Recognition: unknown
MT-OSC: Path for LLMs that Get Lost in Multi-Turn Conversation
Pith reviewed 2026-05-10 16:54 UTC · model grok-4.3
The pith
MT-OSC condenses multi-turn chat histories to cut token counts by up to 72% while preserving LLM accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
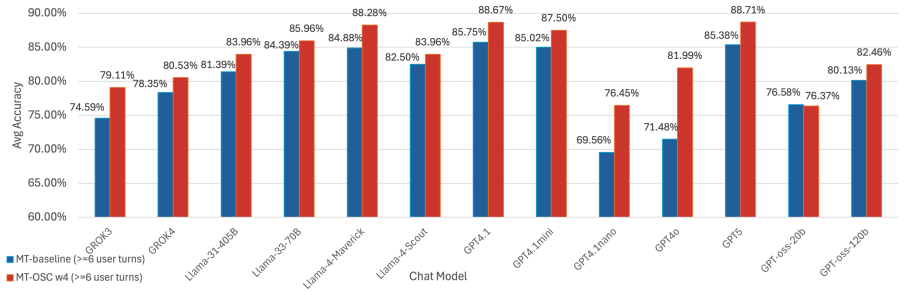
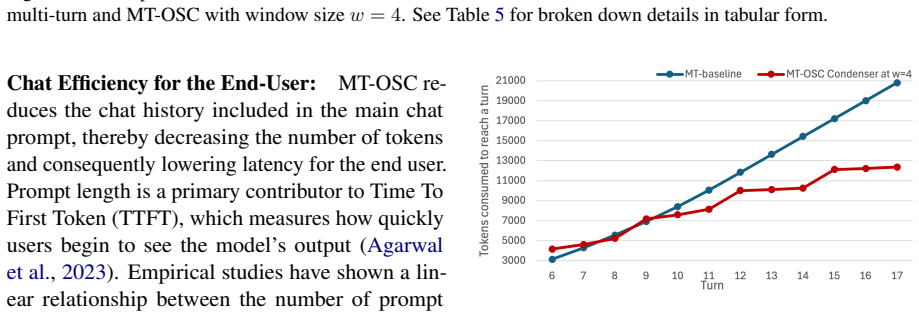
The paper presents MT-OSC as a One-off Sequential Condensation framework. A Condenser Agent applies a few-shot inference-based Condenser and a lightweight Decider to selectively retain essential information from chat history. This reduces token counts by up to 72% in 10-turn dialogues. When tested on 13 state-of-the-art LLMs and diverse multi-turn benchmarks, it narrows the performance gap by yielding improved or preserved accuracy and remains robust to distractors and irrelevant turns.
What carries the argument
The Condenser Agent, which uses few-shot inference to condense chat history selectively via a Condenser and Decider pair.
If this is right
- Enables richer context in multi-turn chats within constrained input spaces.
- Reduces latency and operational costs for extended conversations.
- Maintains or improves accuracy across a wide range of LLMs and datasets.
- Provides robustness against distractors and irrelevant information in dialogues.
- Offers a scalable solution for balancing performance in long conversations.
Where Pith is reading between the lines
- Integrating MT-OSC into LLM deployment pipelines could automatically manage history length for users.
- Similar condensation techniques might apply to other sequential data tasks like document summarization over time.
- It suggests that explicit history management modules can outperform simply expanding context windows in some cases.
- Developers could test this on custom multi-turn tasks to measure token savings and accuracy retention.
Load-bearing premise
The few-shot Condenser and lightweight Decider reliably capture and retain all essential prior information without errors that would affect the main LLM's responses.
What would settle it
Running MT-OSC on a benchmark where full history yields higher accuracy than the condensed version on the same model would contradict the preserved performance claim.
