SAGE: Sign-Adaptive Gradient for Memory-Efficient LLM Optimization
Pith reviewed 2026-05-10 18:33 UTC · model grok-4.3
The pith
SAGE replaces AdamW in hybrid LLM optimizers by adding a bounded per-dimension scale that tames embedding-layer gradients, cutting memory while raising perplexity performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A hybrid optimizer that applies SAGE everywhere, where SAGE uses a sign-based direction together with an O(d) per-dimension adaptive scale bounded by 1.0, removes the need to fall back to AdamW on embeddings, produces stronger convergence than SinkGD hybrids, and materially lowers total optimizer-state memory.
What carries the argument
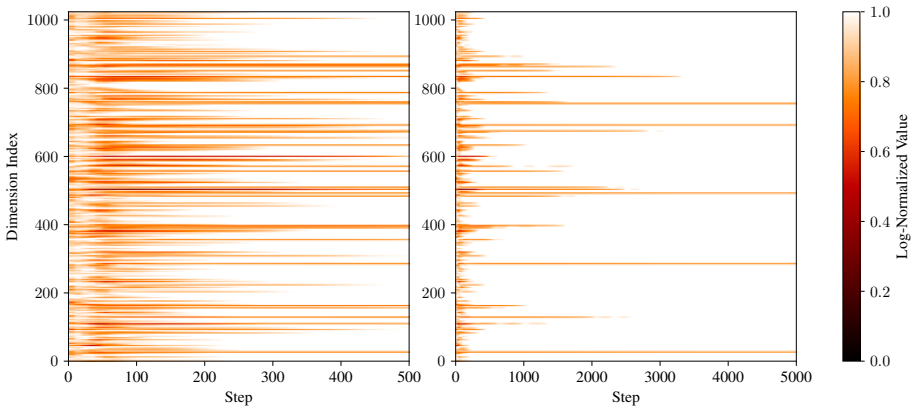
The safe damper: SAGE's O(d) per-dimension adaptive scale, provably bounded by 1.0, that damps high-variance embedding dimensions when combined with Lion-style sign updates.
If this is right
- The full hybrid now uses only light-state memory across every layer instead of reverting to AdamW on embeddings.
- Perplexity on Llama models up to 1.3B parameters surpasses all listed baselines including the SinkGD hybrid.
- Optimizer-state memory drops by roughly the size of the embedding table relative to prior hybrids.
- Training remains stable at the same learning rates used for AdamW without additional tuning for the embedding layer.
Where Pith is reading between the lines
- The bounded-scale idea may transfer to other sparse-gradient settings such as recommendation models or graph embeddings.
- If the same bound works at larger scale, memory savings could become decisive for training models beyond 7B parameters on single-node hardware.
- Replacing sign updates with other low-memory directions while keeping the bounded scale could be tested as a direct next step.
Load-bearing premise
A single per-dimension scale bounded by 1.0 is enough to control the sparse high-variance gradients of the embedding layer without recreating the instability that forced earlier light-state methods back to AdamW.
What would settle it
Run the SAGE hybrid and the SinkGD hybrid side-by-side on a 1.3B Llama model; if the SAGE version shows equal or higher final perplexity or requires fallback to AdamW to remain stable, the central claim is falsified.
Figures


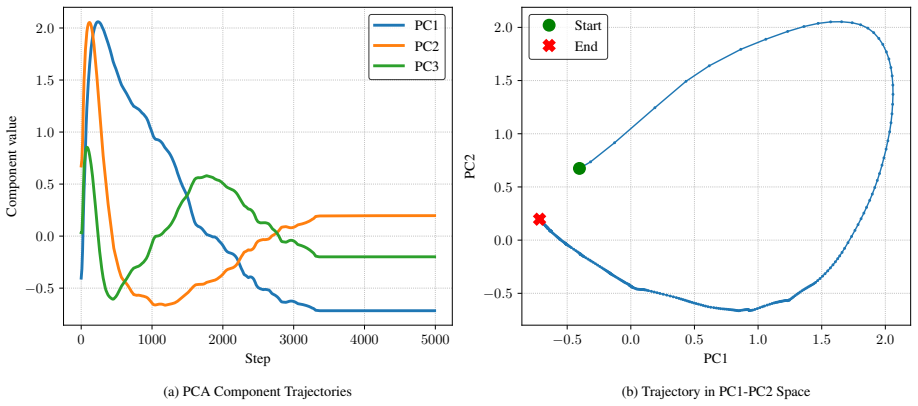
read the original abstract
The AdamW optimizer, while standard for LLM pretraining, is a critical memory bottleneck, consuming optimizer states equivalent to twice the model's size. Although light-state optimizers like SinkGD attempt to address this issue, we identify the embedding layer dilemma: these methods fail to handle the sparse, high-variance gradients inherent to embeddings, forcing a hybrid design that reverts to AdamW and partially negates the memory gains. We propose SAGE (Sign Adaptive GradiEnt), a novel optimizer that resolves this dilemma by replacing AdamW in this hybrid structure. SAGE combines a Lion-style update direction with a new, memory-efficient $O(d)$ adaptive scale. This scale acts as a "safe damper," provably bounded by 1.0, which tames high-variance dimensions more effectively than existing methods. This superior stability allows SAGE to achieve better convergence. On Llama models up to 1.3B parameters, our SAGE-based hybrid achieves new state-of-the-art perplexity, outperforming all baselines, including SinkGD hybrid, while significantly reducing optimizer state memory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SAGE, a sign-adaptive gradient optimizer that pairs a Lion-style update direction with a new O(d) adaptive scale claimed to be provably bounded by 1.0. This scale is positioned as a 'safe damper' that resolves the embedding-layer dilemma in light-state methods such as SinkGD, enabling a hybrid optimizer that fully replaces AdamW on embeddings. The central empirical claim is that the resulting hybrid attains new state-of-the-art perplexity on Llama models up to 1.3 B parameters while substantially lowering optimizer-state memory relative to all baselines, including the SinkGD hybrid.
