a community-sourced dataset for advancing isolated sign language recognition.Advances in Neural Information Processing Systems, 36:76893–76907, 2023
Aashaka Desai, Lauren Berger, Fyodor Minakov, Nessa Mi- lano, Chinmay Singh, Kriston Pumphrey, Richard Ladner, Hal Daum ´e III, Alex X Lu, Naomi Caselli, et al. Asl cit- izen: a community-sourced dataset for advancing isolated sign language recognition.Advances in Neural Information Processing Systems, 36:76893–76907, 2023. 2, 3, 6, 7
2023
-
[11]
Towards automatic sign language annotation for the elan tool
Philippe Dreuw and Hermann Ney. Towards automatic sign language annotation for the elan tool. InWorkshop Pro- gramme, volume 50. 1
-
[12]
How2Sign: A large-scale multimodal dataset for continuous american sign language
Amanda Duarte, Shruti Palaskar, Lucas Ventura, Francisco De la Torre, Florian Metze, and Jimmy Saragih. How2Sign: A large-scale multimodal dataset for continuous american sign language. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2735–2744, 2021. 2, 6
2021
-
[13]
Multiscale vision transformers
Haoqi Fan, Bo Li, Kaiming He, Ross Girshick, and Piotr Doll´ar. Multiscale vision transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 5824–5835, 2021. 2
2021
-
[14]
Slowfast networks for video recognition
Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 6202–6211, 2019. 2
2019
-
[15]
Fsboard: Over 3 million characters of asl fin- gerspelling collected via smartphones
Manfred Georg, Garrett Tanzer, Esha Uboweja, Saad Has- san, Maximus Shengelia, Sam Sepah, Sean Forbes, and Thad Starner. Fsboard: Over 3 million characters of asl fin- gerspelling collected via smartphones. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13897–13906, June 2025. 2, 6, 7
2025
-
[16]
Understanding deaf and hard-of-hearing users’ interest in sign-language interaction with personal-assistant devices
Abraham Glasser, Vaishnavi Mande, and Matt Huenerfauth. Understanding deaf and hard-of-hearing users’ interest in sign-language interaction with personal-assistant devices. In Proceedings of the 18th International Web for All Confer- ence, pages 1–11, 2021. 1
2021
-
[17]
Prosodylab-aligner: A tool for forced alignment of labora- tory speech.Canadian acoustics, 39(3):192–193, 2011
Kyle Gorman, Jonathan Howell, and Michael Wagner. Prosodylab-aligner: A tool for forced alignment of labora- tory speech.Canadian acoustics, 39(3):192–193, 2011. 4
2011
-
[18]
Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks
Alex Graves, Santiago Fern ´andez, Faustino Gomez, and J¨urgen Schmidhuber. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. InProceedings of the 23rd international confer- ence on Machine learning, pages 369–376, 2006. 4
2006
-
[19]
Shubert: Self-supervised sign language representation learning via multi-stream clus- ter prediction
Shester Gueuwou, Xiaodan Du, Greg Shakhnarovich, Karen Livescu, and Alexander H Liu. Shubert: Self-supervised sign language representation learning via multi-stream clus- ter prediction. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025. 7
2025
-
[20]
Hamnosys–representing sign language data in language resources and language processing contexts
Thomas Hanke. Hamnosys–representing sign language data in language resources and language processing contexts. In sign-lang@ LREC 2004, pages 1–6. European Language Re- sources Association (ELRA), 2004. 1
2004
-
[21]
Second language acquisition across modalities: Production variability in adult l2 learn- ers of american sign language.Second Language Research, 31(3):375–388, 2015
Allison I Hilger, Torrey MJ Loucks, David Quinto-Pozos, and Matthew WG Dye. Second language acquisition across modalities: Production variability in adult l2 learn- ers of american sign language.Second Language Research, 31(3):375–388, 2015. 3
2015
-
[22]
Explor- ing very low-resource translation with LLMs: The Univer- sity of Edinburgh’s submission to AmericasNLP 2024 trans- lation task
Vivek Iyer, Bhavitvya Malik, Wenhao Zhu, Pavel Stepachev, Pinzhen Chen, Barry Haddow, and Alexandra Birch. Explor- ing very low-resource translation with LLMs: The Univer- sity of Edinburgh’s submission to AmericasNLP 2024 trans- lation task. In Manuel Mager, Abteen Ebrahimi, Shruti Ri- jhwani, Arturo Oncevay, Luis Chiruzzo, Robert Pugh, and Katharina von...
