The Impact of Dimensionality on the Stability of Node Embeddings
Pith reviewed 2026-05-10 17:53 UTC · model grok-4.3
The pith
Varying the dimensionality of node embeddings changes their stability in method-specific ways, and the dimension with highest stability does not always give the best downstream performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
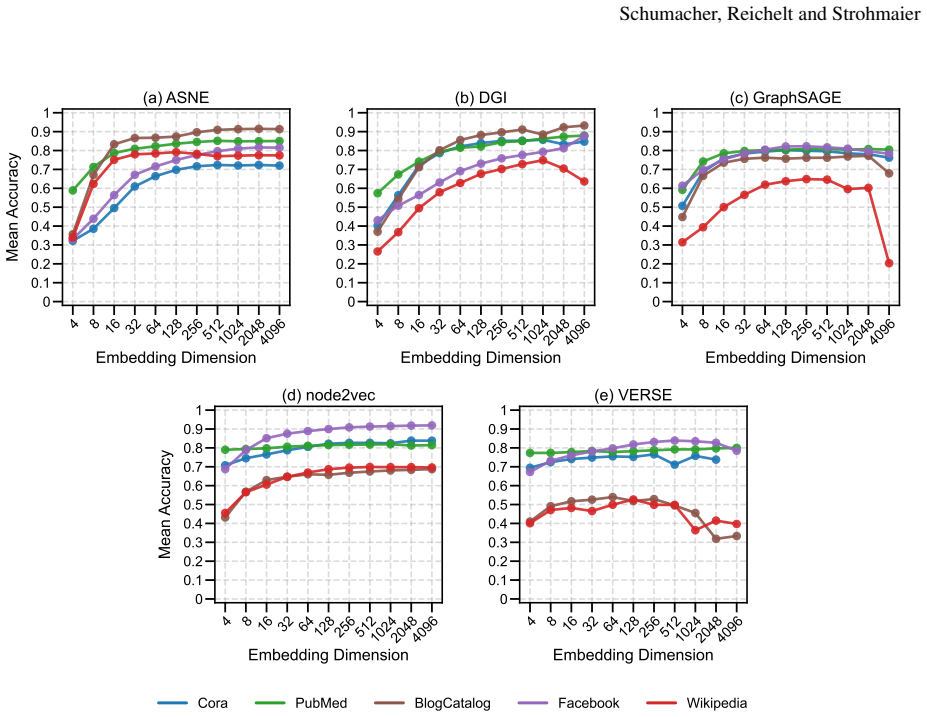
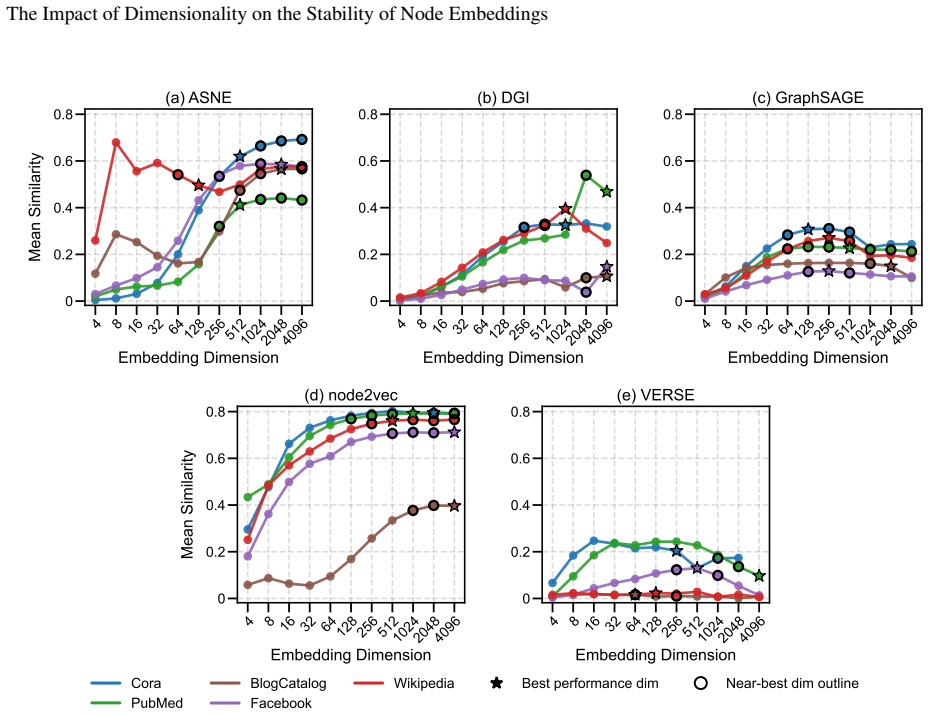
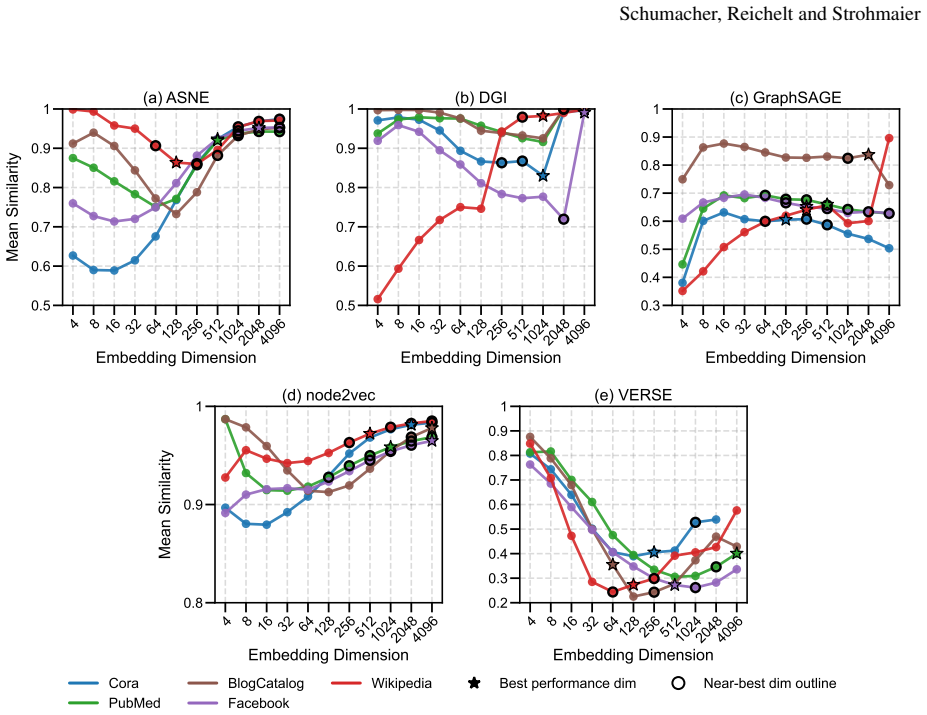
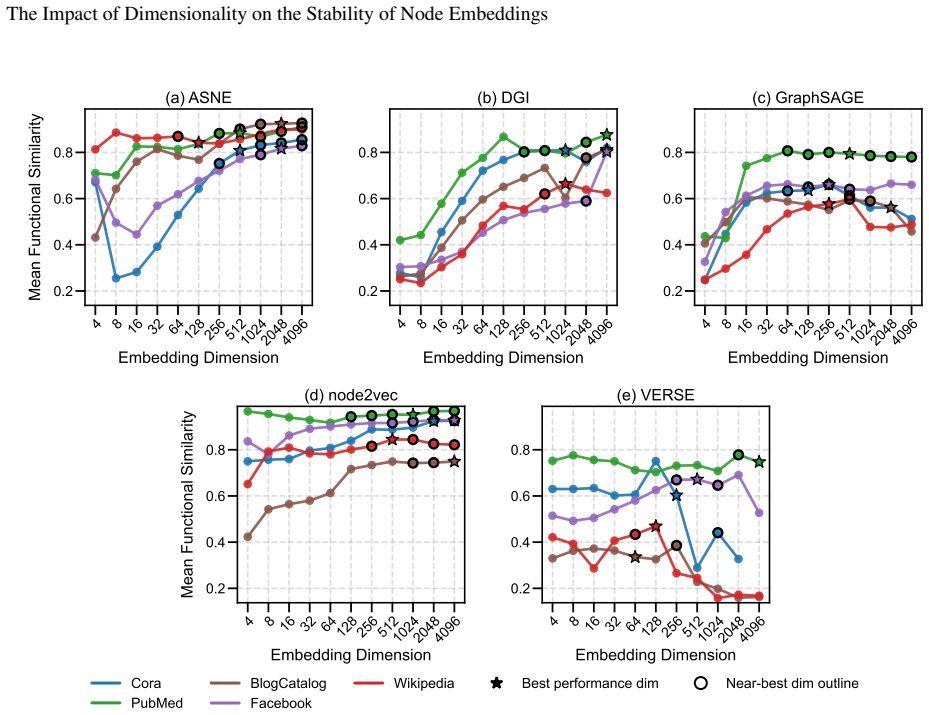
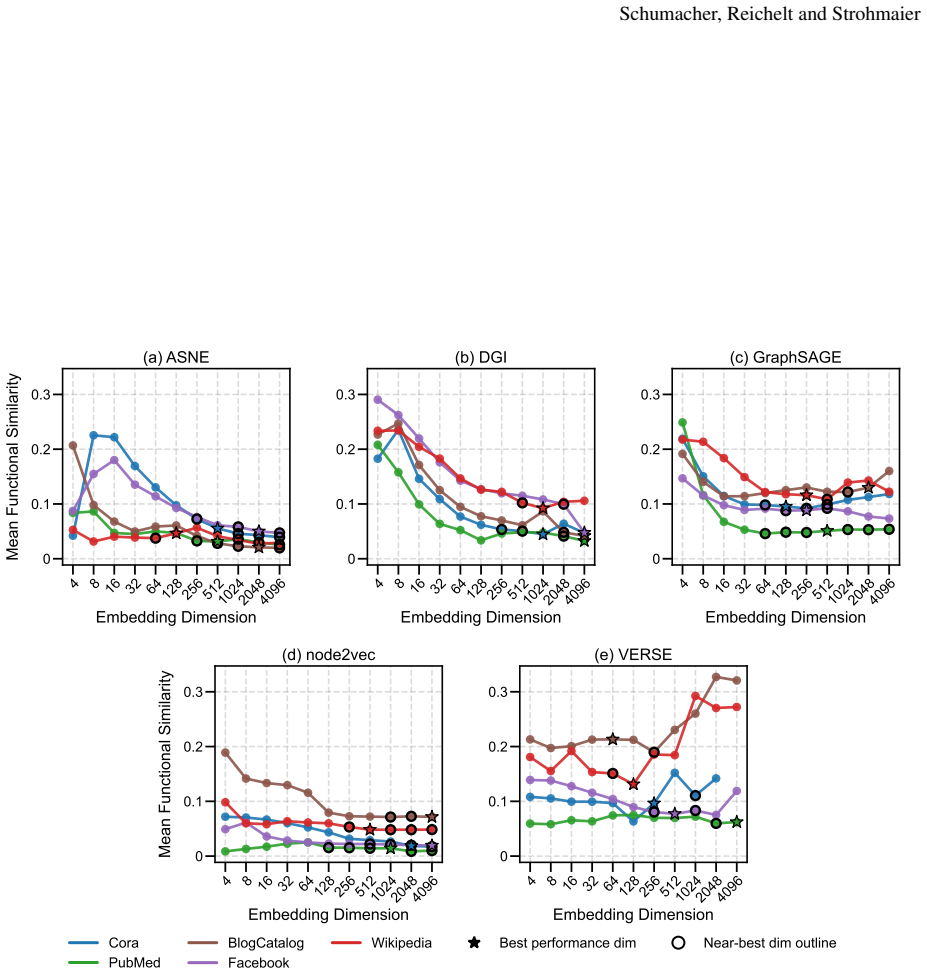
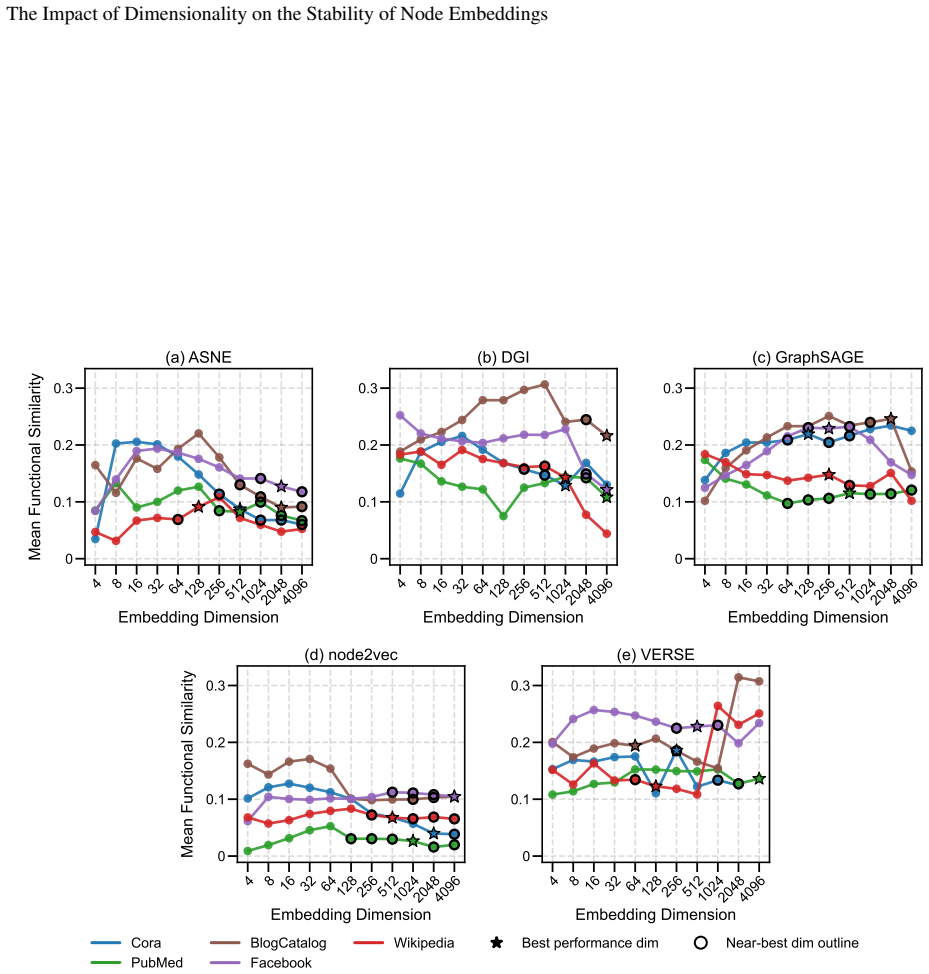
Embedding stability varies significantly with dimensionality, but different methods follow different patterns: node2vec and ASNE tend to become more stable at higher dimensions while DGI, GraphSAGE, and VERSE do not exhibit the same trend. Across all methods, the dimensionality that produces maximum stability does not align with the dimensionality that produces optimal performance on downstream tasks.
What carries the argument
Representational stability (similarity of embedding vectors across random seeds) and functional stability (consistency of downstream task outputs across seeds) measured as functions of embedding dimension for the five algorithms ASNE, DGI, GraphSAGE, node2vec, and VERSE.
If this is right
- Higher embedding dimensions can increase stability for some methods such as node2vec and ASNE.
- Stability and task performance must be optimized separately when selecting embedding dimension.
- Computational cost of higher dimensions is not always offset by gains in either stability or accuracy.
- Different embedding algorithms respond differently to changes in dimension, so method-specific tuning is needed.
Where Pith is reading between the lines
