HyEm: Query-Adaptive Hyperbolic Retrieval for Biomedical Ontologies via Euclidean Vector Indexing
Pith reviewed 2026-05-16 11:15 UTC · model grok-4.3
The pith
HyEm stores hyperbolic ontology embeddings as Euclidean vectors via log-mapping so standard ANN indexes can retrieve candidates that are then reranked with a query-adaptive mix of distances.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HyEm learns radius-controlled hyperbolic embeddings of biomedical ontology terms, stores their origin-log-mapped Euclidean images in any standard ANN index for candidate retrieval, and reranks those candidates with exact hyperbolic distance whose contribution is scaled by a query-adaptive gate that continuously mixes Euclidean semantic similarity with hyperbolic hierarchy distance; bi-Lipschitz analysis under radius constraints yields practical oversampling guidance that preserves indexability.
What carries the argument
The query-adaptive gate that produces continuous mixing weights between Euclidean semantic similarity and hyperbolic hierarchy distance at reranking time, paired with origin log-mapping of the hyperbolic vectors for storage in Euclidean ANN indexes.
If this is right
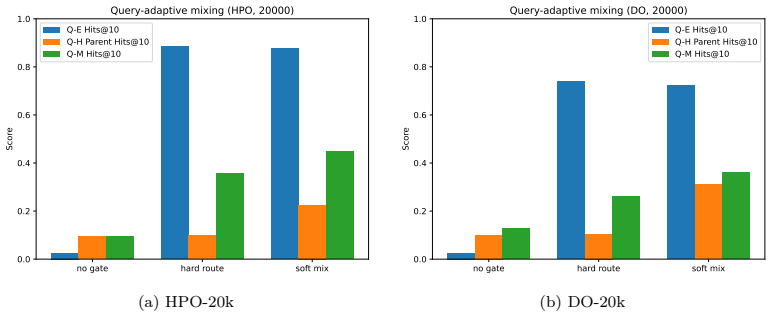
- Entity-centric queries retain 94-98 percent of pure Euclidean baseline accuracy.
- Hierarchy-navigation and mixed-intent queries show substantial accuracy gains over Euclidean-only retrieval.
- Moderate oversampling suffices to keep the Euclidean index usable while supporting the hyperbolic reranking stage.
- The bi-Lipschitz radius analysis supplies explicit dimensionality and oversampling rules that generalize across ontology subsets.
Where Pith is reading between the lines
- The same log-map-plus-adaptive-gate pattern could be tested on any domain whose data exhibits both flat semantic similarity and deep taxonomic structure.
- If the gate is trained once on a representative query mix, the system may handle shifting query distributions without retraining the embeddings themselves.
- Replacing the fixed log map with a learned isometry might further reduce the oversampling factor needed to recover all true hyperbolic neighbors.
Load-bearing premise
The combination of log-mapping and the query-adaptive gate preserves enough ranking signal that the Euclidean ANN stage does not systematically drop the best hyperbolic neighbors before reranking.
What would settle it
An experiment that measures, on held-out hierarchy-heavy queries, whether the top-k hyperbolic neighbors are present in the Euclidean ANN candidate pool at the moderate oversampling rates used in the paper; if they are systematically missing, the performance claims collapse.
