Systematic API Testing Through Model Checking and Executable Contracts
Pith reviewed 2026-05-10 17:04 UTC · model grok-4.3
The pith
Model checking of formal API models generates test sequences with complete state coverage and detects interaction faults.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By modeling API state evolution in TLA+ and exhaustively exploring the reachable states with the TLC model checker using coverage-guided breadth-first traversal, IcePick generates test sequences that provably cover the entire behavioural model. The Glacier language then enriches the specifications with first-order logic contracts that are executable for automated verification of behavior during test runs. Evaluation demonstrates that this achieves complete state coverage on benchmark systems and reveals faults specifically in multi-operation interactions, while also identifying scalability boundaries for the technique.
What carries the argument
Coverage-guided breadth-first traversal of the TLC state-space graph derived from a TLA+ model of the API, combined with executable first-order logic contracts for behavioral verification.
If this is right
- Reproducible test suites with provable coverage guarantees for critical API systems.
- Faults in interactions between multiple operations are detected that black-box testing often misses.
- Scalability limits and applicability requirements for the approach are characterized through evaluation.
- Automated verification of semantic properties beyond HTTP status codes becomes possible.
Where Pith is reading between the lines
- The method could reduce the reliance on random or heuristic test generation in practice.
- Writing the initial TLA+ model by hand represents a potential bottleneck that future work might address with model inference techniques.
- Similar principles might apply to testing stateful components in other software domains, such as microservices or database APIs.
Load-bearing premise
An accurate and sufficiently compact TLA+ model of the target API can be written by hand without the traversal missing critical states.
What would settle it
Observing that the generated test sequences fail to visit a state that the TLA+ model indicates is reachable, or that a known fault in operation interactions goes undetected in the benchmark evaluations.
Figures

read the original abstract
Automated black-box testing of APIs typically relies on interface specifications that define available operations and data schemas, but offer limited or no behavioural semantics. This semantic gap amplifies the test-oracle problem and limits the generation of effective, stateful call sequences. We introduce IcePick, a framework that achieves systematic state-space coverage for API testing by leveraging model checking. IcePick uses TLA+ to formally model API state evolution, employs the TLC model checker to exhaustively explore reachable states, and generates test sequences that provably cover the behavioural model. To mitigate state-space explosion and improve sequence extraction, we introduce a coverage-guided breadth-first traversal of the TLC state-space graph. To address oracle limitations beyond HTTP status codes, we propose Glacier, a first-order logic contract language that enriches API specifications with executable semantic contracts, enabling automated behavioural verification during test execution. We evaluate IcePick on EvoMaster Benchmark systems, demonstrating that model-checking-guided exploration achieves complete state coverage and reveals faults in multi-operation interactions. We also analyse scalability to characterise practical limits and applicability requirements. Overall, IcePick provides reproducible test suites with strong coverage guarantees for critical API-based systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces IcePick, a framework that models API state evolution in TLA+, uses the TLC model checker for exhaustive exploration of reachable states, and extracts test sequences via coverage-guided breadth-first traversal to achieve complete state-space coverage. It also proposes Glacier, a first-order logic contract language for executable semantic contracts to improve oracles beyond HTTP status codes. Evaluation on EvoMaster benchmarks claims that the approach achieves complete state coverage and reveals faults in multi-operation interactions, with additional analysis of scalability and practical limits.
Significance. If the central claims hold, the work offers a valuable contribution to stateful API testing by providing formal coverage guarantees through model checking, which addresses limitations in black-box approaches. The reliance on established tools (TLA+ and TLC) rather than ad-hoc constructions is a strength, as is the introduction of Glacier for richer behavioral verification. This could be significant for critical systems where multi-operation faults are hard to detect.
major comments (2)
- [Evaluation] Evaluation section: The claims of complete state coverage and fault revelation are reported only with respect to the hand-written TLA+ models of the EvoMaster benchmarks. No validation (e.g., differential execution against the implementation, runtime invariant monitoring, or comparison to a reference) is described to confirm that the models neither omit reachable states nor introduce spurious transitions, so the results do not necessarily transfer to the concrete APIs.