- Practitioners may need to run stability checks across a range of dimensions rather than relying on performance alone to pick a fixed size.
- The observed trade-offs could motivate new training procedures that explicitly regularize for stability at moderate dimensions.
- The method-dependent patterns suggest that algorithm choice itself can be informed by stability requirements of the target application.
Load-bearing premise
That the five chosen embedding methods, the stability metrics, and the selected datasets are representative enough for the observed patterns to hold beyond this experimental setup.
What would settle it
A replication that uses the same five methods but additional datasets or different random seeds and finds that every method becomes steadily more stable with higher dimensionality and that stability and task performance peak at the same dimension would contradict the reported variation in trends and the misalignment result.
Figures
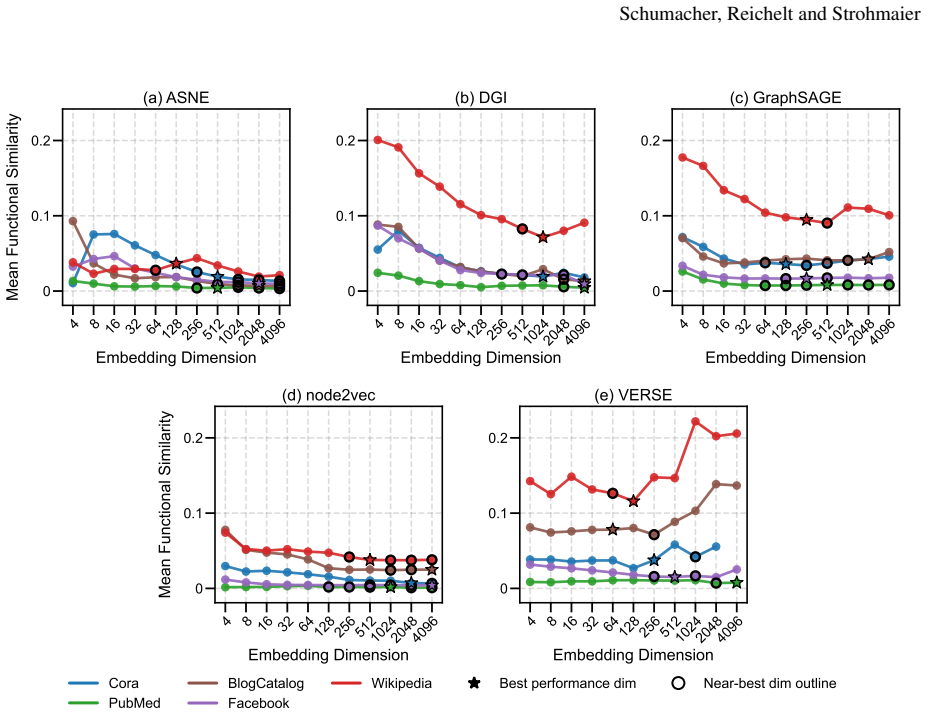

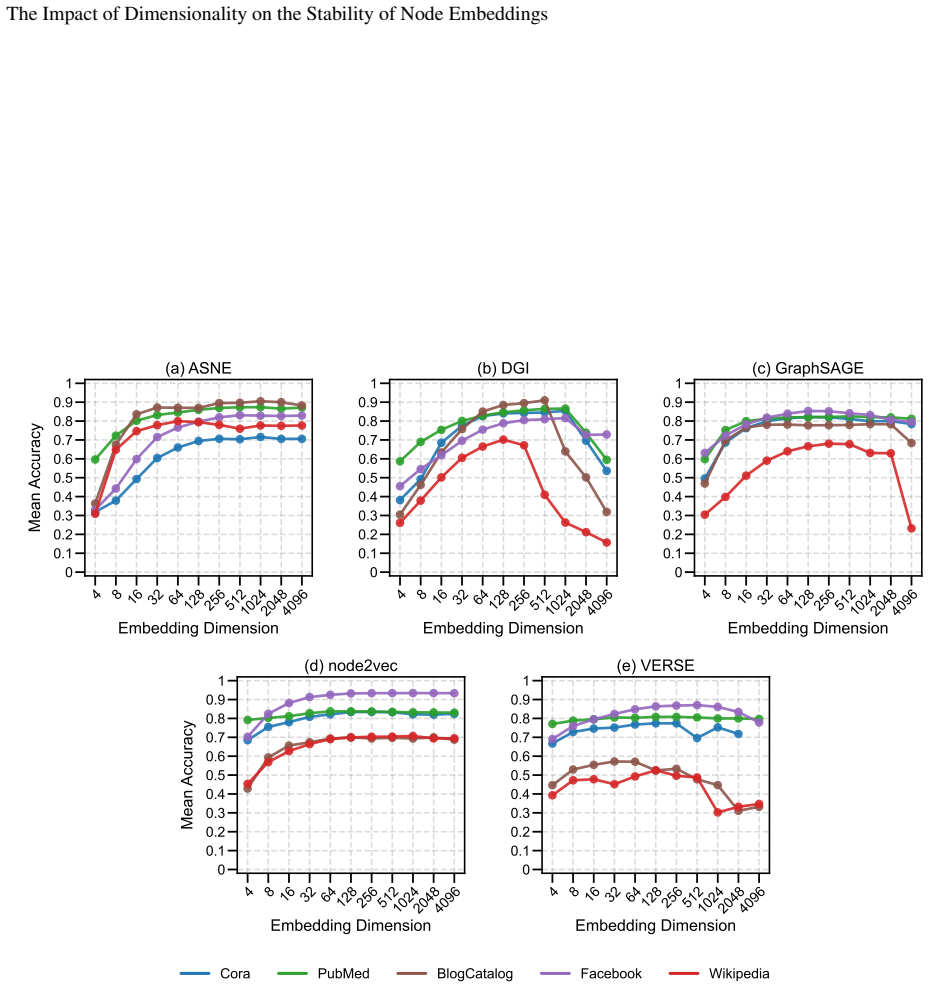
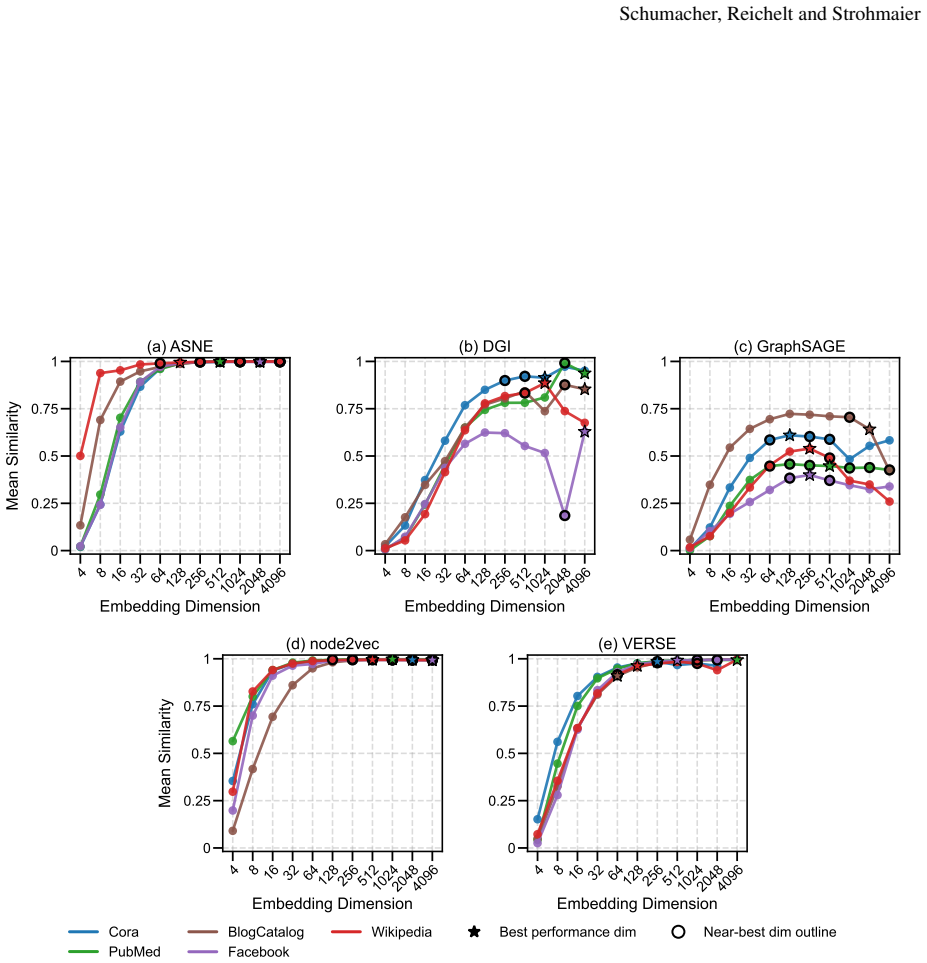
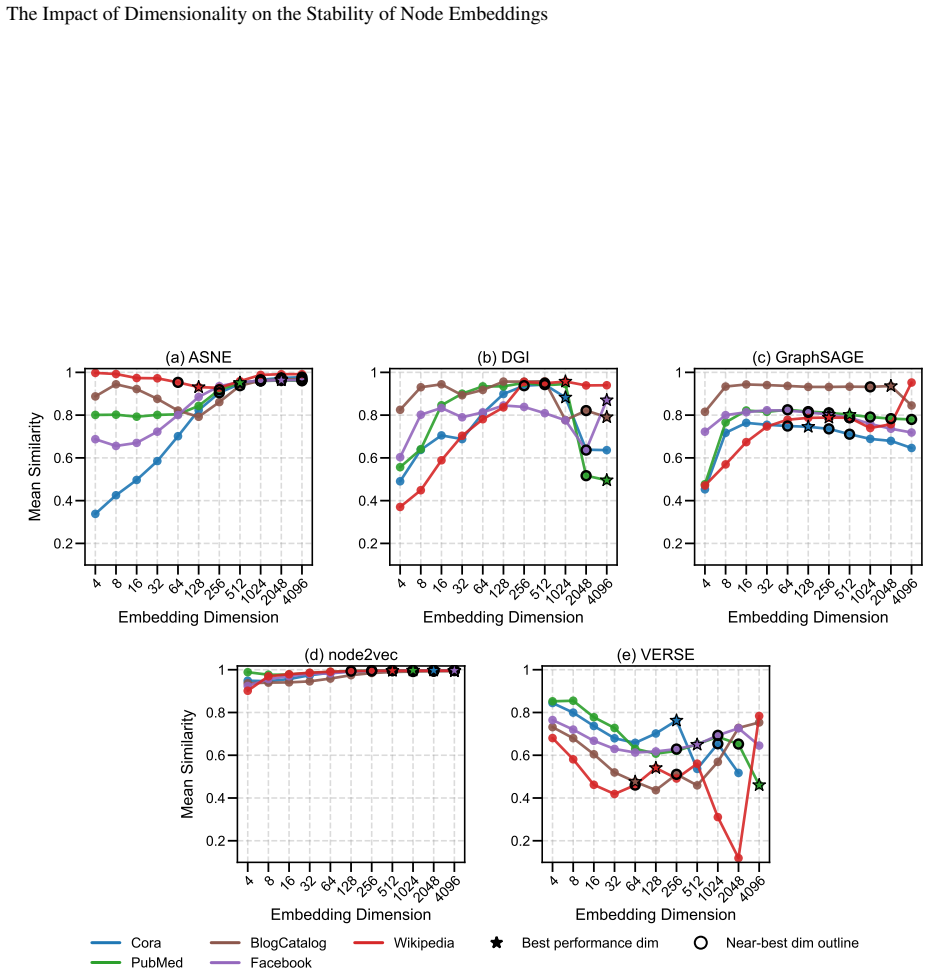
read the original abstract
Previous work has established that neural network-based node embeddings return different outcomes when trained with identical parameters on the same dataset, just from using different training seeds. Yet, it has not been thoroughly analyzed how key hyperparameters such as embedding dimension could impact this instability. In this work, we investigate how varying the dimensionality of node embeddings influences both their stability and downstream performance. We systematically evaluate five widely used methods -- ASNE, DGI, GraphSAGE, node2vec, and VERSE -- across multiple datasets and embedding dimensions. We assess stability