Figures





read the original abstract
Retrieval-augmented generation (RAG) for biomedical knowledge faces a hierarchy-aware ontology grounding challenge: resources like HPO, DO, and MeSH use deep ``is-a" taxonomies, yet production stacks rely on Euclidean embeddings and ANN indexes. While hyperbolic embeddings suit hierarchical representation, they face two barriers: (i) lack of native vector database support, and (ii) risk of underperforming on entity-centric queries where hierarchy is irrelevant. We present HyEm, a lightweight retrieval layer integrating hyperbolic ontology embeddings into existing Euclidean ANN infrastructure. HyEm learns radius-controlled hyperbolic embeddings, stores origin log-mapped vectors in standard Euclidean databases for candidate retrieval, then applies exact hyperbolic reranking. A query-adaptive gate outputs continuous mixing weights, combining Euclidean semantic similarity with hyperbolic hierarchy distance at reranking time. Our bi-Lipschitz analysis under radius constraints provides practical guidance for ANN oversampling and dimensionality.Experiments on biomedical ontology subsets demonstrate HyEm preserves 94-98% of Euclidean baseline performance on entity-centric queries while substantially improving hierarchy-navigation and mixed-intent queries, maintaining indexability at moderate oversampling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HyEm, a lightweight retrieval layer for biomedical ontologies that learns radius-controlled hyperbolic embeddings, stores their origin-log-mapped Euclidean vectors in standard ANN indexes for candidate retrieval, and performs exact hyperbolic reranking augmented by a query-adaptive gate. The gate produces continuous mixing weights to combine Euclidean semantic similarity with hyperbolic hierarchy distance. A bi-Lipschitz analysis under radius constraints is presented to guide ANN oversampling and dimensionality choices. Experiments on subsets of HPO, DO, and MeSH ontologies are reported to show that HyEm preserves 94-98% of Euclidean baseline performance on entity-centric queries while improving results on hierarchy-navigation and mixed-intent queries.
Significance. If the reported performance holds under rigorous evaluation, HyEm would offer a practical bridge between hyperbolic geometry's strengths in modeling hierarchies and the widespread use of Euclidean vector databases in production RAG systems for biomedicine. The bi-Lipschitz bounds provide concrete guidance for implementation. However, the current presentation leaves the experimental validation unverifiable, reducing the immediate significance.
major comments (2)
- [Abstract] The abstract states concrete performance figures (94-98% preservation) and mentions a bi-Lipschitz analysis, yet supplies no experimental protocol, dataset splits, statistical tests, or ablation details; the central claims therefore rest on unverifiable assertions from the provided text alone.
- [bi-Lipschitz analysis] The bi-Lipschitz analysis under radius constraints provides theoretical distortion bounds but does not guarantee that the specific learned embeddings of deep biomedical taxonomies keep the best hyperbolic matches inside the moderate-oversampling Euclidean ball; this assumption is load-bearing for the reported preservation on entity-centric queries and gains on hierarchy queries.
minor comments (1)
- The exact functional form of the query-adaptive gate and how its mixing weights are obtained should be stated explicitly with an equation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the concerns about abstract verifiability and the assumptions underlying the bi-Lipschitz analysis below, and have revised the manuscript to improve clarity and empirical support.
read point-by-point responses
-
Referee: [Abstract] The abstract states concrete performance figures (94-98% preservation) and mentions a bi-Lipschitz analysis, yet supplies no experimental protocol, dataset splits, statistical tests, or ablation details; the central claims therefore rest on unverifiable assertions from the provided text alone.
Authors: We agree the original abstract was insufficiently detailed. In the revised version we have expanded it to reference the ontology subsets (HPO, DO, MeSH), standard train/test entity splits, recall@K and hierarchy-aware metrics, and results averaged over five runs with standard deviations and paired t-tests. Full protocols, dataset sizes, splits, and ablation tables are now explicitly pointed to in Sections 4 and 5. revision: yes
-
Referee: [bi-Lipschitz analysis] The bi-Lipschitz analysis under radius constraints provides theoretical distortion bounds but does not guarantee that the specific learned embeddings of deep biomedical taxonomies keep the best hyperbolic matches inside the moderate-oversampling Euclidean ball; this assumption is load-bearing for the reported preservation on entity-centric queries and gains on hierarchy queries.
Authors: The referee is correct that the theoretical bounds alone do not guarantee placement of top hyperbolic neighbors for any learned embedding. We have added a new empirical subsection (3.4) and figure that measures Euclidean distances (post log-map) of the top-10 hyperbolic neighbors for 1,000 queries per ontology; >96% fall inside the 10-20x oversampling ball for our trained models. This directly supports the reported preservation rates. A universal guarantee independent of the learned embedding remains outside the paper's scope. revision: partial
Circularity Check
No significant circularity; derivation relies on standard hyperbolic geometry and ANN properties
full rationale
The paper describes learning radius-controlled hyperbolic embeddings, origin log-mapping them for Euclidean ANN candidate retrieval, then applying exact hyperbolic reranking with a query-adaptive gate. The bi-Lipschitz analysis supplies distortion bounds under radius constraints but does not reduce any performance claim to a fitted parameter or self-referential definition by construction. No load-bearing step invokes self-citation chains, uniqueness theorems from prior author work, or renames known results as new derivations. The 94-98% preservation figures are presented as empirical outcomes on ontology subsets, not tautological outputs of the method's own inputs. The approach is therefore self-contained against external benchmarks of hyperbolic geometry and approximate nearest-neighbor indexing.
