Recognition: unknown
Artifacts as Memory Beyond the Agent Boundary
Pith reviewed 2026-05-10 16:44 UTC · model grok-4.3
The pith
Certain observations called artifacts allow the environment to reduce the information an agent must store internally to represent its history in reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a mathematical framing for how the environment can functionally serve as an agent's memory, and prove that certain observations, which we call artifacts, can reduce the information needed to represent history. We corroborate our theory with experiments showing that when agents observe spatial paths, the amount of memory required to learn a performant policy is reduced. Interestingly, this effect arises unintentionally, and implicitly through the agent's sensory stream. We discuss the implications of our findings, and show they satisfy qualitative properties previously used to ground accounts of external memory.
What carries the argument
Artifacts: persistent, observable elements in the environment that carry information about past states or actions, thereby allowing a reduction in the agent's internal history representation.
If this is right
- Agents that can observe spatial paths learn performant policies with smaller internal memory.
- The memory reduction occurs automatically through the normal sensory stream without any explicit external-memory design.
- The framing meets the qualitative tests previously used for accounts of external memory.
- Environmental features can substitute for some explicit internal memory in RL agents.
- The approach points toward identifying environments that systematically lower memory demands.
Where Pith is reading between the lines
- Environments could be deliberately shaped with more persistent artifacts to reduce the memory hardware needed for complex RL agents.
- The same principle might apply to physical robots, where objects left in the workspace serve as memory without constant internal updating.
- Non-spatial tasks could be tested to check whether artifacts produce similar memory savings outside navigation settings.
- This framing invites comparisons with how humans use notes or tools to offload cognitive load.
Load-bearing premise
The agent's sensory observations include persistent, observable artifacts whose information content can be treated as reducing the agent's internal history representation without additional assumptions about how those artifacts are generated or maintained.
What would settle it
Run the same path-navigation tasks but block the agent's ability to observe the spatial paths or other artifacts while keeping the task identical; if the theory holds, the memory size needed for equivalent performance must increase.
Figures











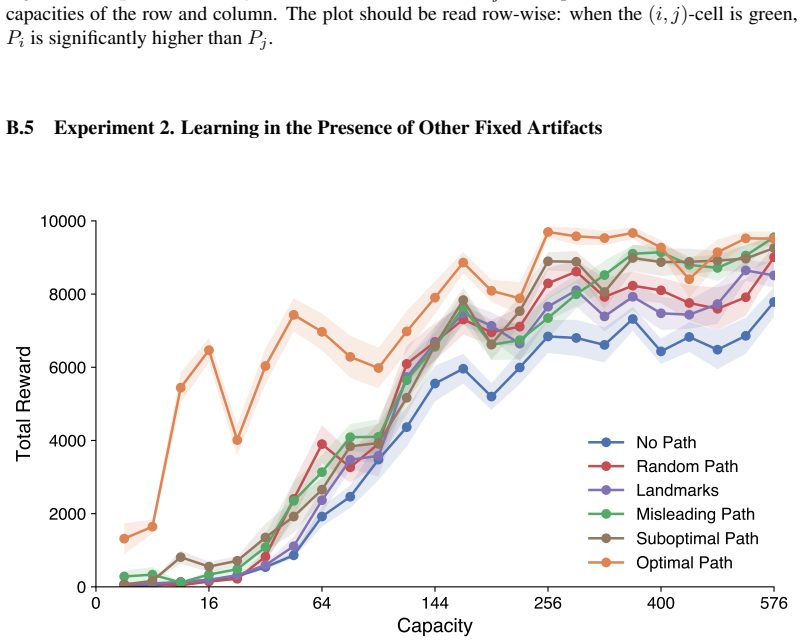







read the original abstract
The situated view of cognition holds that intelligent behavior depends not only on internal memory, but on an agent's active use of environmental resources. Here, we begin formalizing this intuition within Reinforcement Learning (RL). We introduce a mathematical framing for how the environment can functionally serve as an agent's memory, and prove that certain observations, which we call artifacts, can reduce the information needed to represent history. We corroborate our theory with experiments showing that when agents observe spatial paths, the amount of memory required to learn a performant policy is reduced. Interestingly, this effect arises unintentionally, and implicitly through the agent's sensory stream. We discuss the implications of our findings, and show they satisfy qualitative properties previously used to ground accounts of external memory. Moving forward, we anticipate further work on this subject could reveal principled ways to exploit the environment as a substitute for explicit internal memory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a mathematical framing in reinforcement learning for how persistent environmental observations, called artifacts, can functionally serve as an agent's external memory by reducing the information needed to represent history. It claims to prove this reduction and corroborates it with experiments on spatial path navigation where agents observe paths, showing unintentional memory savings through the sensory stream. The work discusses implications and alignment with qualitative properties of external memory accounts.
