Recognition: no theorem link
Synthesizing real-world distributions from high-dimensional Gaussian Noise with Fully Connected Neural Network
Pith reviewed 2026-05-10 17:06 UTC · model grok-4.3
The pith
A fully connected neural network with randomized loss turns high-dimensional Gaussian noise into synthetic copies of real tabular datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The fully connected neural network, when trained using a randomized loss on Gaussian noise, produces synthetic data that approximates target real-world distributions with reference MMD scores, outperforming state-of-the-art generative methods while requiring far less computation time across 25 tabular datasets.
What carries the argument
A fully connected neural network trained with a randomized loss function that maps high-dimensional Gaussian noise to approximate a target real-world data distribution.
If this is right
- Synthetic data generation becomes practical for large-scale use due to reduced training and inference time.
- Data privacy improves because only the trained network and reduced PCA components need sharing instead of original samples.
- Classification performance on downstream tasks can be maintained or enhanced by augmenting real data with the generated samples.
- Dimensionality reduction via PCA lowers memory and time costs while supporting the generative process.
Where Pith is reading between the lines
- The approach might simplify generative modeling pipelines by replacing complex architectures with a single fully connected network.
- Extensions could test whether the same randomized loss works on non-tabular data such as images or sequences.
- Integration into existing ML workflows could lower overall compute budgets for data augmentation tasks.
Load-bearing premise
A fully connected network trained this way on Gaussian noise will reliably match distributions from many different real tabular datasets without overfitting or major loss of fidelity.
What would settle it
Apply the method to a new tabular dataset outside the original 25 and measure whether MMD scores stay competitive while training and generation times remain orders of magnitude lower than current deep generative alternatives.
Figures










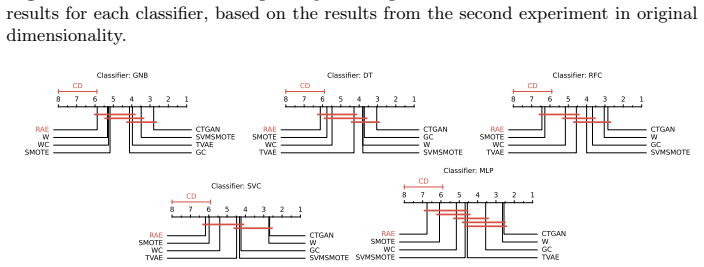

read the original abstract
The use of synthetic data in machine learning applications and research offers many benefits, including performance improvements through data augmentation, privacy preservation of original samples, and reliable method assessment with fully synthetic data. This work proposes a time-efficient synthetic data generation method based on a fully connected neural network and a randomized loss function that transforms a random Gaussian distribution to approximate a target real-world dataset. The experiments conducted on 25 diverse tabular real-world datasets confirm that the proposed solution surpasses the state-of-the-art generative methods and achieves reference MMD scores orders of magnitude faster than modern deep learning solutions. The experiments involved analyzing distributional similarity, assessing the impact on classification quality, and using PCA for dimensionality reduction, which further enhances data privacy and can boost classification quality while reducing time and memory complexity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a method for generating synthetic tabular data by training a fully connected neural network with a randomized loss function to transform high-dimensional Gaussian noise into samples that approximate the distribution of real-world datasets. Experiments on 25 tabular datasets are used to claim that this approach outperforms state-of-the-art generative models in MMD-based distributional similarity while being significantly faster, and that it can improve classification performance and privacy when combined with PCA dimensionality reduction.
Significance. Should the results be confirmed with rigorous experimental controls, the proposed FCNN-based approach with randomized loss could represent a notable advance in efficient synthetic data generation for tabular data, offering simplicity and speed advantages over more complex models like GANs. This could have practical implications for data augmentation, privacy, and benchmarking in machine learning applications. The work is credited for its empirical focus on multiple real-world datasets and exploration of downstream task impacts.
major comments (3)
- [Abstract] Abstract: The central claim that the method 'surpasses the state-of-the-art generative methods' and achieves 'reference MMD scores orders of magnitude faster' lacks any enumeration of the baseline methods, their MMD values, or timing benchmarks. This omission is load-bearing because without these specifics, the superiority and speed claims cannot be evaluated or reproduced.