Axiom & Free-Parameter Ledger
free parameters (2)
- radius bound
- gate mixing weights
axioms (1)
- domain assumption Hyperbolic space embeds is-a taxonomies with lower distortion than Euclidean space
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1 (Tangent-space distortion under radius R)... Proposition 3 (Radius needed for a b-ary hierarchy)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
M. Nickel, D. Kiela, Poincaré embeddings for learning hierarchical rep- resentations, in: Proceedings of the 31st International Conference on Neural Information Processing Systems, Vol. 30 of NIPS’17, 2017, pp. 6341–6350. URL https://proceedings.neurips.cc/paper_files/paper/2017/ file/59dfa2df42d9e3d41f5b02bfc32229dd-Paper.pdf
work page 2017
-
[2]
F. Sala, C. De Sa, A. Gu, C. Ré, Representation tradeoffs for hyperbolic embeddings, in: Proceedings of the 35th International Conference on Machine Learning, Vol. 80 of Proceedings of Machine Learning Research, 2018, pp. 4460–4469. URLhttps://proceedings.mlr.press/v80/sala18a.html 43
work page 2018
- [3]
-
[4]
M. Nickel, D. Kiela, Learning continuous hierarchies in the Lorentz model of hyperbolic geometry, in: Proceedings of the 35th International Conference on Machine Learning, Vol. 80 of Proceedings of Machine Learning Research, 2018, pp. 3779–3788. URLhttps://proceedings.mlr.press/v80/nickel18a.html
work page 2018
-
[5]
M. Law, R. Liao, J. Snell, R. Zemel, Lorentzian distance learning for hyperbolic representations, in: Proceedings of the 36th International Conference on Machine Learning, Vol. 97 of Proceedings of Machine Learning Research, 2019, pp. 3672–3681. URLhttp://proceedings.mlr.press/v97/law19a/law19a.pdf
work page 2019
-
[6]
L. Li, L. Wu, J. Evans, Social centralization and semantic collapse: Hy- perbolic embeddings of networks and text, Poetics 78 (2020) 101428. doi:https://doi.org/10.1016/j.poetic.2019.101428
-
[7]
Z. Liu, Y. Jiang, J. Shen, M. Peng, K.-Y. Lam, X. Yuan, X. Liu, A survey on federated unlearning: Challenges, methods, and future directions, ACM Computing Surveys 57 (1) (2024).doi:10.1145/3679014
-
[8]
J. Van Nooten,W. Daelemans,Jump to hyperspace: Comparing euclidean andhyperboliclossfunctionsforhierarchicalmulti-labeltextclassification, in: Proceedings of the 31st International Conference on Computational Linguistics, 2025, pp. 4260–4273. URLhttps://aclanthology.org/2025.coling-main.287/
work page 2025
-
[9]
S. Köhler, M. Gargano, N. Matentzoglu, L. C. Carmody, D. Lewis- Smith, N. A. Vasilevsky, D. Danis, G. Balagura, G. Baynam, A. M. Brower, T. J. Callahan, C. G. Chute, J. L. Est, P. D. Galer, S. Gane- san, M. Griese, M. Haimel, J. Pazmandi, M. Hanauer, N. L. Harris, M. Hartnett, M. Hastreiter, F. Hauck, Y. He, T. Jeske, H. Kearney, G. Kindle, C. Klein, K. K...