Significance. If the central proof is rigorous and the experiments properly isolate the artifact mechanism without confounding factors, this provides a formal information-theoretic basis for situated cognition in RL, potentially enabling more efficient agents that leverage environmental persistence as memory. The unintentional emergence in experiments and parameter-free framing are notable strengths that could influence future work on externalized memory in AI systems.
major comments (1)
- The abstract and introduction claim a proof that artifacts reduce history representation information, but the specific theorem statement, assumptions on artifact persistence, and derivation steps (likely in the theory section) require explicit verification for rigor; without controls showing the reduction is due to artifacts rather than general observation richness, the central claim risks overgeneralization.
minor comments (3)
- Clarify notation for history representation and information measures early in the paper to aid readability.
- Add more details on experimental controls, baselines, and statistical significance in the results section to strengthen the empirical corroboration.
- Ensure all references to prior work on situated cognition and external memory are complete and accurately cited.
Simulated Author's Rebuttal
We thank the referee for the positive review and recommendation for minor revision. We address the concern about the rigor of the central claim and the need for isolating controls below, and will update the manuscript accordingly.
read point-by-point responses
-
Referee: The abstract and introduction claim a proof that artifacts reduce history representation information, but the specific theorem statement, assumptions on artifact persistence, and derivation steps (likely in the theory section) require explicit verification for rigor; without controls showing the reduction is due to artifacts rather than general observation richness, the central claim risks overgeneralization.
Authors: We agree that the theorem statement, persistence assumptions, and proof steps should be made more prominent and self-contained to avoid any ambiguity. In the revision we will move the full statement of Theorem 1 and its assumptions (artifacts remain fixed in the environment across timesteps unless the agent explicitly modifies them) into the main text, expand the derivation in Section 3 with explicit intermediate steps using the chain rule on conditional mutual information, and add a new paragraph clarifying that the reduction holds only under the persistence condition. We also accept the point on controls: the current experiments compare path observations against no-path baselines, but do not fully isolate persistence from general observation richness. We have therefore run additional ablations in which the observation space is enriched with non-persistent random static features of comparable dimensionality; these yield no comparable memory reduction. The new results and figures will be inserted into Section 5 of the revised manuscript. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper introduces a new formal framing in RL where persistent artifacts in observations are defined to allow reduced internal history representation, then proves an information-theoretic reduction under that definition. The central claim does not reduce to fitted parameters, self-referential definitions, or load-bearing self-citations; the proof targets a general property of observation streams containing persistent elements, corroborated by experiments on spatial paths that demonstrate unintentional memory savings without presupposing the result. No step equates a prediction or theorem to its own inputs by construction, and the weakest assumption (presence of such artifacts) is stated explicitly without smuggling in the target conclusion.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The agent's observations are generated by an environment that can contain persistent, observable structures carrying historical information.
invented entities (1)
-
artifacts
no independent evidence
Reference graph
Works this paper leans on
-
[1]
On the convergence of bounded agents
David Abel, Andr \'e Barreto, Hado van Hasselt, Benjamin Van Roy, Doina Precup, and Satinder Singh. On the convergence of bounded agents. arXiv preprint arXiv:2307.11044, 2023
-
[2]
Anderson
John R. Anderson. Rules of the Mind. Lawrence Erlbaum Associates, Hillsdale, NJ, 1993. ISBN 978-0805812343
1993
-
[3]
Ronald C. Arkin. Behavior-based Robotics. The MIT Press, Cambridge, MA, 1998
1998
-
[4]
The Routledge Handbook of Philosophy of Memory
Sven Bernecker and Kourken Michaelian (eds.). The Routledge Handbook of Philosophy of Memory. Routledge, New York, 1st edition, 2017. ISBN 9781138909366
2017
-
[5]
Bickel and Kjell A
Peter J. Bickel and Kjell A. Doksum. Mathematical Statistics: Basic Ideas and Selected Topics, Volumes I--II Package. Chapman and Hall/CRC, 1st edition, 2015. ISBN 9781498740319
2015
-
[6]
Charles Blundell, Benigno Uria, Alexander Pritzel, Yazhe Li, Avraham Ruderman, Joel Z. Leibo, Jack Rae, Daan Wierstra, and Demis Hassabis. Model-free episodic control. arXiv preprint arXiv:1606.04460, 2016
work page Pith review arXiv 2016
-
[7]
Charles G. Boncelet. Image noise models. In Al Bovik (ed.), Handbook of Image and Video Processing, pp.\ 397--409. Academic Press, 2nd edition, 2005. ISBN 9780121197926. doi:10.1016/B978-012119792-6/50087-5
-
[8]
Observational learning by reinforcement learning
Diana Borsa, Nicolas Heess, Bilal Piot, Siqi Liu, Leonard Hasenclever, Remi Munos, and Olivier Pietquin. Observational learning by reinforcement learning. In Proceedings of the 18th International Conference on Autonomous Agents and Multi-agent Systems, AAMAS '19, pp.\ 1117–1124, Richland, SC, 2019. International Foundation for Autonomous Agents and Multia...
