U²Flow: Uncertainty-Aware Unsupervised Optical Flow Estimation
Pith reviewed 2026-05-10 15:23 UTC · model grok-4.3
The pith
A recurrent unsupervised framework jointly estimates optical flow and per-pixel uncertainty from augmentation consistency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
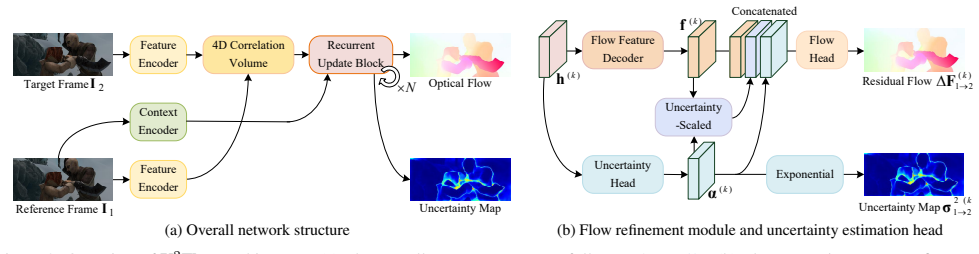
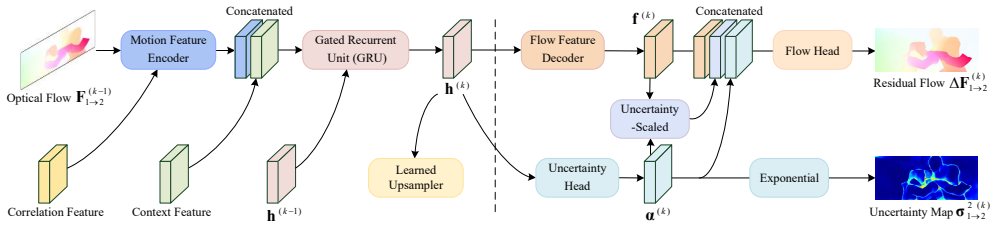
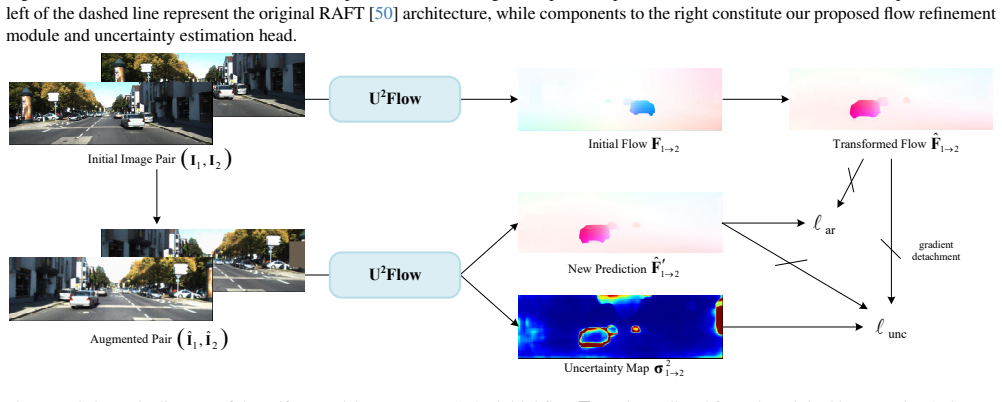
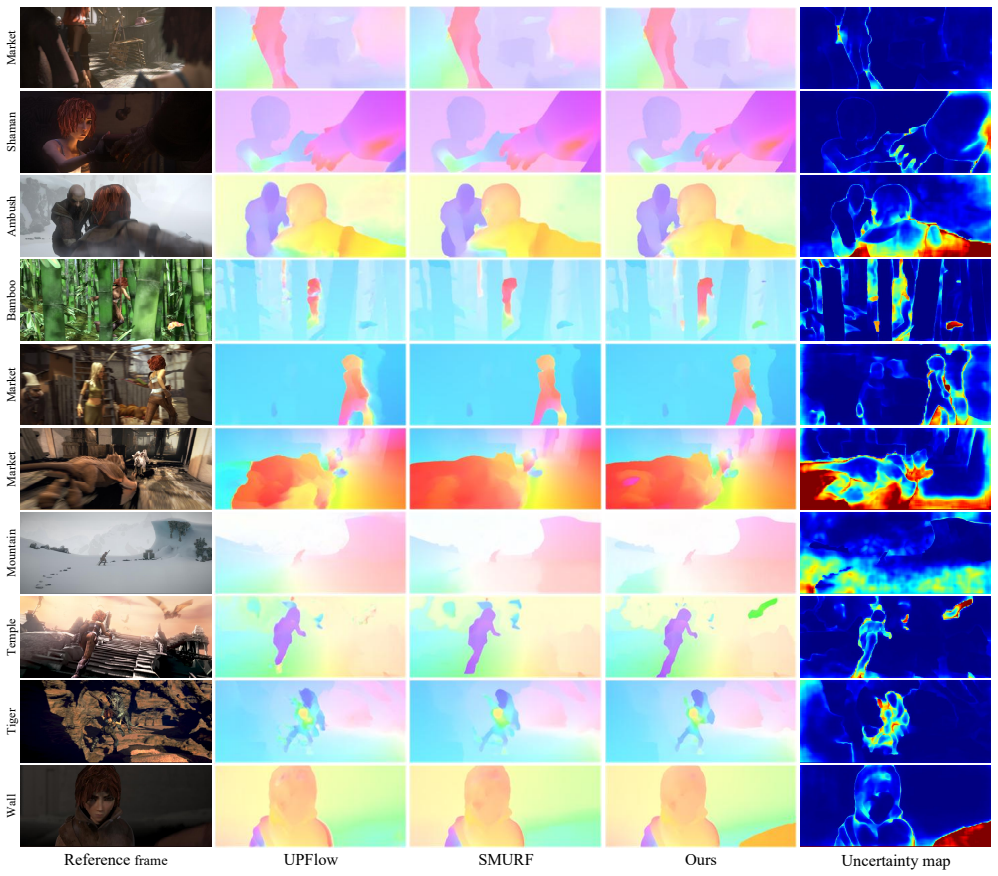
U^{2}Flow is the first recurrent unsupervised framework that jointly estimates optical flow and per-pixel uncertainty. A decoupled learning strategy derives uncertainty supervision from augmentation consistency via a Laplace-based maximum likelihood objective, enabling stable training without ground truth. The predicted uncertainty is integrated to guide adaptive flow refinement, dynamically modulate the regional smoothness loss, and enable an uncertainty-guided bidirectional flow fusion mechanism that enhances robustness in challenging regions.
