E-3DPSM: A State Machine for Event-Based Egocentric 3D Human Pose Estimation
Pith reviewed 2026-05-10 16:47 UTC · model grok-4.3
The pith
E-3DPSM evolves latent states aligned with event dynamics and fuses them with direct predictions to produce stable, drift-free 3D pose reconstructions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
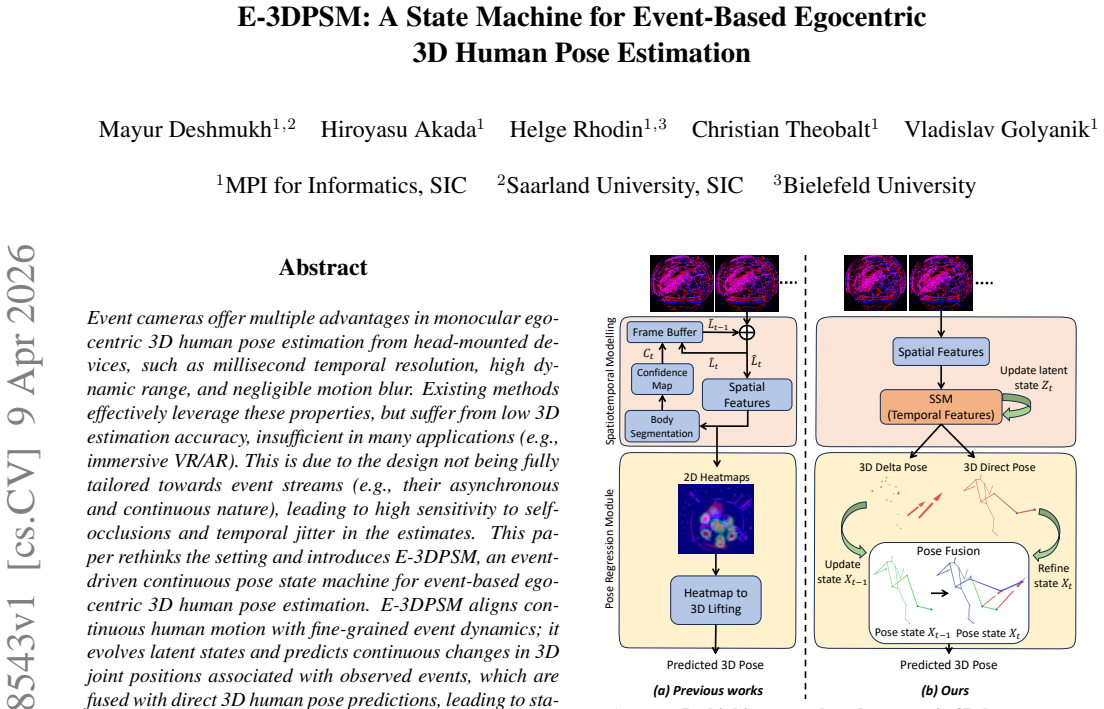
E-3DPSM aligns continuous human motion with fine-grained event dynamics; it evolves latent states and predicts continuous changes in 3D joint positions associated with observed events, which are fused with direct 3D human pose predictions, leading to stable and drift-free final 3D pose reconstructions.
What carries the argument
The event-driven continuous pose state machine (E-3DPSM) that evolves latent states aligned with fine-grained event dynamics and fuses predictions of continuous joint position changes with direct pose estimates.
If this is right
- Accuracy improves by up to 19 percent MPJPE on the two evaluation benchmarks.
- Temporal stability improves by up to 2.7 times compared with prior methods.
- The system runs in real time at 80 Hz on a single workstation.
- Sensitivity to self-occlusions and temporal jitter is reduced in egocentric event streams.
Where Pith is reading between the lines
- The latent-state evolution mechanism could transfer to other asynchronous vision tasks such as object tracking or visual odometry.
- The fusion of evolved states with direct predictions may improve stability in hybrid event-plus-frame pose estimators.
- Real-time operation on modest hardware suggests the design could support always-on tracking in wearable AR devices.
Load-bearing premise
Evolving latent states aligned with fine-grained event dynamics and fusing them with direct predictions will produce stable, drift-free 3D reconstructions without introducing new error sources.
What would settle it
Experiments on the two benchmarks where the full E-3DPSM pipeline fails to reduce MPJPE by the reported margin or to improve temporal stability metrics relative to prior event-based methods.