Figures










read the original abstract
Large language models (LLMs) suffer significant performance degradation when user instructions and context are distributed over multiple conversational turns, yet multi-turn (MT) interactions dominate chat interfaces. The routine approach of appending full chat history to prompts rapidly exhausts context windows, leading to increased latency, higher computational costs, and diminishing returns as conversations extend. We introduce MT-OSC, a One-off Sequential Condensation framework that efficiently and automatically condenses chat history in the background without disrupting the user experience. MT-OSC employs a Condenser Agent that uses a few-shot inference-based Condenser and a lightweight Decider to selectively retain essential information, reducing token counts by up to 72% in 10-turn dialogues. Evaluated across 13 state-of-the-art LLMs and diverse multi-turn benchmarks, MT-OSC consistently narrows the multi-turn performance gap - yielding improved or preserved accuracy across datasets while remaining robust to distractors and irrelevant turns. Our results establish MT-OSC as a scalable solution for multi-turn chats, enabling richer context within constrained input spaces, reducing latency and operational cost, while balancing performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MT-OSC, a One-off Sequential Condensation framework for multi-turn LLM conversations. It employs a Condenser Agent using few-shot inference-based Condenser and a lightweight Decider to selectively retain essential information from chat history, claiming up to 72% token reduction in 10-turn dialogues. Evaluated on 13 LLMs and diverse benchmarks, it asserts consistent narrowing of the multi-turn performance gap with improved or preserved accuracy and robustness to distractors and irrelevant turns.
Significance. If the empirical claims hold, MT-OSC provides a practical engineering solution to context-window exhaustion and latency in conversational LLMs, enabling longer interactions at lower cost without user disruption. The background condensation approach is a useful applied contribution, though it lacks machine-checked proofs or parameter-free derivations.
major comments (3)
- [Abstract] Abstract: The central claim of 'improved or preserved accuracy' and 72% token reduction across 13 LLMs is presented without exact metrics, error bars, baseline comparisons (e.g., full-history vs. truncated), or statistical tests, directly limiting verification of the performance and robustness assertions.
- [Method (Condenser Agent)] Method section (Condenser Agent description): The load-bearing assumption that the few-shot Condenser plus Decider reliably extracts and retains every task-critical fact (including implicit references and conditional constraints) is not directly validated; robustness tests to distractors measure noise tolerance but do not quantify recall fidelity or omission rates that could silently degrade downstream accuracy.
- [Experiments] Experiments section: No details are given on distractor construction, irrelevant-turn injection, or per-benchmark accuracy tables comparing MT-OSC to full-history and naive baselines, undermining the claim that the multi-turn gap is narrowed without degradation.
minor comments (2)
- [Title] The title is informal and vague; a more descriptive title would better convey the technical contribution.
- [Method] Notation for the Condenser and Decider components could be formalized with pseudocode or explicit input/output definitions to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 'improved or preserved accuracy' and 72% token reduction across 13 LLMs is presented without exact metrics, error bars, baseline comparisons (e.g., full-history vs. truncated), or statistical tests, directly limiting verification of the performance and robustness assertions.
Authors: We agree that the abstract would benefit from greater specificity. While the full paper contains detailed per-LLM and per-benchmark tables with accuracy comparisons to full-history and truncated baselines plus token-reduction statistics, the abstract itself summarizes these claims at a high level. We will revise the abstract to include representative quantitative results (e.g., average token reduction and accuracy deltas across the 13 LLMs) and will note that comprehensive tables appear in the Experiments section. revision: yes
-
Referee: [Method (Condenser Agent)] Method section (Condenser Agent description): The load-bearing assumption that the few-shot Condenser plus Decider reliably extracts and retains every task-critical fact (including implicit references and conditional constraints) is not directly validated; robustness tests to distractors measure noise tolerance but do not quantify recall fidelity or omission rates that could silently degrade downstream accuracy.
Authors: The manuscript validates the Condenser Agent primarily through end-to-end accuracy preservation on downstream tasks, which serves as an indirect measure of retention quality. We acknowledge that direct quantification of recall fidelity and omission rates for implicit facts would provide stronger evidence. We will add a new analysis subsection that reports recall metrics for key facts (including implicit references) on a controlled subset of dialogues to directly address this concern. revision: yes
-
Referee: [Experiments] Experiments section: No details are given on distractor construction, irrelevant-turn injection, or per-benchmark accuracy tables comparing MT-OSC to full-history and naive baselines, undermining the claim that the multi-turn gap is narrowed without degradation.
