Recognition: unknown
Adaptive Candidate Point Thompson Sampling for High-Dimensional Bayesian Optimization
Pith reviewed 2026-05-10 17:10 UTC · model grok-4.3
The pith
Adaptive Candidate Thompson Sampling improves high-dimensional Bayesian optimization by generating candidates in gradient-guided subspaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
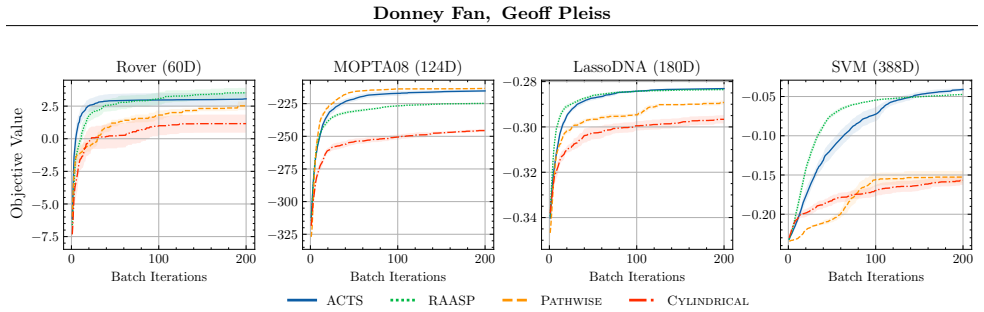
ACTS generates candidate points for Thompson sampling by restricting the search to subspaces aligned with the gradient of a draw from the surrogate posterior, thereby increasing candidate density in regions that are likely to contain high-value points without requiring a new global GP approximation.
What carries the argument
Adaptive Candidate Thompson Sampling (ACTS), which adaptively reduces the search space by generating candidates in subspaces guided by the gradient of a surrogate model sample.
If this is right
- Produces higher-quality samples of the objective maximizer than fixed-candidate Thompson sampling.
- Delivers improved optimization performance on synthetic and real-world benchmarks.
- Functions as a drop-in replacement that combines with existing trust-region or local-approximation variants of Thompson sampling.
- Mitigates the exponential sparsity of candidate sets as input dimension grows.
- Maintains compatibility with any Gaussian-process surrogate without altering its training or inference routine.
Where Pith is reading between the lines
- The same gradient-guided subspace idea could be applied to other posterior-sampling acquisition functions beyond pure Thompson sampling.
- In extremely high dimensions the method may still require an outer dimensionality-reduction step to keep gradient estimation stable.
- Because the subspace choice depends on a single sample, repeated independent runs of ACTS on the same problem could be used to quantify uncertainty in the selected region.
- The approach suggests a general design pattern: replace static discretization with cheap, model-derived local structure whenever sampling from an intractable posterior.
Load-bearing premise
Subspaces chosen from the gradient of a surrogate sample will reliably contain better maximizer locations without systematically missing the global optimum or introducing bias.
What would settle it
A high-dimensional benchmark function where running ACTS repeatedly yields lower final values or fails to locate a known global maximum compared with standard fixed-candidate Thompson sampling.
Figures


















read the original abstract
In Bayesian optimization, Thompson sampling selects the evaluation point by sampling from the posterior distribution over the objective function maximizer. Because this sampling problem is intractable for Gaussian process (GP) surrogates, the posterior distribution is typically restricted to fixed discretizations (i.e., candidate points) that become exponentially sparse as dimensionality increases. While previous works aim to increase candidate point density through scalable GP approximations, our orthogonal approach increases density by adaptively reducing the search space during sampling. Specifically, we introduce Adaptive Candidate Thompson Sampling (ACTS), which generates candidate points in subspaces guided by the gradient of a surrogate model sample. ACTS is a simple drop-in replacement for existing TS methods -- including those that use trust regions or other local approximations -- producing better samples of maxima and improved optimization across synthetic and real-world benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Adaptive Candidate Thompson Sampling (ACTS) for high-dimensional Bayesian optimization with Gaussian process surrogates. Thompson sampling is made tractable by restricting the posterior over the maximizer to a discrete candidate set; ACTS adaptively constructs this set inside low-dimensional subspaces aligned with the gradient of a single draw from the GP posterior. The method is positioned as an orthogonal, drop-in replacement for existing TS variants (including trust-region approaches) that yields higher-quality maximizer samples and better optimization performance on synthetic and real-world benchmarks.
