Recognition: unknown
Direct Segmentation without Logits Optimization for Training-Free Open-Vocabulary Semantic Segmentation
Pith reviewed 2026-05-10 16:54 UTC · model grok-4.3
The pith
Open-vocabulary semantic segmentation can be achieved by directly using the analytic solution to the distribution discrepancy between visual and linguistic features as the segmentation map.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We posit that the distribution discrepancy between visual and linguistic features encodes semantic information, with consistency across patches of the same category and inconsistency across different categories. Therefore the analytic solution of this discrepancy can be used directly as the semantic segmentation map, reformulating the entire task as a closed-form derivation rather than an optimization problem.
What carries the argument
The analytic solution of the distribution discrepancy between visual and linguistic features, applied directly as the pixel-level semantic map.
If this is right
- No iterative training or gradient steps are required at inference time.
- Model-specific attention modulation becomes unnecessary.
- State-of-the-art results are obtained on eight standard open-vocabulary segmentation benchmarks.
- Pixel-level vision-language alignment occurs in a single forward pass.
Where Pith is reading between the lines
- Real-time systems could adopt this approach where optimization loops are too slow.
- The same discrepancy solution might be tested on video sequences to enforce temporal consistency without additional training.
- Any pre-trained vision-language backbone could be plugged in without architectural changes.
Load-bearing premise
The distribution discrepancy between visual and linguistic features must be consistent for patches of the same category and inconsistent for patches of different categories.
What would settle it
On a benchmark where intra-category visual patches produce highly varying distribution discrepancies, the direct analytic map would yield lower accuracy than methods that still optimize logits.
Figures











read the original abstract
Open-vocabulary semantic segmentation (OVSS) aims to segment arbitrary category regions in images using open-vocabulary prompts, necessitating that existing methods possess pixel-level vision-language alignment capability. Typically, this capability involves computing the cosine similarity, \ie, logits, between visual and linguistic features, and minimizing the distribution discrepancy between the logits and the ground truth (GT) to generate optimal logits that are subsequently used to construct segmentation maps, yet it depends on time-consuming iterative training or model-specific attention modulation. In this work, we propose a more direct approach that eschews the logits-optimization process by directly deriving an analytic solution for the segmentation map. We posit a key hypothesis: the distribution discrepancy encodes semantic information; specifically, this discrepancy exhibits consistency across patches belonging to the same category but inconsistency across different categories. Based on this hypothesis, we directly utilize the analytic solution of this distribution discrepancy as the semantic maps. In other words, we reformulate the optimization of the distribution discrepancy as deriving its analytic solution, thereby eliminating time-consuming iterative training, freeing us from model-specific attention modulation, and achieving state-of-the-art performance on eight benchmark datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a training-free method for open-vocabulary semantic segmentation that avoids logits optimization by directly deriving and using an analytic solution to the distribution discrepancy between visual and linguistic features as the semantic segmentation maps. It is based on the hypothesis that this discrepancy is consistent for patches of the same category and inconsistent across categories, leading to state-of-the-art performance on eight benchmark datasets.
Significance. If the central hypothesis holds and the analytic solution is correctly formulated to not require ground truth or iterative processes, this could represent a substantial advance in simplifying OVSS by eliminating training time and model-specific adjustments, potentially making such segmentation more accessible and efficient. The claim of SOTA results, if verified, would strengthen its impact.
major comments (2)
- Abstract: The distribution discrepancy is defined with respect to the ground truth (GT), but the approach is claimed to be training-free and applicable at inference time without GT. The manuscript must clarify how the discrepancy is computed or its analytic solution derived without GT, as this is load-bearing for the 'direct segmentation without logits optimization' claim.
