Recognition: no theorem link
Cross-Lingual Attention Distillation with Personality-Informed Generative Augmentation for Multilingual Personality Recognition
Pith reviewed 2026-05-10 18:18 UTC · model grok-4.3
The pith
A method that augments English personality data with LLM translations and uses cross-lingual attention distillation improves recognition of traits in other languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
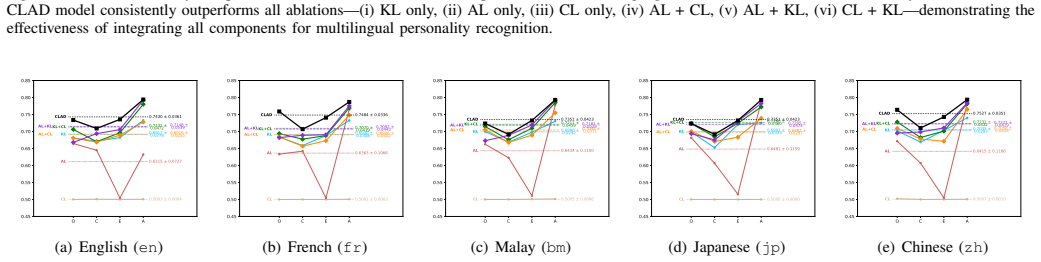
The paper establishes that the ADAM approach, consisting of Personality-Informed Generative Augmentation to create high-quality multilingual training examples from English data and Cross-Lingual Attention Distillation to align the model across languages, yields higher balanced accuracy in personality trait detection than standard binary cross-entropy loss, with specific gains of 0.0573 on the Essays dataset and 0.0968 on the Kaggle dataset, while also matching the performance of top encoder-based models.
What carries the argument
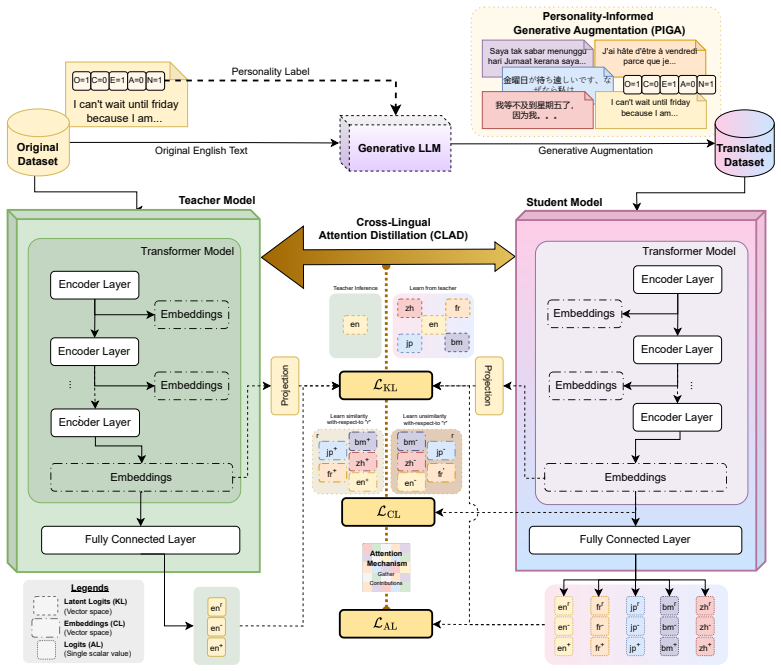
Cross-Lingual Attention Distillation (CLAD) which distills attention knowledge from an English teacher to a multilingual student model, enabled by Personality-Informed Generative Augmentation (PIGA) that directs an LLM to produce label-preserving translations and rewrites.
Load-bearing premise
The large language model produces translations and rewrites that accurately retain the personality trait labels from the original English texts across different languages and cultures.
What would settle it
Human judges rating the personality traits in the generated texts or a classifier trained on original data showing consistent predictions on the augmented data would test whether labels are preserved without bias.