Significance. If the central claim holds, ACTS would provide a lightweight, assumption-light way to increase candidate density in high dimensions without relying on scalable GP approximations or fixed trust regions. The drop-in compatibility and reported gains on both synthetic and real benchmarks would make it a practical contribution to the BO literature, particularly if the subspace construction can be shown to preserve coverage of the global argmax.
major comments (2)
- [Abstract] The abstract states that subspaces are 'guided by the gradient of a surrogate model sample' and that this produces 'better samples of maxima.' However, no argument or bound is supplied showing that a single posterior sample's gradient direction reliably intersects the basin of the global maximizer rather than a local mode. In multimodal high-dimensional landscapes this is load-bearing for the claim that ACTS is unbiased relative to standard TS.
- [Method / Experiments] The skeptic note highlights that the subspace radius and selection rule are not shown to guarantee intersection with the global optimum when modes are separated by distances larger than the local curvature scale. If the full manuscript contains no theoretical coverage guarantee or ablation on deliberately multimodal test functions (e.g., with well-separated modes), the empirical improvements cannot be attributed to the method rather than to the particular benchmark suite.
minor comments (2)
- [Abstract] The abstract claims ACTS is 'parameter-free' relative to trust-region methods, yet the subspace construction necessarily introduces at least a radius or dimensionality-reduction hyper-parameter; this should be clarified and compared explicitly.
- [Method] Notation for the surrogate sample, gradient, and candidate-set construction should be introduced with a short equation or pseudocode block early in the method section to make the drop-in replacement property immediately verifiable.
Simulated Author's Rebuttal
We thank the referee for their constructive comments and the opportunity to clarify aspects of our work. We address each major comment below and indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] The abstract states that subspaces are 'guided by the gradient of a surrogate model sample' and that this produces 'better samples of maxima.' However, no argument or bound is supplied showing that a single posterior sample's gradient direction reliably intersects the basin of the global maximizer rather than a local mode. In multimodal high-dimensional landscapes this is load-bearing for the claim that ACTS is unbiased relative to standard TS.
Authors: We appreciate this observation. The original manuscript does not provide a theoretical bound or argument for reliable intersection with the global maximizer's basin, as the approach is heuristic. We do not claim that ACTS is unbiased relative to standard TS; it is an approximation method that adaptively densifies candidates in subspaces likely to contain high-value regions based on posterior samples. In the revised version, we have modified the abstract to avoid any implication of unbiasedness and added a paragraph in the discussion section acknowledging the limitations in highly multimodal landscapes and the reliance on empirical performance. revision: yes
-
Referee: [Method / Experiments] The skeptic note highlights that the subspace radius and selection rule are not shown to guarantee intersection with the global optimum when modes are separated by distances larger than the local curvature scale. If the full manuscript contains no theoretical coverage guarantee or ablation on deliberately multimodal test functions (e.g., with well-separated modes), the empirical improvements cannot be attributed to the method rather than to the particular benchmark suite.
Authors: We agree that no theoretical coverage guarantee is provided, and deriving one for general cases remains an open challenge. The manuscript includes experiments on multimodal functions like the 6D Hartmann function, but we acknowledge the lack of specific ablations on functions with well-separated modes. In the revised manuscript, we have included an additional ablation study using a high-dimensional multimodal function with separated modes to demonstrate the method's behavior. We have also expanded the description of the subspace radius and selection rule in Section 3 to clarify their design choices. However, we maintain that the empirical gains on the reported benchmarks are attributable to the adaptive candidate construction, as evidenced by comparisons with standard TS variants. revision: partial
- Providing a formal theoretical guarantee that the gradient of a single posterior sample reliably leads to the global maximizer in arbitrary multimodal high-dimensional functions.