2019
-
[9]
Settling the reward hypothesis
Michael Bowling, John D Martin, David Abel, and Will Dabney. Settling the reward hypothesis. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett (eds.), Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pp.\ 3003--3020. PMLR, 2...
2023
-
[10]
Reinforcement learning applied to linear quadratic regulation
Steven Bradtke. Reinforcement learning applied to linear quadratic regulation. In S. Hanson, J. Cowan, and C. Giles (eds.), Advances in Neural Information Processing Systems, volume 5. Morgan-Kaufmann, 1992
1992
-
[11]
Roger W. Brockett and Daniel Liberzon. Quantized feedback stabilization of linear systems. IEEE Transactions on Automatic Control, 45 0 (7): 0 1279--1289, July 2000. doi:10.1109/9.867021
-
[12]
Rodney A. Brooks. A robust layered control system for a mobile robot. IEEE Journal on Robotics and Automation, 2 0 (1): 0 14--23, 1986. doi:10.1109/JRA.1986.1087032
-
[13]
Rodney A. Brooks. Intelligence without representation. Artificial Intelligence, 47 0 (1): 0 139--159, 1991. ISSN 0004-3702. doi:https://doi.org/10.1016/0004-3702(91)90053-M
-
[14]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in Neural Information Processing Systems, 33: 0 1877--1901, 2020
1901
-
[15]
Being there: Putting brain, body, and world together again
Andy Clark. Being there: Putting brain, body, and world together again. MIT press, 1998
1998
-
[16]
The extended mind
Andy Clark and David Chalmers. The extended mind. Analysis, 58 0 (1): 0 7--19, 1998
1998
-
[17]
Delchamps
David F. Delchamps. Stabilizing a linear system with quantized state feedback. IEEE Transactions on Automatic Control, 35 0 (8): 0 916--924, August 1990
1990
-
[18]
Simple agent, complex environment: efficient reinforcement learning with agent states
Shi Dong, Benjamin Van Roy, and Zhengyuan Zhou. Simple agent, complex environment: efficient reinforcement learning with agent states. Journal of Machine Learning Research, 23 0 (1), January 2022. ISSN 1532-4435
2022
-
[19]
Ruiz, Julian Schrittwieser, Grzegorz Swirszcz, et al
Alhussein Fawzi, Matej Balog, Aja Huang, Thomas Hubert, Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Francisco J R. Ruiz, Julian Schrittwieser, Grzegorz Swirszcz, et al. Discovering faster matrix multiplication algorithms with reinforcement learning. Nature, 610 0 (7930): 0 47--53, 2022
2022
-
[20]
Michael S. Gazzaniga (ed.). The Cognitive Neurosciences. The MIT Press, 9 2009. ISBN 9780262303101. doi:10.7551/mitpress/8029.001.0001
-
[21]
Samuel J. Gershman and Nathaniel D. Daw. Reinforcement learning and episodic memory in humans and animals: An integrative framework. Annual Review of Psychology, 68 0 (Volume 68, 2017): 0 101--128, 2017. ISSN 1545-2085. doi:https://doi.org/10.1146/annurev-psych-122414-033625
-
[22]
Pierre-Paul Grass \'e . La reconstruction du nid et les coordinations interindividuelles chez bellicositermes natalensis et cubitermes sp. la th \'e orie de la stigmergie: Essai d'interpr \'e tation du comportement des termites constructeurs. Insectes Sociaux, 6 0 (1): 0 41--80, March 1959. ISSN 1420-9098. doi:10.1007/BF02223791
-
[23]
Deep recurrent q-learning for partially observable mdps
Matthew Hausknecht and Peter Stone. Deep recurrent q-learning for partially observable mdps. In AAAI Fall Symposium Series: Sequential Decision Making for Intelligent Agents, pp.\ 29--37, 2015