Authors: The Experiments section does contain accuracy tables that compare MT-OSC against full-history and other baselines for each benchmark. However, we agree that the construction of distractors and the injection of irrelevant turns could be described more explicitly. We will expand the Experiments section with a dedicated paragraph detailing the distractor-generation process and irrelevant-turn methodology, and we will ensure all tables are clearly labeled with the requested baseline comparisons. revision: yes
Circularity Check
No circularity: MT-OSC is an empirical engineering method with independent evaluation
full rationale
The paper introduces MT-OSC as a practical condensation framework relying on a few-shot Condenser Agent and lightweight Decider, then reports empirical results on token reduction and accuracy across 13 LLMs and multi-turn benchmarks. No mathematical derivation chain, equations, or first-principles predictions are present in the abstract or description. Claims of narrowing performance gaps rest on direct evaluation rather than any fitted parameter renamed as a prediction or self-referential definition. The method is self-contained as an applied contribution without load-bearing self-citations or ansatzes that reduce to inputs by construction.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Condenser Agent
no independent evidence
-
Decider
no independent evidence
Forward citations
Cited by 1 Pith paper
-
GSM-SEM: Benchmark and Framework for Generating Semantically Variant Augmentations
GSM-SEM generates reusable, stochastic semantic variants of math reasoning benchmarks that alter underlying facts but preserve answers, producing larger LLM performance drops than prior surface-level variants.
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Enhancing long-term memory using hierarchi- cal aggregate tree for retrieval augmented generation. arXiv e-prints, pages arXiv–2406. Amit Agarwal, Hansa Meghwani, Hitesh Laxmichand Patel, Tao Sheng, Sujith Ravi, and Dan Roth. 2025. Aligning LLMs for multilingual consistency in enter- prise applications. InProceedings of the 2025 Con- ference on Empirical ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Bogdan Gliwa, Iwona Mochol, Maciej Biesek, and Alek- sander Wawer
A survey on dialogue summarization: Re- cent advances and new frontiers.arXiv preprint arXiv:2107.03175. Bogdan Gliwa, Iwona Mochol, Maciej Biesek, and Alek- sander Wawer. 2019. SAMSum corpus: A human- annotated dialogue dataset for abstractive summa- rization. InProceedings of the 2nd Workshop on New Frontiers in Summarization, pages 70–79, Hong Kong, Ch...
-
[3]
LLMs Get Lost In Multi-Turn Conversation
LongLLMLingua: Accelerating and enhanc- ing LLMs in long context scenarios via prompt com- pression. InProceedings of the 62nd Annual Meeting 10 of the Association for Computational Linguistics (Vol- ume 1: Long Papers), pages 1658–1677, Bangkok, Thailand. Association for Computational Linguistics. Wai-Chung Kwan, Xingshan Zeng, Yuxin Jiang, Yufei Wang, L...
work page internal anchor Pith review arXiv 2024
-
[4]
InProceedings of the 63rd Annual Meeting of the Association for Com- putational Linguistics (Volume 6: Industry Track), pages 1013–1026, Vienna, Austria
Hard negative mining for domain-specific re- trieval in enterprise systems. InProceedings of the 63rd Annual Meeting of the Association for Com- putational Linguistics (Volume 6: Industry Track), pages 1013–1026, Vienna, Austria. Association for Computational Linguistics. Seyed Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, an...
2025
-
[5]
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
Hybrid AI for responsive multi-turn online 11 conversations with novel dynamic routing and feed- back adaptation. InProceedings of the 4th Interna- tional Workshop on Knowledge-Augmented Methods for Natural Language Processing, pages 215–229, Albuquerque, New Mexico, USA. Association for Computational Linguistics. Archiki Prasad, Alexander Koller, Mareike...
work page internal anchor Pith review arXiv 2024
-
[6]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Direct preference optimization: Your lan- guage model is secretly a reward model.Preprint, arXiv:2305.18290. Rana Salama, Jason Cai, Michelle Yuan, Anna Currey, Monica Sunkara, Yi Zhang, and Yassine Benajiba
work page internal anchor Pith review arXiv
-
[7]
InProceedings of the 2025 Con- ference on Empirical Methods in Natural Language Processing, pages 33136–33152, Suzhou, China
MemInsight: Autonomous memory augmenta- tion for LLM agents. InProceedings of the 2025 Con- ference on Empirical Methods in Natural Language Processing, pages 33136–33152, Suzhou, China. As- sociation for Computational Linguistics. Sneheel Sarangi, Maha Elgarf, and Hanan Salam. 2025. Decompose-ToM: Enhancing theory of mind reason- ing in large language mo...