- [Experiments] Experiments section: No information is provided on whether the MMD evaluations were performed on held-out test sets or on the training data used to fit the FCNN. Given the high capacity of fully connected networks, if MMD is computed on training samples, the reported scores may indicate memorization rather than true distribution learning, directly undermining the fidelity claims across the 25 datasets.
- [Experiments] Experiments section: The manuscript does not report statistical significance tests (e.g., p-values or confidence intervals) for the MMD comparisons or classification accuracy improvements, nor details on data splits or cross-validation procedures. These are necessary to support the assertions of consistent outperformance.
minor comments (1)
- [Abstract] Abstract: The abstract refers to 'analyzing distributional similarity' and 'assessing the impact on classification quality' but does not preview any specific quantitative results or figures from these analyses.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important areas for improving clarity and rigor. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the method 'surpasses the state-of-the-art generative methods' and achieves 'reference MMD scores orders of magnitude faster' lacks any enumeration of the baseline methods, their MMD values, or timing benchmarks. This omission is load-bearing because without these specifics, the superiority and speed claims cannot be evaluated or reproduced.
Authors: We agree that the abstract would benefit from greater specificity. In the revised manuscript, we will enumerate the primary baseline methods (e.g., CTGAN, TVAE, and others from the experiments) and include key quantitative results on MMD improvements and runtime advantages drawn directly from our tables. This will make the claims more concrete and easier to evaluate. revision: yes
-
Referee: [Experiments] Experiments section: No information is provided on whether the MMD evaluations were performed on held-out test sets or on the training data used to fit the FCNN. Given the high capacity of fully connected networks, if MMD is computed on training samples, the reported scores may indicate memorization rather than true distribution learning, directly undermining the fidelity claims across the 25 datasets.
Authors: We thank the referee for raising this critical point. The MMD scores were computed using held-out test sets: the FCNN was trained on the training split, and MMD was evaluated between samples generated from Gaussian noise and the unseen test data. We will explicitly document the train/test splits, the evaluation protocol, and any steps taken to mitigate overfitting in the revised Experiments section. revision: yes
-
Referee: [Experiments] Experiments section: The manuscript does not report statistical significance tests (e.g., p-values or confidence intervals) for the MMD comparisons or classification accuracy improvements, nor details on data splits or cross-validation procedures. These are necessary to support the assertions of consistent outperformance.
Authors: We acknowledge the value of statistical rigor. The revised manuscript will report results aggregated over multiple random seeds, including means with standard deviations or confidence intervals for MMD and accuracy metrics, along with appropriate significance tests. We will also detail the data splitting strategy (e.g., 80/20 train/test) and any cross-validation used for downstream classification tasks. revision: yes
Circularity Check
No circularity: empirical proposal supported by external dataset experiments
full rationale
The paper advances an empirical method for synthetic tabular data generation via a fully connected network trained on Gaussian noise with a randomized loss. Its central claims rest on experimental results across 25 independent real-world datasets, measuring MMD distributional similarity, downstream classification performance, and PCA-based privacy effects. No derivation chain, equations, or predictions are presented that reduce by construction to fitted inputs or self-citations; the work is framed as a practical proposal validated against external benchmarks rather than self-referential fitting. Any self-citations (if present) are not load-bearing for the reported performance advantages.
Axiom & Free-Parameter Ledger
free parameters (2)
- neural network architecture parameters
- randomization parameters in loss function
axioms (2)
- domain assumption A fully connected neural network can learn a mapping from Gaussian noise to approximate arbitrary real-world distributions.
- standard math Universal approximation theorem applies to enable distribution matching via the network.