2024
-
[23]
Lost in translation, found in con- text: Sign language translation with contextual cues
Youngjoon Jang, Haran Raajesh, Liliane Momeni, G¨ul Varol, and Andrew Zisserman. Lost in translation, found in con- text: Sign language translation with contextual cues. In 2025 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 8742–8752, 2025. 1, 2
2025
-
[24]
Aiwei Jiang, Yutong Wang, Bowen Zheng, and Jing Wang. SignLLM: A framework for sign language translation with large language models.arXiv preprint arXiv:2402.13011,
-
[25]
Fingerspelling: Beyond handshape sequences.The Oxford handbook of deaf studies in language, pages 146–160, 2016
Jonathan Keane and Diane Brentari. Fingerspelling: Beyond handshape sequences.The Oxford handbook of deaf studies in language, pages 146–160, 2016. 2
2016
-
[26]
Word-level deep sign language recognition from video: A new large-scale dataset and methods
Dongxu Li, Cristian Rodriguez, Xin Yu, and Hongdong Li. Word-level deep sign language recognition from video: A new large-scale dataset and methods. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1458–1467, 2020. 2
2020
-
[27]
Bridging sign and spoken languages: Pseudo glossgeneration for sign language translation
Peike Li, Trevor Cohn, and Jianyuan Guo. Bridging sign and spoken languages: Pseudo glossgeneration for sign language translation. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. 1, 2, 3
2025
-
[28]
MediaPipe: A Framework for Building Perception Pipelines
Camillo Lugaresi, Jiuqiang Tang, Hadon Nash, Chris Mc- Clanahan, Esha Uboweja, Michael Hays, Fan Zhang, Chuo- Ling Chang, Ming Guang Yong, Juhyun Lee, et al. Medi- apipe: A framework for building perception pipelines.arXiv preprint arXiv:1906.08172, 2019. 4
work page internal anchor Pith review arXiv 1906
-
[29]
Spotter+gpt: Turning sign spottings into sentences with llms
Ozge Mercanoglu Sincan and Richard Bowden. Spotter+gpt: Turning sign spottings into sentences with llms. InAdjunct Proceedings of the 25th ACM International Conference on Intelligent Virtual Agents, IV A Adjunct ’25, page 1–6. ACM, Sept. 2025. 3
2025
-
[30]
How the alphabet came to be used in a sign language.Sign Language Studies, 4(1):10–33, 2003
Carol Padden and Darline Clark Gunsauls. How the alphabet came to be used in a sign language.Sign Language Studies, 4(1):10–33, 2003. 2
2003
-
[31]
Bleu: a Method for Automatic Evaluation of Ma- chine Translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a Method for Automatic Evaluation of Ma- chine Translation. In Pierre Isabelle, Eugene Charniak, and Dekang Lin, editors,Proceedings of the 40th Annual Meet- ing of the Association for Computational Linguistics, pages 311–318, Philadelphia, Pennsylvania, USA, July 2002. As- sociation for C...