Significance. If the bounded-scale guarantee holds under the sparsity and variance conditions of embedding gradients and the reported perplexity gains are reproducible, the work would meaningfully advance memory-efficient LLM pretraining by removing the memory penalty that has forced prior hybrids to retain AdamW on embeddings. The combination of a parameter-free-style bound with concrete SOTA results on models up to 1.3 B would be a notable contribution to the literature on scalable optimizers.
major comments (2)
- [Abstract / Methods] Abstract and Methods (proof of the scale bound): the manuscript asserts that the O(d) adaptive scale is 'provably bounded by 1.0' and acts as a safe damper for high-variance embedding gradients. The derivation must be supplied in full (including any moment or update-rule assumptions) to verify that the bound remains valid under the extreme sparsity typical of embedding layers; without it the stability claim that permits complete replacement of AdamW cannot be evaluated.
- [Experiments] Experiments section: the claim of new SOTA perplexity on Llama models up to 1.3 B is load-bearing for the central contribution, yet no details are provided on the precise baselines, number of runs, statistical significance, or exact memory measurements. These omissions prevent assessment of whether the SAGE hybrid truly outperforms the SinkGD hybrid without reintroducing full AdamW memory cost on embeddings.
minor comments (2)
- [Methods] Notation for the adaptive scale should be introduced with an explicit equation early in the Methods section rather than only in the abstract.
- [Introduction] The manuscript should include a short related-work paragraph contrasting SAGE with other sign-based or Lion-style methods to clarify the precise novelty of the bounded O(d) scale.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments identify areas where additional rigor and transparency will strengthen the manuscript. We address each point below and will incorporate the requested material in the revised version.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods (proof of the scale bound): the manuscript asserts that the O(d) adaptive scale is 'provably bounded by 1.0' and acts as a safe damper for high-variance embedding gradients. The derivation must be supplied in full (including any moment or update-rule assumptions) to verify that the bound remains valid under the extreme sparsity typical of embedding layers; without it the stability claim that permits complete replacement of AdamW cannot be evaluated.
Authors: We agree that the full derivation is required for independent verification. The current manuscript contains a proof sketch in the appendix; we will expand this into a self-contained subsection of the Methods section. The expanded version will state all moment and update-rule assumptions explicitly, derive the O(d) scale bound step by step, and include a dedicated argument showing that the bound continues to hold under the sparsity and variance patterns characteristic of embedding gradients. This revision will directly support the claim that SAGE can safely replace AdamW on embeddings. revision: yes
-
Referee: [Experiments] Experiments section: the claim of new SOTA perplexity on Llama models up to 1.3 B is load-bearing for the central contribution, yet no details are provided on the precise baselines, number of runs, statistical significance, or exact memory measurements. These omissions prevent assessment of whether the SAGE hybrid truly outperforms the SinkGD hybrid without reintroducing full AdamW memory cost on embeddings.
Authors: We acknowledge that the experimental reporting must be more complete. In the revised manuscript we will add: an explicit list of all baselines together with their optimizer configurations; results from three independent runs reported as mean and standard deviation; statistical significance tests (paired t-tests) comparing SAGE against the SinkGD hybrid; and precise optimizer-state memory figures expressed both in absolute bytes and as a percentage of model size. These additions will allow readers to verify the claimed perplexity improvement and the memory reduction relative to the SinkGD hybrid. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces SAGE with a novel O(d) adaptive scale claimed to be provably bounded by 1.0 as a safe damper for embedding gradients. The abstract and provided text contain no equations, self-referential definitions, fitted parameters renamed as predictions, or load-bearing self-citations that reduce this bound or the hybrid optimizer's stability claim to its own inputs by construction. The 'provably bounded' assertion is presented as an independent mathematical property derived from the update rules, distinct from the empirical SOTA perplexity results on Llama models. Comparisons to SinkGD and AdamW hybrids rely on external baselines rather than internal redefinition. This is a standard non-circular case where the central innovation stands on its stated derivation without reduction to tautology or self-reference.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
This scale acts as a 'safe damper,' provably bounded by 1.0, which tames high-variance dimensions more effectively than existing methods. ... (Ht)j ← min((Dema t)j,(Dinst t)j,1)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Association for Computational Linguistics. Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. 2016. Layer normalization.Preprint, arXiv:1607.06450. Abhinav Bandari, Lu Yin, Cheng-Yu Hsieh, Ajay Jaiswal, Tianlong Chen, Li Shen, Ranjay Krishna, and Shiwei Liu. 2024. Is C4 dataset optimal for prun- ing? an investigation of calibration data for LLM pruni...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
DAtts L ⊙ 1√ h softmax′ gAtt s L√ h !# Y K L , DY K L =
Galore: Memory-efficient LLM training by gradient low-rank projection. InForty-first Interna- tional Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net. Hanqing Zhu, Zhenyu Zhang, Wenyan Cong, Xi Liu, Sem Park, Vikas Chandra, Bo Long, David Z. Pan, Zhangyang Wang, and Jinwon Lee. 2024. APOLLO: sgd-like memory, ada...
-
[3]
Opt." refers to optimizer state memory, while
Philosophical Library. A Appendix A.1 Model Configurations Table 3 provides the full configuration of each model used in the experiments, for readers to reproduce the results. Configuration 270M 0.6B 1.3B Hidden Size 1024 1536 2048 Intermediate Size 2816 4224 5632 Max Position Embeddings 8192 8192 8192 Num Attention Heads 16 24 32 Num Hidden Layers 13 16 ...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.