Circularity Check
No circularity: new adaptive subspace construction for TS is independent of its claimed performance
full rationale
The paper introduces ACTS as an algorithmic modification to Thompson sampling that restricts candidate generation to gradient-guided subspaces of a single posterior draw. No equations, fitted parameters, or predictions are presented that reduce to the method's own inputs by construction. The central claims rest on empirical benchmarks rather than a self-referential derivation or uniqueness theorem. Self-citations, if present in the full text, are not load-bearing for the core construction, which is described as a drop-in replacement orthogonal to prior scalable GP or trust-region approaches. The derivation chain is therefore self-contained and does not exhibit any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Gaussian-process surrogates provide usable gradient information for guiding subspace selection.
- ad hoc to paper Reducing the candidate set to gradient-guided subspaces still yields representative samples of the posterior maximizer.
Reference graph
Works this paper leans on
-
[1]
Unexpected improvements to expected improvement for B ayesian optimization
Sebastian Ament, Samuel Daulton, David Eriksson, Maximilian Balandat, and Eytan Bakshy. Unexpected improvements to expected improvement for B ayesian optimization. In Advances in Neural Information Processing Systems, volume 36, pages 20577--20612. Curran Associates, Inc., 2023
2023
-
[2]
Botorch: A framework for efficient M onte- C arlo B ayesian optimization
Maximilian Balandat, Brian Karrer, Daniel Jiang, Samuel Daulton, Ben Letham, Andrew G Wilson, and Eytan Bakshy. Botorch: A framework for efficient M onte- C arlo B ayesian optimization. In Advances in Neural Information Processing Systems, volume 33, pages 21524--21538. Curran Associates, Inc., 2020
2020
-
[3]
B ayesian optimization with safety constraints: safe and automatic parameter tuning in robotics
Felix Berkenkamp, Andreas Krause, and Angela P Schoellig. B ayesian optimization with safety constraints: safe and automatic parameter tuning in robotics. Machine Learning, 112 0 (10): 0 3713--3747, 2023
2023
-
[4]
Sch \"o n, Jan-Willem van Wingerden, and Michel Verhaegen
Hildo Bijl, Thomas B. Sch \"o n, Jan-Willem van Wingerden, and Michel Verhaegen. A sequential M onte C arlo approach to T hompson sampling for B ayesian optimization, 2017
2017
-
[5]
Segler, and Alain C
Nathan Brown, Marco Fiscato, Marwin H.S. Segler, and Alain C. Vaucher. Guacamol: Benchmarking models for de novo molecular design. Journal of Chemical Information and Modeling, 59 0 (3): 0 1096--1108, Mar 2019. ISSN 1549-9596
2019
-
[6]
Targeted materials discovery using B ayesian algorithm execution
Sathya R Chitturi, Akash Ramdas, Yue Wu, Brian Rohr, Stefano Ermon, Jennifer Dionne, Felipe H da Jornada, Mike Dunne, Christopher Tassone, Willie Neiswanger, et al. Targeted materials discovery using B ayesian algorithm execution. npj Computational Materials, 10 0 (1): 0 156, 2024
2024
-
[7]
Multi-objective B ayesian optimization over high-dimensional search spaces
Samuel Daulton, David Eriksson, Maximilian Balandat, and Eytan Bakshy. Multi-objective B ayesian optimization over high-dimensional search spaces. In Proceedings of the Thirty-Eighth Conference on Uncertainty in Artificial Intelligence, volume 180 of Proceedings of Machine Learning Research, pages 507--517. PMLR, 01--05 Aug 2022
2022
-
[8]
PILCO : A model-based and data-efficient approach to policy search
Marc Deisenroth and Carl E Rasmussen. PILCO : A model-based and data-efficient approach to policy search. In International Conference on Machine Learning, pages 465--472, 2011
2011
-
[9]
Toward autonomous additive manufacturing: B ayesian optimization on a 3D printer
