Recognition: unknown
Trust Your Memory: Verifiable Control of Smart Homes through Reinforcement Learning with Multi-dimensional Rewards
Pith reviewed 2026-05-10 16:44 UTC · model grok-4.3
The pith
Multi-dimensional rewards in reinforcement learning provide intermediate feedback that improves memory-driven device control in smart homes over conventional outcome-only methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Conventional RL methods that rely only on outcome-based supervision produce sub-optimal results in fine-grained memory management tasks such as adding, updating, deleting, and utilizing memory for device control. Multi-dimensional rewards supply intermediate feedback on each subtask, and the new MemHome benchmark, constructed from anonymized real-world long-term interaction logs in MemHomeLife, enables systematic evaluation of memory-driven smart-home control.
What carries the argument
Multi-dimensional rewards that assign separate signals to memory subtasks (adding, updating, deleting, utilizing) to supply intermediate supervision inside reinforcement learning.
If this is right
- RL agents receive guidance on each memory operation instead of only final task completion, reducing local failures in long sequences of device control.
- The MemHome benchmark allows separate measurement of performance on adding, updating, deleting, and utilizing memory, supporting targeted method improvements.
- Models can maintain consistent memory states across extended user interactions, enabling more reliable personalization of smart-home devices.
- Evaluation gaps between immediate device control and general memory retrieval are closed for smart-home scenarios.
Where Pith is reading between the lines
- The same reward decomposition could be applied to other RL settings that require fine-grained state tracking, such as multi-turn dialogue or personal scheduling assistants.
- Automatically learning the weights or structure of the multi-dimensional rewards might reduce the manual design burden while preserving the intermediate feedback benefit.
- Combining the RL memory component with large language models could be tested to determine whether the added supervision improves the factual accuracy of LLM-based smart-home controllers.
Load-bearing premise
Multi-dimensional rewards can be designed to give effective intermediate feedback on memory subtasks without introducing new biases or requiring extensive manual tuning.
What would settle it
A controlled comparison in which agents trained with the multi-dimensional rewards show no gain, or a drop, in success rate on the memory subtasks of the MemHome benchmark relative to standard outcome-only RL.
Figures



read the original abstract
Large Language Models (LLMs) have become a key foundation for enabling personalized smart home experiences. While existing studies have explored how smart home assistants understand user queries to control devices in real time, their ability to perform memory-driven device control remains challenging from both evaluation and methodological perspectives. In terms of evaluation, existing benchmarks either focus on immediate device control or general open-domain memory retrieval tasks, and therefore cannot effectively evaluate a model's ability to perform memory-driven device control. Methodologically, while memory-driven device control can be approached using Reinforcement Learning, conventional RL methods generally rely on outcome-based supervision (i.e., whether the final task is achieved). This lack of intermediate feedback can lead to sub-optimal performance or local failures in fine-grained memory management tasks (adding, updating, deleting, and utilizing). To address these issues, we first release MemHomeLife, built from anonymized real-world long-term user interaction logs. To enable more fine-grained evaluation of different memory-related subtasks, we further construct MemHome, the first benchmark designed to systematically evaluate memory-driven device control in smart home scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing benchmarks are inadequate for evaluating memory-driven device control in smart homes, and that conventional outcome-based RL leads to sub-optimal performance on fine-grained memory subtasks (add, update, delete, utilize). It releases MemHomeLife (anonymized real-world logs) and constructs the MemHome benchmark to enable systematic evaluation, while proposing RL with multi-dimensional rewards to supply intermediate feedback and improve verifiable control.
Significance. If the multi-dimensional rewards can be shown to deliver robust, low-bias intermediate signals without heavy per-task tuning, the work would meaningfully advance RL applications for personalized, memory-aware smart-home agents. The public release of a real-log-derived dataset and a dedicated benchmark is a concrete contribution that could support future reproducible research in this area.
major comments (3)
- [Methods / Reward Design] The central methodological claim—that multi-dimensional rewards overcome the limitations of outcome-based supervision—rests on the specific reward functions for the four memory subtasks. No evidence is provided that these functions are robust to formulation choices or free of bias introduced by hand-engineering from the MemHomeLife logs; without such validation (e.g., sensitivity analysis or ablation on reward components), reported gains may be artifacts of shaping rather than a general advance.
- [Experiments / Results] The abstract states that conventional RL yields sub-optimal performance or local failures on fine-grained memory tasks, yet no quantitative comparison (success rates, failure modes, or learning curves) between outcome-based and multi-dimensional reward variants is referenced. This comparison is load-bearing for the paper’s motivation and must be shown on the MemHome benchmark.
- [Benchmark Construction] The MemHome benchmark construction is described only at a high level; it is unclear how the four subtasks are operationalized into episodes, what state representation is used for the RL agent, and whether the benchmark includes held-out users or temporal splits that would test generalization beyond the training logs.
minor comments (2)
- [Abstract / Introduction] The title refers to “verifiable control,” but the abstract does not define what verification mechanism is used or how the RL policy is made verifiable; this should be clarified early in the introduction.