What carries the argument
The decoupled learning strategy that derives uncertainty supervision from augmentation consistency via a Laplace-based maximum likelihood objective.
If this is right
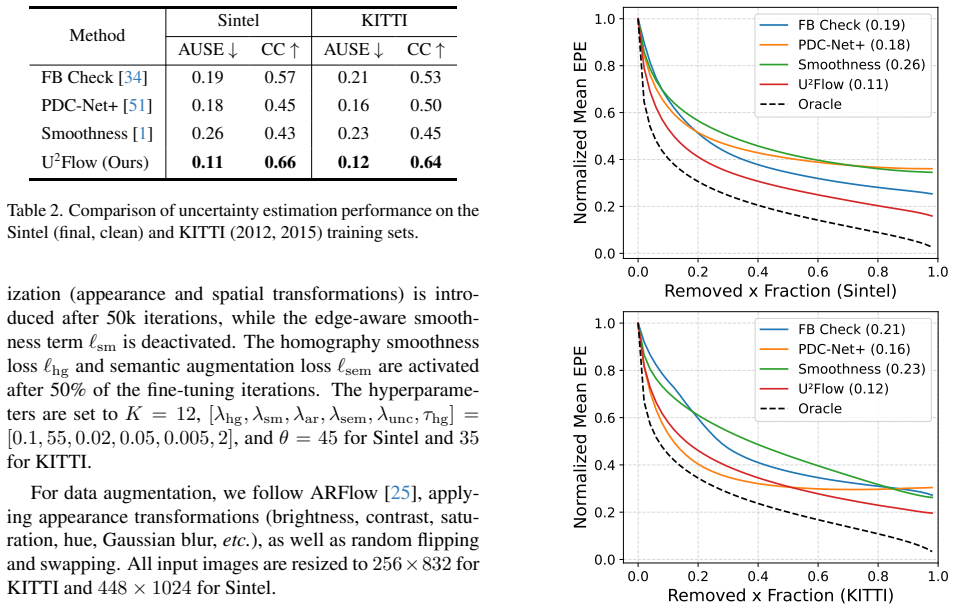
- Achieves state-of-the-art accuracy among all unsupervised optical flow methods on the KITTI and Sintel benchmarks.
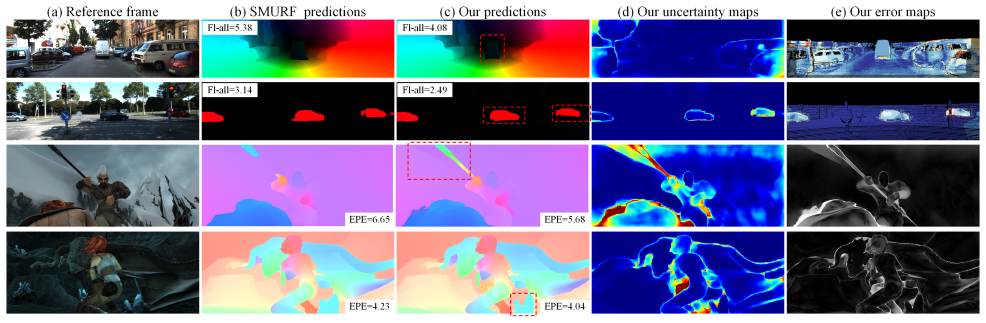
- Generates per-pixel uncertainty maps that align with actual prediction errors.
- Uncertainty integration produces adaptive refinement and stronger robustness via modulated smoothness and bidirectional fusion.
- Allows stable joint training of flow and uncertainty without any ground-truth labels or uncertainty annotations.
Where Pith is reading between the lines
- The same consistency-based supervision could transfer to other label-free vision tasks such as depth or stereo estimation where pixel-wise reliability is also useful.
- Downstream systems such as visual odometry or motion tracking could use the uncertainty maps to down-weight or ignore unreliable flow vectors.
- Evaluating the uncertainty maps on long real-world video sequences with varying lighting and motion would test whether they remain informative outside the training distribution.
Load-bearing premise
Consistency of flow estimates under image augmentations provides a reliable proxy for true per-pixel uncertainty without any labeled data.
What would settle it
Measuring whether the output uncertainty values rise in direct proportion to actual flow error on test sequences that do have ground-truth flow available for comparison.