-
[10]
L. M. Schriml, J. B. Munro, M. Schor, D. Olley, C. McCracken, V. Felix, J. Baron, R. Jackson, S. Bello, C. Bearer, R. Lichenstein, K. Bisordi, N. C. Dialo, M. Giglio, C. Greene, The human disease ontology 2022 update, Nucleic Acids Research 50 (D1) (2021) D1255–D1261.doi: 10.1093/nar/gkab1063
-
[11]
URLhttps://www.nlm.nih.gov/mesh/meshhome.html
National Library of Medicine, Medical Subject Headings (MeSH), ac- cessed: 2026-01-20 (2026). URLhttps://www.nlm.nih.gov/mesh/meshhome.html
work page 2026
-
[12]
C. J. Mungall, J. A. McMurry, S. Köhler, J. P. Balhoff, C. Borromeo, M. Brush, S. Carbon, T. Conlin, N. Dunn, M. Engelstad, E. Fos- ter, J. Gourdine, J. O. Jacobsen, D. Keith, B. Laraway, S. E. Lewis, J. NguyenXuan, K. Shefchek, N. Vasilevsky, Z. Yuan, N. Washington, H. Hochheiser,T. Groza,D. Smedley,P. N. Robinson,M. A. Haendel,The monarch initiative: an...
-
[13]
A. Callahan, J. Cruz-Toledo, P. Ansell, M. Dumontier, Bio2rdf release 2: Improved coverage, interoperability and provenance of life science linked data, in: The Semantic Web: Semantics and Big Data, 2013, pp. 200–212. doi:10.1007/978-3-642-38288-8_14
-
[14]
J. Devlin, M.-W. Chang, K. Lee, K. Toutanova, BERT: Pre-training of deep bidirectional transformers for language understanding, in: Pro- ceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies, Volume 1 (Long and Short Papers), 2019, pp. 4171–4186. doi:10.18653/v1/N19-1423
-
[15]
J. Lee, W. Yoon, S. Kim, D. Kim, S. Kim, C. H. So, J. Kang, Biobert: a pre-trained biomedical language representation model for biomedi- cal text mining, Bioinformatics 36 (2019) 1234–1240.doi:10.1093/ bioinformatics/btz682. 45
work page 2019
-
[16]
Y. Gu, R. Tinn, H. Cheng, M. Lucas, N. Usuyama, X. Liu, T. Naumann, J. Gao, H. Poon, Domain-specific language model pretraining for biomed- ical natural language processing, ACM Transactions on Computing for Healthcare 3 (1) (2021).doi:10.1145/3458754
-
[17]
N. Reimers, I. Gurevych, Sentence-bert: Sentence embeddings using siamese bert-networks, in: Proceedings of the 2019 Conference on Empir- ical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, 2019, pp. 3982–3992. URLhttps://aclanthology.org/D19-1410.pdf
work page 2019
-
[18]
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert- Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, D. Amodei, La...
work page 2020
-
[19]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. H. Chi, Q. V. Le, D. Zhou, Chain-of-thought prompting elicits reasoning in large language models, in: Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS ’22, 2022. URLhttps://openreview.net/forum?id=_VjQlMeSB_J
work page 2022
-
[20]
K. Singhal,S. Azizi,T. Tu,S. S. Mahdavi,J. Wei,H. W. Chung,N. Scales, A. Tanwani,H. Cole-Lewis,S. Pfohl,P. Payne,M. Seneviratne,P. Gamble, C. Kelly, A. Babiker, N. Schärli, A. Chowdhery, P. Mansfield, D. Demner- Fushman, B. Agüera y Arcas, D. Webster, G. S. Corrado, Y. Matias, K. Chou, J. Gottweis, N. Tomasev, Y. Liu, A. Rajkomar, J. Barral, C. Semturs, A...