2015
-
[24]
Varieties of artifacts: Embodied, perceptual, cognitive, and affective
Richard Heersmink. Varieties of artifacts: Embodied, perceptual, cognitive, and affective. Topics in Cognitive Science, 13 0 (4): 0 573--596, 2021. doi:10.1111/tops.12549
-
[25]
Stigmergy as a universal coordination mechanism: Components, varieties and applications
Francis Heylighen. Stigmergy as a universal coordination mechanism: Components, varieties and applications. https://pespmc1.vub.ac.be/Papers/Stigmergy-Springer.pdf, 2015
2015
-
[26]
Generalizable episodic memory for deep reinforcement learning
Hao Hu, Jianing Ye, Guangxiang Zhu, Zhizhou Ren, and Chongjie Zhang. Generalizable episodic memory for deep reinforcement learning. In Marina Meila and Tong Zhang (eds.), Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pp.\ 4380--4390. PMLR, 18--24 Jul 2021
2021
-
[27]
Cognition in the Wild
Edwin Hutchins. Cognition in the Wild. The MIT Press, 02 1995. ISBN 9780262275972
1995
-
[28]
Cognitive artifacts
Edwin Hutchins. Cognitive artifacts. In The MIT Encyclopedia of the Cognitive Sciences , pp.\ 126--127. MIT Press, Cambridge, MA, 2001
2001
-
[29]
Universal Artificial Intelligence
Marcus Hutter. Universal Artificial Intelligence. Texts in Theoretical Computer Science. An EATCS Series. Springer, Berlin, Heidelberg, 1st edition, 2005. ISBN 978-3-540-22139-5. doi:10.1007/b138233
-
[30]
Klassen, Phillip Christoffersen, Amir massoud Farahmand, and Sheila A
Rodrigo Toro Icarte, Richard Valenzano, Toryn Q. Klassen, Phillip Christoffersen, Amir massoud Farahmand, and Sheila A. McIlraith. The act of remembering: a study in partially observable reinforcement learning, 2020
2020
-
[31]
Observable operator models for discrete stochastic time series
Herbert Jaeger. Observable operator models for discrete stochastic time series. Neural Computation, 12 0 (6): 0 1371--1398, 06 2000. ISSN 0899-7667. doi:10.1162/089976600300015411
-
[32]
Leslie Pack Kaelbling, Michael L. Littman, and Anthony R. Cassandra. Planning and acting in partially observable stochastic domains. Artificial Intelligence, 101 0 (1-2): 0 99--134, 1998. ISSN 0004-3702. doi:https://doi.org/10.1016/S0004-3702(98)00023-X
-
[33]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[34]
Arbaaz Khan, Clark Zhang, Nikolay Atanasov, Konstantinos Karydis, Vijay Kumar, and Daniel D. Lee. Memory augmented control networks. In International Conference on Learning Representations, 2018
2018
-
[35]
Stanley B. Klein. What memory is. WIREs Cognitive Science, 6 0 (1): 0 1--38, 2015. doi:https://doi.org/10.1002/wcs.1333
-
[36]
Hippocampal contributions to control: The third way
M\' a t\' e Lengyel and Peter Dayan. Hippocampal contributions to control: The third way. In J. Platt, D. Koller, Y. Singer, and S. Roweis (eds.), Advances in Neural Information Processing Systems, volume 20, pp.\ 889--896, 2007
2007
-
[37]
Self-improving reactive agents based on reinforcement learning, planning and teaching
Long-Ji Lin. Self-improving reactive agents based on reinforcement learning, planning and teaching. Machine Learning, 8 0 (3): 0 293--321, May 1992. ISSN 1573-0565. doi:10.1007/BF00992699
-
[38]
Episodic memory deep q-networks