Figures




read the original abstract
Unsupervised optical flow methods typically lack reliable uncertainty estimation, limiting their robustness and interpretability. We propose U$^{2}$Flow, the first recurrent unsupervised framework that jointly estimates optical flow and per-pixel uncertainty. The core innovation is a decoupled learning strategy that derives uncertainty supervision from augmentation consistency via a Laplace-based maximum likelihood objective, enabling stable training without ground truth. The predicted uncertainty is further integrated into the network to guide adaptive flow refinement and dynamically modulate the regional smoothness loss. Furthermore, we introduce an uncertainty-guided bidirectional flow fusion mechanism that enhances robustness in challenging regions. Extensive experiments on KITTI and Sintel demonstrate that U$^{2}$Flow achieves state-of-the-art performance among unsupervised methods while producing highly reliable uncertainty maps, validating the effectiveness of our joint estimation paradigm. The code is available at https://github.com/sunzunyi/U2FLOW.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces U²Flow, a recurrent unsupervised framework for jointly estimating optical flow and per-pixel uncertainty. The core contribution is a decoupled learning strategy that derives uncertainty supervision from augmentation consistency using a Laplace-based maximum likelihood objective, without requiring ground truth. Predicted uncertainty is integrated to guide adaptive flow refinement, dynamically modulate regional smoothness loss, and enable an uncertainty-guided bidirectional flow fusion mechanism. Experiments on KITTI and Sintel claim state-of-the-art performance among unsupervised methods alongside highly reliable uncertainty maps, validating the joint estimation paradigm. Code is released.
Significance. If the empirical claims and uncertainty reliability hold, this advances unsupervised optical flow by adding interpretability and robustness in challenging regions (occlusions, specularities) without GT supervision. The joint paradigm and code release support reproducibility and potential downstream use in tasks requiring uncertainty-aware flow.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): The SOTA claims on KITTI and Sintel lack reported baselines, error bars, ablation studies, or explicit data splits, preventing evaluation of whether gains are statistically meaningful or due to the joint uncertainty components versus standard photometric+smoothness losses.
- [§3.2] §3.2 (Decoupled Learning Strategy): The Laplace MLE objective treats augmentation-consistency variance as the target; this risks circularity because the same consistency signal supervises both flow and uncertainty. The manuscript must show (e.g., via per-pixel correlation plots or Spearman rank with held-out EPE) that the resulting uncertainty actually tracks real flow errors rather than merely re-weighting an already-optimized loss.
- [§3.3–3.4] §3.3–3.4 (Adaptive Refinement and Regional Smoothness): No ablation isolates the contribution of uncertainty-guided refinement and modulated smoothness versus the base unsupervised losses. If these modules only re-weight existing terms without adding new information, the “joint estimation paradigm” claim is not supported.
minor comments (2)
- [§3.1] Notation for the Laplace scale parameter and uncertainty map should be introduced once with a clear equation reference to avoid ambiguity in later sections.