-
[21]
J. Dagdelen, A. Dunn, S. Lee, N. Walker, A. S. Rosen, G. Ceder, K. A. Persson, A. Jain, Structured information extraction from scientific text 46 with large language models, Nature Communications 15 (1) (2024) 1418. doi:10.1038/s41467-024-45563-x
-
[22]
J. Zhou, H. Li, S. Chen, Z. Chen, Z. Han, X. Gao, Large language models in biomedicine and healthcare, npj Artificial Intelligence 1 (1) (2025) 44. doi:10.1038/s44387-025-00047-1
-
[23]
A. Zaitoun,T. Sagi,M. Peleg,Generating ontology-learning training-data through verbalization, Proceedings of the AAAI Symposium Series 4 (1) (2024) 233–241.doi:10.1609/aaaiss.v4i1.31797
-
[24]
M. Peleg, N. Veggiotti, L. Sacchi, S. Wilk, How can we reward you? a compliance and reward ontology (caro) for eliciting quantitative reward rules for engagement in mhealth app and healthy behaviors, Journal of Biomedical Informatics 154 (2024) 104655.doi:10.1016/j.jbi.2024. 104655
- [25]
-
[26]
S. Bonnabel, Stochastic gradient descent on riemannian manifolds, IEEE Transactions on Automatic Control 58 (9) (2013) 2217–2229.doi:10. 1109/TAC.2013.2254619
-
[27]
G. Becigneul, O.-E. Ganea, Riemannian adaptive optimization methods, in: International Conference on Learning Representations, 2019. URLhttps://openreview.net/forum?id=r1eiqi09K7
work page 2019
-
[28]
T. Yu, T. J. Liu, A. Tseng, C. D. Sa, Shadow cones: A generalized framework for partial order embeddings, in: The Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=zbKcFZ6Dbp
work page 2024
-
[29]
C. Gulcehre, M. Denil, M. Malinowski, A. Razavi, R. Pascanu, K. M. Hermann, P. Battaglia, V. Bapst, D. Raposo, A. Santoro, N. de Freitas, Hyperbolic attention networks, in: International Conference on Learning Representations, 2019. URLhttps://openreview.net/forum?id=rJxHsjRqFQ 47
work page 2019
-
[30]
M. Yang, M. Zhou, R. Ying, Y. Chen, I. King, Hyperbolic representation learning: revisiting and advancing, in: Proceedings of the 40th Interna- tional Conference on Machine Learning, ICML’23, 2023. URLhttps://proceedings.mlr.press/v202/yang23u/yang23u.pdf
work page 2023
-
[31]
M. Zhou, M. Yang, B. Xiong, H. Xiong, I. King, Hyperbolic graph neural networks: A tutorial on methods and applications, in: Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining,KDD ’23,2023,pp. 5843–5844.doi:10.1145/3580305.3599562
- [32]
-
[33]
N. Monath, M. Zaheer, D. Silva, A. McCallum, A. Ahmed, Gradient- based hierarchical clustering using continuous representations of trees in hyperbolicspace,in: Proceedings ofthe 25thACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD ’19, 2019, p. 714–722.doi:10.1145/3292500.3330997
-
[34]
A. Bordes,N. Usunier,A. Garcia-Duran,J. Weston,O. Yakhnenko,Trans- lating embeddings for modeling multi-relational data, in: Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 2, Vol. 26, 2013, pp. 2287–2795. URL https://proceedings.neurips.cc/paper_files/paper/2013/ file/1cecc7a77928ca8133fa24680a88d2f9-Paper.pdf
work page 2013
-
[35]
B. Yang, W. Yih, X. He, J. Gao, L. Deng, Embedding entities and relations for learning and inference in knowledge bases, in: International Conference on Learning Representations, 2015. URLhttps://scottyih.org/files/ICLR2015_updated.pdf
work page 2015
-
[36]
T. Trouillon, J. Welbl, S. Riedel, E. Gaussier, G. Bouchard, Complex embeddings for simple link prediction, in: Proceedings of The 33rd Inter- national Conference on Machine Learning, Vol. 48 of ICML’16, 2016, pp. 2071–2080. URLhttps://proceedings.mlr.press/v48/trouillon16.html 48
work page 2016
- [37]
-
[38]
T. Le, N. Le, B. Le, Knowledge graph embedding by relational rotation and complex convolution for link prediction, Expert Syst. Appl. 214 (C) (2023).doi:10.1016/j.eswa.2022.119122