- Abstract: The key hypothesis regarding the consistency of the distribution discrepancy across same-category patches is posited without any derivation, equations, or empirical support referenced. Since the entire method rests on using the analytic solution based on this property, a detailed mathematical justification is required to substantiate that the solution yields valid semantic maps.
minor comments (1)
- The abstract mentions 'eight benchmark datasets' but does not specify which ones; listing them would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help us improve the clarity of our presentation. We address each major comment below and will incorporate the requested clarifications in the revised manuscript.
read point-by-point responses
-
Referee: Abstract: The distribution discrepancy is defined with respect to the ground truth (GT), but the approach is claimed to be training-free and applicable at inference time without GT. The manuscript must clarify how the discrepancy is computed or its analytic solution derived without GT, as this is load-bearing for the 'direct segmentation without logits optimization' claim.
Authors: We agree the abstract phrasing is potentially ambiguous and will revise it. In the method, the distribution discrepancy is defined between the visual feature distribution of image patches and the corresponding linguistic feature distribution induced by the open-vocabulary prompts; it does not involve ground-truth labels. The analytic solution is obtained by directly solving the consistency equation implied by our hypothesis, which is a closed-form expression that operates solely on the extracted features at inference time. Ground truth appears only in the introductory motivation when contrasting against prior logit-optimization approaches. We will add an explicit sentence in the abstract and a short paragraph in Section 3 stating that no GT is required for the derivation or application of the solution. revision: yes
-
Referee: Abstract: The key hypothesis regarding the consistency of the distribution discrepancy across same-category patches is posited without any derivation, equations, or empirical support referenced. Since the entire method rests on using the analytic solution based on this property, a detailed mathematical justification is required to substantiate that the solution yields valid semantic maps.
Authors: The abstract states the hypothesis concisely for brevity, but the full manuscript contains the supporting derivation. We formalize the discrepancy as a quantity that is invariant within each semantic category and derive the segmentation map as the unique analytic solution to the resulting linear system; the derivation appears in Section 3 together with the closed-form expression. We will revise the abstract to include a brief pointer to this derivation and will ensure the equations are highlighted. If the referee considers additional empirical verification of the consistency property useful, we can add a short analysis or figure in the revision. revision: yes
Circularity Check
No significant circularity in the derivation chain.
full rationale
The paper posits a hypothesis that distribution discrepancy between logits and GT encodes semantic information via intra-category consistency, then claims to derive and directly apply its analytic solution as semantic maps without iterative optimization. No equations or steps in the provided text reduce the final segmentation output to the inputs by construction (e.g., no redefinition of the map as the discrepancy itself or fitted parameter renamed as prediction). The central claim rests on the posited hypothesis and benchmark validation rather than a self-citation chain or tautological reformulation, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- ad hoc to paper The distribution discrepancy between visual and linguistic features encodes semantic information, showing consistency across patches of the same category and inconsistency across different categories.
Reference graph
Works this paper leans on
-
[1]
Sule Bai, Yong Liu, Yifei Han, Haoji Zhang, and Yansong Tang. Self-calibrated clip for training-free open-vocabulary segmentation.arXiv preprint arXiv:2411.15869, 2024. 6
