Recognition: unknown
Weight Group-wise Post-Training Quantization for Medical Foundation Model
Pith reviewed 2026-05-10 17:12 UTC · model grok-4.3
The pith
A post-training method called Permutation-COMQ quantizes medical foundation models to 2, 4, or 8 bits using only dot products, rounding, and weight reordering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
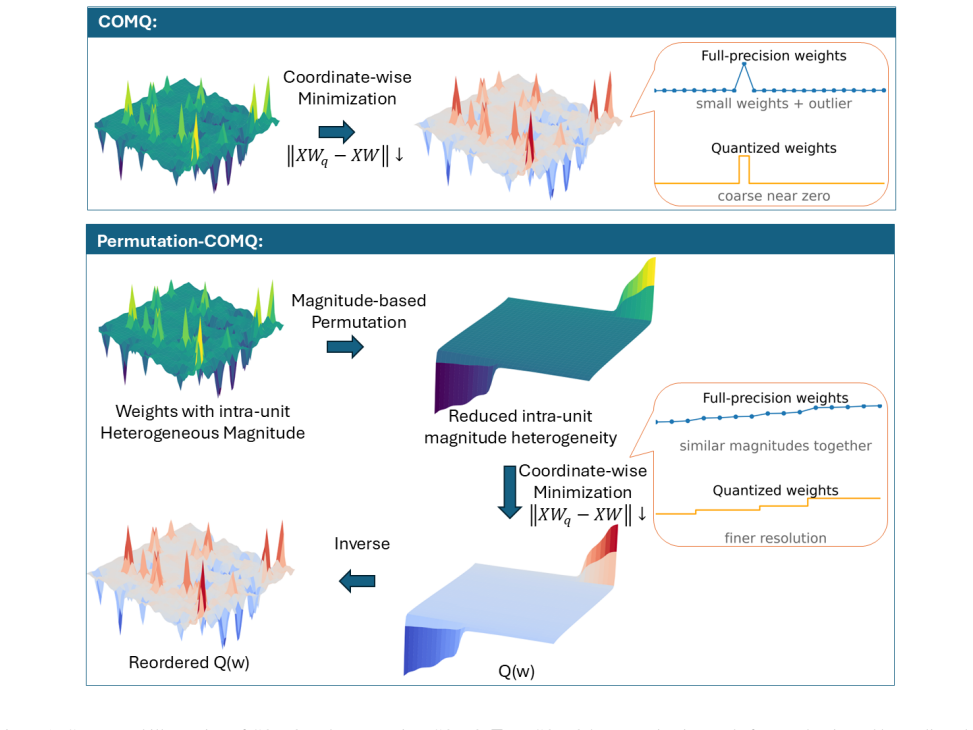
The central claim is that reordering weights group-wise inside each layer compensates for the accuracy degradation caused by channel-wise scaling, while the rest of the quantization reduces to simple dot-product calculations and rounding; when tested on medical foundation models this procedure produces the highest accuracy among compared methods at 2-bit, 4-bit, and 8-bit widths.
What carries the argument
The Permutation-COMQ procedure, which first permutes weights within layers to mitigate channel-wise scaling loss and then applies dot-product-based rounding to obtain the low-bit representation without backpropagation.
If this is right
- Medical foundation models become deployable on terminal hardware with only minor accuracy loss.
- Deployment no longer requires gradient-based fine-tuning or hyperparameter sweeps.
- Channel structure remains intact after quantization, preserving the original model architecture.
- The same simple dot-product steps can be applied uniformly across 2-bit, 4-bit, and 8-bit targets.
Where Pith is reading between the lines
- The same reordering idea could be tested on non-medical vision transformers to check whether the accuracy recovery is domain-specific.
- If the method generalizes, it would lower the compute cost of running diagnostic AI in low-resource clinics.
- One could measure actual inference latency and memory footprint on representative mobile GPUs to quantify the practical gain beyond accuracy numbers.