Figures











read the original abstract
Event cameras offer multiple advantages in monocular egocentric 3D human pose estimation from head-mounted devices, such as millisecond temporal resolution, high dynamic range, and negligible motion blur. Existing methods effectively leverage these properties, but suffer from low 3D estimation accuracy, insufficient in many applications (e.g., immersive VR/AR). This is due to the design not being fully tailored towards event streams (e.g., their asynchronous and continuous nature), leading to high sensitivity to self-occlusions and temporal jitter in the estimates. This paper rethinks the setting and introduces E-3DPSM, an event-driven continuous pose state machine for event-based egocentric 3D human pose estimation. E-3DPSM aligns continuous human motion with fine-grained event dynamics; it evolves latent states and predicts continuous changes in 3D joint positions associated with observed events, which are fused with direct 3D human pose predictions, leading to stable and drift-free final 3D pose reconstructions. E-3DPSM runs in real-time at 80 Hz on a single workstation and sets a new state of the art in experiments on two benchmarks, improving accuracy by up to 19% (MPJPE) and temporal stability by up to 2.7x. See our project page for the source code and trained models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces E-3DPSM, an event-driven continuous pose state machine for monocular egocentric 3D human pose estimation from event cameras. It evolves latent states aligned with fine-grained asynchronous event dynamics, predicts incremental 3D joint position changes, and fuses these predictions with direct pose estimates to produce stable, drift-free reconstructions. The method is claimed to run in real time at 80 Hz and to set a new state of the art on two benchmarks, with up to 19% MPJPE accuracy gains and 2.7× improvement in temporal stability.
Significance. If the empirical gains and design choices are rigorously validated, the work would be significant for event-based vision in VR/AR, where high temporal resolution and robustness to motion blur are critical. The continuous state-machine formulation tailored to event streams addresses a recognized limitation of prior frame-based or recurrent methods and could influence subsequent architectures for asynchronous sensing.
major comments (3)
- [Experiments] Experiments section: the reported 19% MPJPE and 2.7× stability improvements are presented without data splits, number of runs, error bars, or statistical tests, making it impossible to assess whether the gains are robust or attributable to the state-machine components rather than implementation details.
- [§3] §3 (Method): the state-evolution and fusion equations are described at a high level only; no explicit update rule, loss terms, or pseudocode is given for how latent states are advanced from raw events and combined with direct predictions, leaving open the possibility that the fusion introduces new drift or parameter sensitivity.
- [Table 1] Table 1 / benchmark results: quantitative comparisons to prior event-based egocentric pose methods are missing or incomplete; without identical train/test splits and the same evaluation protocol, the SOTA claim cannot be verified.
minor comments (2)
- [Abstract] Abstract: the statement 'See our project page for the source code and trained models' should include an explicit URL or DOI in the camera-ready version.
- [§3] Notation: the distinction between 'direct 3D human pose predictions' and 'incremental changes' is used repeatedly but never formalized with symbols or a diagram; a small notation table would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of experimental rigor, methodological clarity, and benchmark comparisons that we will address in the revision. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the reported 19% MPJPE and 2.7× stability improvements are presented without data splits, number of runs, error bars, or statistical tests, making it impossible to assess whether the gains are robust or attributable to the state-machine components rather than implementation details.
Authors: We agree that the current experimental reporting lacks sufficient statistical detail to fully substantiate the claimed improvements. In the revised manuscript we will explicitly document the train/test splits for both benchmarks, report all quantitative results as means over at least five independent training runs with standard-deviation error bars, and include paired statistical significance tests (e.g., Wilcoxon signed-rank) comparing the full E-3DPSM model against its ablated variants to demonstrate that the gains arise from the state-machine components rather than implementation artifacts. revision: yes
-
Referee: [§3] §3 (Method): the state-evolution and fusion equations are described at a high level only; no explicit update rule, loss terms, or pseudocode is given for how latent states are advanced from raw events and combined with direct predictions, leaving open the possibility that the fusion introduces new drift or parameter sensitivity.