- [§4] Tables reporting flow metrics should include standard deviations across runs or cross-validation folds to allow readers to judge stability of the reported improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have carefully reviewed each major comment and provide point-by-point responses below, indicating where revisions will be made to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The SOTA claims on KITTI and Sintel lack reported baselines, error bars, ablation studies, or explicit data splits, preventing evaluation of whether gains are statistically meaningful or due to the joint uncertainty components versus standard photometric+smoothness losses.
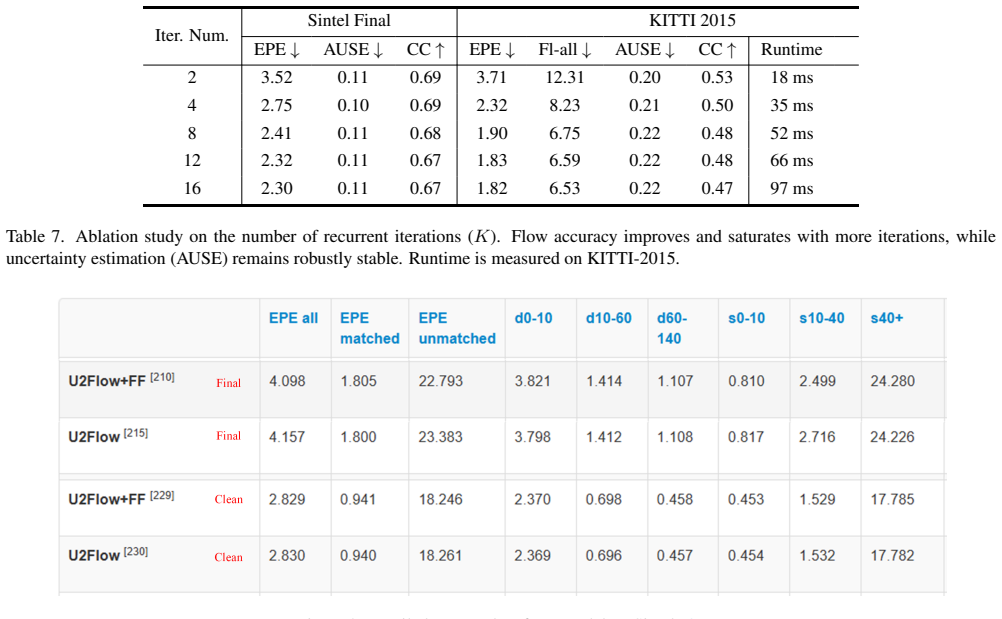
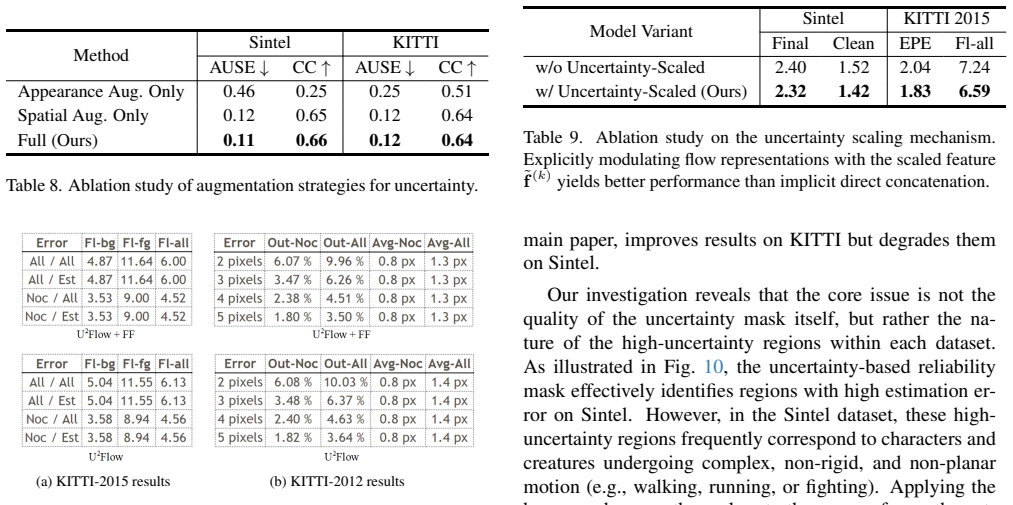
Authors: We appreciate the referee highlighting the need for greater transparency in the experimental reporting. The original manuscript does present comparisons against multiple unsupervised baselines in Tables 1 (KITTI) and 2 (Sintel), using the standard EPE and F1-all metrics under the conventional evaluation protocols. However, we acknowledge that error bars from repeated runs and explicit textual descriptions of the data splits were not included. In the revised version, we will add standard deviations computed over three independent training runs to the result tables and include a dedicated paragraph in Section 4 detailing the exact data splits (e.g., KITTI 2012/2015 training sets and Sintel clean/final training/validation splits). We will also expand the existing ablation studies to include statistical significance testing (paired t-tests) between the full model and the base photometric+smoothness baseline. These additions will allow readers to assess whether the reported gains are statistically meaningful and attributable to the uncertainty components. revision: partial
-
Referee: [§3.2] §3.2 (Decoupled Learning Strategy): The Laplace MLE objective treats augmentation-consistency variance as the target; this risks circularity because the same consistency signal supervises both flow and uncertainty. The manuscript must show (e.g., via per-pixel correlation plots or Spearman rank with held-out EPE) that the resulting uncertainty actually tracks real flow errors rather than merely re-weighting an already-optimized loss.
Authors: We understand the referee's concern about potential circularity in the supervision signal. The decoupled strategy intentionally uses augmentation consistency as a self-supervised proxy for uncertainty, grounded in the principle that robust flow predictions remain stable under photometric and geometric perturbations. To directly address the request for validation against actual errors, we have added new analysis to the revised manuscript: per-pixel scatter plots and Spearman rank correlation coefficients between the predicted uncertainty and held-out endpoint error on the Sintel dataset (using its ground-truth flow solely for post-hoc evaluation, not during training). These results demonstrate a positive correlation, indicating that high-uncertainty regions align with higher flow errors rather than simply re-weighting the loss. The plots and quantitative correlations will be included in an updated Section 3.2 and the supplementary material. revision: yes
-
Referee: [§3.3–3.4] §3.3–3.4 (Adaptive Refinement and Regional Smoothness): No ablation isolates the contribution of uncertainty-guided refinement and modulated smoothness versus the base unsupervised losses. If these modules only re-weight existing terms without adding new information, the “joint estimation paradigm” claim is not supported.
