A Comparison of Multi-View Stereo Methods for Photogrammetric 3D Reconstruction: From Traditional to Learning-Based Approaches
Pith reviewed 2026-05-10 16:23 UTC · model grok-4.3
The pith
End-to-end learning-based MVS methods provide competitive accuracy and faster reconstruction than traditional COLMAP but with larger residuals in challenging scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
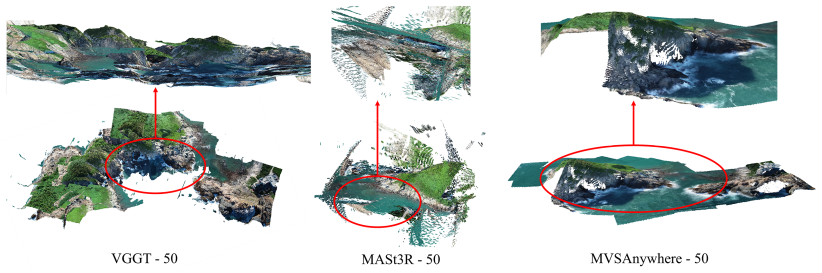
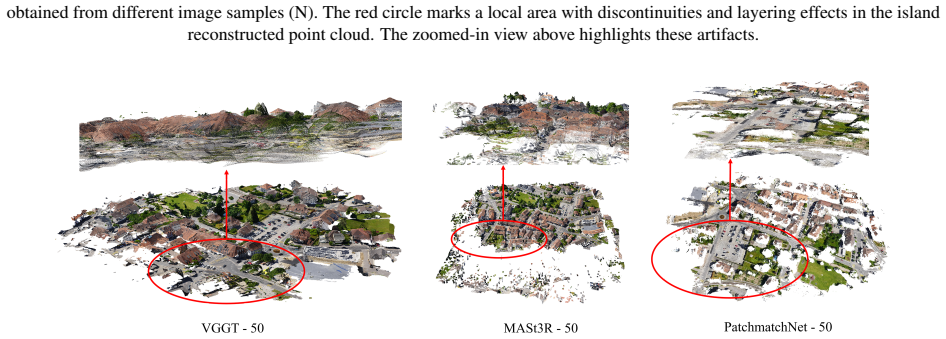
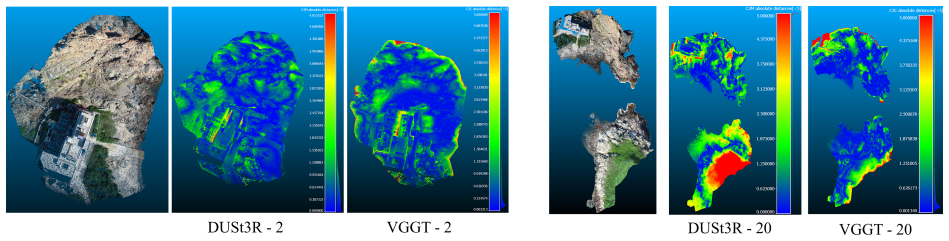
Experimental results show that although COLMAP can provide reliable and geometrically consistent reconstruction results, it requires more computation time. In cases where traditional methods fail in image registration, learning-based approaches exhibit stronger feature-matching capability and greater robustness. Geometry-guided methods usually require careful dataset preparation and often depend on camera pose or depth priors generated by COLMAP. End-to-end methods such as DUSt3R and VGGT achieve competitive accuracy and reasonable coverage while offering substantially faster reconstruction. However, they exhibit relatively large residuals in 3D reconstruction, particularly in challenging 3D
What carries the argument
Comparative benchmarking of accuracy, coverage, and runtime between the COLMAP traditional pipeline and learning-based MVS methods on two aerial datasets with independent ground truth.
If this is right
- COLMAP provides reliable and geometrically consistent reconstruction but requires more computation time.
- Learning-based approaches exhibit stronger feature-matching capability and greater robustness when traditional image registration fails.
- Geometry-guided methods usually require camera pose or depth priors generated by COLMAP.
- End-to-end methods such as DUSt3R and VGGT achieve competitive accuracy and reasonable coverage with substantially faster reconstruction.
- End-to-end methods exhibit relatively large residuals in 3D reconstruction, particularly in challenging scenarios.
Where Pith is reading between the lines
- Hybrid pipelines that use learning-based methods for initial registration and traditional refinement for final geometry could combine speed with lower residuals.
- The speed gains of end-to-end approaches could support real-time or very large-scale aerial mapping that traditional pipelines currently limit.
- Extending tests to non-aerial scenes would clarify whether the accuracy-residual trade-off is specific to the aerial domain.
- Incorporating geometric constraints into end-to-end networks might reduce the observed residuals without sacrificing runtime.
Load-bearing premise
The two chosen aerial datasets and the specific implementations of the compared methods are representative enough to support general conclusions about traditional versus learning-based performance.
What would settle it
If a third dataset with different characteristics, such as ground-level urban imagery, shows end-to-end methods consistently producing smaller residuals than COLMAP while preserving the speed advantage, the observed trade-off would not hold.
