What do Language Models Learn and When? The Implicit Curriculum Hypothesis
Pith reviewed 2026-05-10 17:49 UTC · model grok-4.3
The pith
Language models acquire skills in a consistent compositional order during pretraining, predictable from their internal representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
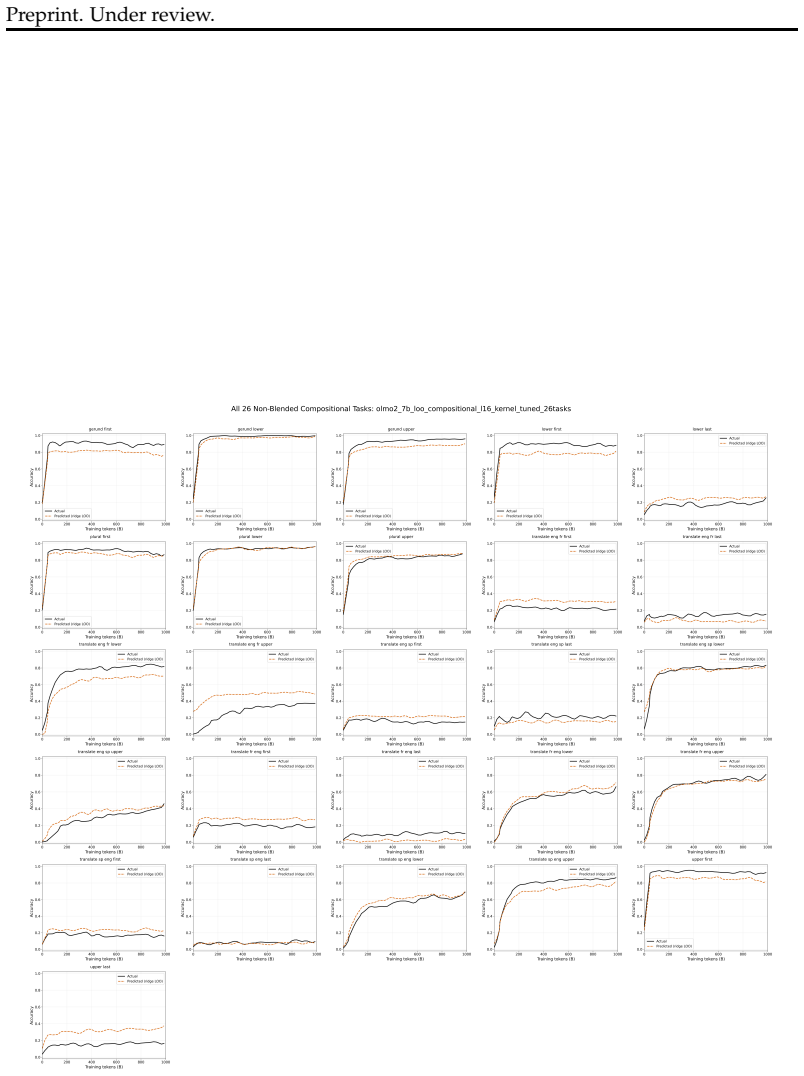
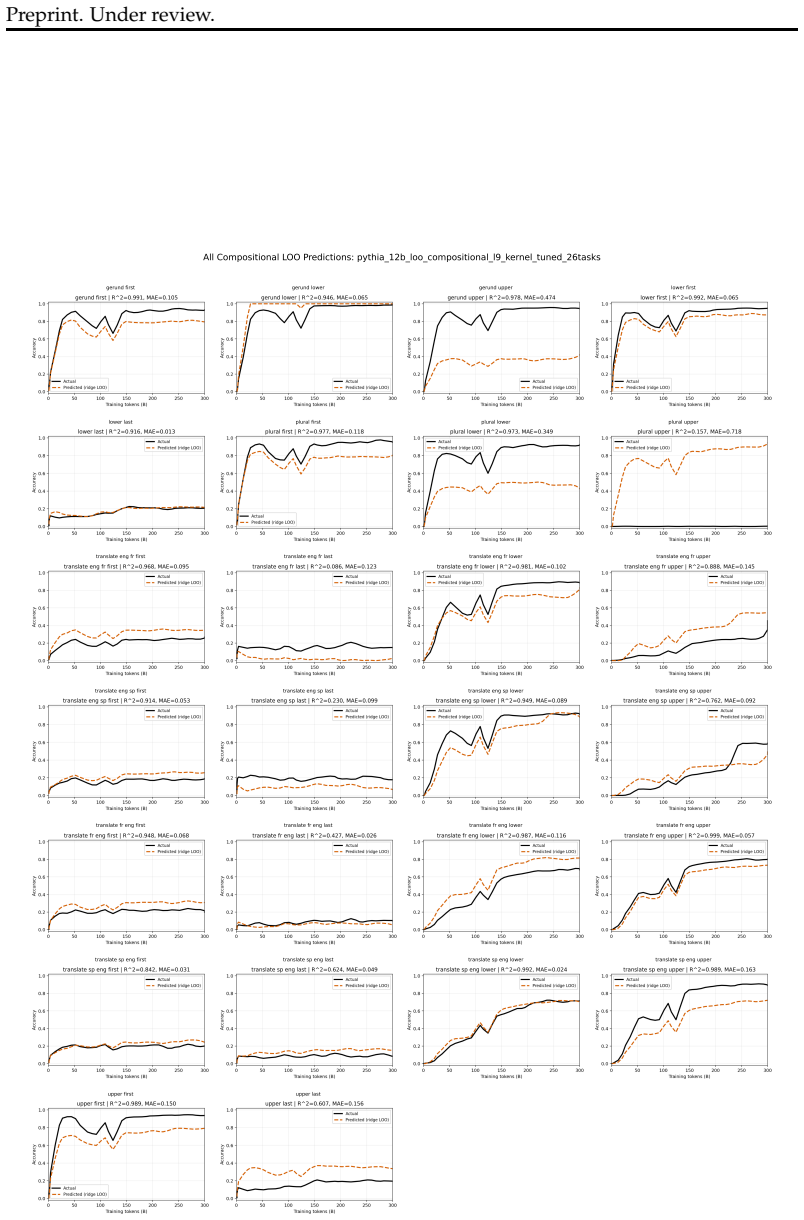
The Implicit Curriculum Hypothesis claims that pretraining follows a compositional and predictable curriculum across models and data mixtures. Tracking a suite of simple composable tasks across four model families from 410M to 13B parameters shows emergence orderings that remain stable with Spearman rank correlation of 0.81 across 45 model pairs, while composite tasks emerge after their components. Similarities among tasks in function-vector space further correspond to aligned learning curves, allowing the authors to predict trajectories for held-out compositional tasks with R-squared values between 0.68 and 0.84 without ever evaluating those tasks directly.
What carries the argument
The Implicit Curriculum Hypothesis, tested via a suite of simple composable tasks whose emergence orderings and function-vector representations encode predictable training trajectories.
If this is right
- Skill emergence order remains similar across model sizes and families.
- Composite tasks reliably appear after their component tasks.
- Model representations encode information sufficient to forecast future task performance.
- Held-out compositional tasks can be tracked without direct evaluation during training.
- Pretraining dynamics contain compositional structure beyond what aggregate loss reveals.
Where Pith is reading between the lines
- Training data mixtures could be adjusted to accelerate or reorder specific capability development.
- The same representation space might be used to monitor real-time progress on abilities not yet directly tested.
- Extending the task suite to more complex or open-ended problems could reveal whether the curriculum persists at larger scales.
- This structure may help explain why certain capabilities remain absent in smaller models even after extensive training.
Load-bearing premise
The suite of simple composable tasks accurately reflects the compositional structure of capabilities that arise during pretraining on natural language.
What would settle it
Running the same task suite on a new model family or data mixture and finding emergence orderings that differ markedly from the previously observed consistent pattern, or finding that representation-based predictions no longer match measured trajectories.