- [Abstract] Abstract and Evaluation: No quantitative metrics, state-space sizes, error bars, or details on model construction effort are supplied to support the 'complete coverage' and 'reveals faults' claims, making it difficult to assess the practical strength of the results or the effectiveness of the coverage-guided traversal.
minor comments (2)
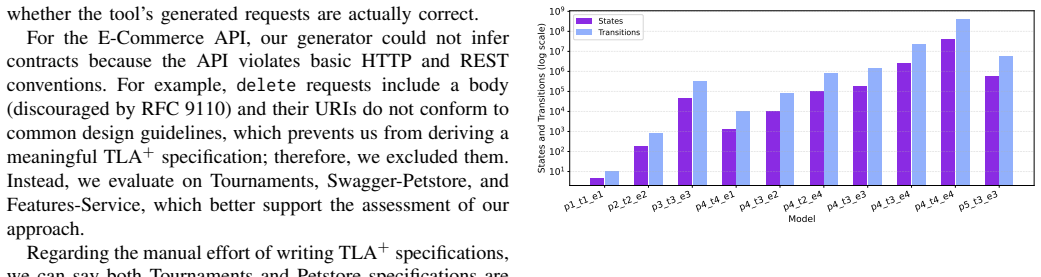
- The scalability analysis would benefit from explicit discussion of state-space sizes and when explosion occurs, to better characterise the applicability requirements.
- Clarify how Glacier contracts are executed during test runs and whether they require additional runtime instrumentation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope and presentation of our evaluation. We address each major comment below.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The claims of complete state coverage and fault revelation are reported only with respect to the hand-written TLA+ models of the EvoMaster benchmarks. No validation (e.g., differential execution against the implementation, runtime invariant monitoring, or comparison to a reference) is described to confirm that the models neither omit reachable states nor introduce spurious transitions, so the results do not necessarily transfer to the concrete APIs.
Authors: We agree that the reported complete state coverage and fault revelation results apply to the hand-written TLA+ models of the EvoMaster benchmarks rather than being directly validated against the concrete implementations. IcePick's primary contribution is the provision of formal coverage guarantees through exhaustive model checking on a behavioral specification; this is a deliberate design choice that distinguishes it from purely black-box approaches. Model fidelity is indeed a prerequisite for transferring results to real APIs, and we acknowledge that the current manuscript does not describe explicit validation steps such as differential execution or runtime invariant monitoring. In the revised manuscript we will add a new subsection in the Evaluation section that details the model construction process (drawing from benchmark documentation and API schemas), discusses potential discrepancies between model and implementation, and outlines practical validation techniques (e.g., runtime monitoring of extracted invariants during test execution on the live system). We will also note that, for safety-critical deployments, independent model validation remains advisable. revision: partial
-
Referee: [Abstract] Abstract and Evaluation: No quantitative metrics, state-space sizes, error bars, or details on model construction effort are supplied to support the 'complete coverage' and 'reveals faults' claims, making it difficult to assess the practical strength of the results or the effectiveness of the coverage-guided traversal.