Authors: We thank the referee for this observation on the need for clearer isolation of component contributions. The original Section 4.3 contains ablation experiments comparing the full model to variants without refinement and without modulated smoothness. We agree that these could be presented more systematically to isolate incremental effects. In the revised manuscript, we will introduce a new sequential ablation table that cumulatively adds (1) the base photometric and smoothness losses, (2) uncertainty-guided adaptive refinement, (3) uncertainty-modulated regional smoothness, and (4) the bidirectional fusion mechanism, reporting EPE on both KITTI and Sintel for each stage. This will provide direct evidence that each uncertainty-aware module contributes measurable improvement beyond re-weighting of the base terms, thereby supporting the joint estimation paradigm. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The paper's central claim rests on a decoupled Laplace MLE objective that uses observed augmentation consistency as external supervision for the uncertainty head, while the flow head is trained under standard photometric and smoothness losses. This separation means the uncertainty prediction is not definitionally identical to the flow output or to the consistency metric itself; the network must learn to regress a per-pixel variance parameter that matches the empirical spread across augmentations. Integration of the predicted uncertainty into refinement and fusion is an additional downstream use rather than a closed loop that forces the result by construction. No load-bearing self-citation or uniqueness theorem is invoked in the abstract or described mechanism, and the SOTA performance is asserted via external benchmarks on KITTI and Sintel rather than by re-labeling fitted quantities. The chain from unsupervised losses to joint estimation therefore contains independent content.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Augmentation consistency provides a valid proxy for per-pixel uncertainty without ground truth
- standard math Photometric and smoothness assumptions hold sufficiently for unsupervised flow learning
Reference graph
Works this paper leans on
-
[1]
Self-supervised uncertainty-guided refinement for robust joint optical flow and depth estimation
Rokia Abdein, Wei Li, Chenghao Li, Xiangping Zheng, and Rahul Yadav. Self-supervised uncertainty-guided refinement for robust joint optical flow and depth estimation. InPro- ceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5, 2025. 2, 6
work page 2025
-
[2]
John L. Barron, David J. Fleet, and Steven S. Beauchemin. Performance of optical flow techniques.International Jour- nal of Computer Vision (IJCV), 12(1):43–77, 1994. 2
work page 1994
-
[3]
Andr ´es Bruhn and Joachim Weickert. A confidence measure for variational optic flow methods.Computational Imaging and Vision, page 283, 2006. 2
work page 2006
-
[4]
Butler, Jonas Wulff, Garrett B
Daniel J. Butler, Jonas Wulff, Garrett B. Stanley, and Michael J. Black. A naturalistic open source movie for opti- cal flow evaluation. InProceedings of the European Confer- ence on Computer Vision (ECCV), pages 611–625, 2012. 1, 5, 3, 4
work page 2012
-
[5]
Memflow: Optical flow es- timation and prediction with memory
Qiaole Dong and Yanwei Fu. Memflow: Optical flow es- timation and prediction with memory. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19068–19078, 2024. 1
work page 2024
-
[6]
Flownet: Learning optical flow with convolutional networks
Alexey Dosovitskiy, Philipp Fischer, Eddy Ilg, Philip Hausser, Caner Hazirbas, Vladimir Golkov, Patrick Van Der Smagt, Daniel Cremers, and Thomas Brox. Flownet: Learning optical flow with convolutional networks. InPro- ceedings of the IEEE International Conference on Computer Vision (ICCV), pages 2758–2766, 2015. 1
work page 2015
-
[7]
Dropout as a bayesian approximation: Representing model uncertainty in deep learning
Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. InProceedings of the 33rd International Con- ference on Machine Learning (ICML), pages 1050–1059. JMLR.org, 2016. 2
work page 2016
-
[8]
Lightweight probabilistic deep networks
Jochen Gast and Stefan Roth. Lightweight probabilistic deep networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3369–3378, 2018. 2
work page 2018
-
[9]
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset.The Inter- national Journal of Robotics Research (IJRR), 32(11):1231– 1237, 2013. 4, 5, 3
work page 2013
-
[10]
Hsin-Ping Huang, Charles Herrmann, Junhwa Hur, Erika Lu, Kyle Sargent, Austin Stone, Ming-Hsuan Yang, and Deqing Sun. Self-supervised autoflow. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11412–11421, 2023. 1
work page 2023
-
[11]
Flowformer: A transformer architecture for optical flow
Zhaoyang Huang, Xiaoyu Shi, Chao Zhang, Qiang Wang, Ka Chun Cheung, Hongwei Qin, Jifeng Dai, and Hongsheng Li. Flowformer: A transformer architecture for optical flow. InProceedings of the European Conference on Computer Vi- sion (ECCV), pages 668–685, 2022. 1, 5
work page 2022
-
[12]