Authors: We will expand Section 3 with the precise mathematical update rules for advancing the latent pose state from asynchronous events, the complete set of loss terms (including any drift-regularization components), and a concise pseudocode listing that shows the exact sequence of state evolution, incremental prediction, and fusion steps. These additions will enable full reproducibility and allow readers to inspect potential drift or sensitivity issues directly. revision: yes
-
Referee: [Table 1] Table 1 / benchmark results: quantitative comparisons to prior event-based egocentric pose methods are missing or incomplete; without identical train/test splits and the same evaluation protocol, the SOTA claim cannot be verified.
Authors: We have included comparisons against the main prior event-based egocentric methods in Table 1, but we acknowledge that the alignment of splits and protocols was not stated with sufficient explicitness. In the revision we will enlarge the table to cover every relevant published event-based baseline, clearly tabulate the exact train/test splits and evaluation protocol used for each entry (re-implementing open-source methods where necessary to enforce identical conditions), and qualify the SOTA claim under these consistent settings. revision: partial
Circularity Check
No significant circularity; design is forward-engineered and externally validated
full rationale
The paper introduces E-3DPSM as a new continuous state machine that evolves latent states from asynchronous event dynamics, predicts incremental 3D joint changes, and fuses them with direct pose estimates to mitigate drift. This architecture is presented as a tailored engineering response to event-camera properties (millisecond resolution, high dynamic range) rather than a re-derivation of its own outputs. Performance improvements (up to 19% MPJPE, 2.7× stability) are reported as empirical results on two external benchmarks. No equations, self-citations, or fitted components are shown to reduce the central claim to a tautology or to prior self-referential results; the derivation chain remains self-contained against independent data.
Axiom & Free-Parameter Ledger
invented entities (1)
-
continuous pose state machine
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Un- realego: A new dataset for robust egocentric 3d human mo- tion capture
Hiroyasu Akada, Jian Wang, Soshi Shimada, Masaki Taka- hashi, Christian Theobalt, and Vladislav Golyanik. Un- realego: A new dataset for robust egocentric 3d human mo- tion capture. InEuropean Conference on Computer Vision (ECCV), 2022. 1, 2
work page 2022
-
[2]
3d human pose perception from egocentric stereo videos
Hiroyasu Akada, Jian Wang, Vladislav Golyanik, and Chris- tian Theobalt. 3d human pose perception from egocentric stereo videos. InComputer Vision and Pattern Recognition (CVPR), 2024. 2, 4, 5
work page 2024
-
[3]
Bring your rear cameras for egocentric 3d hu- man pose estimation
Hiroyasu Akada, Jian Wang, Vladislav Golyanik, and Chris- tian Theobalt. Bring your rear cameras for egocentric 3d hu- man pose estimation. InInternational Conference on Com- puter Vision (ICCV), 2025. 1, 2
work page 2025
-
[4]
Richard S. Bucy and Peter D. Joseph.Filtering for Stochas- tic Processes with Applications to Guidance. AMS Chelsea Publishing, 2nd edition, 2005. 5
work page 2005
-
[5]
Dhp19: Dynamic vision sensor 3d human pose dataset
Enrico Calabrese, Gemma Taverni, Christopher Awai East- hope, Sophie Skriabine, Federico Corradi, Luca Longinotti, Kynan Eng, and Tobi Delbruck. Dhp19: Dynamic vision sensor 3d human pose dataset. InComputer Vision and Pat- tern Recognition (CVPR) Workshops, 2019. 3
work page 2019
-
[6]
Stefan Elfwing, Eiji Uchibe, and Kenji Doya. Sigmoid- weighted linear units for neural network function approxima- tion in reinforcement learning.Neural networks, 107:3–11,
-
[7]
Derpa- nis, and Davide Scaramuzza