Load-bearing premise
Reordering the weights inside each layer fully restores the accuracy lost by independent channel scaling and that this fix works for medical foundation models without any further tuning.
What would settle it
Running the method on a previously unseen medical foundation model and finding that its 2-bit accuracy falls below at least one existing post-training quantizer that does not use reordering.
Figures



read the original abstract
Foundation models have achieved remarkable results in medical image analysis. However, its large network architecture and high computational complexity significantly impact inference speed, limiting its application on terminal medical devices. Quantization, a technique that compresses models into low-bit versions, is a solution to this challenge. In this paper, we propose a post-training quantization algorithm, Permutation-COMQ. It eliminates the need for backpropagation by using simple dot products and rounding operations, thereby removing hyperparameter tuning and simplifying the process. Additionally, we introduce a weight-aware strategy that reorders the weight within each layer to address the accuracy degradation induced by channel-wise scaling during quantization, while preserving channel structure. Experiments demonstrate that our method achieves the best results in 2-bit, 4-bit, and 8-bit quantization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Permutation-COMQ, a post-training quantization algorithm for medical foundation models. It relies on dot products and rounding to avoid backpropagation and hyperparameter tuning. A weight-aware reordering strategy is added to counteract accuracy loss from channel-wise scaling while preserving channel structure. The central claim is that experiments show the method achieves the best results for 2-bit, 4-bit, and 8-bit quantization.
Significance. If the experimental results can be substantiated, the work offers a simple, tuning-free quantization procedure that could aid deployment of large medical foundation models on edge devices. The reordering approach targets a specific quantization artifact in a domain where weight statistics may differ from natural-image models.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: The headline claim that Permutation-COMQ achieves the best results in 2/4/8-bit settings is presented without any quantitative tables, baseline comparisons, dataset specifications, or error bars. This leaves the central empirical assertion unverified and load-bearing for the paper's contribution.
- [Method] Method section on weight-aware reordering: The assertion that reordering fully compensates for accuracy degradation induced by channel-wise scaling while preserving channel structure is not supported by an ablation that isolates the reordering step on the actual weight tensors of the target medical foundation model. Without this, the generalization claim rests on an untested assumption.
minor comments (2)
- [Abstract] The abstract uses 'its large network architecture' where 'the model's' or 'their' would be clearer.
- [Method] Notation for the dot-product and rounding procedure should be formalized with equations to allow reproducibility.
Simulated Author's Rebuttal
We are grateful to the referee for the constructive comments on our manuscript. These observations help strengthen the empirical support and methodological clarity of Permutation-COMQ. We address each major comment below and will incorporate revisions to the manuscript as indicated.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: The headline claim that Permutation-COMQ achieves the best results in 2/4/8-bit settings is presented without any quantitative tables, baseline comparisons, dataset specifications, or error bars. This leaves the central empirical assertion unverified and load-bearing for the paper's contribution.
Authors: We agree that the abstract would be strengthened by including specific quantitative results. The Experiments section reports comparative performance on medical imaging tasks, but we acknowledge the need for greater explicitness. We will revise the abstract to incorporate key metrics (e.g., accuracy or Dice scores) for the 2-bit, 4-bit, and 8-bit cases. In the Experiments section, we will expand the tables to explicitly list all baseline methods, dataset details (including the medical foundation model datasets used), and error bars computed over multiple runs to fully substantiate the central claim. revision: yes
-
Referee: [Method] Method section on weight-aware reordering: The assertion that reordering fully compensates for accuracy degradation induced by channel-wise scaling while preserving channel structure is not supported by an ablation that isolates the reordering step on the actual weight tensors of the target medical foundation model. Without this, the generalization claim rests on an untested assumption.