-
[2]
Training-free open- vocabulary segmentation with offline diffusion-augmented prototype generation
Luca Barsellotti, Roberto Amoroso, Marcella Cornia, Lorenzo Baraldi, and Rita Cucchiara. Training-free open- vocabulary segmentation with offline diffusion-augmented prototype generation. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 3689–3698, 2024. 6
2024
-
[3]
Grounding everything: Emerging localiza- tion properties in vision-language transformers
Walid Bousselham, Felix Petersen, Vittorio Ferrari, and Hilde Kuehne. Grounding everything: Emerging localiza- tion properties in vision-language transformers. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3828–3837, 2024. 6
2024
-
[4]
Zero-shot semantic segmentation.Advances in Neural Information Processing Systems, 32, 2019
Maxime Bucher, Tuan-Hung Vu, Matthieu Cord, and Patrick P´erez. Zero-shot semantic segmentation.Advances in Neural Information Processing Systems, 32, 2019. 2
2019
-
[5]
Coco- stuff: Thing and stuff classes in context
Holger Caesar, Jasper Uijlings, and Vittorio Ferrari. Coco- stuff: Thing and stuff classes in context. InComputer Vision and Pattern Recognition (CVPR), 2018 IEEE conference on. IEEE, 2018. 5
2018
-
[6]
Learn- ing to generate text-grounded mask for open-world semantic segmentation from only image-text pairs
Junbum Cha, Jonghwan Mun, and Byungseok Roh. Learn- ing to generate text-grounded mask for open-world semantic segmentation from only image-text pairs. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11165–11174, 2023. 6
2023
-
[7]
Sign: Spatial-information incorpo- rated generative network for generalized zero-shot seman- tic segmentation
Jiaxin Cheng, Soumyaroop Nandi, Prem Natarajan, and Wael Abd-Almageed. Sign: Spatial-information incorpo- rated generative network for generalized zero-shot seman- tic segmentation. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 9556–9566,
-
[8]
Seokju Cho, Heeseong Shin, Sunghwan Hong, Seungjun An, Seungjun Lee, Anurag Arnab, Paul Hongsuck Seo, and Seungryong Kim. Cat-seg: Cost aggregation for open-vocabulary semantic segmentation.arXiv preprint arXiv:2303.11797, 2023. 2
-
[9]
Cat- seg: Cost aggregation for open-vocabulary semantic seg- mentation
Seokju Cho, Heeseong Shin, Sunghwan Hong, Anurag Arnab, Paul Hongsuck Seo, and Seungryong Kim. Cat- seg: Cost aggregation for open-vocabulary semantic seg- mentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4113– 4123, 2024. 2
2024
-
[10]
The cityscapes dataset for semantic urban scene understanding
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 3213–3223, 2016. 5
2016
-
[11]
Sinkhorn distances: Lightspeed computation of optimal transport.Advances in Neural Information Pro- cessing Systems, 26, 2013
Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport.Advances in Neural Information Pro- cessing Systems, 26, 2013. 4
2013
-
[12]
De- coupling zero-shot semantic segmentation
Jian Ding, Nan Xue, Gui-Song Xia, and Dengxin Dai. De- coupling zero-shot semantic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11583–11592, 2022. 2
2022
-
[13]
Everingham, L
M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman. The PASCAL Visual Object Classes Chal- lenge 2012 (VOC2012) Results, 2012. 5
2012
-
[14]
Context-aware feature generation for zero- shot semantic segmentation
Zhangxuan Gu, Siyuan Zhou, Li Niu, Zihan Zhao, and Liqing Zhang. Context-aware feature generation for zero- shot semantic segmentation. InProceedings of the 28th ACM International Conference on Multimedia, pages 1921–1929,
1921
-
[15]
Pay attention to your neighbours: Training-free open-vocabulary semantic segmentation
Sina Hajimiri, Ismail Ben Ayed, and Jose Dolz. Pay attention to your neighbours: Training-free open-vocabulary semantic segmentation. In2025 IEEE/CVF Winter Conference on Ap- plications of Computer Vision (WACV), pages 5061–5071. IEEE, 2025. 1, 2, 6
2025
-
[16]
Primitive gener- ation and semantic-related alignment for universal zero-shot segmentation
Shuting He, Henghui Ding, and Wei Jiang. Primitive gener- ation and semantic-related alignment for universal zero-shot segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11238– 11247, 2023. 1
2023