Authors: We accept that additional quantitative detail would strengthen the presentation. Although the manuscript states that complete coverage is achieved and faults are revealed, we will expand the Evaluation section (and update the abstract accordingly) to include a summary table reporting, for each benchmark: the size of the reachable state space, the number of states explored by the coverage-guided traversal, model-checking runtime, test-sequence extraction time, approximate effort for constructing each TLA+ model (e.g., specification lines and person-hours), and the concrete multi-operation faults detected. Because TLC performs deterministic exhaustive exploration, statistical error bars are not applicable; we will explicitly state this deterministic character. These additions will allow readers to better judge scalability and the practical benefit of the coverage-guided breadth-first traversal. revision: yes
Circularity Check
No significant circularity; derivation relies on external model-checking tools
full rationale
The paper constructs TLA+ models by hand, applies the external TLC model checker for exhaustive exploration, and extracts test sequences that cover states of that model by construction. This is not circular because the coverage claim is explicitly limited to the hand-written behavioural model (an input assumption), the tools (TLA+, TLC) are independent established artifacts, and no equations, fitted parameters, or self-citations reduce the central result to a tautology. The method's soundness for the real API is a separate validation question, not a definitional loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption API behaviors can be faithfully captured by a TLA+ specification
invented entities (2)
-
IcePick framework
no independent evidence
-
Glacier contract language
no independent evidence
Reference graph
Works this paper leans on
-
[1]
E. M. Clarke, “Model checking,” inInternational conference on founda- tions of software technology and theoretical computer science. Springer, 1997, pp. 54–56
work page 1997
-
[2]
P. Godefroid and K. Sen,Combining Model Checking and Testing. Cham: Springer International Publishing, 2018
work page 2018
-
[3]
Using model checking to generate tests from specifications,
P. E. Ammann, P. E. Black, and W. Majurski, “Using model checking to generate tests from specifications,” inProceedings second international conference on formal engineering methods (Cat. No. 98EX241). IEEE, 1998, pp. 46–54
work page 1998
-
[4]
M. Fowler and J. Lewis, “Microservices,” http://martinfowler.com/artic les/microservices.html, 2014, accessed in January 2024
work page 2014
-
[5]
RESTful API automated test case generation with evomas- ter,
A. Arcuri, “RESTful API automated test case generation with evomas- ter,”ACM Trans. Softw. Eng. Methodol., vol. 28, no. 1, 2019
work page 2019
-
[6]
Swagger, “OpenAPI specification,” https://swagger.io/specification/, 2021, accessed in January 2024
work page 2021
-
[7]
Automated black- and white-box testing of RESTful APIs with EvoMaster,
A. Arcuri, “Automated black- and white-box testing of RESTful APIs with EvoMaster,”IEEE Software, vol. 38, no. 3, pp. 72–78, 2021
work page 2021
-
[8]
RESTTESTGEN: Auto- mated black-box testing of RESTful APIs,
E. Viglianisi, M. Dallago, and M. Ceccato, “RESTTESTGEN: Auto- mated black-box testing of RESTful APIs,” in2020 IEEE 13th Inter- national Conference on Software Testing, Validation and Verification (ICST), 2020, pp. 142–152
work page 2020
-
[9]
Morest: Model-based RESTful API testing with execution feedback,
Y . Liu, Y . Li, G. Deng, Y . Liu, R. Wan, R. Wu, D. Ji, S. Xu, and M. Bao, “Morest: Model-based RESTful API testing with execution feedback,” inProceedings of the 44th International Conference on Software Engineering, ser. ICSE ’22. Association for Computing Machinery, 2022, p. 1406–1417
work page 2022
-
[10]
RESTler: Stateful REST API fuzzing,