Zichuan Lin, Tianqi Zhao, Guangwen Yang, and Lintao Zhang. Episodic memory deep q-networks. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI-18 , pp.\ 2433--2439. International Joint Conferences on Artificial Intelligence Organization, 7 2018. doi:10.24963/ijcai.2018/337
-
[39]
Michael L. Littman. Memoryless policies: theoretical limitations and practical results. In Proceedings of the Third International Conference on Simulation of Adaptive Behavior: From Animals to Animats 3: From Animals to Animats 3, SAB94, pp.\ 238–245, Cambridge, MA, USA, 1994. The MIT Press. ISBN 0262531224
1994
-
[40]
Littman, Richard S
Michael L. Littman, Richard S. Sutton, and Satinder Singh. Predictive representations of state. In T. Dietterich, S. Becker, and Z. Ghahramani (eds.), Advances in Neural Information Processing Systems, volume 14, pp.\ 1555--1561, 2001
2001
-
[41]
Reinforcement Learning for Embedded Agents Facing Complex Tasks
Mario Mart \' n Mu \ n oz. Reinforcement Learning for Embedded Agents Facing Complex Tasks. Phd thesis, Universitat Polit \`e cnica de Catalunya, Barcelona, Spain, 1998
1998
-
[42]
Cognitive integration and the extended mind
Richard Menary. Cognitive integration and the extended mind. The extended mind, pp.\ 227--243, 2010
2010
-
[43]
Is external memory memory? biological memory and extended mind
Kourken Michaelian. Is external memory memory? biological memory and extended mind. Consciousness and Cognition, 21 0 (3): 0 1154--1165, 2012. ISSN 1053-8100. doi:https://doi.org/10.1016/j.concog.2012.04.008
-
[44]
Kourken Michaelian and John Sutton. Memory . In Edward N. Zalta (ed.), The Stanford Encyclopedia of Philosophy . Metaphysics Research Lab, Stanford University, S ummer 2017 edition, 2017
2017
-
[45]
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. Human-level control through deep reinforcement l...
-
[46]
Unified Theories of Cognition
Allen Newell. Unified Theories of Cognition. Harvard University Press, Cambridge, MA, 1990. ISBN 9780674920996
1990
-
[47]
Control of memory, active perception, and action in minecraft
Junhyuk Oh, Valliappa Chockalingam, Satinder Singh, and Honglak Lee. Control of memory, active perception, and action in minecraft. In Maria Florina Balcan and Kilian Q. Weinberger (eds.), Proceedings of The 33rd International Conference on Machine Learning, volume 48 of Proceedings of Machine Learning Research, pp.\ 2790--2799, New York, New York, USA, 2...
2016
-
[48]
Empirical design in reinforcement learning
Andrew Patterson, Samuel Neumann, Martha White, and Adam White. Empirical design in reinforcement learning. Journal of Machine Learning Research, 25 0 (318): 0 1--63, 2024. URL https://jmlr.org/papers/v25/23-0183.html
2024
-
[49]
Learning policies with external memory
Leonid Peshkin, Nicolas Meuleau, and Leslie Pack Kaelbling. Learning policies with external memory. In Proceedings of the 16th International Conference on Machine Learning, ICML '99, pp.\ 307–314, San Francisco, CA, USA, 1999. Morgan Kaufmann Publishers Inc. ISBN 1558606122
1999
-
[50]
Neural episodic control
Alexander Pritzel, Benigno Uria, Sriram Srinivasan, Adri \`a Puigdom \`e nech Badia, Oriol Vinyals, Demis Hassabis, Daan Wierstra, and Charles Blundell. Neural episodic control. In Doina Precup and Yee Whye Teh (eds.), Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pp.\ 2827--28...