from both a representational perspective and a functional perspective, alongside performance evaluation. Our results show that embedding stability varies significantly with dimensionality, but we observe different patterns across the methods we consider: while some approaches, such as node2vec and ASNE, tend to become more stable with higher dimensionality, other methods do not exhibit the same trend. Moreover, we find that maximum stability does not necessarily align with optimal task performance. These findings highlight the importance of carefully selecting embedding dimension, and provide new insights into the trade-offs between stability, performance, and computational effectiveness in graph representation learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts an empirical investigation into the effect of embedding dimensionality on the stability of node embeddings generated by five methods (ASNE, DGI, GraphSAGE, node2vec, VERSE) across multiple datasets. Stability is measured from both representational (e.g., similarity across seeds) and functional (e.g., downstream task consistency) perspectives, with comparisons to task performance. Key findings are that stability trends with increasing dimension are method-dependent (improving for node2vec and ASNE but not uniformly for others) and that the dimensionality yielding maximum stability does not necessarily coincide with optimal downstream performance.
Significance. If the reported patterns hold under the described experimental controls, the work supplies actionable guidance for hyperparameter tuning in graph representation learning by quantifying stability-performance trade-offs as a function of dimension. It extends prior observations of seed-induced variability with a systematic dimension sweep, which is a practically relevant axis, and underscores that stability and accuracy may need independent optimization.