Figures







read the original abstract
While significant work has been done on personality recognition, the lack of multilingual datasets remains an unresolved challenge. To address this, we propose ADAM (Cross-Lingual (A)ttention (D)istillation with Personality-Guided Generative (A)ugmentation for (M)ultilingual Personality Recognition), a state-of-the-art approach designed to advance multilingual personality recognition. Our approach leverages an existing English-language personality dataset as the primary source and employs a large language model (LLM) for translationbased augmentation, enhanced by Personality-Informed Generative Augmentation (PIGA), to generate high-quality training data in multiple languages, including Japanese, Chinese, Malay, and French. We provide a thorough analysis to justify the effectiveness of these augmentation techniques. Building on these advancements, ADAM integrates Cross-Lingual Attention Distillation (CLAD) to train a model capable of understanding and recognizing personality traits across languages, bridging linguistic and cultural gaps in personality analysis. This research presents a thorough evaluation of the proposed augmentation method, incorporating an ablation study on recognition performance to ensure fair comparisons and robust validation. Overall, with PIGA augmentation, the findings demonstrate that CLAD significantly outperforms the standard BCE across all languages and personality traits, achieving notable improvements in average BA scores - 0.6332 (+0.0573) on the Essays dataset and 0.7448 (+0.0968) on the Kaggle dataset. The CLAD-trained model also demonstrated strong generalizability and achieved benchmark performance comparable to current leading encoder models. The model weight, dataset, and algorithm repository are available at https://research.jingjietan.com/?q=ADAM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ADAM, which augments English personality datasets (Essays, Kaggle) using LLM-based translation and Personality-Informed Generative Augmentation (PIGA) to create training data in Japanese, Chinese, Malay, and French, then applies Cross-Lingual Attention Distillation (CLAD) to train multilingual personality recognition models. It reports that CLAD with PIGA outperforms standard BCE loss across languages and traits, with average balanced accuracy (BA) gains of +0.0573 (to 0.6332) on Essays and +0.0968 (to 0.7448) on Kaggle, plus an ablation study and claims of generalizability comparable to leading encoders.
Significance. If the generated multilingual data accurately preserves original personality labels without systematic cultural or linguistic bias, the work would provide a practical route to multilingual personality recognition by leveraging abundant English resources and LLMs, potentially improving cross-lingual transfer in affective computing and enabling more inclusive NLP systems for non-English users.
major comments (3)
- [Abstract and experimental results / ablation study] The central performance claim (CLAD + PIGA beats BCE by the reported BA margins) rests on the unverified assumption that PIGA-generated translations and personality-informed rewrites retain the exact original Big-Five trait labels. The abstract and experimental sections provide no human validation, inter-annotator agreement scores, or cross-lingual label-consistency metrics (e.g., Cohen’s kappa on back-translated samples or trait-expression drift analysis). Without this, attribution of gains to CLAD rather than label noise cannot be established.
- [Results tables and ablation study] No error bars, standard deviations across random seeds, or statistical significance tests (e.g., paired t-test or McNemar) are reported for the BA improvements (+0.0573 and +0.0968). This omission makes it impossible to determine whether the observed lifts exceed experimental variability, especially given the free parameters in LLM generation and distillation temperature.
- [Ablation study section] The ablation study is described as ensuring “fair comparisons,” yet it does not include a control condition that isolates label fidelity (e.g., comparing performance on PIGA data vs. human-verified translations or measuring trait-score correlation before/after augmentation). This leaves open the possibility that gains arise from altered label distributions rather than the CLAD mechanism.
minor comments (2)
- [Experimental setup] The repository link is given but no details on reproducibility (e.g., exact LLM prompts, generation hyperparameters, or seed values) appear in the main text; these should be added to the supplementary material or code release.
- [Methods] Notation for the CLAD loss and attention distillation components is introduced without an explicit equation reference in the provided abstract; ensure all symbols are defined at first use in the methods section.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. We have carefully considered each major comment and provide point-by-point responses below. Where appropriate, we will revise the manuscript to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract and experimental results / ablation study] The central performance claim (CLAD + PIGA beats BCE by the reported BA margins) rests on the unverified assumption that PIGA-generated translations and personality-informed rewrites retain the exact original Big-Five trait labels. The abstract and experimental sections provide no human validation, inter-annotator agreement scores, or cross-lingual label-consistency metrics (e.g., Cohen’s kappa on back-translated samples or trait-expression drift analysis). Without this, attribution of gains to CLAD rather than label noise cannot be established.
