An Eye for Trust: An Exploration of Developers' Trust Perceptions Through Urgency and Reputation
Pith reviewed 2026-05-10 16:58 UTC · model grok-4.3
The pith
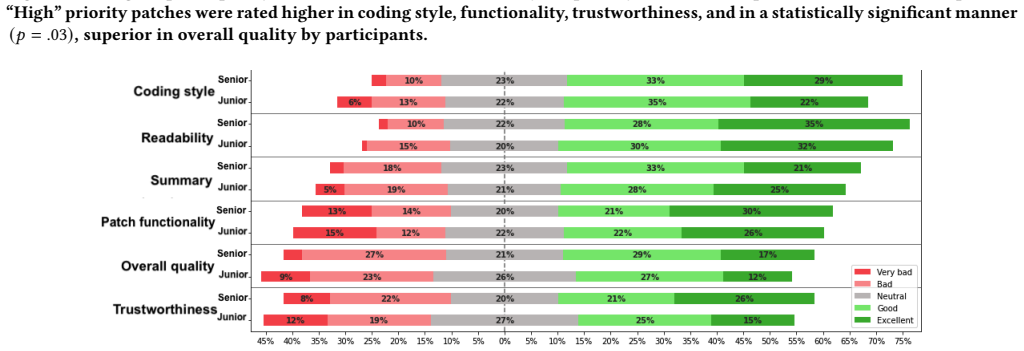
Priority labels alter developers' code review time, effort, and quality ratings while leaving their adoption decisions unchanged.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The priority assigned to a code patch significantly influenced developers' code review behavior, impacting their evaluation time, cognitive load, and perceived quality. However, the decision to incorporate and implement the code was not affected. Eye tracking data revealed variations in overall visual code scanning and the distribution of attention across identical code patches labeled as written by senior versus junior developers, yet there were no significant performance differences. Participants nominated code functionality, quality, and comprehensibility as primary factors in code evaluation.
What carries the argument
Controlled experiment presenting identical code patches under manipulated urgency (priority) and reputation (author experience) labels while recording eye movements to capture visual attention and decision processes.
If this is right
- Code review platforms could surface priority indicators to guide attention allocation without expecting changes in reuse rates.
- Reputation signals may influence how developers distribute visual attention even when they do not alter final adoption choices.
- Developers appear to under-recognize the effect of urgency and reputation on their own review processes.
- Presenting code with explicit priority cues could standardize review effort across patches without shifting reuse decisions.
Where Pith is reading between the lines
- Real-world reputation cues drawn from public profiles might produce stronger or different attention effects than the artificial labels used here.
- Eye-tracking methods could be applied to other reuse scenarios, such as library selection or generated code, to expose similar hidden influences on behavior.
- The separation between changed review processes and unchanged adoption decisions suggests trust operates at multiple distinct stages that platforms might address separately.
Load-bearing premise
The experimental labels for urgency and reputation were perceived by participants as intended and eye-tracking metrics captured trust-related cognitive processes rather than other factors such as curiosity or habit.
What would settle it
A replication study that applies the same priority and author-experience labels to identical patches but records no measurable difference in review duration, fixation patterns, or cognitive-load indicators would falsify the central claim.
Figures





read the original abstract
Code reuse is a widespread practice across software development projects, suggesting an inherent trust in the reused code. Yet, there is a lack of a fundamental understanding of developers' trust and how various factors mold their trust-based cognitive processes. Drawing from the psychology of compliance and trust, we present the results of the first controlled experiment (n=37) which uses eye tracking to explore how urgency (represented by code priority level) and reputation (represented by the experience level of the code's author) influence developers' perceptions of code trustworthiness. Our research revealed that the priority assigned to a code patch significantly influenced developers' code review behavior, impacting their evaluation time, cognitive load, and perceived quality. However, the decision to incorporate and implement the code was not affected . Eye tracking data revealed that there were variations in overall visual code scanning and the distribution of attention across identical code patches labeled as written by senior vs. junior developers. Yet, there were no significant performance differences. Moreover, our participants nominate code functionality, quality, and comprehensibility as primary factors in code evaluation. Despite noticeable changes in code review behavior, our participants surprisingly overlooked the substantial influence of urgency and reputation on their decisions to review and reuse code changes. This study takes the next step toward a better understanding of trust in software engineering and may inform future research about code review platforms and guidelines, code reuse, and automated code generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports results from a controlled experiment (n=37) that uses eye-tracking to examine how urgency (operationalized via code priority labels) and reputation (operationalized via author experience levels) shape developers' trust perceptions, code review behavior, cognitive load, perceived quality, and reuse decisions. Key findings are that priority labels significantly affected review time, cognitive load, and quality perceptions but not the decision to incorporate the code; eye-tracking showed differences in visual scanning and attention distribution for senior- vs. junior-author patches with no performance differences; and participants self-nominated functionality, quality, and comprehensibility as primary evaluation factors while appearing to overlook the role of urgency and reputation.