Reference graph
Works this paper leans on
-
[1]
In: 2023 IEEE 35th international conference on tools with artificial intelligence (ICTAI)
Akritidis, L., Fevgas, A., Alamaniotis, M., Bozanis, P.: Conditional data synthesis with deep generative models for imbalanced dataset oversampling. In: 2023 IEEE 35th international conference on tools with artificial intelligence (ICTAI). pp. 444–
2023
-
[2]
Sensors24(22), 7389 (2024)
Alabdulwahab, S., Kim, Y.T., Son, Y.: Privacy-preserving synthetic data genera- tion method for iot-sensor network ids using ctgan. Sensors24(22), 7389 (2024)
2024
-
[3]
Knowledge-Based Systems300, 112174 (2024)
Almeida, G., Bacao, F.: Umap-smotenc: A simple, efficient, and consistent alterna- tive for privacy-aware synthetic data generation. Knowledge-Based Systems300, 112174 (2024)
2024
-
[4]
In: International conference on machine learning
Arjovsky,M.,Chintala,S.,Bottou,L.:Wassersteingenerativeadversarialnetworks. In: International conference on machine learning. pp. 214–223. Pmlr (2017)
2017
-
[5]
In: 2009 International Conference on Advances in Recent Technologies in Communication and Computing
Banu, R.V., Nagaveni, N.: Preservation of data privacy using pca based transfor- mation. In: 2009 International Conference on Advances in Recent Technologies in Communication and Computing. pp. 439–443. IEEE (2009)
2009
-
[6]
Ieee Access8, 20067–20079 (2019)
Binjubeir, M., Ahmed, A.A., Ismail, M.A.B., Sadiq, A.S., Khan, M.K.: Compre- hensive survey on big data privacy protection. Ieee Access8, 20067–20079 (2019)
2019
-
[7]
IEEE transactions on neural networks and learning systems31(8), 2868–2878 (2019)
Brzezinski, D., Stefanowski, J., Susmaga, R., Szczech, I.: On the dynamics of classi- fication measures for imbalanced and streaming data. IEEE transactions on neural networks and learning systems31(8), 2868–2878 (2019)
2019
-
[8]
Current Research in Biotechnology7, 100164 (2024)
Chakraborty, C., Bhattacharya, M., Pal, S., Lee, S.S.: From machine learning to deep learning: Advances of the recent data-driven paradigm shift in medicine and healthcare. Current Research in Biotechnology7, 100164 (2024)
2024
-
[9]
Journal of artificial intelligence research16, 321– 357 (2002)
Chawla, N.V., Bowyer, K.W., Hall, L.O., Kegelmeyer, W.P.: Smote: synthetic mi- nority over-sampling technique. Journal of artificial intelligence research16, 321– 357 (2002)
2002
-
[10]
Journal of King Saud University Computer and Information Sciences37(7), 163 (2025)
Chen, K., Zhou, X., Lin, Y., Feng, S., Shen, L., Wu, P.: A survey on privacy risks and protection in large language models. Journal of King Saud University Computer and Information Sciences37(7), 163 (2025)
2025
-
[11]
In: Machine learning for healthcare conference
Choi, E., Biswal, S., Malin, B., Duke, J., Stewart, W.F., Sun, J.: Generating multi- label discrete patient records using generative adversarial networks. In: Machine learning for healthcare conference. pp. 286–305. PMLR (2017)
2017
-
[12]
Journal of Machine learning research7(Jan), 1–30 (2006)
Demšar, J.: Statistical comparisons of classifiers over multiple data sets. Journal of Machine learning research7(Jan), 1–30 (2006)
2006
-
[13]
Chemical Reviews123(13), 8736–8780 (2023)
Dou, B., Zhu, Z., Merkurjev, E., Ke, L., Chen, L., Jiang, J., Zhu, Y., Liu, J., Zhang, B., Wei, G.W.: Machine learning methods for small data challenges in molecular science. Chemical Reviews123(13), 8736–8780 (2023)
2023
-
[14]
Information sciences505, 32–64 (2019)
Elreedy, D., Atiya, A.F.: A comprehensive analysis of synthetic minority oversam- pling technique (smote) for handling class imbalance. Information sciences505, 32–64 (2019)
2019
-
[15]
Machine Learning113(7), 4903–4923 (2024) 26 Joanna Komorniczak
Elreedy, D., Atiya, A.F., Kamalov, F.: A theoretical distribution analysis of syn- thetic minority oversampling technique (smote) for imbalanced learning. Machine Learning113(7), 4903–4923 (2024) 26 Joanna Komorniczak