Authors: We thank the referee for highlighting this important point. While our manuscript includes an analysis of the augmentation techniques and an ablation study demonstrating performance improvements, we acknowledge that explicit human validation or inter-annotator agreement for label preservation in the generated multilingual data is not reported. To strengthen the attribution of gains to the CLAD mechanism, we will add a new subsection in the experimental results detailing label consistency metrics, including back-translation experiments and correlation analysis of trait scores before and after augmentation. This will help confirm that the observed improvements are not due to label noise. revision: yes
-
Referee: [Results tables and ablation study] No error bars, standard deviations across random seeds, or statistical significance tests (e.g., paired t-test or McNemar) are reported for the BA improvements (+0.0573 and +0.0968). This omission makes it impossible to determine whether the observed lifts exceed experimental variability, especially given the free parameters in LLM generation and distillation temperature.
Authors: We agree that including measures of variability and statistical tests is essential for robust reporting. In the revised manuscript, we will rerun the experiments with multiple random seeds (e.g., 5 seeds) and report standard deviations for the balanced accuracy scores. Additionally, we will include paired t-tests or McNemar's test to assess the statistical significance of the improvements over the BCE baseline. This will provide clearer evidence that the gains are reliable. revision: yes
-
Referee: [Ablation study section] The ablation study is described as ensuring “fair comparisons,” yet it does not include a control condition that isolates label fidelity (e.g., comparing performance on PIGA data vs. human-verified translations or measuring trait-score correlation before/after augmentation). This leaves open the possibility that gains arise from altered label distributions rather than the CLAD mechanism.
Authors: The ablation study in the current manuscript compares various configurations of our proposed method, including with and without PIGA and CLAD, to demonstrate their contributions. However, we recognize the value in explicitly isolating the effect of label fidelity. We will revise the ablation study to incorporate additional controls, such as trait-score correlations pre- and post-augmentation and, where feasible, performance comparisons on a small set of human-verified translations. This will better isolate the contributions of the CLAD mechanism. revision: partial
Circularity Check
No significant circularity in empirical ML evaluation
full rationale
This is an applied machine learning paper proposing data augmentation via LLM (PIGA) and a distillation training method (CLAD) for multilingual personality recognition. All performance claims are grounded in direct measurements of balanced accuracy on held-out test sets from the Essays and Kaggle datasets, with comparisons to external baselines such as standard BCE. No equations, derivations, uniqueness theorems, or fitted parameters are presented that reduce to the inputs by construction. The evaluation relies on external benchmarks rather than self-referential logic, satisfying the default expectation of no circularity for empirical studies.
Axiom & Free-Parameter Ledger
free parameters (2)
- LLM generation hyperparameters
- Distillation temperature and loss weights
axioms (1)
- domain assumption Personality traits are stable across languages and cultures when expressed in text
Reference graph
Works this paper leans on
-
[1]
A survey on personality-aware recommendation systems,
S. Dhelim, N. Aung, M. A. Bouras, H. Ning, and E. Cambria, “A survey on personality-aware recommendation systems,”Artificial Intelligence Review, vol. 55, no. 3, p. 2409–2454, Sep. 2021. [Online]. Available: http://dx.doi.org/10.1007/s10462-021-10063-7
-
[2]
The power of personalization: A systematic review of personality-adaptive chatbots,
T. Ait Baha, M. El Hajji, Y . Es-Saady, and H. Fadili, “The power of personalization: A systematic review of personality-adaptive chatbots,” SN Computer Science, vol. 4, no. 5, Aug. 2023. [Online]. Available: http://dx.doi.org/10.1007/s42979-023-02092-6
-
[3]
Can llm-generated misinformation be detected?