V . Atlidakis, P. Godefroid, and M. Polishchuk, “RESTler: Stateful REST API fuzzing,” in2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), 2019, pp. 748–758
work page 2019
-
[11]
Restest: automated black-box testing of RESTful web APIs,
A. Martin-Lopez, S. Segura, and A. Ruiz-Cortés, “Restest: automated black-box testing of RESTful web APIs,” inProceedings of the 30th ACM SIGSOFT International Symposium on Software Testing and Analysis, ser. ISSTA 2021. New York, NY , USA: Association for Computing Machinery, 2021, p. 682–685. [Online]. Available: https://doi.org/10.1145/3460319.3469082
-
[12]
Combinatorial testing of RESTful APIs,
H. Wu, L. Xu, X. Niu, and C. Nie, “Combinatorial testing of RESTful APIs,” inProceedings of the 44th International Conference on Software Engineering, ser. ICSE ’22. New York, NY , USA: Association for Computing Machinery, 2022, p. 426–437
work page 2022
-
[13]
AGORA: Automated generation of test oracles for REST APIs,
J. C. Alonso, S. Segura, and A. Ruiz-Cortés, “AGORA: Automated generation of test oracles for REST APIs,” inProceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis, ser. ISSTA 2023. New York, NY , USA: Association for Computing Machinery, 2023, p. 1018–1030
work page 2023
-
[14]
Automatic gener- ation of test cases for REST APIs: A specification-based approach,
H. Ed-douibi, J. L. Cánovas Izquierdo, and J. Cabot, “Automatic gener- ation of test cases for REST APIs: A specification-based approach,” in 2018 IEEE 22nd International Enterprise Distributed Object Computing Conference (EDOC), 2018, pp. 181–190
work page 2018
-
[15]
Metamorphic testing of RESTful Web APIs,
S. Segura, J. A. Parejo, J. Troya, and A. Ruiz-Cortés, “Metamorphic testing of RESTful Web APIs,” inProceedings of the 40th International Conference on Software Engineering, ser. ICSE ’18. New York, NY , USA: Association for Computing Machinery, 2018, p. 882
work page 2018
-
[16]
The oracle problem in software testing: A survey,
E. T. Barr, M. Harman, P. McMinn, M. Shahbaz, and S. Yoo, “The oracle problem in software testing: A survey,”IEEE Transactions on Software Engineering, vol. 41, no. 5, pp. 507–525, 2015
work page 2015
-
[17]
The temporal logic of actions,
L. Lamport, “The temporal logic of actions,”ACM Transactions on Programming Languages and Systems (TOPLAS), vol. 16, no. 3, pp. 872–923, 1994
work page 1994
-
[18]
——,Specifying Systems: The TLA+ Language and Tools for Hardware and Software Engineers. Addison-Wesley, June 2002. [Online]. Available: https://www.microsoft.com/en-us/research/publica tion/specifying-systems-the-tla-language-and-tools-for-hardware-and-s oftware-engineers/
work page 2002
-
[19]
Model checking TLA+ specifica- tions,
Y . Yu, P. Manolios, and L. Lamport, “Model checking TLA+ specifica- tions,” inAdvanced research working conference on correct hardware design and verification methods. Springer, 1999, pp. 54–66
work page 1999
-
[20]
TLA+ model checking made symbolic,
M. A. Kuppe, L. Lamport, and D. Ricketts, “TLA+ model checking made symbolic,” inProceedings of the ACM on Programming Lan- guages (OOPSLA), vol. 3, no. OOPSLA, 2019, pp. 123:1–123:30
work page 2019
-
[21]
Glacier generator & catalogue,
A. C. Ribeiro, “Glacier generator & catalogue,” https://github.com/acm -ribeiro/glacier-generator, 2025
work page 2025
-
[22]
A. Arcuri, M. Zhang, A. Golmohammadi, A. Belhadi, J. P. Galeotti, B. Marculescu, and S. Seran, “Emb: A curated corpus of web/enter- prise applications and library support for software testing research,” in 2023 IEEE Conference on Software Testing, Verification and Validation (ICST), 2023, pp. 433–442
work page 2023
-
[23]
Replication package for sys- tematic API testing through model checking and executable contracts,
A. Ribeiro, M. Mamede, and C. Ferreira, “Replication package for sys- tematic API testing through model checking and executable contracts,” https://doi.org/10.5281/zenodo.19404322, Dec. 2025
-
[24]
Invariant-driven automated testing,