2025
-
[8]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Can LLMs narrate tabular data? an evaluation framework for natural language representations of text-to-SQL system outputs. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 883– 902, Suzhou (China). Association for Computational Linguistics. Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo ...
work page internal anchor Pith review arXiv 2025
-
[9]
A survey on multi-turn interaction capa- bilities of large language models.arXiv preprint arXiv:2501.09959. Tong Zhang, Yong Liu, Boyang Li, Zhiwei Zeng, Peng- wei Wang, Yuan You, Chunyan Miao, and Lizhen Cui
-
[10]
InFind- ings of the Association for Computational Linguistics: EMNLP 2022, pages 3395–3407, Abu Dhabi, United Arab Emirates
History-aware hierarchical transformer for multi-session open-domain dialogue system. InFind- ings of the Association for Computational Linguistics: EMNLP 2022, pages 3395–3407, Abu Dhabi, United Arab Emirates. Association for Computational Lin- guistics. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Tianle Li, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zhu...
2022
-
[11]
lost in the middle
and diverse data sources, including business and finance, social media, and even unstructured data (Yang et al., 2025; Singh et al., 2025; Liu et al., 2024b; Singh, 2021), spanning task-oriented, data- analysis-focused (Singh et al., 2021), and free-form settings, and now LLMs are heavily used across these data types and applications. While LLMs of- fer s...
2025
-
[12]
If time allows, try again
and LongLLMLingua (Jiang et al., 2024) target a different regime of compressing very long inputs via token/segment pruning (often importance/perplexity-based) and, for LongLLM- Lingua, reordering/filtering. In short-horizon multi- turn setting, redundancy is limited and correctness often hinges on small but decisive state (e.g., nega- 13 tions, correction...
2024
-
[13]
N is set to be a portion of the total number of turns in the conversation
Repetition Infusion: Repeated random turns within the multi-turn dialogues - for each multi-turn conversation, we randomly select N turns in the middle (not the first turn or the last turn) and repeat them once in the same position. N is set to be a portion of the total number of turns in the conversation
-
[14]
- for each multi-turn conversa- tion, we randomly select N turns in the middle (exclude the first turn) and add a randomly se- lected filler word as extra turn right before them
Filler Injection: Inserted random turns con- taining only meaningless filler words, such as ’Um.’, ’Uh.’, ’Well.’, ’Anyway.’, ’Ok.’, ’Hmm.’, etc. - for each multi-turn conversa- tion, we randomly select N turns in the middle (exclude the first turn) and add a randomly se- lected filler word as extra turn right before them
-
[15]
I am providing you a table. You must produce a short one-sentence description of the table. The description should be at most 30 words. . . . . . . . . . . . ..<data>
Contextual Diversion: For each multi-turn chat, we randomly select N turns from the middle (excluding the first and last) and add 17 new, contextually relevant turns that aren’t essential for task completion. If a selected turn isn’t blank, we generate an extra turn based on its content and place it immediately after. Appendix C.3 shows the prompt we use ...
2012
-
[16]
How far is Elvis from his house?
Repetition Infusion 2. Filler Injection 3. Contextual Diversion MT MT-OSC MT MT-OSC MT MT-OSC GSMshrd 85.80 86.63 84.77 87.86 82.92 84.77 BFCLshrd 63.45 70.64 64.02 69.89 59.77 67.24 HumanEvalshrd 70.81 75.89 74.40 79.17 66.67 79.63 Spidershrd 67.68 70.20 63.13 66.67 57.07 61.62 refinementmte 5.67 5.66 5.7 5.64 5.01 5.00 Table 7: Comparison of performance...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.