James R Deneault, Jorge Chang, Jay Myung, Daylond Hooper, Andrew Armstrong, Mark Pitt, and Benji Maruyama. Toward autonomous additive manufacturing: B ayesian optimization on a 3D printer. MRS Bulletin, 46: 0 566--575, 2021
2021
-
[10]
High-dimensional Bayesian optimization with sparse axis-aligned subspaces
David Eriksson and Martin Jankowiak. High-dimensional Bayesian optimization with sparse axis-aligned subspaces. In Uncertainty in Artificial Intelligence, volume 161 of Proceedings of Machine Learning Research, pages 493--503. PMLR, 27--30 Jul 2021
2021
-
[11]
Scalable constrained B ayesian optimization
David Eriksson and Matthias Poloczek. Scalable constrained B ayesian optimization. In Proceedings of The 24th International Conference on Artificial Intelligence and Statistics, volume 130 of Proceedings of Machine Learning Research, pages 730--738. PMLR, 13--15 Apr 2021
2021
-
[12]
Scalable global optimization via local B ayesian optimization
David Eriksson, Michael Pearce, Jacob Gardner, Ryan D Turner, and Matthias Poloczek. Scalable global optimization via local B ayesian optimization. Advances in Neural Information Processing Systems, 32, 2019
2019
-
[13]
Gpytorch: Blackbox matrix-matrix G aussian process inference with gpu acceleration
Jacob Gardner, Geoff Pleiss, Kilian Q Weinberger, David Bindel, and Andrew G Wilson. Gpytorch: Blackbox matrix-matrix G aussian process inference with gpu acceleration. In Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018
2018
-
[14]
B ayesian optimization
Roman Garnett. B ayesian optimization . Cambridge University Press, 2023
2023
-
[15]
Vanilla B ayesian optimization performs great in high dimensions
Carl Hvarfner, Erik Orm Hellsten, and Luigi Nardi. Vanilla B ayesian optimization performs great in high dimensions. In Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pages 20793--20817. PMLR, 21--27 Jul 2024
2024
-
[16]
Large-scale multi-disciplinary mass optimization in the auto industry
Donald R Jones. Large-scale multi-disciplinary mass optimization in the auto industry. In MOPTA 2008 Conference (20 August 2008), volume 64, 2008
2008
-
[17]
Efficient global optimization of expensive black-box functions
Donald R Jones, Matthias Schonlau, and William J Welch. Efficient global optimization of expensive black-box functions. Journal of Global optimization, 13: 0 455--492, 1998
1998
-
[18]
Parallelised B ayesian optimisation via T hompson sampling
Kirthevasan Kandasamy, Akshay Krishnamurthy, Jeff Schneider, and Barnab \'a s P \'o czos. Parallelised B ayesian optimisation via T hompson sampling. In Artificial Intelligence and Statistics, 2018
2018
-
[19]
Local latent space B ayesian optimization over structured inputs
Natalie Maus, Haydn Jones, Juston Moore, Matt J Kusner, John Bradshaw, and Jacob Gardner. Local latent space B ayesian optimization over structured inputs. In Advances in Neural Information Processing Systems, volume 35, pages 34505--34518. Curran Associates, Inc., 2022
2022
-
[20]
On B ayesian methods for seeking the extremum
Jonas Mo c kus. On B ayesian methods for seeking the extremum. In Optimization Techniques IFIP Technical Conference Novosibirsk, pages 400--404, 1975
1975
-
[21]
Local policy search with B ayesian optimization
Sarah M \"u ller, Alexander von Rohr, and Sebastian Trimpe. Local policy search with B ayesian optimization. Advances in Neural Information Processing Systems, 34: 0 20708--20720, 2021
2021
-
[22]
Bayesian learning for neural networks, volume 118
Radford M Neal. Bayesian learning for neural networks, volume 118. Springer Scionce & Business Media, 2012
2012
-
[23]
Local B ayesian optimization via maximizing probability of descent
Quan Nguyen, Kaiwen Wu, Jacob Gardner, and Roman Garnett. Local B ayesian optimization via maximizing probability of descent. Advances in neural information processing systems, 35: 0 13190--13202, 2022