- [Abstract] The abstract contains a minor grammatical issue: “their ability to perform memory-driven device control remains challenging from both evaluation and methodological perspectives” would read more clearly as “remains challenging both from an evaluation and from a methodological perspective.”
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback on our manuscript. We believe the comments will help improve the clarity and rigor of the work. We address each major comment below and plan to incorporate revisions as indicated.
read point-by-point responses
-
Referee: [Methods / Reward Design] The central methodological claim—that multi-dimensional rewards overcome the limitations of outcome-based supervision—rests on the specific reward functions for the four memory subtasks. No evidence is provided that these functions are robust to formulation choices or free of bias introduced by hand-engineering from the MemHomeLife logs; without such validation (e.g., sensitivity analysis or ablation on reward components), reported gains may be artifacts of shaping rather than a general advance.
Authors: We agree that demonstrating the robustness of the multi-dimensional reward design is crucial for the central claim. In the revised manuscript, we will add a sensitivity analysis varying the weights and formulations of the reward components across the four subtasks, together with ablations that isolate individual reward dimensions. These additions will provide evidence that performance gains are not artifacts of the specific hand-engineered functions derived from the logs. revision: yes
-
Referee: [Experiments / Results] The abstract states that conventional RL yields sub-optimal performance or local failures on fine-grained memory tasks, yet no quantitative comparison (success rates, failure modes, or learning curves) between outcome-based and multi-dimensional reward variants is referenced. This comparison is load-bearing for the paper’s motivation and must be shown on the MemHome benchmark.
Authors: We acknowledge that the abstract claim requires direct supporting evidence. We will revise the manuscript to prominently present and reference the quantitative comparisons between outcome-based and multi-dimensional reward RL variants, including success rates, failure modes, and learning curves evaluated on the MemHome benchmark. The abstract will be updated to cite these results explicitly. revision: yes
-
Referee: [Benchmark Construction] The MemHome benchmark construction is described only at a high level; it is unclear how the four subtasks are operationalized into episodes, what state representation is used for the RL agent, and whether the benchmark includes held-out users or temporal splits that would test generalization beyond the training logs.
Authors: We will expand the benchmark construction section with concrete details. The revision will specify how the add, update, delete, and utilize subtasks are operationalized as RL episodes, describe the precise state representation provided to the agent, and clarify the use of held-out users together with temporal splits to evaluate generalization beyond the training logs. revision: yes
Circularity Check
No circularity: contributions are benchmark release and empirical RL proposal without self-referential derivations
full rationale
The paper introduces MemHomeLife (from real logs) and MemHome benchmark for memory-driven device control, then proposes multi-dimensional rewards to supply intermediate feedback for subtasks (add/update/delete/utilize) where outcome-only RL fails. No equations, uniqueness theorems, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claim—that multi-dimensional rewards improve fine-grained performance—is an empirical hypothesis tested on the new benchmark, not a reduction to inputs by construction. This is the expected non-finding for a data-release + method-proposal paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qingyao Ai, Yichen Tang, Changyue Wang, Jianming Long, Weihang Su, and Yiqun Liu. 2025. MemoryBench: A Benchmark for Memory and Continual Learning in LLM Systems.arXiv preprint arXiv:2510.17281(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Ya- dav. 2025. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413(2025)
work page internal anchor Pith review arXiv 2025
- [3]
-
[4]
Evan King, Haoxiang Yu, Sangsu Lee, and Christine Julien. 2024. Sasha: creative goal-oriented reasoning in smart homes with large language models.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies8, 1 (2024), 1–38
2024
-
[5]
Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, and Sushant Prakash. 2024. RLAIF vs. RLHF: scaling reinforcement learning from human feedback with AI feedback. InProceedings of the 41st International Con- ference on Machine Learning(Vienna, Austria)(ICML’24)...
2024
- [6]
-
[7]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. 2024. Evaluating Very Long-Term Conversational Memory of LLM Agents. InProceedings of the 62nd Annual Meeting of the Associ- ation for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Com...
-
[9]
Charles Packer, Vivian Fang, Shishir_G Patil, Kevin Lin, Sarah Wooders, and Joseph_E Gonzalez. 2023. MemGPT: Towards LLMs as Operating Systems. (2023)
2023
-
[10]
Hao Peng, Yunjia Qi, Xiaozhi Wang, Bin Xu, Lei Hou, and Juanzi Li. 2025. VerIF: Verification Engineering for Reinforcement Learning in Instruction Following. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.). Association for Comput...