Significance. If the manipulations are shown to have operated as intended, the study offers a novel contribution by providing direct behavioral and physiological measures of trust-related processes in code review, an area where prior work has relied primarily on self-report. The dissociation between effects on review processes and reuse decisions, together with the eye-tracking attention data, could inform the design of code review platforms and guidelines for code reuse and automated generation. The self-nominated factors also add empirical grounding to discussions of developer decision-making.
major comments (3)
- [Methods] Methods: No post-experiment manipulation check is reported to confirm that participants perceived the high- vs. low-priority labels as conveying urgency and the senior- vs. junior-author labels as conveying reputation. This is load-bearing for the central claim that these factors influenced trust perceptions and thereby drove the observed changes in evaluation time, cognitive load, and perceived quality; without it, alternative explanations such as demand characteristics or label inattention cannot be ruled out.
- [Results] Results: With n=37 and no reported power analysis or effect sizes, the null findings on reuse/incorporation decisions and on performance differences are difficult to interpret. The absence of these statistics weakens the claim that urgency and reputation do not affect reuse behavior, as the study may simply be underpowered to detect such effects.
- [Discussion] Discussion: The interpretation that eye-tracking metrics (overall visual scanning and attention distribution) specifically index trust-related cognitive processes rather than other factors (e.g., curiosity, habit, or visual salience of labels) is asserted without additional validation or convergent measures. This assumption underpins the linkage between the eye-tracking data and trust perceptions.
minor comments (3)
- [Abstract] Abstract: The phrasing 'our participants surprisingly overlooked the substantial influence' introduces an interpretive tone that is not supported by direct evidence; a more neutral description of the self-report data would be clearer.
- [Results] Results: The statement 'there were no significant performance differences' is ambiguous—what performance metric is being referenced (e.g., correctness of review, time to decision, or something else)? Clarification would improve readability.
- The manuscript would benefit from reporting exact statistical values (F, t, p, and effect sizes) for all reported significant and null effects rather than qualitative summaries.
Simulated Author's Rebuttal
We thank the referee for their detailed and insightful comments on our manuscript. We address each of the major comments point by point below, indicating where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: [Methods] Methods: No post-experiment manipulation check is reported to confirm that participants perceived the high- vs. low-priority labels as conveying urgency and the senior- vs. junior-author labels as conveying reputation. This is load-bearing for the central claim that these factors influenced trust perceptions and thereby drove the observed changes in evaluation time, cognitive load, and perceived quality; without it, alternative explanations such as demand characteristics or label inattention cannot be ruled out.
Authors: We agree that including a post-experiment manipulation check would have provided valuable confirmation that the priority and author labels were interpreted by participants as conveying urgency and reputation, respectively, and that these influenced trust perceptions. Since this check was not part of the original study protocol, we cannot add the data retroactively. In the revised manuscript, we will add a dedicated limitations section discussing this issue, acknowledge the possibility of alternative explanations like demand characteristics or inattention to labels, and recommend that future studies include such checks to bolster causal inferences about trust. revision: partial
-
Referee: [Results] Results: With n=37 and no reported power analysis or effect sizes, the null findings on reuse/incorporation decisions and on performance differences are difficult to interpret. The absence of these statistics weakens the claim that urgency and reputation do not affect reuse behavior, as the study may simply be underpowered to detect such effects.
Authors: We acknowledge the importance of power analysis and effect sizes for interpreting null results. In the revised version, we will report effect sizes (such as partial eta-squared for ANOVA results and Cohen's d where appropriate) for all statistical tests, including those showing null effects on reuse decisions and performance metrics. Additionally, we will include a post-hoc power analysis based on the observed data to help readers evaluate the study's sensitivity to detect effects on reuse behavior. While we observed significant effects on review time, cognitive load, and perceived quality, we will revise the text to be more cautious in claiming that urgency and reputation do not affect reuse. revision: yes
-
Referee: [Discussion] Discussion: The interpretation that eye-tracking metrics (overall visual scanning and attention distribution) specifically index trust-related cognitive processes rather than other factors (e.g., curiosity, habit, or visual salience of labels) is asserted without additional validation or convergent measures. This assumption underpins the linkage between the eye-tracking data and trust perceptions.