Daniel Gehrig, Antonio Loquercio, Konstantinos G. Derpa- nis, and Davide Scaramuzza. End-to-end learning of rep- resentations for asynchronous event-based data. InInterna- tional Conference on Computer Vision (ICCV), 2019. 13
work page 2019
-
[8]
Recurrent vision transformers for object detection with event cameras
Mathias Gehrig and Davide Scaramuzza. Recurrent vision transformers for object detection with event cameras. In Computer Vision and Pattern Recognition (CVPR), 2023. 3, 13
work page 2023
-
[9]
Combining recurrent, con- volutional, and continuous-time models with linear state- space layers
Albert Gu, Isys Johnson, Karan Goel, Khaled Saab, Tri Dao, Atri Rudra, and Christopher R ´e. Combining recurrent, con- volutional, and continuous-time models with linear state- space layers. InAdvances in Neural Information Processing Systems (NeurIPS), 2021. 2
work page 2021
-
[10]
Efficiently mod- eling long sequences with structured state spaces
Albert Gu, Karan Goel, and Christopher Re. Efficiently mod- eling long sequences with structured state spaces. InInter- national Conference on Learning Representations (ICLR),
-
[11]
Backprop kf: learning discriminative deterministic state estimators
Tuomas Haarnoja, Anurag Ajay, Sergey Levine, and Pieter Abbeel. Backprop kf: learning discriminative deterministic state estimators. InAdvances in Neural Information Process- ing Systems (NeurIPS), 2016. 5
work page 2016
-
[12]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InComputer Vision and Pattern Recognition (CVPR), 2016. 4
work page 2016
-
[13]
Catalin Ionescu, Dragos Papava, Vlad Olaru, and Cristian Sminchisescu. Human3.6m: Large scale datasets and pre- dictive methods for 3d human sensing in natural environ- ments.Pattern Analysis and Machine Intelligence (PAMI), 36(7):1325–39, 2014. 6
work page 2014
-
[14]
Egocentric Pose Es- timation from Human Vision Span
Hao Jiang and Vamsi Krishna Ithapu. Egocentric Pose Es- timation from Human Vision Span. InInternational Confer- ence on Computer Vision (ICCV), 2021. 1, 2
work page 2021
-
[15]
Rudolph E. Kalman. A new approach to linear filtering and prediction problems.J. Fluids Eng., 82(1):35–45, 1960. 5
work page 1960
-
[16]
Attention-propagation net- work for egocentric heatmap to 3d pose lifting
Taeho Kang and Youngki Lee. Attention-propagation net- work for egocentric heatmap to 3d pose lifting. InConfer- ence on Computer Vision and Pattern Recognition (CVPR),
-
[17]
Ego3dpose: Capturing 3d cues from binocular egocentric views
Taeho Kang, Kyungjin Lee, Jinrui Zhang, and Youngki Lee. Ego3dpose: Capturing 3d cues from binocular egocentric views. InSIGGRAPH Asia Conference Papers, 2023. 1, 2
work page 2023
-
[18]
David G. Kendall. A survey of the statistical theory of shape. Statistical Science, 4(2):87–99, 1989. 7
work page 1989
-
[19]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InInternational Conference on Learning Representations (ICLR), 2015. 7
work page 2015
-
[20]
How to train your differentiable filter.Autonomous Robots, 45(4): 561–578, 2021
Alina Kloss, Georg Martius, and Jeannette Bohg. How to train your differentiable filter.Autonomous Robots, 45(4): 561–578, 2021. 5
work page 2021
-
[21]
Event-guided fusion- mamba for context-aware 3d human pose estimation
Bo Lang and Mooi Choo Chuah. Event-guided fusion- mamba for context-aware 3d human pose estimation. InPro- ceedings of the Winter Conference on Applications of Com- puter Vision (WACV), pages 950–960, 2025. 3
work page 2025
-
[22]
Aviles- Rivero, Chaokang Jiang, Zhe Liu, and Hesheng Wang
Jiuming Liu, Jinru Han, Lihao Liu, Angelica I. Aviles- Rivero, Chaokang Jiang, Zhe Liu, and Hesheng Wang. Mamba4d: Efficient 4d point cloud video understanding with disentangled spatial-temporal state space models. InConfer- ence on Computer Vision and Pattern Recognition (CVPR),
-
[23]
Egofish3d: Egocentric 3d pose es- timation from a fisheye camera via self-supervised learning