Uncertainty es- timates and multi-hypotheses networks for optical flow
Eddy Ilg, ¨Ozg¨un C ¸ ic ¸ek, Silvio Galesso, Aaron Klein, Osama Makansi, Frank Hutter, and Thomas Brox. Uncertainty es- timates and multi-hypotheses networks for optical flow. In Proceedings of the European Conference on Computer Vi- sion (ECCV), pages 677–693. Springer, 2018. 1, 2, 4, 6
work page 2018
-
[13]
Optical flow with seman- tic guidance and uncertainty estimation for robust video per- ception
Andrei Iosif and Mihai Negru. Optical flow with seman- tic guidance and uncertainty estimation for robust video per- ception. InProceedings of the IEEE International Confer- ence on Intelligent Computer Communication and Process- ing (ICCP), pages 49–56, 2023. 1, 2, 4
work page 2023
-
[14]
Unsupervised learning of multi-frame optical flow with occlusions
Joel Janai, Fatma Guney, Anurag Ranjan, Michael Black, and Andreas Geiger. Unsupervised learning of multi-frame optical flow with occlusions. InProceedings of the Euro- pean Conference on Computer Vision (ECCV), pages 690– 706, 2018. 2
work page 2018
-
[15]
Learning to estimate hidden motions with global motion aggregation
Shihao Jiang, Dylan Campbell, Yao Lu, Hongdong Li, and Richard Hartley. Learning to estimate hidden motions with global motion aggregation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9772–9781, 2021. 5
work page 2021
-
[16]
What matters in unsupervised optical flow
Rico Jonschkowski, Austin Stone, Jonathan T Barron, Ariel Gordon, Kurt Konolige, and Anelia Angelova. What matters in unsupervised optical flow. InProceedings of the Euro- pean Conference on Computer Vision (ECCV), pages 557– 572, 2020. 1, 2, 5
work page 2020
-
[17]
Flownetu: Accurate uncertainty estimation of optical flow for video object detection
Jun-Gu Kang, Si-Dong Roh, and Ki-Seok Chung. Flownetu: Accurate uncertainty estimation of optical flow for video object detection. InProceedings of the International Con- ference on Artificial Intelligence and Pattern Recognition (AIPR), pages 36–41, 2022. 1, 2, 4
work page 2022
-
[18]
Cross-attention transformer for video interpola- tion
Hannah Halin Kim, Shuzhi Yu, Shuai Yuan, and Carlo Tomasi. Cross-attention transformer for video interpola- tion. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 320– 337, 2022. 1
work page 2022
-
[19]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
A statistical confidence measure for optical flows
Claudia Kondermann, Rudolf Mester, and Christoph Garbe. A statistical confidence measure for optical flows. InPro- ceedings of the European Conference on Computer Vision (ECCV), pages 290–301. Springer, 2008. 2
work page 2008
-
[21]
Jan Kybic and Claudia Nieuwenhuis. Bootstrap optical flow and uncertainty measure.Computer Vision and Image Un- derstanding (CVIU), 115(10):1449–1462, 2011. 2
work page 2011
-
[22]
Dense optical tracking: Connecting the dots
Guillaume Le Moing, Jean Ponce, and Cordelia Schmid. Dense optical tracking: Connecting the dots. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19187–19197, 2024. 1
work page 2024
-
[23]
Occlusionfusion: Occlusion-aware motion estimation for real-time dynamic 3d reconstruction
Wenbin Lin, Chengwei Zheng, Jun-Hai Yong, and Feng Xu. Occlusionfusion: Occlusion-aware motion estimation for real-time dynamic 3d reconstruction. InProceedings of 9 the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1736–1745, 2022. 1
work page 2022
-
[24]
Jiuming Liu, Guangming Wang, Weicai Ye, Chaokang Jiang, Jinru Han, Zhe Liu, Guofeng Zhang, Dalong Du, and Hes- heng Wang. Difflow3d: Toward robust uncertainty-aware scene flow estimation with iterative diffusion-based refine- ment. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 15109– 15119, 2024. 2
work page 2024
-
[25]
Liang Liu, Jiangning Zhang, Ruifei He, Yong Liu, Yabiao Wang, Ying Tai, Donghao Luo, Chengjie Wang, Jilin Li, and Feiyue Huang. Learning by analogy: Reliable supervision from transformations for unsupervised optical flow estima- tion. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 6488– 6497, 2020. 1, 2...
work page 2020
-
[26]
Pengpeng Liu, Irwin King, Michael R. Lyu, and Jia Xu. Ddflow: Learning optical flow with unlabeled data distilla- tion. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), pages 8770–8777, 2019. 2
work page 2019
-
[27]
Self- low: Self-supervised learning of optical flow
Pengpeng Liu, Michael Lyu, Irwin King, and Jia Xu. Self- low: Self-supervised learning of optical flow. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 4571–4580, 2019. 1, 2, 5
work page 2019
-
[28]
Flow2stereo: Effective self-supervised learning of optical flow and stereo matching
Pengpeng Liu, Irwin King, Michael R Lyu, and Jia Xu. Flow2stereo: Effective self-supervised learning of optical flow and stereo matching. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6648–6657, 2020. 1
work page 2020
-
[29]
Flowdiffuser: Advancing optical flow estimation with diffusion models
Ao Luo, Xin Li, Fan Yang, Jiangyu Liu, Haoqiang Fan, and Shuaicheng Liu. Flowdiffuser: Advancing optical flow estimation with diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19167–19176, 2024. 1, 5