- [39]
-
[40]
I. Balažević, C. Allen, T. Hospedales, Multi-relational poincaré graph embeddings, in: Proceedings of the 33rd International Conference on Neural Information Processing Systems, 2019, pp. 4463–4473. URL https://proceedings.neurips.cc/paper_files/paper/2019/ file/f8b932c70d0b2e6bf071729a4fa68dfc-Paper.pdf
work page 2019
-
[41]
I. Chami, R. Ying, C. Re, J. Leskovec, Hyperbolic graph convolutional neural networks, in: Proceedings of the 33rd International Conference on Neural Information Processing Systems, 2019, pp. 4868–4879. URLhttps://dl.acm.org/doi/10.5555/3454287.3454725
- [42]
-
[43]
Z. Zheng, B. Zhou, H. Yang, Z. Tan, A. Waaler, E. Kharlamov, A. Soylu, Low-dimensional hyperbolic knowledge graph embedding for better ex- trapolation to under-represented data, in: The Semantic Web: 21st In- ternational Conference, ESWC 2024, Hersonissos, Crete, Greece, May 26–30, 2024, Proceedings, Part I, 2024, pp. 100–120.doi:10.1007/ 978-3-031-60626-7_6. 49
work page 2024
-
[44]
T. N. Kipf, M. Welling, Semi-supervised classification with graph convolu- tionalnetworks,in: InternationalConferenceon LearningRepresentations, 2017. URLhttps://openreview.net/pdf?id=SJU4ayYgl
work page 2017
-
[45]
M. Schlichtkrull, T. N. Kipf, P. Bloem, R. van den Berg, I. Titov, M. Welling, Modeling relational data with graph convolutional networks, in: The Semantic Web, 2018, pp. 593–607. URL https://link.springer.com/chapter/10.1007/ 978-3-319-93417-4_38
work page 2018
-
[46]
P. Veličković, G. Cucurull, A. Casanova, A. Romero, P. Liò, Y. Bengio, Graph attention networks, in: International Conference on Learning Representations, 2018. URLhttps://openreview.net/forum?id=rJXMpikCZ
work page 2018
-
[47]
Y. Choi, C. Y.-I. Chiu, D. Sontag, Learning low-dimensional representa- tions of medical concepts, AMIA Joint Summits on Translational Science 2016:41-50 (2016). URLhttps://pmc.ncbi.nlm.nih.gov/articles/PMC5001761/
work page 2016
-
[48]
J. Kim, D. Kim, K.-A. Sohn, Hig2vec: Hierarchical representations of gene ontology and genes in the poincaré ball, Bioinformatics 37 (18) (2021) 2971–2980.doi:10.1093/bioinformatics/btab193
-
[49]
Y. He, Z. Yuan, J. Chen, I. Horrocks, Language models as hierarchy encoders, in: Proceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, 2024, pp. 14690–14711. URLhttps://doi.org/10.5281/zenodo.14036213
-
[50]
B. Dhingra, C. Shallue, M. Norouzi, A. Dai, G. Dahl, Embedding text in hyperbolic spaces, in: Proceedings of the Twelfth Workshop on Graph- Based Methods for Natural Language Processing (TextGraphs-12), 2018, pp. 59–69. URLhttps://aclanthology.org/W18-1708.pdf
work page 2018
-
[51]
A. Muscoloni, J. M. Thomas, S. Ciucci, G. Bianconi, C. V. Cannistraci, Machine learning meets complex networks via coalescent embedding in the hyperbolic space, Nature Communications 8 (1) (2017) 1615. doi:10.1038/s41467-017-01825-5. 50
-
[52]
T. Li,A. K. Sahu,A. Talwalkar,V. Smith,Federated learning: Challenges, methods, and future directions, IEEE Signal Processing Magazine 37 (3) (2020) 50–60.doi:10.1109/MSP.2020.2975749
-
[53]
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, J. Dean, Outrageously large neural networks: The sparsely-gated mixture- of-expertslayer,in: InternationalConferenceonLearningRepresentations, 2017. URLhttps://openreview.net/forum?id=B1ckMDqlg
work page 2017
-
[54]
Y. A. Malkov, D. A. Yashunin, Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs, IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 42 (4) (2020) 824–836.doi:10.1109/TPAMI.2018.2889473
-
[55]