Yuxuan Liu, Jianxin Yang, Xiao Gu, Yijun Chen, Yao Guo, and Guang-Zhong Yang. Egofish3d: Egocentric 3d pose es- timation from a fisheye camera via self-supervised learning. IEEE Transactions on Multimedia (TMM), 2023. 1, 2
work page 2023
-
[24]
Dynamics-regulated kinematic policy for egocentric pose es- timation
Zhengyi Luo, Ryo Hachiuma, Ye Yuan, and Kris Kitani. Dynamics-regulated kinematic policy for egocentric pose es- timation. InAdvances in Neural Information Processing Sys- tems (NeurIPS), 2021. 1, 2
work page 2021
-
[25]
Even- tego3d: 3d human motion capture from egocentric event streams
Christen Millerdurai, Hiroyasu Akada, Jian Wang, Diogo Luvizon, Christian Theobalt, and Vladislav Golyanik. Even- tego3d: 3d human motion capture from egocentric event streams. InComputer Vision and Pattern Recognition (CVPR), 2024. 1, 2, 3, 6, 7, 11, 12, 14, 16, 17, 19, 20
work page 2024
-
[26]
Christen Millerdurai, Hiroyasu Akada, Jian Wang, Diogo Luvizon, Alain Pagani, Didier Stricker, Christian Theobalt, and Vladislav Golyanik. Eventego3d++: 3d human motion capture from a head-mounted event camera.International Journal of Computer Vision (IJCV), 2025. 1, 2, 3, 6, 7, 8, 11, 12, 14, 16, 17, 19, 20 9
work page 2025
-
[27]
Domain-guided spatio- temporal self-attention for egocentric 3d pose estimation
Jinman Park, Kimathi Kaai, Saad Hossain, Norikatsu Sumi, Sirisha Rambhatla, and Paul Fieguth. Domain-guided spatio- temporal self-attention for egocentric 3d pose estimation. InConference on Knowledge Discovery and Data Mining (KDD), 2023. 1, 2
work page 2023
-
[28]
Py- torch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zem- ing Lin, Natalia Gimelshein, Luca Antiga, Alban Desmai- son, Andreas Kopf, Edward Yang, Zachary DeVito, Mar- tin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Py- torch: An imperative style, hi...
work page 2019
-
[29]
Helge Rhodin, Christian Richardt, Dan Casas, Eldar Insafut- dinov, Mohammad Shafiei, Hans-Peter Seidel, Bernt Schiele, and Christian Theobalt. Egocap: egocentric marker-less mo- tion capture with two fisheye cameras.ACM Transactions on Graphics (TOG), 2016. 1, 2
work page 2016
-
[30]
Pre-mamba: A 4d state space model for ultra-high-frequent event camera deraining
Ciyu Ruan, Ruishan Guo, Zihang Gong, Jingao Xu, Wenhan Yang, and Xinlei Chen. Pre-mamba: A 4d state space model for ultra-high-frequent event camera deraining. InInterna- tional Conference on Computer Vision (ICCV), 2025. 3
work page 2025
-
[31]
Eventhands: Real-time neural 3d hand pose esti- mation from an event stream
Viktor Rudnev, Vladislav Golyanik, Jiayi Wang, Hans-Peter Seidel, Franziska Mueller, Mohamed Elgharib, and Christian Theobalt. Eventhands: Real-time neural 3d hand pose esti- mation from an event stream. InInternational Conference on Computer Vision (ICCV), 2021. 2, 3, 11, 13
work page 2021
-
[32]
Davide Scaramuzza. Omnidirectional camera. InComputer vision: A reference guide, pages 900–909. Springer, 2021. 6
work page 2021
-
[33]
Soshi Shimada, Vladislav Golyanik, Weipeng Xu, and Chris- tian Theobalt. Physcap: Physically plausible monocular 3d motion capture in real time.Transactions on Graphics (TOG), 2020. 7
work page 2020
-
[34]
Smith, Andrew Warrington, and Scott Linder- man
Jimmy T.H. Smith, Andrew Warrington, and Scott Linder- man. Simplified state space layers for sequence modeling. InInternational Conference on Learning Representations (ICLR), 2023. 3
work page 2023
-
[35]
xR-EgoPose: Egocentric 3D Human Pose From an HMD Camera
Denis Tome, Patrick Peluse, Lourdes Agapito, and Hernan Badino. xR-EgoPose: Egocentric 3D Human Pose From an HMD Camera. InInternational Conference on Computer Vision (ICCV), 2019. 1, 2
work page 2019
-
[36]
Denis Tome, Thiemo Alldieck, Patrick Peluse, Gerard Pons- Moll, Lourdes Agapito, Hernan Badino, and Fernando de la Torre. Selfpose: 3d egocentric pose estimation from a head- set mounted camera.Pattern Analysis and Machine Intelli- gence (PAMI), 45(6):6794 – 6806, 2023. 1, 2
work page 2023
-
[37]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems (NeurIPS), 2017. 5