2022
-
[24]
Increasing the scope as you learn: Adaptive B ayesian optimization in nested subspaces
Leonard Papenmeier, Luigi Nardi, and Matthias Poloczek. Increasing the scope as you learn: Adaptive B ayesian optimization in nested subspaces. In Advances in Neural Information Processing Systems, volume 35, pages 11586--11601. Curran Associates, Inc., 2022
2022
-
[25]
Exploring exploration in bayesian optimization
Leonard Papenmeier, Nuojin Cheng, Stephen Becker, and Luigi Nardi. Exploring exploration in bayesian optimization. In Proceedings of the Forty-First Conference on Uncertainty in Artificial Intelligence, UAI '25. JMLR.org, 2025
2025
-
[26]
Constant-time predictive distributions for G aussian processes
Geoff Pleiss, Jacob Gardner, Kilian Weinberger, and Andrew Gordon Wilson. Constant-time predictive distributions for G aussian processes. In Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pages 4114--4123. PMLR, 10--15 Jul 2018
2018
-
[27]
Fast matrix square roots with applications to G aussian processes and B ayesian optimization
Geoff Pleiss, Martin Jankowiak, David Eriksson, Anil Damle, and Jacob Gardner. Fast matrix square roots with applications to G aussian processes and B ayesian optimization. Advances in Neural Information Processing Systems, 33, 2020
2020
-
[28]
Random features for large-scale kernel machines
Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines. In Advances in Neural Information Processing Systems, volume 20. Curran Associates, Inc., 2007
2007
-
[29]
Cylindrical T hompson sampling for high-dimensional B ayesian optimization
Bahador Rashidi, Kerrick Johnstonbaugh, and Chao Gao. Cylindrical T hompson sampling for high-dimensional B ayesian optimization. In Proceedings of The 27th International Conference on Artificial Intelligence and Statistics, volume 238 of Proceedings of Machine Learning Research, pages 3502--3510. PMLR, 02--04 May 2024
2024
-
[30]
Carl Edward Rasmussen and Christopher K. I. Williams. Gaussian Processes for Machine Learning. MIT Press, 2006
2006
-
[31]
Regis and Christine A
Rommel G. Regis and Christine A. Shoemaker. Combining radial basis function surrogates and dynamic coordinate search in high-dimensional expensive black-box optimization. Engineering Optimization, 45 0 (5): 0 529--555, 2013
2013
-
[32]
qpots: Efficient batch multiobjective B ayesian optimization via pareto optimal thompson sampling
Ashwin Renganathan and Kade Carlson. qpots: Efficient batch multiobjective B ayesian optimization via pareto optimal thompson sampling. In Proceedings of The 28th International Conference on Artificial Intelligence and Statistics, volume 258 of Proceedings of Machine Learning Research, pages 4051--4059. PMLR, 03--05 May 2025
2025
-
[33]
An information-theoretic analysis of T hompson sampling
Daniel Russo and Benjamin Van Roy. An information-theoretic analysis of T hompson sampling. Journal of Machine Learning Research, 17 0 (68): 0 1--30, 2016
2016
-
[34]
Learning to optimize via information-directed sampling
Daniel Russo and Benjamin Van Roy. Learning to optimize via information-directed sampling. In Advances in Neural Information Processing Systems, volume 27. Curran Associates, Inc., 2014
2014
-
[35]
Significance of gradient information in bayesian optimization
Shubhanshu Shekhar and Tara Javidi. Significance of gradient information in bayesian optimization. In Proceedings of The 24th International Conference on Artificial Intelligence and Statistics, volume 130 of Proceedings of Machine Learning Research, pages 2836--2844. PMLR, 13--15 Apr 2021
2021
-
[36]
Automated self-optimization, intensification, and scale-up of photocatalysis in flow
Aidan Slattery, Zhenghui Wen, Pauline Tenblad, Jes \'u s Sanjos \'e -Orduna, Diego Pintossi, Tim den Hartog, and Timothy No \"e l. Automated self-optimization, intensification, and scale-up of photocatalysis in flow. Science, 383 0 (6681): 0 eadj1817, 2024