2002
-
[32]
Sources of handshape error in first- time signers of asl.Deaf around the world: The impact of language, pages 96–121, 2011
Deborah Chen Pichler. Sources of handshape error in first- time signers of asl.Deaf around the world: The impact of language, pages 96–121, 2011. 15
2011
-
[33]
chrf: character n-gram f-score for automatic mt evaluation
Maja Popovi ´c. chrf: character n-gram f-score for automatic mt evaluation. InProceedings of the tenth workshop on sta- tistical machine translation, pages 392–395, 2015. 7, 14
2015
-
[34]
COMET: A neural framework for MT evaluation
Ricardo Rei, Craig Stewart, Ana C Farinha, and Alon Lavie. COMET: A neural framework for MT evaluation. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu, editors,Pro- ceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2685–2702, Online, Nov. 2020. Association for Computational Linguis- tics. 7, 14
2020
-
[35]
L2m1 and l2m2 acquisition of sign lexicon: The impact of multimodality on the sign second language acquisition.Frontiers in Psychol- ogy, 13:896254, 2022
Krister Sch ¨onstr¨om and Ingela Holmstr¨om. L2m1 and l2m2 acquisition of sign lexicon: The impact of multimodality on the sign second language acquisition.Frontiers in Psychol- ogy, 13:896254, 2022. 3
2022
-
[36]
Bleurt: Learning robust metrics for text generation
Thibault Sellam, Dipanjan Das, and Ankur Parikh. Bleurt: Learning robust metrics for text generation. InProceedings of the 58th annual meeting of the association for computa- tional linguistics, pages 7881–7892, 2020. 7, 14
2020
-
[37]
Open-domain sign language translation learned from online video
Bowen Shi, Diane Brentari, Greg Shakhnarovich, and Karen Livescu. Open-domain sign language translation learned from online video. InEMNLP, 2022. 2
2022
-
[38]
Gloss-free sign language translation: An unbiased evaluation of progress in the field.Computer Vision and Image Understanding, 261:104498, 2025
Ozge Mercanoglu Sincan, Jian He Low, Sobhan Asasi, and Richard Bowden. Gloss-free sign language translation: An unbiased evaluation of progress in the field.Computer Vision and Image Understanding, 261:104498, 2025. 1, 2
2025
-
[39]
The signwriting alphabet.Read and Write any Sign Language in the World
Valerie Sutton. The signwriting alphabet.Read and Write any Sign Language in the World. ISWA Manual, 2010. 1
2010
-
[40]
Fingerspelling within sign language transla- tion, 2024
Garrett Tanzer. Fingerspelling within sign language transla- tion, 2024. 5, 6, 7
2024
-
[41]
FLEURS-ASL: Including American Sign Language in massively multilingual multitask evaluation
Garrett Tanzer. FLEURS-ASL: Including American Sign Language in massively multilingual multitask evaluation. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Proceed- ings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 6167–6191, ...
2025
-
[42]
Reconsidering sentence-level sign language translation, 2024
Garrett Tanzer, Maximus Shengelia, Ken Harrenstien, and David Uthus. Reconsidering sentence-level sign language translation, 2024. 6
2024
-
[43]
Youtube-SL-25: A large- scale, open-domain multilingual sign language parallel cor- pus
Garrett Tanzer and Biao Zhang. Youtube-SL-25: A large- scale, open-domain multilingual sign language parallel cor- pus. InThe Thirteenth International Conference on Learning Representations, 2025. 1, 2
2025
-
[44]
Ladner, and Danielle Bragg
Nina Tran, Richard E. Ladner, and Danielle Bragg. U.s. deaf community perspectives on automatic sign language transla- tion. InProceedings of the 25th International ACM SIGAC- CESS Conference on Computers and Accessibility, ASSETS ’23, New York, NY , USA, 2023. Association for Computing Machinery. 1
2023
-
[45]
Gallaudet University Press,
Clayton Valli and Ceil Lucas.Linguistics of American sign language: An introduction. Gallaudet University Press,
-
[46]
Gloss-free sign language recognition with question- answering
G ¨ul Varol, Ivan Laptev, Cordelia Schmid, and Andrew Zis- serman. Gloss-free sign language recognition with question- answering. InProceedings of the IEEE/CVF Winter Con- ference on Applications of Computer Vision (WACV), pages 30–39, 2021. 2
2021
-
[47]
SIGN2GPT: LEVERAGING LARGE LANGUAGE MOD- ELS FOR GLOSS-FREE SIGN LANGUAGE TRANSLA-
Ryan Wong, Necati Cihan Camgoz, and Richard Bowden. SIGN2GPT: LEVERAGING LARGE LANGUAGE MOD- ELS FOR GLOSS-FREE SIGN LANGUAGE TRANSLA-
-
[48]
ASL STEM Wiki: Dataset and benchmark for inter- preting STEM articles
Kayo Yin, Chinmay Singh, Fyodor O Minakov, Vanessa Mi- lan, Hal Daum´e Iii, Cyril Zhang, Alex Xijie Lu, and Danielle Bragg. ASL STEM Wiki: Dataset and benchmark for inter- preting STEM articles. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Con- ference on Empirical Methods in Natural Language Process- ing, pages 14...