2024
-
[16]
Expert Systems with Applications169, 114463 (2021)
Fajardo, V.A., Findlay, D., Jaiswal, C., Yin, X., Houmanfar, R., Xie, H., Liang, J., She, X., Emerson, D.B.: On oversampling imbalanced data with deep conditional generative models. Expert Systems with Applications169, 114463 (2021)
2021
-
[17]
arXiv preprint arXiv:2105.07612 (2021)
Fan, X., Wang, G., Chen, K., He, X., Xu, W.: Ppca: Privacy-preserving principal component analysis using secure multiparty computation (mpc). arXiv preprint arXiv:2105.07612 (2021)
-
[18]
In: Proceedings of the 31st ACM international conference on information & knowledge management
Fang, J., Tang, C., Cui, Q., Zhu, F., Li, L., Zhou, J., Zhu, W.: Semi-supervised learning with data augmentation for tabular data. In: Proceedings of the 31st ACM international conference on information & knowledge management. pp. 3928–3932 (2022)
2022
-
[19]
Fernández, A., Garcia, S., Herrera, F., Chawla, N.V.: Smote for learning from imbalanceddata:progressandchallenges,markingthe15-yearanniversary.Journal of artificial intelligence research61, 863–905 (2018)
2018
-
[20]
Journal of Big Data10(1), 115 (2023)
Fonseca, J., Bacao, F.: Tabular and latent space synthetic data generation: a lit- erature review. Journal of Big Data10(1), 115 (2023)
2023
-
[21]
In: 23rd USENIX security symposium (USENIX Security 14)
Fredrikson, M., Lantz, E., Jha, S., Lin, S., Page, D., Ristenpart, T.: Privacy in pharmacogenetics: An{End-to-End}case study of personalized warfarin dosing. In: 23rd USENIX security symposium (USENIX Security 14). pp. 17–32 (2014)
2014
-
[22]
In: 2023 IEEE Symposium on Security and Privacy (SP)
Froelicher, D., Cho, H., Edupalli, M., Sousa, J.S., Bossuat, J.P., Pyrgelis, A., Troncoso-Pastoriza,J.R.,Berger,B.,Hubaux,J.P.:Scalableandprivacy-preserving federated principal component analysis. In: 2023 IEEE Symposium on Security and Privacy (SP). pp. 1908–1925. IEEE (2023)
2023
-
[23]
arXiv preprint arXiv:2510.15083 (2025)
Ganev, G., Nazari, R., Davison, R., Dizche, A., Wu, X., Abbey, R., Silva, J., De Cristofaro, E.: Smote and mirrors: Exposing privacy leakage from synthetic minority oversampling. arXiv preprint arXiv:2510.15083 (2025)
-
[24]
Advances in neural in- formation processing systems27(2014)
Goodfellow, I.J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial nets. Advances in neural in- formation processing systems27(2014)
2014
-
[25]
In: 2017 international conference on advances in computing, communications and informatics (ICACCI)
Gosain, A., Sardana, S.: Handling class imbalance problem using oversampling techniques: A review. In: 2017 international conference on advances in computing, communications and informatics (ICACCI). pp. 79–85. IEEE (2017)
2017
-
[26]
Advances in neural information processing systems 19(2006)
Gretton, A., Borgwardt, K., Rasch, M., Schölkopf, B., Smola, A.: A kernel method for the two-sample-problem. Advances in neural information processing systems 19(2006)
2006
-
[27]
NPJ Digital Medicine6(1), 37 (2023)
Guillaudeux, M., Rousseau, O., Petot, J., Bennis, Z., Dein, C.A., Goronflot, T., Vince, N., Limou, S., Karakachoff, M., Wargny, M., et al.: Patient-centric synthetic data generation, no reason to risk re-identification in biomedical data analysis. NPJ Digital Medicine6(1), 37 (2023)
2023
-
[28]
Advances in neural information processing systems17(2004)
Guyon, I., Gunn, S., Ben-Hur, A., Dror, G.: Result analysis of the nips 2003 feature selection challenge. Advances in neural information processing systems17(2004)
2003
-
[29]
Neurocomputing493, 28–45 (2022)
Hernandez, M., Epelde, G., Alberdi, A., Cilla, R., Rankin, D.: Synthetic data generation for tabular health records: A systematic review. Neurocomputing493, 28–45 (2022)
2022
-
[30]
Journal of Network and Computer Applications185, 103066 (2021)