work page 2017
-
[38]
Estimating egocentric 3d human pose in global space
Jian Wang, Lingjie Liu, Weipeng Xu, Kripasindhu Sarkar, and Christian Theobalt. Estimating egocentric 3d human pose in global space. InInternational Conference on Com- puter Vision (ICCV), 2021. 1, 2
work page 2021
-
[39]
Jian Wang, Lingjie Liu, Weipeng Xu, Kripasindhu Sarkar, Diogo Luvizon, and Christian Theobalt. Estimating egocen- tric 3d human pose in the wild with external weak supervi- sion.Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2022. 2
work page 2022
-
[40]
Egocentric whole-body motion capture with fisheyevit and diffusion-based motion refinement
Jian Wang, Zhe Cao, Diogo Luvizon, Lingjie Liu, Kri- pasindhu Sarkar, Danhang Tang, Thabo Beeler, and Chris- tian Theobalt. Egocentric whole-body motion capture with fisheyevit and diffusion-based motion refinement. InConfer- ence on Computer Vision and Pattern Recognition (CVPR),
-
[41]
Continuous-time human motion field from event cameras
Ziyun Wang, Ruijun Zhang, Zi-Yan Liu, Yufu Wang, and Kostas Daniilidis. Continuous-time human motion field from event cameras. InInternational Conference on Computer Vision (ICCV), 2025. 1
work page 2025
-
[42]
Ximea MU050CR-SY.https : / / www . ximea . com / products / miniature - compact / ximu - smallest - industrial - usb - cameras / sony - imx675- usb3- color- ximu- smallest- camera,
-
[43]
Eventcap: Monoc- ular 3d capture of high-speed human motions using an event camera
Lan Xu, Weipeng Xu, Vladislav Golyanik, Marc Haber- mann, Lu Fang, and Christian Theobalt. Eventcap: Monoc- ular 3d capture of high-speed human motions using an event camera. InComputer Vision and Pattern Recognition (CVPR), 2020. 2
work page 2020
-
[44]
Egopose- former: A simple baseline for stereo egocentric 3d human pose estimation
Chenhongyi Yang, Anastasia Tkach, Shreyas Hampali, Lin- guang Zhang, Elliot J Crowley, and Cem Keskin. Egopose- former: A simple baseline for stereo egocentric 3d human pose estimation. InEuropean Conference on Computer Vi- sion (ECCV), 2024. 1, 4, 5, 6, 7, 12, 16, 17, 19, 20
work page 2024
-
[45]
Ego-pose estimation and forecast- ing as real-time pd control
Ye Yuan and Kris Kitani. Ego-pose estimation and forecast- ing as real-time pd control. InInternational Conference on Computer Vision (ICCV), 2019. 1, 2
work page 2019
-
[46]
Distribution-aware coordinate representation for human pose estimation
Feng Zhang, Xiatian Zhu, Hanbin Dai, Mao Ye, and Ce Zhu. Distribution-aware coordinate representation for human pose estimation. InComputer Vision and Pattern Recognition (CVPR), 2020. 2
work page 2020
-
[47]
EgoGlass: Egocentric-View Human Pose Estima- tion From an Eyeglass Frame
Dongxu Zhao, Zhen Wei, Jisan Mahmud, and Jan-Michael Frahm. EgoGlass: Egocentric-View Human Pose Estima- tion From an Eyeglass Frame. InInternational Conference on 3D Vision (3DV), 2021. 1, 2
work page 2021
-
[48]
Deformable detr: Deformable transformers for end-to-end object detection
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable transformers for end-to-end object detection. InInternational Conference on Learning Representations (ICLR), 2021. 4
work page 2021
-
[49]
Even- thpe: Event-based 3d human pose and shape estimation
Shihao Zou, Chuan Guo, Xinxin Zuo, Sen Wang, Hu Xiao- qin, Shoushun Chen, Minglun Gong, and Li Cheng. Even- thpe: Event-based 3d human pose and shape estimation. In International Conference on Computer Vision (ICCV), 2021. 3
work page 2021
-
[50]
State space models for event cameras
Nikola Zubic, Mathias Gehrig, and Davide Scaramuzza. State space models for event cameras. InConference on Computer Vision and Pattern Recognition (CVPR), 2024. 2, 3, 4, 7 10 E-3DPSM: A State Machine for Event-Based Egocentric 3D Human Pose Estimation Supplementary Material Table of Contents: •Appendix A: Dataset Preprocessing •Appendix B: Pose Drift unde...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.