work page 2024
-
[30]
Upflow: Upsampling pyramid for unsupervised optical flow learning
Kunming Luo, Chuan Wang, Shuaicheng Liu, Haoqiang Fan, Jue Wang, and Jian Sun. Upflow: Upsampling pyramid for unsupervised optical flow learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1045–1054, 2021. 1, 2, 5, 6, 4
work page 2021
-
[31]
Oisin Mac Aodha, Ahmad Humayun, Marc Pollefeys, and Gabriel J Brostow. Learning a confidence measure for optical flow.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 35(5):1107–1120, 2012. 2
work page 2012
-
[32]
Brightflow: Brightness-change-aware un- supervised learning of optical flow
R ´emi Marsal, Florian Chabot, Ang ´elique Loesch, and Hichem Sahbi. Brightflow: Brightness-change-aware un- supervised learning of optical flow. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 2061–2070, 2023. 1, 2
work page 2061
-
[33]
Spring: A high-resolution high- detail dataset and benchmark for scene flow, optical flow and stereo
Lukas Mehl, Jenny Schmalfuss, Azin Jahedi, Yaroslava Nali- vayko, and Andr ´es Bruhn. Spring: A high-resolution high- detail dataset and benchmark for scene flow, optical flow and stereo. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 4981– 4991, 2023. 4, 5
work page 2023
-
[34]
Unflow: Un- supervised learning of optical flow with a bidirectional cen- sus loss
Simon Meister, Junhwa Hur, and Stefan Roth. Unflow: Un- supervised learning of optical flow with a bidirectional cen- sus loss. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2018. 1, 2, 3, 5, 6, 4
work page 2018
-
[35]
Object scene flow for au- tonomous vehicles
Moritz Menze and Andreas Geiger. Object scene flow for au- tonomous vehicles. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 3061–3070, 2015. 4, 5, 3
work page 2015
-
[36]
On the uncertainty of self-supervised monocular depth estimation
Matteo Poggi, Filippo Aleotti, Fabio Tosi, and Stefano Mat- toccia. On the uncertainty of self-supervised monocular depth estimation. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 3227–3237, 2020. 1
work page 2020
-
[37]
Unsupervised deep learning for optical flow estimation
Zhe Ren, Junchi Yan, Bingbing Ni, Bin Liu, Xiaokang Yang, and Hongyuan Zha. Unsupervised deep learning for optical flow estimation. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2017. 2
work page 2017
-
[38]
Stephan R Richter, Zeeshan Hayder, and Vladlen Koltun. Playing for benchmarks. InProceedings of the IEEE In- ternational Conference on Computer Vision (ICCV), pages 2213–2222, 2017. 5
work page 2017
-
[39]
Shihao Shen, Louis Kerofsky, and Senthil Yogamani. Optical flow for autonomous driving: Applications, challenges and improvements.arXiv preprint arXiv:2301.04422, 2023. 1
-
[40]
Yichen Shen, Zhilu Zhang, Mert R. Sabuncu, and Lin Sun. Real-time uncertainty estimation in computer vision via uncertainty-aware distribution distillation. InProceedings of the IEEE/CVF Winter Conference on Applications of Com- puter Vision (WACV), pages 707–716, 2021. 1, 2, 4
work page 2021
-
[41]
Videoflow: Exploiting temporal cues for multi-frame optical flow estimation
Xiaoyu Shi, Zhaoyang Huang, Weikang Bian, Dasong Li, Manyuan Zhang, Ka Chun Cheung, Simon See, Hongwei Qin, Jifeng Dai, and Hongsheng Li. Videoflow: Exploiting temporal cues for multi-frame optical flow estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 12435–12446, 2023. 1, 5
work page 2023
-
[42]
Flowformer++: Masked cost volume autoen- coding for pretraining optical flow estimation
Xiaoyu Shi, Zhaoyang Huang, Dasong Li, Manyuan Zhang, Ka Chun Cheung, Simon See, Hongwei Qin, Jifeng Dai, and Hongsheng Li. Flowformer++: Masked cost volume autoen- coding for pretraining optical flow estimation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1599–1610, 2023. 1
work page 2023
-
[43]
Super-convergence: Very fast training of neural networks using large learn- ing rates
Leslie N Smith and Nicholay Topin. Super-convergence: Very fast training of neural networks using large learn- ing rates. InArtificial Intelligence and Machine Learning for Multi-Domain Operations Applications, pages 369–386,
-
[44]
Smurf: Self-teaching multi- frame unsupervised raft with full-image warping
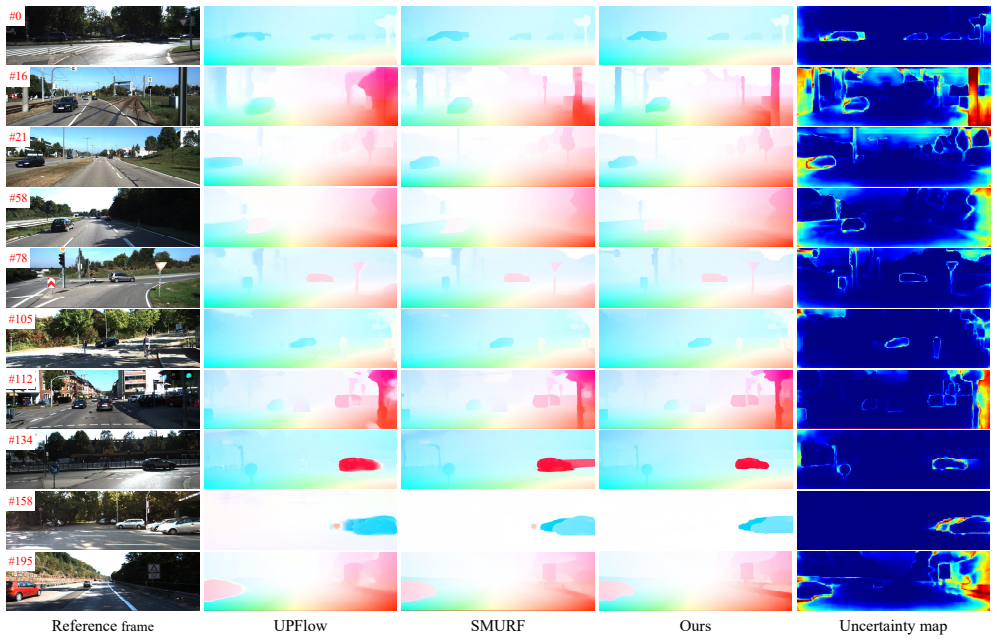
Austin Stone, Daniel Maurer, Alper Ayvaci, Anelia An- gelova, and Rico Jonschkowski. Smurf: Self-teaching multi- frame unsupervised raft with full-image warping. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3887–3896, 2021. 2, 5, 6, 7, 4
work page 2021
-
[45]
Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume
Deqing Sun, Xiaodong Yang, Ming-Yu Liu, and Jan Kautz. Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8934–8943, 2018. 1
work page 2018
-
[46]
Deqing Sun, Xiaodong Yang, Ming-Yu Liu, and Jan Kautz. Models matter, so does training: An empirical study of cnns for optical flow estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 42(6):1408– 1423, 2019. 1, 5 10
work page 2019
-
[47]
Autoflow: Learning a better training set for optical flow