-
[17]
Learning mask-aware clip representations for zero-shot segmentation.Advances in Neural Information Processing Systems, 36:35631–35653, 2023
Siyu Jiao, Yunchao Wei, Yaowei Wang, Yao Zhao, and Humphrey Shi. Learning mask-aware clip representations for zero-shot segmentation.Advances in Neural Information Processing Systems, 36:35631–35653, 2023. 2
2023
-
[18]
In defense of lazy visual grounding for open-vocabulary semantic segmentation
Dahyun Kang and Minsu Cho. In defense of lazy visual grounding for open-vocabulary semantic segmentation. In European Conference on Computer Vision, pages 143–164. Springer, 2024. 6
2024
-
[19]
Repurposing stable diffusion attention for training-free unsupervised interactive segmentation
Markus Karmann and Onay Urfalioglu. Repurposing stable diffusion attention for training-free unsupervised interactive segmentation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24518–24528, 2025. 5
2025
-
[20]
Distilling spectral graph for object-context aware open-vocabulary semantic segmenta- tion
Chanyoung Kim, Dayun Ju, Woojung Han, Ming-Hsuan Yang, and Seong Jae Hwang. Distilling spectral graph for object-context aware open-vocabulary semantic segmenta- tion. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15033–15042, 2025. 2, 6
2025
-
[21]
Probabilistic prompt learning for dense prediction
Hyeongjun Kwon, Taeyong Song, Somi Jeong, Jin Kim, Jinhyun Jang, and Kwanghoon Sohn. Probabilistic prompt learning for dense prediction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6768–6777, 2023. 2
2023
-
[22]
Clearclip: Decom- posing clip representations for dense vision-language infer- ence
Mengcheng Lan, Chaofeng Chen, Yiping Ke, Xinjiang Wang, Litong Feng, and Wayne Zhang. Clearclip: Decom- posing clip representations for dense vision-language infer- ence. InEuropean Conference on Computer Vision, pages 143–160. Springer, 2024. 1, 2, 6
2024
-
[23]
Proxyclip: Proxy attention improves clip for open-vocabulary segmentation
Mengcheng Lan, Chaofeng Chen, Yiping Ke, Xinjiang Wang, Litong Feng, and Wayne Zhang. Proxyclip: Proxy attention improves clip for open-vocabulary segmentation. InEuropean Conference on Computer Vision, pages 70–88. Springer, 2024. 1, 2, 6
2024
-
[24]
Relation- ship prompt learning is enough for open-vocabulary seman- tic segmentation.Advances in Neural Information Process- ing Systems, 37:74298–74324, 2024
Jiahao Li, Yang Lu, Yuan Xie, and Yanyun Qu. Relation- ship prompt learning is enough for open-vocabulary seman- tic segmentation.Advances in Neural Information Process- ing Systems, 37:74298–74324, 2024. 2
2024
-
[25]
Novel category discovery with x-agent attention for open-vocabulary semantic segmentation
Jiahao Li, Yang Lu, Yachao Zhang, Fangyong Wang, Yuan Xie, and Yanyun Qu. Novel category discovery with x-agent attention for open-vocabulary semantic segmentation. In Proceedings of the 33rd ACM International Conference on Multimedia, pages 2929–2938, 2025. 1
2025
-
[26]
Consistent structural relation learning for zero-shot segmentation.Advances in Neural Information Processing Systems, 33:10317–10327,
Peike Li, Yunchao Wei, and Yi Yang. Consistent structural relation learning for zero-shot segmentation.Advances in Neural Information Processing Systems, 33:10317–10327,
-
[27]
Clip surgery for better explainability with enhancement in open- vocabulary tasks.arXiv e-prints, pages arXiv–2304, 2023
Yi Li, Hualiang Wang, Yiqun Duan, and Xiaomeng Li. Clip surgery for better explainability with enhancement in open- vocabulary tasks.arXiv e-prints, pages arXiv–2304, 2023. 6
2023
-
[28]
Open-vocabulary semantic segmentation with mask-adapted clip
Feng Liang, Bichen Wu, Xiaoliang Dai, Kunpeng Li, Yinan Zhao, Hang Zhang, Peizhao Zhang, Peter Vajda, and Diana Marculescu. Open-vocabulary semantic segmentation with mask-adapted clip. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 7061–7070, 2023. 2
2023
-
[29]
Delving into shape-aware zero-shot semantic segmentation
Xinyu Liu, Beiwen Tian, Zhen Wang, Rui Wang, Kehua Sheng, Bo Zhang, Hao Zhao, and Guyue Zhou. Delving into shape-aware zero-shot semantic segmentation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2999–3009, 2023. 1
2023
-
[30]