Authors: We appreciate this point. The weight-aware reordering is designed to mitigate accuracy loss from channel-wise scaling by reordering weights within layers according to their magnitude statistics while keeping the original channel ordering intact for architectural compatibility. To directly support this, we will add a dedicated ablation study to the revised manuscript. The ablation will isolate the reordering step by comparing quantization outcomes (with and without reordering) applied to the actual weight tensors extracted from layers of the target medical foundation model, reporting the resulting accuracy differences to demonstrate the compensation effect. revision: yes
Circularity Check
Permutation-COMQ presented as direct algorithmic construction using dot products and rounding; no equations reduce accuracy claims to self-fitted parameters
full rationale
The paper describes Permutation-COMQ as a post-training quantization method relying on simple dot products, rounding operations, and a weight-aware reordering strategy to address channel-wise scaling degradation while preserving channel structure. No derivation equations, predictions, or first-principles results are shown that reduce the claimed best results in 2/4/8-bit quantization to inputs by construction (e.g., fitting a parameter on the same data and renaming it a prediction). The accuracy claims rest on experimental validation rather than any self-definitional or fitted-input reduction. This is a standard algorithmic proposal with empirical results and no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep se- mantic segmentation of natural and medical images: a re- view.Artificial intelligence review, 54(1):137–178, 2021
Saeid Asgari Taghanaki, Kumar Abhishek, Joseph Paul Co- hen, Julien Cohen-Adad, and Ghassan Hamarneh. Deep se- mantic segmentation of natural and medical images: a re- view.Artificial intelligence review, 54(1):137–178, 2021. 1
2021
-
[2]
Tianrun Chen, Ankang Lu, Lanyun Zhu, Chaotao Ding, Chu- nan Yu, Deyi Ji, Zejian Li, Lingyun Sun, Papa Mao, and Ying Zang. Sam2-adapter: Evaluating & adapting seg- ment anything 2 in downstream tasks: Camouflage, shadow, medical image segmentation, and more.arXiv preprint arXiv:2408.04579, 2024. 2
-
[3]
Junlong Cheng, Jin Ye, Zhongying Deng, Jianpin Chen, Tianbin Li, Haoyu Wang, Yanzhou Su, Ziyan Huang, Ji- long Chen, Lei Jiang, et al. Sam-med2d.arXiv preprint arXiv:2308.16184, 2023. 2
-
[4]
Medical image anal- ysis: Progress over two decades and the challenges ahead
James S Duncan and Nicholas Ayache. Medical image anal- ysis: Progress over two decades and the challenges ahead. IEEE transactions on pattern analysis and machine intelli- gence, 22(1):85–106, 2002. 1
2002
-
[5]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers.arXiv preprint arXiv:2210.17323, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Model compression in practice: Lessons learned from practitioners creating on-device machine learning ex- periences
Fred Hohman, Mary Beth Kery, Donghao Ren, and Dominik Moritz. Model compression in practice: Lessons learned from practitioners creating on-device machine learning ex- periences. InProceedings of the 2024 CHI conference on human factors in computing systems, pages 1–18, 2024. 2
2024
-
[7]
Umednerf: Uncertainty-aware single view vol- umetric rendering for medical neural radiance fields