C. Chen and K. Shu, “Can llm-generated misinformation be detected?”
-
[4]
Can llm-generated misinformation be detected?arXiv preprint arXiv:2309.13788, 2023
[Online]. Available: https://arxiv.org/abs/2309.13788
-
[5]
Z. R. Tam, C.-K. Wu, Y .-L. Tsai, C.-Y . Lin, H.-y. Lee, and Y .-N. Chen, “Let me speak freely? a study on the impact of format restrictions on performance of large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2408.02442
-
[6]
J. J. Tan, B.-H. Kwan, D. W.-K. Ng, Y .-C. Hum, A. Mokraoui, and S.-Y . Lo, “Prompting-in-a-series: Psychology-informed contents and embeddings for personality recognition with decoder-only models,” IEEE Transactions on Computational Social Systems, p. 1–15, 2025. [Online]. Available: http://dx.doi.org/10.1109/TCSS.2025.3593323
-
[7]
Ptdlrec: A recommendation model integrating personality traits and deep learning,
X. Wang, B. Li, J. Dong, Z. Lin, and X. Xing, “Ptdlrec: A recommendation model integrating personality traits and deep learning,”Neurocomputing, vol. 652, p. 131083, Nov. 2025. [Online]. Available: http://dx.doi.org/10.1016/j.neucom.2025.131083
-
[8]
P. Hosseini, I. Castro, I. Ghinassi, and M. Purver, “Efficient solutions for an intriguing failure of llms: Long context window does not mean llms can analyze long sequences flawlessly,” 2024. [Online]. Available: https://arxiv.org/abs/2408.01866
-
[9]
The structure of phenotypic personality traits
L. R. Goldberg, “The structure of phenotypic personality traits.”Amer- ican Psychologist, vol. 48, pp. 26–34, 1993
1993
-
[10]
The myers-briggs type indicator: Manual (1962)
I. B. Myers, “The myers-briggs type indicator: Manual (1962).” 1962
1962
-
[11]
Myers-briggs type indicator (mbti),
A. Furnham, “Myers-briggs type indicator (mbti),”Encyclopedia of Personality and Individual Differences, pp. 1–4, 2017
2017
-
[12]
The big- 2/rose model of online personality,
G. I. Simari, M. V . Martinez, F. R. Gallo, and M. A. Falappa, “The big- 2/rose model of online personality,”Cognitive Computation, vol. 13, pp. 1198–1214, 9 2021
2021
-
[13]
Multimodal emotion fusion mechanism and empathetic responses in companion robots,
X. Liu, Q. Lv, J. Li, S. Song, and A. Cangelosi, “Multimodal emotion fusion mechanism and empathetic responses in companion robots,”IEEE Transactions on Cognitive and Developmental Systems, vol. 17, no. 2, pp. 271–286, 2025
2025
-
[14]
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications
P. Sahoo, A. K. Singh, S. Saha, V . Jain, S. Mondal, and A. Chadha, “A systematic survey of prompt engineering in large language models: Techniques and applications,” 2024. [Online]. Available: https://arxiv.org/abs/2402.07927
work page internal anchor Pith review arXiv 2024
-
[15]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskeveret al., “Language models are unsupervised multitask learners,”OpenAI blog, vol. 1, no. 8, p. 9, 2019
2019
-
[16]
Language Models are Few-Shot Learners
T. B. Brown, “Language models are few-shot learners,”arXiv preprint arXiv:2005.14165, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[17]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,”Advances in neural information processing systems, vol. 35, pp. 24 824–24 837, 2022
2022
-
[18]
Enhancing zero-shot chain-of-thought reasoning in large language models through logic,
X. Zhao, M. Li, W. Lu, C. Weber, J. H. Lee, K. Chu, and S. Wermter, “Enhancing zero-shot chain-of-thought reasoning in large language models through logic,”arXiv preprint arXiv:2309.13339, 2023
-
[19]
A review of current trends, techniques, and challenges in large language models (llms),
R. Patil and V . Gudivada, “A review of current trends, techniques, and challenges in large language models (llms),”Applied Sciences, vol. 14, no. 5, p. 2074, Mar. 2024. [Online]. Available: http: //dx.doi.org/10.3390/app14052074
-
[20]
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Z. Han, C. Gao, J. Liu, J. Zhang, and S. Q. Zhang, “Parameter-efficient fine-tuning for large models: A comprehensive survey,” 2024. [Online]. Available: https://arxiv.org/abs/2403.14608
work page internal anchor Pith review arXiv 2024
-
[21]
dLoRA: Dynamically orchestrating requests and adapters for LoRA LLM serving,
B. Wu, R. Zhu, Z. Zhang, P. Sun, X. Liu, and X. Jin, “dLoRA: Dynamically orchestrating requests and adapters for LoRA LLM serving,” in18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). USENIX Association, 2024, pp. 911–
2024
-
[22]
Available: https://www.usenix.org/conference/osdi24/ presentation/wu-bingyang
[Online]. Available: https://www.usenix.org/conference/osdi24/ presentation/wu-bingyang
-
[23]
Heinrich Peters and Sandra C Matz