Deqing Sun, Daniel Vlasic, Charles Herrmann, Varun Jampani, Michael Krainin, Huiwen Chang, Ramin Zabih, William T Freeman, and Ce Liu. Autoflow: Learning a better training set for optical flow. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10093–10102, 2021. 1
work page 2021
-
[48]
Deqing Sun, Charles Herrmann, Fitsum Reda, Michael Ru- binstein, David J. Fleet, and William T. Freeman. Disen- tangling architecture and training for optical flow. InPro- ceedings of the European Conference on Computer Vision (ECCV), pages 165–182, 2022. 1
work page 2022
-
[49]
Xunpei Sun, Gang Chen, and Zuoxun Hou. M2flow: A motion information fusion framework for enhanced unsuper- vised optical flow estimation in autonomous driving. InPro- ceedings of the AAAI Conference on Artificial Intelligence (AAAI), pages 7140–7148, 2025. 1, 2, 5, 6
work page 2025
-
[50]
Raft: Recurrent all-pairs field transforms for optical flow
Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. InProceedings of the European Conference on Computer Vision (ECCV), pages 402–419,
-
[51]
Prune Truong, Martin Danelljan, Radu Timofte, and Luc Van Gool. Pdc-net+: Enhanced probabilistic dense corre- spondence network.IEEE Transactions on Pattern Analy- sis and Machine Intelligence (TPAMI), 45(8):10247–10266,
-
[52]
Itermvs: Iterative probability estimation for efficient multi-view stereo
Fangjinhua Wang, Silvano Galliani, Christoph V ogel, and Marc Pollefeys. Itermvs: Iterative probability estimation for efficient multi-view stereo. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8606–8615, 2022. 2
work page 2022
-
[53]
Occlusion aware unsupervised learning of optical flow
Yang Wang, Yi Yang, Zhenheng Yang, Liang Zhao, Peng Wang, and Wei Xu. Occlusion aware unsupervised learning of optical flow. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4884–4893, 2018. 1, 2
work page 2018
-
[54]
Probflow: Joint optical flow and uncertainty estimation
Anne S Wannenwetsch, Margret Keuper, and Stefan Roth. Probflow: Joint optical flow and uncertainty estimation. In Proceedings of the IEEE International Conference on Com- puter Vision (ICCV), pages 1173–1182, 2017. 1, 2, 6
work page 2017
-
[55]
Gmflow: Learning optical flow via global matching
Haofei Xu, Jing Zhang, Jianfei Cai, Hamid Rezatofighi, and Dacheng Tao. Gmflow: Learning optical flow via global matching. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8121–8130, 2022. 5
work page 2022
-
[56]
Hierarchical dis- crete distribution decomposition for match density estima- tion
Zhichao Yin, Trevor Darrell, and Fisher Yu. Hierarchical dis- crete distribution decomposition for match density estima- tion. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 6037– 6046, 2019. 2
work page 2019
-
[57]
Optical flow training under limited label budget via active learning
Shuai Yuan, Xian Sun, Hannah Kim, Shuzhi Yu, and Carlo Tomasi. Optical flow training under limited label budget via active learning. InProceedings of the European Conference on Computer Vision (ECCV), pages 410–427, 2022. 1
work page 2022
-
[58]
Semarflow: Injecting semantics into unsupervised optical flow estimation for autonomous driving
Shuai Yuan, Shuzhi Yu, Hannah Kim, and Carlo Tomasi. Semarflow: Injecting semantics into unsupervised optical flow estimation for autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9566–9577, 2023. 2, 5, 6
work page 2023
-
[59]
Unsamflow: Unsu- pervised optical flow guided by segment anything model
Shuai Yuan, Lei Luo, Zhuo Hui, Can Pu, Xiaoyu Xiang, Rakesh Ranjan, and Denis Demandolx. Unsamflow: Unsu- pervised optical flow guided by segment anything model. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 19027–19037,
-
[60]
Optical flow boosts unsupervised localization and segmentation
Xinyu Zhang and Abdeslam Boularias. Optical flow boosts unsupervised localization and segmentation. InProceed- ings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7635–7642, 2023. 1
work page 2023
-
[61]
Yushan Zhang, Bastian Wandt, Maria Magnusson, and Michael Felsberg. Diffsf: Diffusion models for scene flow estimation.Advances in Neural Information Processing Sys- tems (NeurIPS), 37:11227–11247, 2024. 2
work page 2024
-
[62]
Clearer frames, anytime: Re- solving velocity ambiguity in video frame interpolation
Zhihang Zhong, Gurunandan Krishnan, Xiao Sun, Yu Qiao, Sizhuo Ma, and Jian Wang. Clearer frames, anytime: Re- solving velocity ambiguity in video frame interpolation. In Proceedings of the European Conference on Computer Vi- sion (ECCV), pages 346–363, 2024. 1
work page 2024
-
[63]
Kaichen Zhou, Jia-Wang Bian, Jian-Qing Zheng, Jiaxing Zhong, Qian Xie, Niki Trigoni, and Andrew Markham. Manydepth2: Motion-aware self-supervised monocular depth estimation in dynamic scenes.IEEE Robotics and Au- tomation Letters, 2025. 1
work page 2025
-
[64]
Mo Zhou, Jingwei Wang, Xinyu Zhang, Dylan Camp- bell, Kaixuan Wang, Li Yuan, and Xiao Lin. Probdiff- flow: An efficient learning-free framework for probabilis- tic single-image optical flow estimation.arXiv preprint arXiv:2503.12348, 2025. 2 11 U2Flow: Uncertainty-Aware Unsupervised Optical Flow Estimation Supplementary Material A. Method details A.1. Rec...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.