Ho, S., Qu, Y., Gu, B., Gao, L., Li, J., Xiang, Y.: Dp-gan: Differentially private consecutive data publishing using generative adversarial nets. Journal of Network and Computer Applications185, 103066 (2021)
2021
-
[31]
ACM Computing Surveys (CSUR)54(11s), 1–37 (2022) Synthesizing Real-world Distributions from Gaussian Noise 27
Hu, H., Salcic, Z., Sun, L., Dobbie, G., Yu, P.S., Zhang, X.: Membership inference attacks on machine learning: A survey. ACM Computing Surveys (CSUR)54(11s), 1–37 (2022) Synthesizing Real-world Distributions from Gaussian Noise 27
2022
-
[32]
In: International conference on learning rep- resentations (2018)
Jordon, J., Yoon, J., Van Der Schaar, M.: Pate-gan: Generating synthetic data with differential privacy guarantees. In: International conference on learning rep- resentations (2018)
2018
-
[33]
Advances in Neural Information Processing Systems34, 22919–22930 (2021)
Kim, Y.Y., Song, K., Jang, J., Moon, I.C.: Lada: Look-ahead data acquisition via augmentation for deep active learning. Advances in Neural Information Processing Systems34, 22919–22930 (2021)
2021
-
[34]
Auto-Encoding Variational Bayes
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[35]
Advances in Neural Information Processing Systems35, 36308–36323 (2022)
Kotelevskii,N.,Artemenkov,A.,Fedyanin,K.,Noskov,F.,Fishkov,A.,Shelmanov, A., Vazhentsev, A., Petiushko, A., Panov, M.: Nonparametric uncertainty quan- tification for single deterministic neural network. Advances in Neural Information Processing Systems35, 36308–36323 (2022)
2022
-
[36]
Progress in artificial intelligence5(4), 221–232 (2016)
Krawczyk, B.: Learning from imbalanced data: open challenges and future direc- tions. Progress in artificial intelligence5(4), 221–232 (2016)
2016
-
[37]
Journal of machine learning research18(17), 1–5 (2017)
LemaÃŽtre, G., Nogueira, F., Aridas, C.K.: Imbalanced-learn: A python toolbox to tackle the curse of imbalanced datasets in machine learning. Journal of machine learning research18(17), 1–5 (2017)
2017
-
[38]
ACM Computing Surveys (CSUR) 54(2), 1–36 (2021)
Liu, B., Ding, M., Shaham, S., Rahayu, W., Farokhi, F., Lin, Z.: When machine learning meets privacy: A survey and outlook. ACM Computing Surveys (CSUR) 54(2), 1–36 (2021)
2021
-
[39]
ACM Computing Surveys (CSUR)52(5), 1–34 (2019)
Lorena, A.C., Garcia, L.P., Lehmann, J., Souto, M.C., Ho, T.K.: How complex is your classification problem? a survey on measuring classification complexity. ACM Computing Surveys (CSUR)52(5), 1–34 (2019)
2019
-
[40]
Global Transitions Proceedings3(1), 91–99 (2022)
Maharana, K., Mondal, S., Nemade, B.: A review: Data pre-processing and data augmentation techniques. Global Transitions Proceedings3(1), 91–99 (2022)
2022
-
[41]
Bagan: Data augmentation with balancing gan.arXiv preprint arXiv:1803.09655,
Mariani, G., Scheidegger, F., Istrate, R., Bekas, C., Malossi, C.: Bagan: Data aug- mentation with balancing gan. arXiv preprint arXiv:1803.09655 (2018)
-
[42]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
McInnes, L., Healy, J., Melville, J.: Umap: Uniform manifold approximation and projection for dimension reduction. arXiv preprint arXiv:1802.03426 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[43]
JMIR AI4, e65729 (2025)
Miletic, M., Sariyar, M.: Utility-based analysis of statistical approaches and deep learning models for synthetic data generation with focus on correlation structures: algorithm development and validation. JMIR AI4, e65729 (2025)
2025
-
[44]
Array16, 100258 (2022)
Mumuni, A., Mumuni, F.: Data augmentation: A comprehensive survey of modern approaches. Array16, 100258 (2022)
2022
-
[45]
Journal of statistical software74, 1–26 (2016)
Nowok, B., Raab, G.M., Dibben, C.: synthpop: Bespoke creation of synthetic data in r. Journal of statistical software74, 1–26 (2016)
2016
-
[46]
arXiv preprint arXiv:1806.03384 (2018)