H. Peters, M. Cerf, and S. C. Matz, “Large language models can infer personality from free-form user interactions,” 2024. [Online]. Available: https://arxiv.org/abs/2405.13052
-
[24]
Rao, H., Leung, C., and Miao, C
H. Rao, C. Leung, and C. Miao, “Can chatgpt assess human personalities? a general evaluation framework,” 2023. [Online]. Available: https://arxiv.org/abs/2303.01248
-
[25]
Z. Wen, Y . Yang, J. Cao, H. Sun, R. Yang, and S. Liu, “Self-assessment, exhibition, and recognition: a review of personality in large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2406.17624
-
[26]
Is chatgpt a good personality recognizer? a preliminary study,
Y . Ji, W. Wu, H. Zheng, Y . Hu, X. Chen, and L. He, “Is chatgpt a good personality recognizer? a preliminary study,” 2023. [Online]. Available: https://arxiv.org/abs/2307.03952
-
[27]
Teaching large language models to translate with comparison,
J. Zeng, F. Meng, Y . Yin, and J. Zhou, “Teaching large language models to translate with comparison,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 17, p. 19488–19496, Mar. 2024. [Online]. Available: http://dx.doi.org/10.1609/aaai.v38i17.29920
-
[28]
Lost in the Middle: How Language Models Use Long Contexts
Z. He, T. Liang, W. Jiao, Z. Zhang, Y . Yang, R. Wang, Z. Tu, S. Shi, and X. Wang, “Exploring human-like translation strategy with large language models,”Transactions of the Association for Computational Linguistics, vol. 12, p. 229–246, 2024. [Online]. Available: http://dx.doi.org/10.1162/tacl a 00642
work page internal anchor Pith review doi:10.1162/tacl 2024
-
[29]
J. Yan, P. Yan, Y . Chen, J. Li, X. Zhu, and Y . Zhang, “Gpt-4 vs. human translators: A comprehensive evaluation of translation quality across languages, domains, and expertise levels,” 2024. [Online]. Available: https://arxiv.org/abs/2407.03658
-
[30]
T. Kocmi and C. Federmann, “Large language models are state-of- the-art evaluators of translation quality,” 2023. [Online]. Available: https://arxiv.org/abs/2302.14520
-
[31]
Examining sentiment analysis for low-resource languages with data augmentation techniques,
G. Thakkar, N. M. Preradovi ´c, and M. Tadi ´c, “Examining sentiment analysis for low-resource languages with data augmentation techniques,” Eng, vol. 5, no. 4, p. 2920–2942, Nov. 2024. [Online]. Available: http://dx.doi.org/10.3390/eng5040152
-
[32]
Leveraging large language models for code-mixed data augmentation in sentiment analysis,
L. Zeng, “Leveraging large language models for code-mixed data augmentation in sentiment analysis,” 2024. [Online]. Available: https://arxiv.org/abs/2411.00691
-
[33]
Efficient toxic content detection by bootstrapping and distilling large language models,
J. Zhang, Q. Wu, Y . Xu, C. Cao, Z. Du, and K. Psounis, “Efficient toxic content detection by bootstrapping and distilling large language models,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 19, p. 21779–21787, Mar. 2024. [Online]. Available: http://dx.doi.org/10.1609/aaai.v38i19.30178
-
[34]
Distilling the Knowledge in a Neural Network
G. E. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,”ArXiv, vol. abs/1503.02531, 2015. [Online]. Available: https://api.semanticscholar.org/CorpusID:7200347
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[35]
Can students beyond the teacher? distilling knowledge from teacher’s bias,
J. Zhang, Y . Gao, R. Liu, X. Cheng, H. Zhang, and S. Chen, “Can students beyond the teacher? distilling knowledge from teacher’s bias,”
-
[36]
Available: https://arxiv.org/abs/2412.09874
[Online]. Available: https://arxiv.org/abs/2412.09874
-
[37]
Leveraging logit uncertainty for better knowledge distillation,
Z. Guo, D. Wang, Q. He, and P. Zhang, “Leveraging logit uncertainty for better knowledge distillation,”Scientific Reports, vol. 14, no. 1, Dec. 2024. [Online]. Available: http://dx.doi.org/10. 1038/s41598-024-82647-6
2024
-
[38]
Decoupled knowledge distillation,
B. Zhao, Q. Cui, R. Song, Y . Qiu, and J. Liang, “Decoupled knowledge distillation,” 2022. [Online]. Available: https://arxiv.org/abs/2203.08679
-
[39]
S. Zhu, R. Shang, B. Yuan, W. Zhang, W. Li, Y . Li, and L. Jiao, “Dynamickd: An effective knowledge distillation via dynamic entropy correction-based distillation for gap optimizing,”Pattern Recognition, vol. 153, p. 110545, Sep. 2024. [Online]. Available: http://dx.doi.org/10.1016/j.patcog.2024.110545
-
[40]
One- teacher and multiple-student knowledge distillation on sentiment classification,
X. Chang, S. Y . M. Lee, S. Zhu, S. Li, and G. Zhou, “One- teacher and multiple-student knowledge distillation on sentiment classification,” inProceedings of the 29th International Conference on Computational Linguistics, N. Calzolari, C.-R. Huang, H. Kim, J. Pustejovsky, L. Wanner, K.-S. Choi, P.-M. Ryu, H.-H. Chen, L. Donatelli, H. Ji, S. Kurohashi, P. ...