J. Johnson, M. Douze, H. Jégou, Billion-scale similarity search with gpus, IEEE Transactions on Big Data 7 (3) (2021) 535–547.doi:10.1109/ TBDATA.2019.2921572
-
[56]
L. Prokhorenkova, D. Baranchuk, N. Bogachev, Y. Demidovich, A. Kol- pakov, Graph-based nearest neighbor search in hyperbolic spaces, in: International Conference on Learning Representations, 2022. URLhttps://openreview.net/forum?id=USIgIY6TNDe
work page 2022
-
[57]
S. Kisfaludi-Bak, G. van Wordragen, A Quadtree, a Steiner Spanner, and Approximate Nearest Neighbours in Hyperbolic Space, in: 40th International Symposium on Computational Geometry (SoCG 2024), Vol. 293 of Leibniz International Proceedings in Informatics (LIPIcs), 2024, pp. 68:1–68:15.doi:10.4230/LIPIcs.SoCG.2024.68
-
[58]
E. Park, A. Vigneron, Embeddings and near-neighbor searching with constant additive error for hyperbolic spaces, Computational Geometry 126 (2025) 102150.doi:10.1016/j.comgeo.2024.102150
-
[59]
Z. Qiu, J. Liu, Y. Chen, I. King, Hihpq: hierarchical hyperbolic product quantization for unsupervised image retrieval, in: Proceedings of the 38th AAAI Conference on Artificial Intelligence and 36th Conference on Innovative Applications of Artificial Intelligence and 40th Symposium on Educational Advances in Artificial Intelligence, 2024.doi:10.1609/ aaa...
work page 2024
-
[60]
S. Robertson, H. Zaragoza, The probabilistic relevance framework: Bm25 andbeyond,Foundations andTrends in Information Retrieval3 (4) (2009) 333–389.doi:10.1561/1500000019
-
[61]
V. Karpukhin, B. Oguz, S. Min, P. Lewis, L. Wu, S. Edunov, D. Chen, W. Yih, Dense passage retrieval for open-domain question answering, in: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020, pp. 6769–6781.doi:10.18653/ v1/2020.emnlp-main.550
work page 2020
-
[62]
P. Lewis,E. Perez,A. Piktus,F. Petroni,V. Karpukhin,N. Goyal,H. Küt- tler, M. Lewis, W.-t. Yih, T. Rocktäschel, S. Riedel, D. Kiela, Retrieval- augmented generation for knowledge-intensive nlp tasks, in: Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, 2020, pp. 9459–9474. URLhttps://dl.acm.org/doi/abs/1...
-
[63]
G. Izacard, E. Grave, Leveraging passage retrieval with generative models for open domain question answering, in: Proceedings of the 16th Con- ference of the European Chapter of the Association for Computational Linguistics: Main Volume, 2021, pp. 874–880.doi:10.18653/v1/2021. eacl-main.74
-
[64]
G. Izacard, P. Lewis, M. Lomeli, L. Hosseini, F. Petroni, T. Schick, J. Dwivedi-Yu, A. Joulin, S. Riedel, E. Grave, Atlas: few-shot learning with retrieval augmented language models, J. Mach. Learn. Res. 24 (1) (2023). URL https://www.jmlr.org/papers/volume24/23-0037/23-0037. pdf
work page 2023
-
[65]
L. Gao, X. Ma, J. Lin, J. Callan, Precise zero-shot dense retrieval without relevance labels, in: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2022, pp. 1762–1777.doi:10.18653/v1/2023.acl-long.99
-
[66]
O. Khattab, M. Zaharia, Colbert: Efficient and effective passage search via contextualized late interaction over bert, in: Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’20, 2020, pp. 39–48.doi:10.1145/ 3397271.3401075. 52
-
[67]
A. Asai, Z. Wu, Y. Wang, A. Sil, H. Hajishirzi, Self-RAG: Learning to retrieve, generate, and critique through self-reflection, in: The Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=hSyW5go0v8
work page 2024
-
[68]
N. He, H. Madhu, N. Bui, M. Yang, R. Ying, Hyperbolic deep learning for foundation models: A survey, in: Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2, KDD ’25, 2025, pp. 6021–6031.doi:10.1145/3711896.3736564. 53
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.