minor comments (3)
- The abstract refers to 'representational perspective and a functional perspective' for stability; the methods section should provide explicit mathematical definitions or pseudocode for these two metrics (including any distance functions or correlation measures used) to allow exact reproduction.
- Results should include per-method, per-dataset tables or plots with error bars or statistical significance tests (e.g., paired t-tests across seeds) rather than qualitative trend descriptions alone, so readers can assess the magnitude and reliability of the reported differences.
- The manuscript should state the exact range of dimensions tested, the number of random seeds per configuration, and the data-split protocol (train/validation/test) to clarify whether any post-hoc selection of dimensions or seeds occurred.
Simulated Author's Rebuttal
We are grateful to the referee for the positive and insightful summary of our manuscript. The recommendation for minor revision is welcome, and we appreciate the acknowledgment of the practical relevance of our findings on stability-performance trade-offs in node embeddings. Given that no major comments were specified, we have no point-by-point rebuttals to provide. We stand ready to make any necessary revisions to the manuscript.
Circularity Check
No significant circularity
full rationale
The paper is a purely empirical study that evaluates five node embedding methods (ASNE, DGI, GraphSAGE, node2vec, VERSE) across datasets and dimensions, measuring representational and functional stability plus downstream task performance. No derivation chain, first-principles prediction, or mathematical