-
[11]
Dmitriy Rivkin, Francois Hogan, Amal Feriani, Abhisek Konar, Adam Sigal, Xue Liu, and Gregory Dudek. 2024. Aiot smart home via autonomous llm agents. IEEE Internet of Things Journal(2024)
2024
- [12]
-
[13]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [14]
-
[15]
Haoran Tan, Zeyu Zhang, Chen Ma, Xu Chen, Quanyu Dai, and Zhenhua Dong
-
[16]
InFindings of the Association for Computational Linguistics: ACL 2025
MemBench: Towards More Comprehensive Evaluation on the Memory Trust Your Memory: Verifiable Control of Smart Homes through Reinforcement Learning with Multi-dimensional Rewards of LLM-based Agents. InFindings of the Association for Computational Linguis- tics: ACL 2025, Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Moham- mad Taher Pilehvar (Eds.). ...
- [17]
-
[18]
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, et al . 2025. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534(2025)
work page internal anchor Pith review arXiv 2025
-
[19]
Qwen Team. 2024. Qwen2.5: A Party of Foundation Models. https://qwenlm. github.io/blog/qwen2.5/
2024
- [20]
- [21]
-
[22]
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. 2024. Longmemeval: Benchmarking chat assistants on long-term interactive memory.arXiv preprint arXiv:2410.10813(2024)
work page internal anchor Pith review arXiv 2024
-
[23]
Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Kristian Kersting, Jeff Z Pan, Hinrich Schütze, et al. 2025. Memory- r1: Enhancing large language model agents to manage and utilize memories via reinforcement learning.arXiv preprint arXiv:2508.19828(2025)
work page internal anchor Pith review arXiv 2025
-
[24]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [25]
- [26]
-
[27]
打开空调,就要设置25度
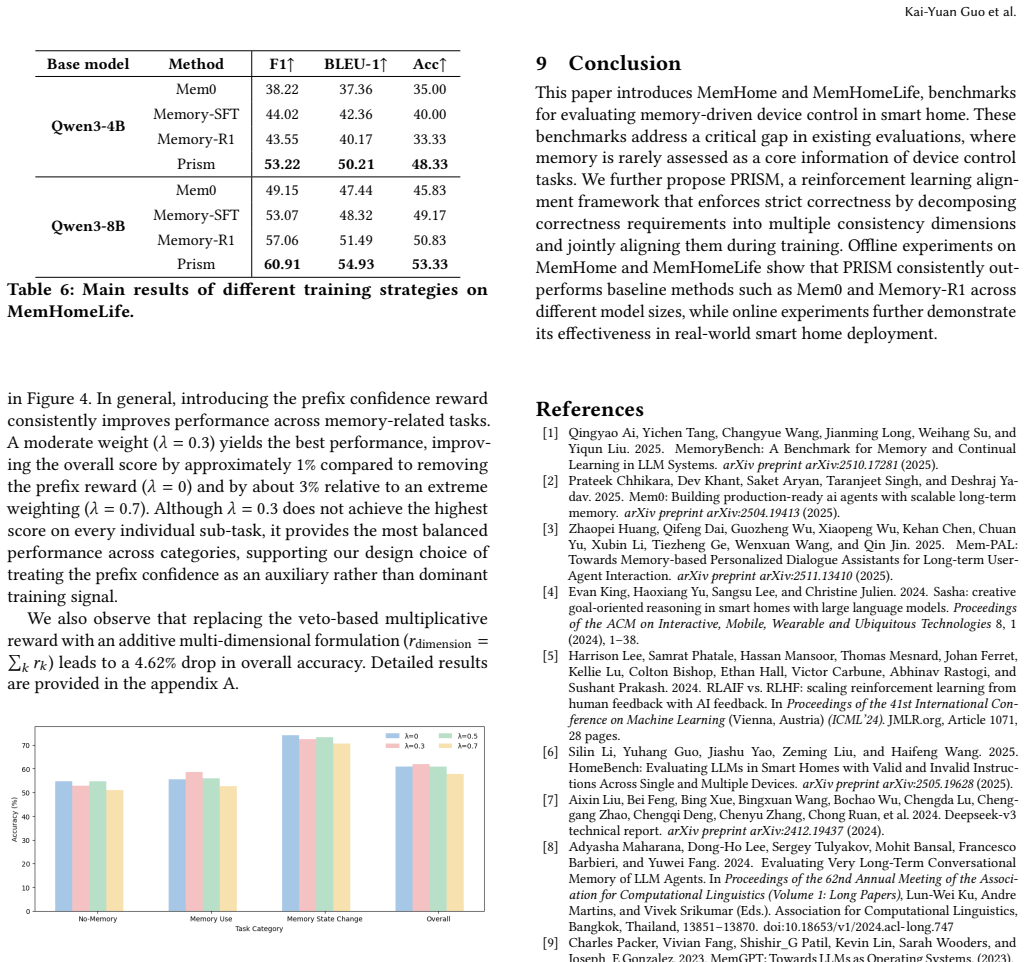
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. 2024. Memo- rybank: Enhancing large language models with long-term memory. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 19724–19731. Kai-Yuan Guo et al. A Ablation on Reward Design. The detailed results of ablation studies under different prefix reward weights and ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.