2017
-
[51]
Rao and Michael P
Anand S. Rao and Michael P. Georgeff. BDI agents: From theory to practice. In Proceedings of the First International Conference on Multi-Agent Systems (ICMAS-95), pp.\ 312--319, 1995
1995
-
[52]
Slime mold uses an externalized spatial “memory” to navigate in complex environments
Chris R Reid, Tanya Latty, Audrey Dussutour, and Madeleine Beekman. Slime mold uses an externalized spatial “memory” to navigate in complex environments. Proceedings of the National Academy of Sciences, 109 0 (43): 0 17490--17494, 2012
2012
-
[53]
Cognitive stigmergy: Towards a framework based on agents and artifacts
Alessandro Ricci, Andrea Omicini, Mirko Viroli, Luca Gardelli, and Enrico Oliva. Cognitive stigmergy: Towards a framework based on agents and artifacts. In Danny Weyns, H. Van Dyke Parunak, and Fabien Michel (eds.), Environments for Multi-Agent Systems III, pp.\ 124--140. Springer, 2007. ISBN 978-3-540-71103-2
2007
-
[54]
The Analysis of Mind
Bertrand Russell. The Analysis of Mind. G. Allen & Unwin, London, 1921
1921
-
[55]
Prioritized experience replay
Tom Schaul, John Quan, Ioannis Antonoglou, and David Silver. Prioritized experience replay. In International Conference on Learning Representations, 2016
2016
-
[56]
Mastering the game of go with deep neural networks and tree search
David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. Mastering the game of go with deep neural networks and tree search. nature, 529 0 (7587): 0 484--489, 2016
2016
-
[57]
Externalized memory in slime mould and the extended (non-neuronal) mind
Matthew Sims and Julian Kiverstein. Externalized memory in slime mould and the extended (non-neuronal) mind. Cognitive Systems Research, 73: 0 26--35, 2022. ISSN 1389-0417. doi:https://doi.org/10.1016/j.cogsys.2021.12.001
-
[58]
James, and Matthew R
Satinder Singh, Michael R. James, and Matthew R. Rudary. Predictive state representations: a new theory for modeling dynamical systems. In Proceedings of the 20th Conference on Uncertainty in Artificial Intelligence, UAI '04, pp.\ 512–519, Arlington, Virginia, USA, 2004. AUAI Press. ISBN 0974903906
2004
-
[59]
Singh, Tommi Jaakkola, and Michael I
Satinder P. Singh, Tommi Jaakkola, and Michael I. Jordan. Learning without state-estimation in partially observable markovian decision processes. In William W. Cohen and Haym Hirsh (eds.), Machine Learning Proceedings 1994, pp.\ 284--292. Morgan Kaufmann, San Francisco (CA), 1994. ISBN 978-1-55860-335-6. doi:https://doi.org/10.1016/B978-1-55860-335-6.50042-8
-
[60]
Kim Sterelny. Minds: extended or scaffolded? Phenomenology and the Cognitive Sciences, 9 0 (4): 0 465--481, December 2010. ISSN 1572-8676. doi:10.1007/s11097-010-9174-y
-
[61]
From nonlinearity to optimality: pheromone trail foraging by ants
David J.T Sumpter and Madeleine Beekman. From nonlinearity to optimality: pheromone trail foraging by ants. Animal Behaviour, 66 0 (2): 0 273--280, 2003. ISSN 0003-3472. doi:https://doi.org/10.1006/anbe.2003.2224
-
[62]
Constructive memory and distributed cognition: Towards an interdisciplinary framework
John Sutton. Constructive memory and distributed cognition: Towards an interdisciplinary framework. In B. Kokinov and W. Hirst (eds.), Constructive Memory, pp.\ 290--303. New Bulgarian University, 2003
2003
-
[63]
Richard S. Sutton. The bitter lesson. Incomplete Ideas (blog), 2019. URL http://www.incompleteideas.net/IncIdeas/BitterLesson.html
2019
-
[64]
Richard S. Sutton. The quest for a common model of the intelligent decision maker. In Proceedings of the 5th Multi-disciplinary Conference on Reinforcement Learning and Decision Making (RLDM 2022), Providence, Rhode Island, USA, 2022
2022
-
[65]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction. The MIT Press, Cambridge, MA, 2nd edition, 2018
2018
-
[66]
Memory allocation in resource-constrained reinforcement learning
Massimiliano Tamborski and David Abel. Memory allocation in resource-constrained reinforcement learning. arXiv preprint arXiv:2506.17263, 2025
-
[67]
B. Thierry, G. Theraulaz, J.Y. Gautier, and B. Stiegler. Joint memory. Behavioural Processes, 35 0 (1): 0 127--140, 1995. ISSN 0376-6357. doi:https://doi.org/10.1016/0376-6357(95)00039-9. Cognition and Evolution
-
[68]
Episodic and semantic memory
Endel Tulving. Episodic and semantic memory. In Organization of Memory, pp.\ 381--403. Academic Press, London, UK, 1972
1972
-
[69]
Christopher J. C. H. Watkins and Peter Dayan. Q-learning. Machine Learning, 8 0 (3--4): 0 279--292, May 1992. ISSN 1573-0565. doi:10.1007/BF00992698
-
[70]
Edward O. Wilson. Chemical communication among workers of the fire ant solenopsis saevissima (fr. smith) 1. the organization of mass-foraging. Animal Behaviour, 10 0 (1): 0 134--147, 1962. ISSN 0003-3472. doi:https://doi.org/10.1016/0003-3472(62)90141-0
-
[71]
Episodic reinforcement learning with associative memory
Guangxiang Zhu*, Zichuan Lin*, Guangwen Yang, and Chongjie Zhang. Episodic reinforcement learning with associative memory. In International Conference on Learning Representations, 2020
2020
-
[72]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.