Authors: The linkage between eye-tracking metrics and trust processes is grounded in prior psychological research on visual attention during decision-making and trust evaluation. However, we recognize that without additional convergent measures (e.g., explicit trust ratings correlated with eye data), other factors like curiosity about the labels or habitual scanning patterns could contribute. In the revision, we will revise the discussion to present the trust-related interpretation more tentatively, explicitly discuss alternative explanations such as visual salience of the labels and habit, and integrate the participants' self-nominated evaluation factors (functionality, quality, comprehensibility) to provide a more balanced view of the cognitive processes involved. revision: partial
Circularity Check
No circularity: purely empirical experiment with no derivations or self-referential predictions
full rationale
The paper reports results from a controlled experiment (n=37) using eye-tracking to measure effects of urgency and reputation labels on code review behavior. No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations appear in the provided text or abstract. Claims rest on direct observational outcomes (review time, cognitive load via eye-tracking, perceived quality) rather than any chain that reduces to its own definitions or prior author work by construction. This is self-contained empirical work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Eye tracking metrics (fixations, scan paths) validly reflect cognitive load and attention allocation during code review tasks
- domain assumption Participants perceive and respond to the provided urgency and reputation labels as intended in the experimental materials
Reference graph
Works this paper leans on
-
[1]
Gene M Alarcon, Rose Gamble, Sarah A Jessup, Charles Walter, Tyler J Ryan, David W Wood, and Chris S Calhoun. 2017. Application of the heuristic- systematic model to computer code trustworthiness: The influence of reputation and transparency.Cogent Psychology4, 1 (2017), 1389640
work page 2017
-
[2]
Gene M. Alarcon, Anthony M. Gibson, Charles Walter, Rose F. Gamble, Tyler J. Ryan, Sarah A. Jessup, Brian E. Boyd, and August Capiola. 2020. Trust Perceptions of Metadata in Open-Source Software: The Role of Performance and Reputation. Systems8, 3 (2020). https://doi.org/10.3390/systems8030028
-
[3]
Gene M. Alarcon and Tyler J. Ryan. 2018. Trustworthiness Perceptions of Com- puter Code: A Heuristic-Systematic Processing Model. InProceedings of the 51st Hawaii International Conference on System Sciences
work page 2018
-
[4]
Alarcon, Charles Walter, Anthony M
Gene M. Alarcon, Charles Walter, Anthony M. Gibson, Rose F. Gamble, August Capiola, Sarah A. Jessup, and Tyler J. Ryan. 2020. Would You Fix This Code for Me? Effects of Repair Source and Commenting on Trust in Code Repair.Systems 8, 1 (2020). https://doi.org/10.3390/systems8010008
-
[5]
Apostolos Ampatzoglou, Antonios Gkortzis, Sofia Charalampidou, and Paris Avgeriou. 2013. An Embedded Multiple-Case Study on OSS Design Quality Assessment across Domains. In2013 ACM / IEEE International Symposium on Empirical Software Engineering and Measurement. 255–258. https://doi.org/10. 1109/ESEM.2013.48
work page 2013
- [6]
-
[7]
Andrew Begel and Hana Vrzakova. 2018. Eye Movements in Code Review. In Proceedings of the Workshop on Eye Movements in Programming. Article 5, 5 pages. https://doi.org/10.1145/3216723.3216727
-
[8]
Ian Bertram, Jack Hong, Yu Huang, Westley Weimer, and Zohreh Sharafi
-
[9]
Trustworthiness Perceptions in Code Review: An Eye-Tracking Study. InProceedings of the 14th ACM / IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM)(Bari, Italy)(ESEM ’20). Asso- ciation for Computing Machinery, New York, NY, USA, Article 31, 6 pages. https://doi.org/10.1145/3382494.3422164
-
[10]
Martha E. Crosby and Jan Stelovsky. 1990. How Do We Read Algorithms? A Case Study.Computer23, 1 (Jan. 1990), 24–35
work page 1990
-
[11]
Zakir Durumeric, Frank Li, James Kasten, Johanna Amann, Jethro Beekman, Mathias Payer, Nicolas Weaver, David Adrian, Vern Paxson, Michael Bailey, and J. Alex Halderman. 2014. The Matter of Heartbleed. InProceedings of the 2014 Conference on Internet Measurement Conference(Vancouver, BC, Canada) (IMC ’14). Association for Computing Machinery, New York, NY,...