A. C. Ribeiro, “Invariant-driven automated testing,” M.S. thesis, NOV A School of Science and Technology, February 2021
work page 2021
-
[25]
Verifying concurrent programs using contracts,
R. J. Dias, C. Ferreira, J. Fiedor, J. M. Lourenço, A. Smrcka, D. G. Sousa, and T. V ojnar, “Verifying concurrent programs using contracts,” in2017 IEEE International Conference on Software Testing, Verification and Validation (ICST), 2017, pp. 196–206
work page 2017
-
[26]
Towards contract-based testing of web services,
R. Heckel and M. Lohmann, “Towards contract-based testing of web services,”Electronic Notes in Theoretical Computer Science, vol. 116, pp. 145–156, 2005
work page 2005
-
[27]
Contract-based testing for web services,
G. Dai, X. Bai, Y . Wang, and F. Dai, “Contract-based testing for web services,” in31st Annual International Computer Software and Applications Conference (COMPSAC 2007), vol. 1, 2007, pp. 517–526
work page 2007
-
[28]
B. K. Aichernig,Contract-Based Testing. Berlin, Heidelberg: Springer Berlin Heidelberg, 2003, pp. 34–48. [Online]. Available: https://doi.org/10.1007/978-3-540-40007-3_3
-
[29]
Model checking guided testing for distributed systems,
D. Wang, W. Dou, Y . Gao, C. Wu, J. Wei, and T. Huang, “Model checking guided testing for distributed systems,” inProceedings of the Eighteenth European Conference on Computer Systems, ser. EuroSys ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 127–143. [Online]. Available: https://doi.org/10.1145/355232 6.3587442
-
[30]
T. H. Cormen, C. E. Leiserson, R. L. Rivest, and C. Stein,Introduction to algorithms. MIT press, 2022
work page 2022
-
[31]
Applying ’design by contract’,
B. Meyer, “Applying ’design by contract’,”Computer, vol. 25, no. 10, pp. 40–51, 1992
work page 1992
-
[32]
Swagger, “Petstore - openapi 3.0,” https://petstore3.swagger.io/, 2018, accessed in September 2025
work page 2018
-
[33]
WFC/WFD: Web fuzzing commons, dataset and guidelines to support experimentation in REST API fuzzing,
O. Sahin, M. Zhang, and A. Arcuri, “WFC/WFD: Web fuzzing commons, dataset and guidelines to support experimentation in REST API fuzzing,” 2025. [Online]. Available: https://arxiv.org/abs/2509.016 12
work page 2025
-
[34]
J. R. Roy T. Fielding, Mark Nottingham, “HTTP semantics (POST),” https://httpwg.org/specs/rfc9110.html#POST, RFC 9110, 6 2022, accessed in December 2025
work page 2022
-
[35]
Efficient bounded exhaustive input generation from program apis,
M. Politano, V . Bengolea, F. Molina, N. Aguirre, M. F. Frias, and P. Ponzio, “Efficient bounded exhaustive input generation from program apis,” inInternational Conference on Fundamental Approaches to Soft- ware Engineering. Springer, 2023, pp. 111–132
work page 2023
-
[36]
How Amazon Web Services uses formal methods,
C. Newcombe, T. Rath, F. Zhang, B. Munteanu, M. Brooker, and M. Deardeuff, “How Amazon Web Services uses formal methods,” Communications of the ACM, vol. 58, no. 4, pp. 66–73, 2015
work page 2015
-
[37]
Formal verification of a dis- tributed dynamic reconfiguration protocol,
W. Schultz, I. Dardik, and S. Tripakis, “Formal verification of a dis- tributed dynamic reconfiguration protocol,” inInternational Conference on Principles of Distributed Systems (OPODIS), 2019
work page 2019
-
[38]
JepREST: Functional tests for distributed REST applications,
S. Simoes, A. Ribeiro, C. Ferreira, and N. Preguica, “JepREST: Functional tests for distributed REST applications,” 2023. [Online]. Available: https://arxiv.org/abs/2303.14104
-
[39]
Model- guided fuzzing of distributed systems,
E. B. Gulcan, B. K. Ozkan, R. Majumdar, and S. Nagendra, “Model- guided fuzzing of distributed systems,”Proc. ACM Program. Lang., vol. 9, no. OOPSLA2, 2025
work page 2025
-
[40]
Adaptive REST API testing with rein- forcement learning,
M. Kim, S. Sinha, and A. Orso, “Adaptive REST API testing with rein- forcement learning,” in2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2023, pp. 446–458
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.