Emergent open-vocabulary semantic segmenta- tion from off-the-shelf vision-language models
Jiayun Luo, Siddhesh Khandelwal, Leonid Sigal, and Boyang Li. Emergent open-vocabulary semantic segmenta- tion from off-the-shelf vision-language models. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4029–4040, 2024. 6
2024
-
[31]
The role of context for object detection and semantic segmentation in the wild
Roozbeh Mottaghi, Xianjie Chen, Xiaobai Liu, Nam-Gyu Cho, Seong-Whan Lee, Sanja Fidler, Raquel Urtasun, and Alan Yuille. The role of context for object detection and semantic segmentation in the wild. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014. 5
2014
-
[32]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
A closer look at self-training for zero-label semantic segmentation
Giuseppe Pastore, Fabio Cermelli, Yongqin Xian, Massimil- iano Mancini, Zeynep Akata, and Barbara Caputo. A closer look at self-training for zero-label semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 2693–2702, 2021. 2
2021
-
[34]
Freeseg: Unified, universal and open-vocabulary image segmentation
Jie Qin, Jie Wu, Pengxiang Yan, Ming Li, Ren Yuxi, Xue- feng Xiao, Yitong Wang, Rui Wang, Shilei Wen, Xin Pan, et al. Freeseg: Unified, universal and open-vocabulary image segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19446– 19455, 2023. 1
2023
-
[35]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 6
2021
-
[36]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 5
2022
-
[37]
Ex- plore the potential of clip for training-free open vocabulary semantic segmentation
Tong Shao, Zhuotao Tian, Hang Zhao, and Jingyong Su. Ex- plore the potential of clip for training-free open vocabulary semantic segmentation. InEuropean Conference on Com- puter Vision, pages 139–156. Springer, 2024. 6
2024
-
[38]
Conterfactual gen- erative zero-shot semantic segmentation.arXiv preprint arXiv:2106.06360, 2021
Feihong Shen, Jun Liu, and Ping Hu. Conterfactual gen- erative zero-shot semantic segmentation.arXiv preprint arXiv:2106.06360, 2021. 1
-
[39]
Llmformer: Large language model for open-vocabulary semantic seg- mentation.International Journal of Computer Vision, 133 (2):742–759, 2025
Hengcan Shi, Son Duy Dao, and Jianfei Cai. Llmformer: Large language model for open-vocabulary semantic seg- mentation.International Journal of Computer Vision, 133 (2):742–759, 2025. 2
2025
-
[40]
Reco: Re- trieve and co-segment for zero-shot transfer.Advances in Neural Information Processing Systems, 35:33754–33767,
Gyungin Shin, Weidi Xie, and Samuel Albanie. Reco: Re- trieve and co-segment for zero-shot transfer.Advances in Neural Information Processing Systems, 35:33754–33767,
-
[41]
Lposs: Label propagation over patches and pixels for open-vocabulary semantic segmentation
Vladan Stojni ´c, Yannis Kalantidis, Ji ˇr´ı Matas, and Giorgos Tolias. Lposs: Label propagation over patches and pixels for open-vocabulary semantic segmentation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9794–9803, 2025. 2, 3
2025
-
[42]
Clip as rnn: Segment countless visual concepts without training endeavor
Shuyang Sun, Runjia Li, Philip Torr, Xiuye Gu, and Siyang Li. Clip as rnn: Segment countless visual concepts without training endeavor. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 13171–13182, 2024. 6
2024
-
[43]
Diffuse attend and segment: Un- supervised zero-shot segmentation using stable diffusion
Junjiao Tian, Lavisha Aggarwal, Andrea Colaco, Zsolt Kira, and Mar Gonzalez-Franco. Diffuse attend and segment: Un- supervised zero-shot segmentation using stable diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 3554–3563, 2024. 5
2024
-
[44]
Sclip: Rethink- ing self-attention for dense vision-language inference
Feng Wang, Jieru Mei, and Alan Yuille. Sclip: Rethink- ing self-attention for dense vision-language inference. In European Conference on Computer Vision, pages 315–332. Springer, 2024. 1, 2, 6
2024
-
[45]
Diffusion model is secretly a training-free open vocabulary semantic segmenter
Jinglong Wang, Xiawei Li, Jing Zhang, Qingyuan Xu, Qin Zhou, Qian Yu, Lu Sheng, and Dong Xu. Diffusion model is secretly a training-free open vocabulary semantic segmenter. IEEE Transactions on Image Processing, 2025. 2