result is claimed; all findings are direct experimental observations scoped to the tested setup. No self-definitional quantities, fitted inputs renamed as predictions, or load-bearing self-citations appear. The work is self-contained against external benchmarks and does not reduce any claim to its own inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our results show that embedding stability varies significantly with dimensionality, but we observe different patterns across the methods we consider: while some approaches, such as node2vec and ASNE, tend to become more stable with higher dimensionality...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Detecting the ultra low dimensionality of real networks
Pedro Almagro, Marián Boguñá, and M. Ángeles Serrano. “Detecting the ultra low dimensionality of real networks”. In Nature Communications13(1), pp. 6096, 2022
work page 2022
-
[2]
Evaluating the Stability of Embedding-based Word Similarities
Maria Antoniak and David Mimno. “Evaluating the Stability of Embedding-based Word Similarities”. InTransactions of the Association for Computational Linguistics6, pp. 107–119, 2018
work page 2018
-
[3]
Node Classification in Social Networks
Smriti Bhagat, Graham Cormode, and S. Muthukrishnan. “Node Classification in Social Networks”. InSocial Network Data Analytics. Edited by Charu C. Aggarwal., pp. 115–148, Springer US, Boston, MA, 2011
work page 2011
-
[4]
Dimensionality of Social Networks Using Motifs and Eigenvalues
Anthony Bonato, David F. Gleich, Myunghwan Kim, Dieter Mitsche, Paweł Prałat, Yanhua Tian, and Stephen J. Young. “Dimensionality of Social Networks Using Motifs and Eigenvalues”. InPLOS ONE9(9), pp. e106052, 2014
work page 2014
-
[5]
Are Word Embedding Methods Stable and Should We Care About It?