Park, N., Mohammadi, M., Gorde, K., Jajodia, S., Park, H., Kim, Y.: Data syn- thesis based on generative adversarial networks. arXiv preprint arXiv:1806.03384 (2018)
-
[47]
In: 2016 IEEE international conference on data science and advanced analytics (DSAA)
Patki, N., Wedge, R., Veeramachaneni, K.: The synthetic data vault. In: 2016 IEEE international conference on data science and advanced analytics (DSAA). pp. 399–410. IEEE (2016)
2016
-
[48]
Journal of Machine Learning Research12, 2825–2830 (2011)
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., Duchesnay, E.: Scikit-learn: Machine learning in Python. Journal of Machine Learning Research12, 2825–2830 (2011)
2011
-
[49]
In: 2022 IEEE Latin American Conference on Computational Intelligence (LA-CCI)
Pereira, S., Miranda, P., França, T., Bastos-Filho, C.J.A., Si, T.: A many-objective optimization approach to generate synthetic datasets based on real-world classi- fication problems. In: 2022 IEEE Latin American Conference on Computational Intelligence (LA-CCI). pp. 1–6 (2022) 28 Joanna Komorniczak
2022
-
[50]
Ieee Access8, 54776–54788 (2020)
Reddy, G.T., Reddy, M.P.K., Lakshmanna, K., Kaluri, R., Rajput, D.S., Srivas- tava, G., Baker, T.: Analysis of dimensionality reduction techniques on big data. Ieee Access8, 54776–54788 (2020)
2020
-
[51]
ACM Transactions on Intelligent Systems and Technology (TIST)13(4), 1–24 (2022)
Ren, H., Deng, J., Xie, X.: Grnn: generative regression neural network—a data leakage attack for federated learning. ACM Transactions on Intelligent Systems and Technology (TIST)13(4), 1–24 (2022)
2022
-
[52]
arXiv preprint arXiv:2012.00058v2 (2021)
Romano, J.D., Le, T.T., La Cava, W., Gregg, J.T., Goldberg, D.J., Chakraborty, P., Ray, N.L., Himmelstein, D., Fu, W., Moore, J.H.: Pmlb v1.0: an open source dataset collection for benchmarking machine learning methods. arXiv preprint arXiv:2012.00058v2 (2021)
-
[53]
International Journal of Applied Earth Observation and Geoinformation125, 103569 (2023)
Safonova, A., Ghazaryan, G., Stiller, S., Main-Knorn, M., Nendel, C., Ryo, M.: Ten deep learning techniques to address small data problems with remote sens- ing. International Journal of Applied Earth Observation and Geoinformation125, 103569 (2023)
2023
-
[54]
CAAI Transactions on Intelligence Technology7(3), 481–491 (2022)
Sathianarayanan, B., Singh Samant, Y.C., Conjeepuram Guruprasad, P.S., Hari- haran, V.B., Manickam, N.D.: Feature-based augmentation and classification for tabular data. CAAI Transactions on Intelligence Technology7(3), 481–491 (2022)
2022
-
[55]
Pattern Recognition Letters52, 9–16 (2015)
Scitovski, R., Marošević, T.: Multiple circle detection based on center-based clus- tering. Pattern Recognition Letters52, 9–16 (2015)
2015
-
[56]
In: 2020 5th IEEE International Conference on Big Data Analytics (ICBDA)
Shao, M., Gu, N., Zhang, X.: Credit card transactions data adversarial augmenta- tion in the frequency domain. In: 2020 5th IEEE International Conference on Big Data Analytics (ICBDA). pp. 238–245. IEEE (2020)
2020
-
[57]
Multimedia tools and applications83(41), 88811–88858 (2024)
Sharma, P., Kumar, M., Sharma, H.K., Biju, S.M.: Generative adversarial networks (gans): introduction, taxonomy, variants, limitations, and applications. Multimedia tools and applications83(41), 88811–88858 (2024)
2024
-
[58]
In: Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society
Sharma, S., Zhang, Y., Ríos Aliaga, J.M., Bouneffouf, D., Muthusamy, V., Varsh- ney, K.R.: Data augmentation for discrimination prevention and bias disambigua- tion. In: Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society. pp. 358–364 (2020)
2020
-
[59]
Shokri, R., Stronati, M., Song, C., Shmatikov, V.: Membership inference attacks againstmachinelearningmodels.In:2017IEEEsymposiumonsecurityandprivacy (SP). pp. 3–18. IEEE (2017)
2017
-
[60]