Figures



















read the original abstract
Large language models (LLMs) can perform remarkably complex tasks, yet the fine-grained details of how these capabilities emerge during pretraining remain poorly understood. Scaling laws on validation loss tell us how much a model improves with additional compute, but not what skills it acquires in which order. To remedy this, we propose the Implicit Curriculum Hypothesis: pretraining follows a compositional and predictable curriculum across models and data mixtures. We test this by designing a suite of simple, composable tasks spanning retrieval, morphological transformations, coreference, logical reasoning, and mathematics. Using these tasks, we track emergence points across four model families spanning sizes from 410M-13B parameters. We find that emergence orderings of when models reach fixed accuracy thresholds are strikingly consistent ($\rho = .81$ across 45 model pairs), and that composite tasks most often emerge after their component tasks. Furthermore, we find that this structure is encoded in model representations: tasks with similar function vector representations also tend to follow similar trajectories in training. By using the space of representations derived from our task set, we can effectively predict the training trajectories of simple held-out compositional tasks throughout the course of pretraining ($R^2 = .68$-$.84$ across models) without previously evaluating them. Together, these results suggest that pretraining is more structured than loss curves reveal: skills emerge in a compositional order that is consistent across models and readable from their internals.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Implicit Curriculum Hypothesis that pretraining of large language models follows a compositional and predictable curriculum across models and data mixtures. The authors design a suite of simple composable tasks spanning retrieval, morphological transformations, coreference, logical reasoning, and mathematics; they track emergence points (fixed accuracy thresholds) across four model families (410M–13B parameters), report consistent emergence orderings (Spearman’s ρ = .81 across 45 model pairs), show that composite tasks typically emerge after their components, and demonstrate that task function-vector representations allow prediction of held-out compositional task trajectories (R² = .68–.84) without prior evaluation.
Significance. If the hand-designed task suite is shown to instantiate the same compositional dependencies that drive emergence on natural data, the results would provide a concrete, falsifiable framework for studying fine-grained capability acquisition beyond aggregate scaling laws. The reported consistency of orderings across model families and the predictive use of internal representations are notable empirical strengths that could inform both mechanistic interpretability and training interventions.
major comments (2)
- [Abstract and experimental design] The central claim concerns the structure of pretraining on natural language data, yet all quantitative support (ρ = .81, composite-after-component ordering, R² = .68–.84) is obtained exclusively on the authors’ hand-designed suite; no experiment or analysis is presented that tests whether the observed orderings or representational similarities align with capabilities that actually emerge from natural pretraining distributions (e.g., by probing for known emergent skills such as multi-step arithmetic or coreference in naturally occurring contexts). This assumption is load-bearing for the Implicit Curriculum Hypothesis.
- [Methods and results sections] The manuscript provides insufficient detail on task construction, accuracy-threshold selection, and controls for confounds such as task difficulty, token overlap with pretraining data, or prompt sensitivity; without these, it is impossible to determine whether the reported consistency and predictability are robust properties of the pretraining process or artifacts of the particular task definitions and evaluation protocol.
minor comments (2)
- [Representation analysis] The description of how function vectors are extracted and how similarity is quantified could be expanded with an explicit equation or pseudocode to improve reproducibility.
- [Figures] Figure legends and axis labels should explicitly state the accuracy threshold used for each emergence curve and the number of seeds or runs averaged.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important considerations for strengthening the manuscript. We address each major comment below with clarifications on our design choices and commitments to revisions where the concerns are valid.
read point-by-point responses
-
Referee: [Abstract and experimental design] The central claim concerns the structure of pretraining on natural language data, yet all quantitative support (ρ = .81, composite-after-component ordering, R² = .68–.84) is obtained exclusively on the authors’ hand-designed suite; no experiment or analysis is presented that tests whether the observed orderings or representational similarities align with capabilities that actually emerge from natural pretraining distributions (e.g., by probing for known emergent skills such as multi-step arithmetic or coreference in naturally occurring contexts). This assumption is load-bearing for the Implicit Curriculum Hypothesis.
Authors: We agree that the central claim targets the structure of natural pretraining, and our experiments rely on a controlled hand-designed suite as a proxy. This choice enables precise isolation of compositional dependencies (retrieval, morphology, coreference, logic, math) and exact measurement of emergence orderings and function-vector predictability—analyses that are difficult to perform cleanly on noisy natural data. The suite was constructed to instantiate core compositional patterns known to underlie many emergent capabilities in language. While we have not conducted direct alignment experiments (e.g., probing natural contexts for multi-step arithmetic or coreference), the high consistency of orderings across four model families and the ability to predict held-out trajectories from representations provide evidence that the observed structure is not an artifact of the suite alone. In revision we will (a) explicitly qualify the scope in the abstract and introduction, (b) add a dedicated limitations subsection discussing the proxy nature of the tasks and their relation to documented natural emergent skills, and (c) outline concrete future directions for validating the orderings against natural pretraining distributions. We maintain that the current results constitute a necessary, falsifiable first step toward the hypothesis. revision: partial
-
Referee: [Methods and results sections] The manuscript provides insufficient detail on task construction, accuracy-threshold selection, and controls for confounds such as task difficulty, token overlap with pretraining data, or prompt sensitivity; without these, it is impossible to determine whether the reported consistency and predictability are robust properties of the pretraining process or artifacts of the particular task definitions and evaluation protocol.