Angana Borah, Manash Pratim Barman, and Amit Awekar. “Are Word Embedding Methods Stable and Should We Care About It?” InProceedings of the 32nd ACM Conference on Hypertext and Social Media, HT ’21, pp. 45–55, 2021
work page 2021
-
[6]
Deep Neural Networks for Learning Graph Representations
Shaosheng Cao, Wei Lu, and Qiongkai Xu. “Deep Neural Networks for Learning Graph Representations”. InProceedings of the AAAI Conference on Artificial Intelligence30(1), 2016
work page 2016
-
[7]
GRAPE for fast and scalable graph processing and random-walk-based embedding
Luca Cappelletti, Tommaso Fontana, Elena Casiraghi, Vida Ravanmehr, Tiffany J. Callahan, Carlos Cano, Marcin P. Joachimiak, Christopher J. Mungall, Peter N. Robinson, Justin Reese, and Giorgio Valentini. “GRAPE for fast and scalable graph processing and random-walk-based embedding”. InNature Computational Science3(6), pp. 552–568, 2023
work page 2023
-
[8]
Graph representation learning: a survey
Fenxiao Chen, Yun-Cheng Wang, Bin Wang, and C.-C. Jay Kuo. “Graph representation learning: a survey”. InAPSIPA Transactions on Signal and Information Processing9, pp. e15, 2020
work page 2020
-
[9]
Effect of word embedding vector dimensionality on sentiment analysis through short and long texts
Mohamed Chiny, Marouane Chihab, Abdelkarim Ait Lahcen, Omar Bencharef, and Younes Chihab. “Effect of word embedding vector dimensionality on sentiment analysis through short and long texts”. InIAES International Journal of Artificial Intelligence (IJ-AI)12(2), pp. 823, 2023
work page 2023
-
[10]
Stability of Word Embeddings Using Word2Vec
Mansi Chugh, Peter A. Whigham, and Grant Dick. “Stability of Word Embeddings Using Word2Vec”. InAI 2018: Advances in Artificial Intelligence, pp. 812–818, 2018
work page 2018
-
[11]
A min-max cut algorithm for graph partitioning and data clustering
C.H.Q. Ding, Xiaofeng He, Hongyuan Zha, Ming Gu, and H.D. Simon. “A min-max cut algorithm for graph partitioning and data clustering”. InProceedings 2001 IEEE International Conference on Data Mining, pp. 107–114, 2001
work page 2001
-
[12]
Deep network embedding with dimension selection
Tianning Dong, Yan Sun, and Faming Liang. “Deep network embedding with dimension selection”. InNeural Networks179, pp. 106512, 2024
work page 2024
-
[13]
k-NN Embedding Stability for word2vec Hyper-Parametrisation in Scientific Text
Amna Dridi, Mohamed Medhat Gaber, R. Muhammad Atif Azad, and Jagdev Bhogal. “k-NN Embedding Stability for word2vec Hyper-Parametrisation in Scientific Text”. InDiscovery Science, pp. 328–343, 2018
work page 2018
-
[14]
Fast Graph Representation Learning with PyTorch Geometric
Matthias Fey and Jan E Lenssen. “Fast Graph Representation Learning with PyTorch Geometric”. InICLR Workshop on Representation Learning on Graphs and Manifolds, 2019
work page 2019
-
[15]
PyG 2.0: Scalable Learning on Real World Graphs
Matthias Fey, Jinu Sunil, Akihiro Nitta, Rishi Puri, Manan Shah, Blaž Stojanovi ˇc, Ramona Bendias, Alexandria Barghi, Vid Kocijan, Zecheng Zhang, Xinwei He, Jan Eric Lenssen, and Jure Leskovec. “PyG 2.0: Scalable Learning on Real World Graphs”. InTemporal Graph Learning Workshop @ KDD, 2025
work page 2025
-
[16]
Graph embedding techniques, applications, and performance: A survey
Palash Goyal and Emilio Ferrara. “Graph embedding techniques, applications, and performance: A survey”. InKnowledge- Based Systems151, pp. 78–94, 2018
work page 2018
-
[17]
node2vec: Scalable Feature Learning for Networks
Aditya Grover and Jure Leskovec. “node2vec: Scalable Feature Learning for Networks”. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, pp. 855–864, 2016
work page 2016
-
[18]
Grünwald, In Jae Myung, and Mark A
Peter D. Grünwald, In Jae Myung, and Mark A. Pitt.Advances in Minimum Description Length: Theory and Applications. MIT Press, 2005
work page 2005
-
[19]
Principled approach to the selection of the embedding dimension of networks
Weiwei Gu, Aditya Tandon, Yong-Yeol Ahn, and Filippo Radicchi. “Principled approach to the selection of the embedding dimension of networks”. InNature Communications12(1), pp. 3772, 2021
work page 2021
-
[20]
Noise-contrastive estimation: A new estimation principle for unnormalized statistical models
Michael Gutmann and Aapo Hyvärinen. “Noise-contrastive estimation: A new estimation principle for unnormalized statistical models”. InProceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, pp. 297–304, 2010
work page 2010
-
[21]
Inductive Representation Learning on Large Graphs
Will Hamilton, Zhitao Ying, and Jure Leskovec. “Inductive Representation Learning on Large Graphs”. InAdvances in Neural Information Processing Systems30., 2017. 13 Schumacher, Reichelt and Strohmaier
work page 2017
-
[22]
Cultural Shift or Linguistic Drift? Comparing Two Computational Measures of Semantic Change
William L. Hamilton, Jure Leskovec, and Dan Jurafsky. “Cultural Shift or Linguistic Drift? Comparing Two Computational Measures of Semantic Change”. InProceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pp. 2116–2121, 2016
work page 2016
-
[23]
Diachronic Word Embeddings Reveal Statistical Laws of Semantic Change
William L. Hamilton, Jure Leskovec, and Dan Jurafsky. “Diachronic Word Embeddings Reveal Statistical Laws of Semantic Change”. InProceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 1489–1501, 2016
work page 2016
-
[24]
Bad Company—Neighborhoods in Neural Embedding Spaces Considered Harmful
Johannes Hellrich and Udo Hahn. “Bad Company—Neighborhoods in Neural Embedding Spaces Considered Harmful”. InProceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, pp. 2785–2796, 2016