Jing Hu, Qinrui Fan, Shu Hu, Siwei Lyu, Xi Wu, and Xin Wang. Umednerf: Uncertainty-aware single view vol- umetric rendering for medical neural radiance fields. In 2024 IEEE International Symposium on Biomedical Imag- ing (ISBI), pages 1–4. IEEE, 2024. 2
2024
-
[8]
Improving generalization of medical image registra- tion foundation model
Jing Hu, Kaiwei Yu, Hongjiang Xian, Shu Hu, and Xin Wang. Improving generalization of medical image registra- tion foundation model. In2025 International Joint Confer- ence on Neural Networks (IJCNN), pages 1–8. IEEE, 2025
2025
-
[9]
Robustly optimized deep feature decoupling network for fatty liver diseases detection
Peng Huang, Shu Hu, Bo Peng, Jiashu Zhang, Xi Wu, and Xin Wang. Robustly optimized deep feature decoupling network for fatty liver diseases detection. InInternational Conference on Medical Image Computing and Computer- Assisted Intervention, pages 68–78. Springer, 2024. 2
2024
-
[10]
Diffusion-empowered autoprompt medsam,
Peng Huang, Shu Hu, Bo Peng, Jiashu Zhang, Hongtu Zhu, Xi Wu, and Xin Wang. Diffusion-empowered autoprompt medsam.arXiv preprint arXiv:2502.06817, 2025. 1, 2
-
[11]
Segment any- thing
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProc. IEEE Int. Conf. Comput. Vis. (ICCV), pages 4015–4026, 2023. 1
2023
-
[12]
Is (selective) round-to-nearest quantization all you need?arXiv preprint arXiv:2505.15909, 2025
Alex Kogan. Is (selective) round-to-nearest quantization all you need?arXiv preprint arXiv:2505.15909, 2025. 3, 6
-
[13]
Quantizing deep convolutional networks for efficient inference: A whitepaper
Raghuraman Krishnamoorthi. Quantizing deep convolu- tional networks for efficient inference: A whitepaper.arXiv preprint arXiv:1806.08342, 2018. 3
work page Pith review arXiv 2018
-
[14]
A compre- hensive study on quantization techniques for large language models
Jiedong Lang, Zhehao Guo, and Shuyu Huang. A compre- hensive study on quantization techniques for large language models. In2024 4th International Conference on Artificial Intelligence, Robotics, and Communication (ICAIRC), pages 224–231. IEEE, 2024. 2
2024
-
[15]
Awq: Activation-aware weight quantization for on-device llm compression and accelera- tion.Proceedings of machine learning and systems, 6:87– 100, 2024
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for on-device llm compression and accelera- tion.Proceedings of machine learning and systems, 6:87– 100, 2024. 3
2024
-
[16]
Robust covid-19 detection in ct images with clip
Li Lin, Yamini Sri Krubha, Zhenhuan Yang, Cheng Ren, Thuc Duy Le, Irene Amerini, Xin Wang, and Shu Hu. Robust covid-19 detection in ct images with clip. In2024 IEEE 7th International Conference on Multimedia Information Pro- cessing and Retrieval (MIPR), pages 586–592. IEEE, 2024. 2
2024
-
[17]
Abdomenct-1k: Is abdominal organ segmentation a solved problem?IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(10):6695–6714, 2021
Jun Ma, Yao Zhang, Song Gu, Cheng Zhu, Cheng Ge, Yichi Zhang, Xingle An, Congcong Wang, Qiyuan Wang, Xin Liu, et al. Abdomenct-1k: Is abdominal organ segmentation a solved problem?IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(10):6695–6714, 2021. 6
2021
-
[18]
Segment anything in medical images.Nat
Jun Ma, Yuting He, Feifei Li, Lin Han, Chenyu You, and Bo Wang. Segment anything in medical images.Nat. Commun., 15(1):654, 2024. 1, 2
2024
-
[19]
Efficient deep learning: A survey on making deep learning models smaller, faster, and better
Gaurav Menghani. Efficient deep learning: A survey on making deep learning models smaller, faster, and better. ACM Computing Surveys, 55(12):1–37, 2023. 2