2024
-
[37]
Practical B ayesian optimization of machine learning algorithms
Jasper Snoek, Hugo Larochelle, and Ryan P Adams. Practical B ayesian optimization of machine learning algorithms. Advances in neural information processing systems, 25, 2012
2012
-
[38]
G aussian process optimization in the bandit setting: no regret and experimental design
Niranjan Srinivas, Andreas Krause, Sham Kakade, and Matthias Seeger. G aussian process optimization in the bandit setting: no regret and experimental design. In International Conference on Machine Learning, pages 1015--1022, 2010
2010
-
[39]
Fast, precise T hompson sampling for B ayesian optimization, 2024
David Sweet. Fast, precise T hompson sampling for B ayesian optimization, 2024
2024
-
[40]
Freeze-thaw bayesian optimization
Kevin Swersky, Jasper Snoek, and Ryan Prescott Adams. Freeze-thaw bayesian optimization. arXiv preprint arXiv:1406.3896, 2014
-
[41]
Thompson
William R. Thompson. On the likelihood that one unknown probability exceeds another in view of the evidence of two samples. Biometrika, 25 0 (3/4): 0 285--294, 1933. ISSN 00063444
1933
-
[42]
Mujoco: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026--5033, 2012
2012
-
[43]
Lassobench: A high-dimensional hyperparameter optimization benchmark suite for lasso
Kenan S ehi\'c, Alexandre Gramfort, Joseph Salmon, and Luigi Nardi. Lassobench: A high-dimensional hyperparameter optimization benchmark suite for lasso. In Proceedings of the First International Conference on Automated Machine Learning, volume 188 of Proceedings of Machine Learning Research, pages 2/1--24. PMLR, 25--27 Jul 2022
2022
-
[44]
High-dimensional statistics: A non-asymptotic viewpoint
Martin J Wainwright. High-dimensional statistics: A non-asymptotic viewpoint. Cambridge University Press, 2019
2019
-
[45]
Batched large-scale bayesian optimization in high-dimensional spaces
Zi Wang, Clement Gehring, Pushmeet Kohli, and Stefanie Jegelka. Batched large-scale bayesian optimization in high-dimensional spaces. In Proceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics, volume 84 of Proceedings of Machine Learning Research, pages 745--754. PMLR, 09--11 Apr 2018
2018
-
[46]
Efficiently sampling functions from G aussian process posteriors
James Wilson, Viacheslav Borovitskiy, Alexander Terenin, Peter Mostowsky, and Marc Deisenroth. Efficiently sampling functions from G aussian process posteriors. In Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 10292--10302. PMLR, 13--18 Jul 2020
2020
-
[47]
Wilson, Viacheslav Borovitskiy, Alexander Terenin, Peter Mostowsky, and Marc Peter Deisenroth
James T. Wilson, Viacheslav Borovitskiy, Alexander Terenin, Peter Mostowsky, and Marc Peter Deisenroth. Pathwise conditioning of G aussian processes. Journal of Machine Learning Research, 22 0 (105): 0 1--47, 2021
2021
-
[48]
B ayesian optimization with gradients
Jian Wu, Matthias Poloczek, Andrew G Wilson, and Peter Frazier. B ayesian optimization with gradients. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017
2017
-
[49]
The behavior and convergence of local B ayesian optimization
Kaiwen Wu, Kyurae Kim, Roman Garnett, and Jacob Gardner. The behavior and convergence of local B ayesian optimization. Advances in neural information processing systems, 36: 0 73497--73523, 2023
2023
-
[50]
Improving sample efficiency of high dimensional B ayesian optimization with MCMC
Zeji Yi, Yunyue Wei, Chu Xin Cheng, Kaibo He, and Yanan Sui. Improving sample efficiency of high dimensional B ayesian optimization with MCMC . In Proceedings of the 6th Annual Learning for Dynamics & Control Conference, volume 242 of Proceedings of Machine Learning Research, pages 813--824. PMLR, 15--17 Jul 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.