-
[12]
Anneli Eteläpelto. 1993. Metacognition and the expertise of computer program comprehension.Scandinavian Journal of Educational Research37, 3 (1993), 243– 254
work page 1993
-
[13]
Quyin Fan. 2010.The Effects of Beacons, Comments, and Tasks on Program Com- prehension Process in Software Maintenance. Ph. D. Dissertation. University of Maryland, Baltimore County, Catonsville, MD, USA. Advisor(s) Norcio, Anthony F. AAI3422807
work page 2010
-
[14]
Denae Ford, Mahnaz Behroozi, Alexander Serebrenik, and Chris Parnin. 2019. Beyond the code itself: how programmers really look at pull requests. InInterna- tional Conference on Software Engineering: Software Engineering in Society
work page 2019
-
[15]
In: Proceedings of the 2012 International Symposium on Software Testing and Analysis
Zachary P. Fry, Bryan Landau, and Westley Weimer. 2012. A human study of patch maintainability. InInternational Symposium on Software Testing and Analysis, ISSTA 2012, Minneapolis, MN, USA, July 15-20, 2012, Mats Per Erik Heimdahl and Zhendong Su (Eds.). ACM, 177–187. https://doi.org/10.1145/2338965.2336775
-
[16]
Claudia Geitner, Ben D Sawyer, S Birrell, P Jennings, L Skyrypchuk, Bruce Mehler, and Bryan Reimer. 2017. A link between trust in technology and glance allocation in on-road driving. (2017)
work page 2017
-
[17]
Christian Gold, Moritz Körber, Christoph Hohenberger, David Lechner, and Klaus Bengler. 2015. Trust in automation–Before and after the experience of take-over scenarios in a highly automated vehicle.Procedia Manufacturing3 (2015), 3025–3032
work page 2015
-
[18]
Joseph H. Goldberg and Jonathan I. Helfman. 2010. Comparing Information Graphics: A Critical Look at Eye Tracking. InProceedings of the 3rd BEyond Time and Errors: Novel evaLuation Methods for Information Visualization Workshop (Atlanta, Georgia)(BELIV ’10). ACM, New York, NY, USA, 71–78. https://doi. org/10.1145/2110192.2110203
-
[19]
Claire Goues, Stephanie Forrest, and Westley Weimer. 2013. Current Challenges in Automatic Software Repair.Software Quality Journal21, 3 (Sept. 2013), 421–443. https://doi.org/10.1007/s11219-013-9208-0
-
[20]
Stefan Haefliger, Georg Von Krogh, and Sebastian Spaeth. 2008. Code reuse in open source software.Management science54, 1 (2008), 180–193
work page 2008
-
[21]
Israel Herraiz, Daniel M. German, Jesus M. Gonzalez-Barahona, and Gregorio Robles. 2008. Towards a Simplification of the Bug Report Form in Eclipse. In Proceedings of the 2008 International Working Conference on Mining Software Repositories(Leipzig, Germany)(MSR ’08). Association for Computing Machinery, New York, NY, USA, 145–148. https://doi.org/10.1145...
-
[22]
https://www.tobiipro.com/. 2001. Online; Accessed 17-07-2020
work page 2001
-
[23]
Yu Huang, Kevin Leach, Zohreh Sharafi, Nicholas McKay, Tyler Santander, and Westley Weimer. 2020. Biases and Differences in Code Review Using Medical Imaging and Eye-Tracking: Genders, Humans, and Machines. InInternational Symposium on the Foundations of Software Engineering(Virtual Event, USA) (ESEC/FSE 2020). Association for Computing Machinery, New Yor...