work page 2016
-
[25]
Learning deep representations by mutual information estimation and maximization
R. Devon Hjelm, Alex Fedorov, Samuel Lavoie-Marchildon, Karan Grewal, Phil Bachman, Adam Trischler, and Yoshua Bengio. “Learning deep representations by mutual information estimation and maximization”., 2018
work page 2018
-
[26]
SimRank: a measure of structural-context similarity
Glen Jeh and Jennifer Widom. “SimRank: a measure of structural-context similarity”. InProceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining, KDD ’02, pp. 538–543, 2002
work page 2002
-
[27]
Semi-Supervised Classification with Graph Convolutional Networks
Thomas N. Kipf and Max Welling. “Semi-Supervised Classification with Graph Convolutional Networks”., 2017
work page 2017
-
[28]
On the Prediction Instability of Graph Neural Networks
Max Klabunde and Florian Lemmerich. “On the Prediction Instability of Graph Neural Networks”. InMachine Learning and Knowledge Discovery in Databases, pp. 187–202, 2023
work page 2023
-
[29]
Similarity of Neural Network Models: A Survey of Functional and Representational Measures
Max Klabunde, Tobias Schumacher, Markus Strohmaier, and Florian Lemmerich. “Similarity of Neural Network Models: A Survey of Functional and Representational Measures”. InACM Comput. Surv.57(9), pp. 242:1–242:52, 2025
work page 2025
-
[30]
ReSi: A Comprehensive Benchmark for Representational Similarity Measures
Max Klabunde, Tassilo Wald, Tobias Schumacher, Klaus Maier-Hein, Markus Strohmaier, and Florian Lemmerich. “ReSi: A Comprehensive Benchmark for Representational Similarity Measures”. InThe Thirteenth International Conference on Learning Representations, pp. 40, 2025
work page 2025
-
[31]
How to Generate a Good Word Embedding
Siwei Lai, Kang Liu, Shizhu He, and Jun Zhao. “How to Generate a Good Word Embedding”. InIEEE Intelligent Systems 31(6), pp. 5–14, 2016
work page 2016
-
[32]
Understanding the Downstream Instability of Word Embeddings
Megan Leszczynski, Avner May, Jian Zhang, Sen Wu, Christopher Aberger, and Christopher Re. “Understanding the Downstream Instability of Word Embeddings”. InProceedings of Machine Learning and Systems2, pp. 262–290, 2020
work page 2020
-
[33]
Attributed Social Network Embedding
Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua. “Attributed Social Network Embedding”. InIEEE Transactions on Knowledge and Data Engineering30(12), pp. 2257–2270, 2018
work page 2018
-
[34]
The link prediction problem for social networks
David Liben-Nowell and Jon Kleinberg. “The link prediction problem for social networks”. InProceedings of the twelfth international conference on Information and knowledge management, CIKM ’03, pp. 556–559, 2003
work page 2003
-
[35]
Graph Entropy Guided Node Embedding Dimension Selection for Graph Neural Networks
Gongxu Luo, Jianxin Li, Hao Peng, Carl Yang, Lichao Sun, Philip S. Yu, and Lifang He. “Graph Entropy Guided Node Embedding Dimension Selection for Graph Neural Networks”. InProceedings of the Thirtieth International Joint Conference on Artificial Intelligence, pp. 2767–2774, 2021
work page 2021
-
[36]
Laurens van der Maaten and Geoffrey Hinton. “Visualizing Data using t-SNE”. InJournal of Machine Learning Research 9(86), pp. 2579–2605, 2008
work page 2008
-
[37]
Co-Validation: Using Model Disagreement on Unlabeled Data to Validate Classification Algorithms
Omid Madani, David Pennock, and Gary Flake. “Co-Validation: Using Model Disagreement on Unlabeled Data to Validate Classification Algorithms”. InAdvances in Neural Information Processing Systems17., 2004
work page 2004
-
[38]
Link Prediction or Perdition: the Seeds of Instability in Knowledge Graph Embeddings
Guillaume Méroué, Fabien L. Gandon, and Pierre Monnin. “Link Prediction or Perdition: the Seeds of Instability in Knowledge Graph Embeddings”. In, 2025
work page 2025
-
[39]
Efficient Estimation of Word Representations in Vector Space
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. “Efficient Estimation of Word Representations in Vector Space”. InInternational Conference on Learning Representations 2013 - Workshop Proceedings, 2013
work page 2013
-
[40]
Distributed Representations of Words and Phrases and their Compositionality
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. “Distributed Representations of Words and Phrases and their Compositionality”. InAdvances in Neural Information Processing Systems26., 2013
work page 2013
-
[41]
Nikolaos Nakis, Niels Raunkjær Holm, Andreas Lyhne Fiehn, and Morten Mørup. “How Low Can You Go? Searching for the Intrinsic Dimensionality of Complex Networks using Metric Node Embeddings”., 2024
work page 2024
-
[42]
Asymmetric Transitivity Preserving Graph Embedding
Mingdong Ou, Peng Cui, Jian Pei, Ziwei Zhang, and Wenwu Zhu. “Asymmetric Transitivity Preserving Graph Embedding”. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, pp. 1105–1114, 2016
work page 2016
-
[43]
Lawrence Page, Sergey Brin, Rajeev Motwani, and Terry Winograd.The PageRank Citation Ranking: Bringing Order to the Web.Techreport. 1999
work page 1999
-
[44]
DeepWalk: online learning of social representations
Bryan Perozzi, Rami Al-Rfou, and Steven Skiena. “DeepWalk: online learning of social representations”. InProceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining, KDD ’14, pp. 701–710, 2014
work page 2014
-
[45]
Investigating the stability of concrete nouns in word embeddings
Bénédicte Pierrejean and Ludovic Tanguy. “Investigating the stability of concrete nouns in word embeddings”. In13th International Conference on Computational Semantics, 2019