Journal of big data6(1), 1–48 (2019)
Shorten, C., Khoshgoftaar, T.M.: A survey on image data augmentation for deep learning. Journal of big data6(1), 1–48 (2019)
2019
-
[61]
Journal of big Data8(1), 101 (2021)
Shorten,C.,Khoshgoftaar,T.M.,Furht,B.:Textdataaugmentationfordeeplearn- ing. Journal of big Data8(1), 101 (2021)
2021
-
[62]
Knowledge-Based Systems280, 110956 (2023)
Sivakumar, J., Ramamurthy, K., Radhakrishnan, M., Won, D.: Generativemtd: A deep synthetic data generation framework for small datasets. Knowledge-Based Systems280, 110956 (2023)
2023
-
[63]
Advances in neural information processing systems30(2017)
Srivastava, A., Valkov, L., Russell, C., Gutmann, M.U., Sutton, C.: Veegan: Reduc- ing mode collapse in gans using implicit variational learning. Advances in neural information processing systems30(2017)
2017
-
[64]
In: ICPRAM
Tazwar, S.M., Knobbout, M., Quesada, E.H., Popa, M.: Tab-vae: A novel vae for generating synthetic tabular data. In: ICPRAM. pp. 17–26 (2024)
2024
-
[65]
A note on the evaluation of generative models
Theis, L., Oord, A.v.d., Bethge, M.: A note on the evaluation of generative models. arXiv preprint arXiv:1511.01844 (2015)
work page Pith review arXiv 2015
-
[66]
In: Proceedings of the 37th International conference on machine learn- ing, ICML HSYS Workshop 2020 (2020) Synthesizing Real-world Distributions from Gaussian Noise 29
Vardhan, L.V.H., Kok, S.: Synthetic tabular data generation with oblivious vari- ational autoencoders: alleviating the paucity of personal tabular data for open research. In: Proceedings of the 37th International conference on machine learn- ing, ICML HSYS Workshop 2020 (2020) Synthesizing Real-world Distributions from Gaussian Noise 29
2020
-
[67]
Procedia computer science165, 104–111 (2019)
Velliangiri, S., Alagumuthukrishnan, S., et al.: A review of dimensionality reduc- tion techniques for efficient computation. Procedia computer science165, 104–111 (2019)
2019
-
[68]
Applied Soft Computing166, 112223 (2024)
Wang, A.X., Chukova, S.S., Simpson, C.R., Nguyen, B.P.: Challenges and opportu- nities of generative models on tabular data. Applied Soft Computing166, 112223 (2024)
2024
-
[69]
Artificial Intelligence340, 104292 (2025)
Wang, A.X., Nguyen, B.P.: Ttvae: Transformer-based generative modeling for tab- ular data generation. Artificial Intelligence340, 104292 (2025)
2025
-
[70]
Advances in neural information processing systems32 (2019)
Xu,L.,Skoularidou,M.,Cuesta-Infante,A.,Veeramachaneni,K.:Modelingtabular data using conditional gan. Advances in neural information processing systems32 (2019)
2019
-
[71]
Synthesizing Tabular Data using Generative Adversarial Networks
Xu, L., Veeramachaneni, K.: Synthesizing tabular data using generative adversarial networks. arXiv preprint arXiv:1811.11264 (2018)
work page Pith review arXiv 2018
-
[72]
In: 2018 IEEE 31st computer security foundations symposium (CSF)
Yeom, S., Giacomelli, I., Fredrikson, M., Jha, S.: Privacy risk in machine learning: Analyzing the connection to overfitting. In: 2018 IEEE 31st computer security foundations symposium (CSF). pp. 268–282. IEEE (2018)
2018
-
[73]
ACM Transactions on Database Systems (TODS)42(4), 1–41 (2017)
Zhang, J., Cormode, G., Procopiuc, C.M., Srivastava, D., Xiao, X.: Privbayes: Pri- vate data release via bayesian networks. ACM Transactions on Database Systems (TODS)42(4), 1–41 (2017)
2017
-
[74]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhang, Y., Jia, R., Pei, H., Wang, W., Li, B., Song, D.: The secret revealer: Gener- ative model-inversion attacks against deep neural networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 253–261 (2020)
2020
-
[75]
arXiv preprint arXiv:2506.01907 (2025)
Zhou,Y.,Malin,B.,Kantarcioglu,M.:Smote-dp:Improvingprivacy-utilitytradeoff with synthetic data. arXiv preprint arXiv:2506.01907 (2025)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.