Authors: We accept this criticism and will substantially expand the Methods and Results sections. Specifically, we will add: (1) full task-construction details, including primitive definitions, composition rules, and example prompts for every task; (2) explicit justification and sensitivity analysis for the accuracy thresholds used to mark emergence (currently 70 %); (3) quantitative controls for task difficulty via random-model baselines and length-matched controls; (4) token-overlap statistics between task prompts and common pretraining corpora (e.g., The Pile, C4); and (5) prompt-sensitivity results across at least three prompt templates per task. These additions will appear in the main text where space permits and in a new appendix containing complete task specifications, code snippets, and robustness tables. We believe these revisions will allow readers to evaluate whether the reported consistency (ρ = .81) and predictive R² values reflect genuine pretraining structure. revision: yes
Circularity Check
No circularity: claims rest on direct empirical measurements of held-out tasks
full rationale
The paper designs a task suite, measures emergence orderings across models (ρ = .81), observes composite-after-component patterns, and reports R² = .68-.84 for predicting trajectories of held-out compositional tasks from representation spaces. These steps are empirical evaluations and cross-task predictions on explicitly held-out items; they do not reduce by construction to fitted parameters, self-definitions, or self-citation chains. No equations or derivations are presented that equate outputs to inputs tautologically. The central results remain falsifiable against external benchmarks and do not rely on renaming or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The selected tasks are representative of compositional capabilities in language models.
Reference graph
Works this paper leans on
-
[1]
doi: 10.18653/v1/2021.findings-emnlp
Association for Computational Linguistics. doi: 10.18653/v1/2021.findings-emnlp
-
[2]
URLhttps://aclanthology.org/2021.findings-emnlp.71/. 11 Preprint. Under review. Zhengzhong Liu, Aurick Qiao, Willie Neiswanger, Hongyi Wang, Bowen Tan, Tianhua Tao, Junbo Li, Yuqi Wang, Suqi Sun, Omkar Pangarkar, Richard Fan, Yi Gu, Victor Miller, Yonghao Zhuang, Guowei He, Haonan Li, Fajri Koto, Liping Tang, Nikhil Ranjan, Zhiqiang Shen, Xuguang Ren, Rob...
-
[3]
URLhttps://aclanthology.org/2021.acl-long.414/. James A. Michaelov, Roger P . Levy, and Benjamin K. Bergen. Language model behavioral phases are consistent across architecture, training data, and scale, 2025. URL https: //arxiv.org/abs/2510.24963. Eric J Michaud, Ziming Liu, Uzay Girit, and Max Tegmark. The quantization model of neural scaling. InThirty-s...
-
[4]
Alice gave five apples to Bob at the park
URLhttps://openreview.net/forum?id=j5BuTrEj35. Preetum Nakkiran, Gal Kaplun, Dimitris Kalimeris, Tristan Yang, Benjamin L. Edelman, Fred Zhang, and Boaz Barak. Sgd on neural networks learns functions of increasing complexity, 2019. URLhttps://arxiv.org/abs/1905.11604. Olmo. Olmo 3: Charting a path through the model flow to lead open-source ai.AI2 Blog Nov...
-
[5]
QPPQ 2. HGHH 3. TTTU 4. DDDE
-
[6]
Identify the pattern and find the correct position in row 5
MLMM 1 textfrct:I228 Instr.: Each row marks one position with ‘x’. Identify the pattern and find the correct position in row 5. ------- x------- ---- -- ---- -x--- -- --- ------ --------------- --x----- -------- ---x----------- ----1 2---3-- 4---5----- 3 Associative Memory (FRCT) textfrct:MA230 Instr.: Memorize 30 word–number pairs, then answer re- trieva...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.