2024
-
[49]
Towards ai-driven sign language generation with non- manual markers
Han Zhang, Rotem Shalev-Arkushin, Vasileios Baltatzis, Connor Gillis, Gierad Laput, Raja Kushalnagar, Lorna C Quandt, Leah Findlater, Abdelkareem Bedri, and Colin Lea. Towards ai-driven sign language generation with non- manual markers. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 1–26, 2025. 3
2025
-
[50]
SignCLIP: Contrastive language-image pre- training for zero-shot sign language recognition
Yutong Zheng, Yutong Zuo, Fangyun Wei, Wei-Shi Wang, and Xiao Wang. SignCLIP: Contrastive language-image pre- training for zero-shot sign language recognition. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision (ICCV), pages 16006–16016, 2023. 7
2023
-
[51]
Gloss-free sign language translation: Improving from visual- language pretraining
Benjia Zhou, Zhigang Chen, Albert Clap ´es, Jun Wan, Yanyan Liang, Sergio Escalera, Zhen Lei, and Du Zhang. Gloss-free sign language translation: Improving from visual- language pretraining. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 20871–20881, October 2023. 1, 2
2023
-
[52]
Improving sign language translation with monolingual data by sign back-translation
Hao Zhou, Wengang Zhou, Weizhen Qi, Junfu Pu, and Houqiang Li. Improving sign language translation with monolingual data by sign back-translation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1316–1325, 2021. 2
2021
-
[53]
CiCo: Visual-textual contrastive learn- ing for sign language recognition
Yutong Zuo, Fangyun Wei, Zeng-Fei Wang, Wei-Shi Wang, and Xiao Wang. CiCo: Visual-textual contrastive learn- ing for sign language recognition. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 15951–15962, 2023. 2 A. LLM Prompts In the paper we share results using three LLM prompts: (1) K-Shot English to ASL Gloss, (...
2023
-
[54]
NUMBERS: - Write numbers 1-9 as digits: 1, 2, 3, etc. - Numbers 10+ use conceptual signing: ”100”→”1 HUNDRED”, ”25”→”2 5” or ”TWENTY-FIVE” - Years: Use full digits ”1998” or conceptual ”NINETEEN NINETY-EIGHT” - Ages: ”AGE” + number - Time: Use appropriate time markers (MORNING, AFTERNOON, etc.)
1998
-
[55]
Don’t use ”FS-” or have dashes between letters
GRAMMAR MARKERS: - Use hyphens for compound signs: SELF-CONTROL - Fingerspelling: JOHN for names not having signs. Don’t use ”FS-” or have dashes between letters. - Use classifiers when appropriate (e.g., CL:1(POINT) or CL:4(list)) - Prefer classifiers instead of index notation - Use a special character instead of text (e.g., use ”+” instead of ”PLUS”)
-
[56]
- Sometimes follow ASL word order (typically Time-Subject-Object-Verb)
ASL STRUCTURE: - Every sentence you generate should consider using a different grammatical structure. - Sometimes follow ASL word order (typically Time-Subject-Object-Verb)
-
[57]
‘json ”1
COMMON CONVENTIONS: - Past tense: FINISH or time markers, not English -ed - Questions: Use question markers and facial expressions - Negation: Use NOT before the sign EXAMPLE: English: ”I am happy” Output: “‘json ”1”: ”I AM HAPPY”, ”2”: ”CL:1(point) AM HAPPY”, ”3”: I VERY HAPPY”, ”4”: ”ME AM HAPPY”, ”5”: ”I SO HAPPY”, ”6”: ”I REALLY HAPPY”, ”7”: ”I AM GLA...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.