2023
-
[20]
A white paper on neural network quantization
Markus Nagel, Marios Fournarakis, Rana Ali Amjad, Yely- sei Bondarenko, Mart Van Baalen, and Tijmen Blankevoort. A white paper on neural network quantization.arXiv preprint arXiv:2106.08295, 2021. 2, 3
-
[21]
Easyquant: An efficient data-free quan- tization algorithm for llms
Hanlin Tang, Yifu Sun, Decheng Wu, Kai Liu, Jianchen Zhu, and Zhanhui Kang. Easyquant: An efficient data-free quan- tization algorithm for llms. InProceedings of the 2023 Con- ference on Empirical Methods in Natural Language Process- ing, pages 9119–9128, 2023. 3
2023
-
[22]
Uu-mamba: uncertainty-aware u- mamba for cardiac image segmentation
Ting Yu Tsai, Li Lin, Shu Hu, Ming-Ching Chang, Hongtu Zhu, and Xin Wang. Uu-mamba: uncertainty-aware u- mamba for cardiac image segmentation. In2024 IEEE 7th International Conference on Multimedia Information Pro- cessing and Retrieval (MIPR), pages 267–273. IEEE, 2024. 2
2024
-
[23]
Uu-mamba: Uncertainty-aware u-mamba for cardiovascular segmentation,
Ting Yu Tsai, Li Lin, Shu Hu, Connie W Tsao, Xin Li, Ming- Ching Chang, Hongtu Zhu, and Xin Wang. Uu-mamba: Uncertainty-aware u-mamba for cardiovascular segmenta- tion.arXiv preprint arXiv:2409.14305, 2024
-
[24]
Neural radiance fields in medical imaging: A survey,
Xin Wang, Yineng Chen, Shu Hu, Heng Fan, Hongtu Zhu, and Xin Li. Neural radiance fields in medical imaging: A survey.arXiv preprint arXiv:2402.17797, 2024. 2
-
[25]
U-medsam: Uncertainty-aware medsam 8 for medical image segmentation
Xin Wang, Xiaoyu Liu, Peng Huang, Pu Huang, Shu Hu, and Hongtu Zhu. U-medsam: Uncertainty-aware medsam 8 for medical image segmentation. InMedical Image Segmen- tation Challenge, pages 206–217. Springer, 2024. 2
2024
-
[26]
Aozhong Zhang, Naigang Wang, Yanxia Deng, Xin Li, Zi Yang, and Penghang Yin. Magr: Weight magnitude reduc- tion for enhancing post-training quantization.arXiv preprint arXiv:2406.00800, 2024. 2
-
[27]
Aozhong Zhang, Zi Yang, Naigang Wang, Yingyong Qi, Jack Xin, Xin Li, and Penghang Yin. Comq: A backpropagation-free algorithm for post-training quantiza- tion.arXiv preprint arXiv:2403.07134, 2024. 2, 3, 4, 6
-
[28]
Mobilesamv2: Faster segment anything to everything.arXiv preprint arXiv:2312.09579, 2023
Chaoning Zhang, Dongshen Han, Sheng Zheng, Jinwoo Choi, Tae-Ho Kim, and Choong Seon Hong. Mobilesamv2: Faster segment anything to everything.arXiv preprint arXiv:2312.09579, 2023. 2
-
[29]
Xu Zhao, Wenchao Ding, Yongqi An, Yinglong Du, Tao Yu, Min Li, Ming Tang, and Jinqiao Wang. Fast segment any- thing.arXiv preprint arXiv:2306.12156, 2023. 2
-
[30]
Contextual reinforcement learning for unsupervised deformable multimodal medical images regis- tration
Yang Zheng, Hongjiang Xian, Zhikun Shuai, Jing Hu, Xin Wang, and Shu Hu. Contextual reinforcement learning for unsupervised deformable multimodal medical images regis- tration. In2024 IEEE International Joint Conference on Bio- metrics (IJCB), pages 1–9. IEEE, 2024. 2
2024
-
[31]
Cgd-net: A hybrid end-to- end network with gating decoding for liver tumor segmenta- tion from ct images
Xiaogang Zhu, Tao Liu, Ziqiu Liu, Ouyang Shaobo, Xin Wang, Shu Hu, and Feng Ding. Cgd-net: A hybrid end-to- end network with gating decoding for liver tumor segmenta- tion from ct images. In2024 IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), pages 1–7. IEEE, 2024. 2 9
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.