work page 2019
-
[46]
struc2vec: Learning Node Representations from Structural Identity
Leonardo F.R. Ribeiro, Pedro H.P. Saverese, and Daniel R. Figueiredo. “struc2vec: Learning Node Representations from Structural Identity”. InProceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’17, pp. 385–394, 2017
work page 2017
-
[47]
Multi-Scale attributed node embedding
Benedek Rozemberczki, Carl Allen, and Rik Sarkar. “Multi-Scale attributed node embedding”. InJournal of Complex Networks9(2), pp. cnab014, 2021. 14 The Impact of Dimensionality on the Stability of Node Embeddings
work page 2021
-
[48]
Karate Club: An API Oriented Open-Source Python Framework for Unsupervised Learning on Graphs
Benedek Rozemberczki, Oliver Kiss, and Rik Sarkar. “Karate Club: An API Oriented Open-Source Python Framework for Unsupervised Learning on Graphs”. InProceedings of the 29th ACM International Conference on Information & Knowledge Management, CIKM ’20, pp. 3125–3132, 2020
work page 2020
-
[49]
The Graph Neural Network Model
Franco Scarselli, Marco Gori, Ah Chung Tsoi, Markus Hagenbuchner, and Gabriele Monfardini. “The Graph Neural Network Model”. InIEEE Transactions on Neural Networks20(1), pp. 61–80, 2009
work page 2009
-
[50]
The Effects of Randomness on the Stability of Node Embeddings
Tobias Schumacher, Hinrikus Wolf, Martin Ritzert, Florian Lemmerich, Martin Grohe, and Markus Strohmaier. “The Effects of Randomness on the Stability of Node Embeddings”. InMachine Learning and Principles and Practice of Knowledge Discovery in Databases, pp. 197–215, 2021
work page 2021
-
[51]
Geometric instability of graph neural networks on large graphs
Borun Shi, Emily Morris, Haotian Shen, Weiling Du, and Muhammad Hamza Sajjad. “Geometric instability of graph neural networks on large graphs”., 2023
work page 2023
-
[52]
Measuring and testing dependence by correlation of distances
Gábor J. Székely, Maria L. Rizzo, and Nail K. Bakirov. “Measuring and testing dependence by correlation of distances”. In The Annals of Statistics35(6), pp. 2769–2794, 2007
work page 2007
-
[53]
LINE: Large-scale Information Network Embedding
Jian Tang, Meng Qu, Mingzhe Wang, Ming Zhang, Jun Yan, and Qiaozhu Mei. “LINE: Large-scale Information Network Embedding”. InProceedings of the 24th International Conference on World Wide Web, WWW ’15, pp. 1067–1077, 2015
work page 2015
-
[54]
VERSE: Versatile Graph Embeddings from Similarity Measures
Anton Tsitsulin, Davide Mottin, Panagiotis Karras, and Emmanuel Müller. “VERSE: Versatile Graph Embeddings from Similarity Measures”. InProceedings of the 2018 World Wide Web Conference, WWW ’18, pp. 539–548, 2018
work page 2018
-
[55]
Petar Veliˇckovi´c, William Fedus, William L. Hamilton, Pietro Liò, Yoshua Bengio, and R. Devon Hjelm. “Deep Graph Infomax”., 2018
work page 2018
-
[56]
Towards Understanding the Instability of Network Embedding
Chenxu Wang, Wei Rao, Wenna Guo, Pinghui Wang, Jun Liu, and Xiaohong Guan. “Towards Understanding the Instability of Network Embedding”. InIEEE Transactions on Knowledge and Data Engineering34(2), pp. 927–941, 2022
work page 2022
-
[57]
Structural Deep Network Embedding
Daixin Wang, Peng Cui, and Wenwu Zhu. “Structural Deep Network Embedding”. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, pp. 1225–1234, 2016
work page 2016
-
[58]
On the Dimensionality of Sentence Embeddings
Hongwei Wang, Hongming Zhang, and Dong Yu. “On the Dimensionality of Sentence Embeddings”. InFindings of the Association for Computational Linguistics: EMNLP 2023, pp. 10344–10354, 2023
work page 2023
-
[59]
Single Training Dimension Selection for Word Embedding with PCA
Yu Wang. “Single Training Dimension Selection for Word Embedding with PCA”. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 3597–3602, 2019
work page 2019
-
[60]
Factors Influencing the Surprising Instability of Word Embeddings
Laura Wendlandt, Jonathan K. Kummerfeld, and Rada Mihalcea. “Factors Influencing the Surprising Instability of Word Embeddings”. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pp. 2092–2102, 2018
work page 2018
-
[61]
Optimal Node Embedding Dimension Selection Using Overall Entropy
Xinrun Xu, Zhiming Ding, Yurong Wu, Jin Yan, Shan Jiang, and Qinglong Cui. “Optimal Node Embedding Dimension Selection Using Overall Entropy”. InArtificial Neural Networks and Machine Learning – ICANN 2023, pp. 114–127, 2023
work page 2023
-
[62]
PANE: scalable and effective attributed network embedding
Renchi Yang, Jieming Shi, Xiaokui Xiao, Yin Yang, Sourav S. Bhowmick, and Juncheng Liu. “PANE: scalable and effective attributed network embedding”. InThe VLDB Journal32(6), pp. 1237–1262, 2023
work page 2023
-
[63]
Revisiting Semi-Supervised Learning with Graph Embeddings
Zhilin Yang, William Cohen, and Ruslan Salakhudinov. “Revisiting Semi-Supervised Learning with Graph Embeddings”. In Proceedings of The 33rd International Conference on Machine Learning, pp. 40–48, 2016
work page 2016
-
[64]
On the Dimensionality of Word Embedding
Zi Yin and Yuanyuan Shen. “On the Dimensionality of Word Embedding”. InAdvances in Neural Information Processing Systems31., 2018
work page 2018
-
[65]
Ryo Yuki, Atsushi Suzuki, and Kenji Yamanishi. “Dimensionality and Curvature Selection of Graph Embedding using Decomposed Normalized Maximum Likelihood Code-Length”. In2023 IEEE International Conference on Data Mining (ICDM), pp. 1517–1522, 2023. A Hyperparameters In our experiments, if not mentioned otherwise, we largely utilized default parameters of t...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.