2025
-
[46]
Clipself: Vision trans- former distills itself for open-vocabulary dense prediction
Size Wu, Wenwei Zhang, Lumin Xu, Sheng Jin, Xiangtai Li, Wentao Liu, and Chen Change Loy. Clipself: Vision trans- former distills itself for open-vocabulary dense prediction. arXiv preprint arXiv:2310.01403, 2023. 2
-
[47]
Clim: Contrastive language- image mosaic for region representation
Size Wu, Wenwei Zhang, Lumin Xu, Sheng Jin, Wentao Liu, and Chen Change Loy. Clim: Contrastive language- image mosaic for region representation. InProceedings of the AAAI Conference on Artificial Intelligence, pages 6117– 6125, 2024. 2
2024
-
[48]
Weijia Wu, Yuzhong Zhao, Mike Zheng Shou, Hong Zhou, and Chunhua Shen. Diffumask: Synthesizing images with pixel-level annotations for semantic segmentation using dif- fusion models.arXiv preprint arXiv:2303.11681, 2023. 2
-
[49]
Clip-dinoiser: Teaching clip a few dino tricks for open- vocabulary semantic segmentation
Monika Wysocza ´nska, Oriane Sim´eoni, Micha¨el Ramamon- jisoa, Andrei Bursuc, Tomasz Trzci ´nski, and Patrick P ´erez. Clip-dinoiser: Teaching clip a few dino tricks for open- vocabulary semantic segmentation. InEuropean Conference on Computer Vision, pages 320–337. Springer, 2024. 6
2024
-
[50]
Semantic projection network for zero-and few-label semantic segmentation
Yongqin Xian, Subhabrata Choudhury, Yang He, Bernt Schiele, and Zeynep Akata. Semantic projection network for zero-and few-label semantic segmentation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8256–8265, 2019. 2
2019
-
[51]
Groupvit: Semantic segmentation emerges from text supervision
Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, and Xiaolong Wang. Groupvit: Semantic segmentation emerges from text supervision. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 18134–18144, 2022. 2, 6
2022
-
[52]
A simple baseline for open- vocabulary semantic segmentation with pre-trained vision- language model
Mengde Xu, Zheng Zhang, Fangyun Wei, Yutong Lin, Yue Cao, Han Hu, and Xiang Bai. A simple baseline for open- vocabulary semantic segmentation with pre-trained vision- language model. InEuropean Conference on Computer Vi- sion, pages 736–753. Springer, 2022. 2
2022
-
[53]
Side adapter network for open-vocabulary semantic segmentation
Mengde Xu, Zheng Zhang, Fangyun Wei, Han Hu, and Xi- ang Bai. Side adapter network for open-vocabulary semantic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2945– 2954, 2023. 2
2023
-
[54]
Zero- shot referring image segmentation with global-local context features
Seonghoon Yu, Paul Hongsuck Seo, and Jeany Son. Zero- shot referring image segmentation with global-local context features. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19456– 19465, 2023. 2
2023
-
[55]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M Ni, and Heung-Yeung Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object detection.arXiv preprint arXiv:2203.03605, 2022. 2
work page internal anchor Pith review arXiv 2022
-
[56]
Open vocabulary scene parsing
Hang Zhao, Xavier Puig, Bolei Zhou, Sanja Fidler, and An- tonio Torralba. Open vocabulary scene parsing. InProceed- ings of the IEEE International Conference on Computer Vi- sion, pages 2002–2010, 2017. 1
2002
-
[57]
Semantic under- standing of scenes through the ade20k dataset.International Journal of Computer Vision, 127:302–321, 2019
Bolei Zhou, Hang Zhao, Xavier Puig, Tete Xiao, Sanja Fi- dler, Adela Barriuso, and Antonio Torralba. Semantic under- standing of scenes through the ade20k dataset.International Journal of Computer Vision, 127:302–321, 2019. 5
2019
-
[58]
Extract free dense labels from clip
Chong Zhou, Chen Change Loy, and Bo Dai. Extract free dense labels from clip. InEuropean Conference on Com- puter Vision, pages 696–712. Springer, 2022. 1, 2, 6
2022
-
[59]
Zegclip: Towards adapting clip for zero-shot se- mantic segmentation
Ziqin Zhou, Yinjie Lei, Bowen Zhang, Lingqiao Liu, and Yifan Liu. Zegclip: Towards adapting clip for zero-shot se- mantic segmentation. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 11175–11185, 2023. 2 Direct Segmentation without Logits Optimization for Training-Free Open-Vocabulary Semantic Segmentation Sup...