2022
-
[41]
Muti- modal emotion recognition via hierarchical knowledge distillation,
T. Sun, Y . Wei, J. Ni, Z. Liu, X. Song, Y . Wang, and L. Nie, “Muti- modal emotion recognition via hierarchical knowledge distillation,” IEEE Transactions on Multimedia, vol. 26, pp. 9036–9046, 2024
2024
-
[42]
M. Ramezani, M.-R. Feizi-Derakhshi, and M.-A. Balafar, “Text-based automatic personality prediction using kgrat-net: a knowledge graph attention network classifier,”Scientific Reports, vol. 12, no. 1, Dec. 2022. [Online]. Available: http://dx.doi.org/10.1038/s41598-022-25955-z
-
[43]
Transentgat: A sentiment-based lexical psycholinguistic graph attention network for personality prediction,
S. S. Bajestani, M. M. Khalilzadeh, M. Azarnoosh, and H. R. Kobravi, “Transentgat: A sentiment-based lexical psycholinguistic graph attention network for personality prediction,”IEEE Access, vol. 12, pp. 59 630– 59 642, 2024
2024
-
[44]
Eerpd: Leveraging emotion and emotion regulation for improving personality detection,
Z. Li, D. Zhu, Q. Ma, W. Xiong, and S. Li, “Eerpd: Leveraging emotion and emotion regulation for improving personality detection,”
-
[45]
Available: https://arxiv.org/abs/2406.16079
[Online]. Available: https://arxiv.org/abs/2406.16079
-
[46]
J. J. Tan, B.-H. Kwan, D. W.-K. Ng, and Y . C. Hum, “Psychology- informed natural language understanding: Integrating personality and emotion-aware features for comprehensive sentiment analysis and depression detection,”Pertanika Journal of Science & Technology, vol. 33, no. S4, December 2025. [Online]. Available: https: //doi.org/10.47836/pjst.33.S4.04
-
[47]
essays-big5 (revision ac1977f),
J. J. Tan, “essays-big5 (revision ac1977f),” 2025. [Online]. Available: https://huggingface.co/datasets/jingjietan/essays-big5
2025
-
[48]
kaggle-mbti (revision 46036ad),
——, “kaggle-mbti (revision 46036ad),” 2025. [Online]. Available: https://huggingface.co/datasets/jingjietan/kaggle-mbti
2025
-
[49]
J. J. Tan, B.-H. Kwan, D. W.-K. Ng, and Y .-C. Hum, “Adaptive focal loss with personality stratification for stably mitigating hard class imbalance in multi-dimensional personality recognition,”Scientific Reports, vol. 15, no. 1, Nov. 2025. [Online]. Available: http: //dx.doi.org/10.1038/s41598-025-22853-y
-
[50]
essays all-minilm-l6-v2,
J. J. Tan, “essays all-minilm-l6-v2,” https://huggingface.co/jingjietan/ essays all-MiniLM-L6-v2, 2025, hugging Face
2025
-
[51]
kaggle-all-minilm-l6-v2,
——, “kaggle-all-minilm-l6-v2,” https://huggingface.co/jingjietan/ kaggle-all-MiniLM-L6-v2, 2025, hugging Face
2025
-
[52]
Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers,
W. Wang, F. Wei, L. Dong, H. Bao, N. Yang, and M. Zhou, “Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers,” inAdvances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33. Curran Associates, Inc., 2020, pp. 5776–5788. [Online]. Available: ht...
2020
-
[53]
Mpnet: Masked and permuted pre-training for language understanding,
K. Song, X. Tan, T. Qin, J. Lu, and T.-Y . Liu, “Mpnet: Masked and permuted pre-training for language understanding,” in Advances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33. Curran Associates, Inc., 2020, pp. 16 857–16 867. [Online]. Available: https://proceedings.neurips.cc/paper ...