-
[24]
Yu Huang, Xinyu Liu, Ryan Krueger, Tyler Santander, Xiaosu Hu, Kevin Leach, and Westley Weimer. 2019. Distilling Neural Representations of Data Structure Manipulation Using FMRI and FNIRS. InProceedings of the 41st International Conference on Software Engineering (ICSE ’19). IEEE Press, Montreal, Quebec, Canada, 396–407. https://doi.org/10.1109/ICSE.2019.00053
-
[25]
Marcel A Just and Patricia A Carpenter. 1980. A theory of reading: from eye fixations to comprehension.Psychological review87, 4 (1980), 329
work page 1980
-
[26]
Dongsun Kim, Jaechang Nam, Jaewoo Song, and Sunghun Kim. 2013. Automatic patch generation learned from human-written patches. In2013 35th International Conference on Software Engineering (ICSE). IEEE, 802–811
work page 2013
-
[27]
Kitchenham, Shari Lawrence Pfleeger, Lesley M
Barbara A. Kitchenham, Shari Lawrence Pfleeger, Lesley M. Pickard, Peter W. Jones, David C. Hoaglin, Khaled El Emam, and Jarrett Rosenberg. 2002. Pre- liminary Guidelines for Empirical Research in Software Engineering.IEEE Transactions on Software Engineering28, 8 (Aug. 2002), 721–734. https://doi.org/ 10.1109/TSE.2002.1027796
-
[28]
Oleksii Kononenko, Olga Baysal, Latifa Guerrouj, Yaxin Cao, and Michael W. Godfrey. 2015. Investigating code review quality: Do people and participation matter?. In2015 IEEE International Conference on Software Maintenance and Evolution (ICSME). 111–120. https://doi.org/10.1109/ICSM.2015.7332457
-
[29]
John D Lee and Katrina A See. 2004. Trust in automation: Designing for appro- priate reliance.Human factors46, 1 (2004), 50–80
work page 2004
-
[30]
Y. Lu and N. Sarter. 2019. Eye Tracking: A Process-Oriented Method for Inferring Trust in Automation as a Function of Priming and System Reliability.IEEE Transactions on Human-Machine Systems49, 6 (Dec 2019), 560–568. https: //doi.org/10.1109/THMS.2019.2930980
-
[31]
Joseph B Lyons, Nhut T Ho, William E Fergueson, Garrett G Sadler, Samantha D Cals, Casey E Richardson, and Mark A Wilkins. 2016. Trust of an automatic ground collision avoidance technology: A fighter pilot perspective.Military Psychology28, 4 (2016), 271–277
work page 2016
-
[32]
A. Marginean, J. Bader, S. Chandra, M. Harman, Y. Jia, K. Mao, A. Mols, and A. Scott. 2019. SapFix: Automated End-to-End Repair at Scale. InInternational Conference on Software Engineering: Software Engineering in Practice. 269–278
work page 2019
-
[33]
Matias Martinez, Thomas Durieux, Romain Sommerard, Jifeng Xuan, and Martin Monperrus. 2016. Automatic Repair of Real Bugs in Java: A Large-Scale Experi- ment on the Defects4J Dataset.Springer Empirical Software Engineering(2016). https://doi.org/10.1007/s10664-016-9470-4
-
[34]
Stephanie Merritt, Lei Shirase, and Garett Foster. 2020. Normed Images for X-ray Screening Vigilance Tasks.Journal of Open Psychology Data8, 1 (2020)
work page 2020
-
[35]
Audris Mockus. 2007. Large-Scale Code Reuse in Open Source Software. InFirst International Workshop on Emerging Trends in FLOSS Research and Development (FLOSS’07: ICSE Workshops 2007). 7–7. https://doi.org/10.1109/FLOSS.2007.10
-
[36]
Martin Monperrus. 2018. Automatic Software Repair: A Bibliography.ACM Comput. Surv.51, 1, Article 17 (Jan. 2018), 24 pages. https://doi.org/10.1145/ 3105906
work page 2018
-
[37]
Martin Monperrus, Simon Urli, Thomas Durieux, Matias Martinez, Benoit Baudry, and Lionel Seinturier. 2019. Repairnator Patches Programs Automatically.Ubiq- uity2019, July, Article 2 (July 2019), 12 pages. https://doi.org/10.1145/3349589
-
[38]
Rennie Naidoo. 2015. Analysing urgency and trust cues exploited in phishing scam designs. In10th International Conference on Cyber Warfare and Security. 216
work page 2015
-
[39]
Yannic Noller, Ridwan Shariffdeen, Xiang Gao, and Abhik Roychoudhury. 2022. Trust Enhancement Issues in Program Repair. InProceedings of the 44th Inter- national Conference on Software Engineering(Pittsburgh, Pennsylvania)(ICSE ’22). Association for Computing Machinery, New York, NY, USA, 2228–2240. https://doi.org/10.1145/3510003.3510040
-
[40]
Richard E Petty, John T Cacioppo, Richard E Petty, and John T Cacioppo. 1986. The elaboration likelihood model of persuasion. Springer
work page 1986
-
[41]
Alex Poole and Linden J. Ball. 2005. Eye Tracking in Human-Computer Interac- tion and Usability Research: Current Status and Future. InProspects”, Chapter in C. Ghaoui (Ed.): Encyclopedia of Human-Computer Interaction. Pennsylvania: Idea Group, Inc. Information Science Reference, Hershey, PA, 1–5
work page 2005
-
[42]
K. Rayner. 1978. Eye movements in reading and information processing.Psycho- logical Bulletin85, 3 (1978), 618–660
work page 1978
-
[43]
Paige Rodeghero. 2017. Behavior-Informed Algorithms for Automatic Documen- tation Generation. In2017 IEEE International Conference on Software Maintenance Conference’17, July 2017, Washington, DC, USA Yabesi, et al. and Evolution (ICSME). IEEE Computer Society, Los Alamitos, CA, USA, 660–664. https://doi.org/10.1109/ICSME.2017.73
-
[44]
Tyler J Ryan, Gene M Alarcon, Charles Walter, Rose Gamble, Sarah A Jessup, August Capiola, and Marc D Pfahler. 2019. Trust in automated software repair: The effects of repair source, transparency, and programmer experience on per- ceived trustworthiness and trust. InHCI for Cybersecurity, Privacy and Trust: First International Conference, HCI-CPT 2019, He...