2023
-
[60]
Proof Given the cost matrixC∈R N×N and the regularization scalarϵ, the objective is to solve the following equation: π∗ = min π X i,j Ci,jπi,j −ϵ X i,j πi,j(lnπ i,j −1), (13) subject to marginal constraints: X j πi,j =f c i , X i πi,j =f t j ,∀i, j,π i,j ≥0, (14) whereP i f c i = 1,P j f t j = 1. By introducing Lagrange multipliersα∈R N andβ∈R N , the Lag...
-
[61]
More Details Non-maximum suppression.Given that existing visual language models are constrained by coarse-grained multi- modal training paradigms, the resulting logits often con- tain numerous misaligned patches, which serve as noise and interfere with downstream fine-grained tasks. In this work, this noise disrupts the distribution transmission pro- cess...
-
[62]
Logits” and “Attention
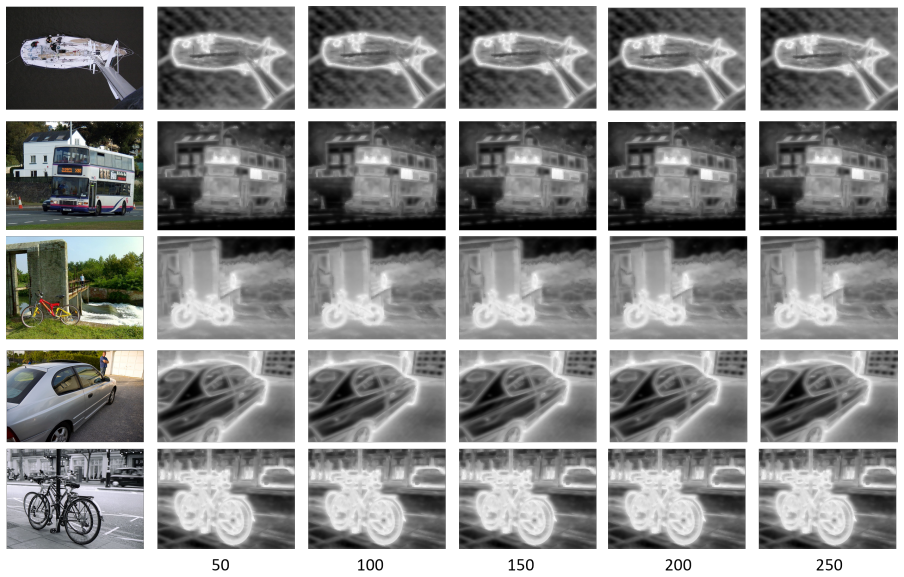
More results Ablation about optimal path.We conduct component ablation experiments under the optimal path mode. As il- lustrated in Figure 6, our analysis reveals that the effect of denoising step length confirms that single-step denois- ing generates deterministic self-attention tensors with opti- mal performance. Moreover, higher resolution of the atten...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.