2020
-
[54]
Linguistic measures of personality in group discussions,
L. A. Spitzley, X. Wang, X. Chen, J. K. Burgoon, N. E. Dunbar, and S. Ge, “Linguistic measures of personality in group discussions,” Frontiers in Psychology, vol. 13, Sep. 2022. [Online]. Available: http://dx.doi.org/10.3389/fpsyg.2022.887616
-
[55]
Bottom-up and top-down: Predicting personality with psycholinguistic and language model features,
Y . Mehta, S. Fatehi, A. Kazameini, C. Stachl, E. Cambria, and S. Eetemadi, “Bottom-up and top-down: Predicting personality with psycholinguistic and language model features,” in2020 IEEE International Conference on Data Mining (ICDM). IEEE, Nov. 2020, p. 1184–1189. [Online]. Available: http://dx.doi.org/10.1109/ ICDM50108.2020.00146
-
[56]
Definite and nondefinite superlatives and npi licensing,
S. Herdan and Y . Sharvit, “Definite and nondefinite superlatives and npi licensing,”Syntax, vol. 9, no. 1, p. 1–31, Apr. 2006. [Online]. Available: http://dx.doi.org/10.1111/j.1467-9612.2006.00082.x
-
[57]
A. Shah, P. Ranka, U. Dedhia, S. Prasad, S. Muni, and K. Bhowmick, “Detecting and unmasking ai-generated texts through explainable artificial intelligence using stylistic features,”International Journal of Advanced Computer Science and Applications, vol. 14, no. 10, 2023. [Online]. Available: http://dx.doi.org/10.14569/IJACSA.2023.01410110
-
[58]
Lexical richness viewed through lexical diversity, density, and sophistication,
W. Zheng, “Lexical richness viewed through lexical diversity, density, and sophistication,”Digital Scholarship in the Humanities, Mar. 2025. [Online]. Available: http://dx.doi.org/10.1093/llc/fqaf023
-
[59]
Multilingual E5 Text Embeddings: A Technical Report
L. Wang, N. Yang, X. Huang, L. Yang, R. Majumder, and F. Wei, “Multilingual e5 text embeddings: A technical report,” 2024. [Online]. Available: https://arxiv.org/abs/2402.05672
work page internal anchor Pith review arXiv 2024
-
[60]
Qwen3 embedding: Advancing text embedding and reranking through foundation models,
Y . Zhang, M. Li, D. Long, X. Zhang, H. Lin, B. Yang, P. Xie, A. Yang, D. Liu, J. Lin, F. Huang, and J. Zhou, “Qwen3 embedding: Advancing text embedding and reranking through foundation models,”
-
[61]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
[Online]. Available: https://arxiv.org/abs/2506.05176
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
Embeddinggemma: Powerful and lightweight text representations,
H. S. Vera, S. Dua, B. Zhang, D. Salz, R. Mullins, S. R. Panyam, S. Smoot, I. Naim, J. Zou, F. Chen, D. Cer, A. Lisak, M. Choi, L. Gonzalez, O. Sanseviero, G. Cameron, I. Ballantyne, K. Black, K. Chen, W. Wang, Z. Li, G. Martins, J. Lee, M. Sherwood, and et. al., “Embeddinggemma: Powerful and lightweight text representations,”
-
[63]
EmbeddingGemma: Powerful and Lightweight Text Representations
[Online]. Available: https://arxiv.org/abs/2509.20354
work page internal anchor Pith review arXiv
-
[64]
Language- agnostic BERT sentence embedding,
F. Feng, Y . Yang, D. Cer, N. Arivazhagan, and W. Wang, “Language- agnostic BERT sentence embedding,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), S. Muresan, P. Nakov, and A. Villavicencio, Eds. Dublin, Ireland: Association for Computational Linguistics, May 2022, pp. 878–891. [Online]...
2022
-
[65]
M3-embedding: Multi-linguality, multi-functionality, multi-granularity text embeddings through self-knowledge distillation,
J. Chen, S. Xiao, P. Zhang, K. Luo, D. Lian, and Z. Liu, “M3-embedding: Multi-linguality, multi-functionality, multi-granularity text embeddings through self-knowledge distillation,” inFindings of the Association for Computational Linguistics: ACL 2024, L.-W. Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand: Association for Computational Linguisti...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.