work page 2019
-
[45]
Timothy R Shaffer, Jenna L Wise, Braden M Walters, Sebastian C Müller, Michael Falcone, and Bonita Sharif. 2015. itrace: Enabling eye tracking on software artifacts within the ide to support software engineering tasks. InProceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering. 954–957
work page 2015
-
[46]
Jenessa R Shapiro and Steven L Neuberg. 2007. From stereotype threat to stereo- type threats: Implications of a multi-threat framework for causes, moderators, mediators, consequences, and interventions.Personality and Social Psychology Review11, 2 (2007), 107–130
work page 2007
-
[47]
Zohreh Sharafi, Yu Huang, Kevin Leach, and Westley Weimer. 2020. Towards an objective measure of developers’ cognitive activities. InTransactions on Software Engineering and Methodology (TOSEM). ACM, to appear
work page 2020
-
[48]
Zohreh Sharafi, Timothy Shaffer, Bonita Sharif, and Yann-Gaël Guéhéneuc. 2015. Eye-tracking metrics in software engineering. InProceeding of 2015 Asia-Pacific Software Engineering Conference (APSEC). IEEE, 96–103
work page 2015
-
[49]
Zohreh Sharafi, Bonita Sharif, Yann-Gaël Guéhéneuc, Andrew Begel, Roman Bednarik, and Martha Crosby. 2020. A practical guide on conducting eye tracking studies in software engineering.Empirical Software Engineering(2020), 1–47
work page 2020
-
[50]
Bonita Sharif, Michael Falcone, and Jonathan I. Maletic. 2012. An Eye-Tracking Study on the Role of Scan Time in Finding Source Code Defects. InSymposium on Eye Tracking Research and Applications. https://doi.org/10.1145/2168556.2168642
-
[51]
Janet Siegmund, Christian Kästner, Jörg Liebig, Sven Apel, and Stefan Hanenberg
-
[52]
Measuring and modeling programming experience.Empirical Software Engineering19, 5 (2014), 1299–1334
work page 2014
-
[53]
Steven J Spencer, Claude M Steele, and Diane M Quinn. 1999. Stereotype threat and women’s math performance.Journal of experimental social psychology35, 1 (1999), 4–28
work page 1999
-
[54]
Claude M Steele and Joshua Aronson. 1995. Stereotype threat and the intellec- tual test performance of African Americans.Journal of personality and social psychology69, 5 (1995), 797
work page 1995
-
[55]
Cass R Sunstein. 2005. Moral heuristics.Behavioral and brain sciences28, 4 (2005), 531–541
work page 2005
-
[56]
Hidetake Uwano, Masahide Nakamura, Akito Monden, and Ken-ichi Matsumoto
-
[57]
InEye Tracking Research & Applications
Analyzing Individual Performance of Source Code Review Using Reviewers’ Eye Movement. InEye Tracking Research & Applications. 133–140
-
[58]
Jacob O Wobbrock, Leah Findlater, Darren Gergle, and James J Higgins. 2011. The aligned rank transform for nonparametric factorial analyses using only anova procedures. InProceedings of the SIGCHI conference on human factors in computing systems. ACM, 143–146. Received 20 February 2007; revised 12 March 2009; accepted 5 June 2009
work page 2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.