Figures

read the original abstract
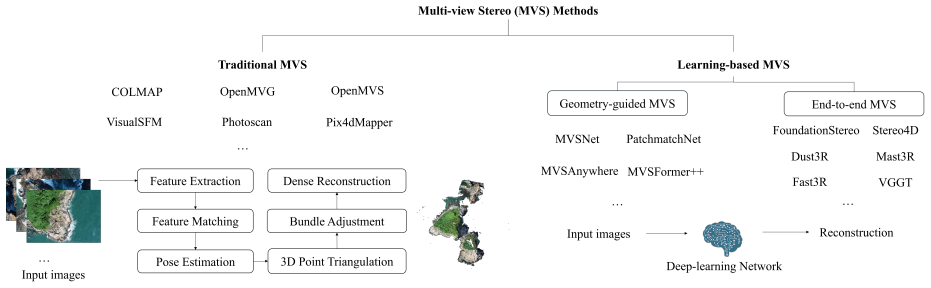
Photogrammetric 3D reconstruction has long relied on traditional Structure-from-Motion (SfM) and Multi-View Stereo (MVS) methods, which provide high accuracy but face challenges in speed and scalability. Recently, learning-based MVS methods have emerged, aiming for faster and more efficient reconstruction. This work presents a comparative evaluation between a representative traditional MVS pipeline (COLMAP) and state-of-the-art learning-based approaches, including geometry-guided methods (MVSNet, PatchmatchNet, MVSAnywhere, MVSFormer++) and end-to-end frameworks (Stereo4D, FoundationStereo, DUSt3R, MASt3R, Fast3R, VGGT). Two experiments were conducted on different aerial scenarios. The first experiment used the MARS-LVIG dataset, where ground-truth 3D reconstruction was provided by LiDAR point clouds. The second experiment used a public scene from the Pix4D official website, with ground truth generated by Pix4Dmapper. We evaluated accuracy, coverage, and runtime across all methods. Experimental results show that although COLMAP can provide reliable and geometrically consistent reconstruction results, it requires more computation time. In cases where traditional methods fail in image registration, learning-based approaches exhibit stronger feature-matching capability and greater robustness. Geometry-guided methods usually require careful dataset preparation and often depend on camera pose or depth priors generated by COLMAP. End-to-end methods such as DUSt3R and VGGT achieve competitive accuracy and reasonable coverage while offering substantially faster reconstruction. However, they exhibit relatively large residuals in 3D reconstruction, particularly in challenging scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper performs an empirical comparison of a traditional SfM/MVS pipeline (COLMAP) against geometry-guided learning-based MVS methods (MVSNet, PatchmatchNet, MVSAnywhere, MVSFormer++) and end-to-end frameworks (Stereo4D, FoundationStereo, DUSt3R, MASt3R, Fast3R, VGGT) for photogrammetric 3D reconstruction. Experiments are run on two aerial datasets (MARS-LVIG with LiDAR ground truth and one Pix4D public scene with Pix4Dmapper ground truth), evaluating accuracy, coverage, and runtime; the central claim is that end-to-end methods deliver competitive accuracy and coverage at substantially lower runtime while COLMAP is more reliable but slower, with learning-based methods showing greater robustness when traditional registration fails.
Significance. If the quantitative results hold, the work supplies useful practical guidance on speed-accuracy-coverage trade-offs for aerial photogrammetry applications. The explicit inclusion of both geometry-guided and end-to-end learning methods, together with named ground-truth sources, strengthens the comparison; however, the narrow dataset scope reduces broader significance for the field.
major comments (2)
- [Experiments] The experimental evaluation (described in the abstract and Experiments section) is confined to two large-scale aerial/nadir datasets with similar viewpoint distributions and texture properties. This choice does not test the observed accuracy-coverage-runtime-residual pattern in close-range, terrestrial, oblique, or indoor regimes where feature-matching statistics, scale ambiguity, and occlusion differ markedly, so the general statements contrasting traditional versus learning-based approaches rest on an unrepresentative sample.
- [Results] The abstract states that DUSt3R and VGGT achieve 'competitive accuracy' and 'reasonable coverage' yet 'relatively large residuals in 3D reconstruction,' but the provided description contains no quantitative tables, error histograms, or per-scene metrics that would allow verification of these claims or assessment of implementation fairness (e.g., whether COLMAP and learning-based pipelines used identical camera poses or depth priors).
minor comments (1)
- [Abstract] The abstract refers to 'three evaluation axes' without naming them; explicitly listing accuracy, coverage, and runtime would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each major comment below with point-by-point responses and indicate planned revisions to improve clarity and scope discussion without altering the core experimental design.
read point-by-point responses
-
Referee: [Experiments] The experimental evaluation (described in the abstract and Experiments section) is confined to two large-scale aerial/nadir datasets with similar viewpoint distributions and texture properties. This choice does not test the observed accuracy-coverage-runtime-residual pattern in close-range, terrestrial, oblique, or indoor regimes where feature-matching statistics, scale ambiguity, and occlusion differ markedly, so the general statements contrasting traditional versus learning-based approaches rest on an unrepresentative sample.
Authors: We agree that the evaluation is restricted to aerial photogrammetry settings, consistent with the paper title and focus on large-scale 3D reconstruction from nadir imagery. The chosen datasets (MARS-LVIG with LiDAR GT and the Pix4D scene) were selected specifically because they supply independent, high-quality ground truth for quantitative metrics in realistic aerial conditions. We do not claim the results generalize to all regimes. In revision we will add an explicit Limitations subsection in the Experiments and Conclusion sections that states the aerial scope, notes the differing challenges in close-range/terrestrial/indoor settings, and recommends future work on those regimes. This will prevent any over-generalization while preserving the practical guidance for photogrammetric aerial applications. revision: partial
-
Referee: [Results] The abstract states that DUSt3R and VGGT achieve 'competitive accuracy' and 'reasonable coverage' yet 'relatively large residuals in 3D reconstruction,' but the provided description contains no quantitative tables, error histograms, or per-scene metrics that would allow verification of these claims or assessment of implementation fairness (e.g., whether COLMAP and learning-based pipelines used identical camera poses or depth priors).
Authors: The full manuscript (Section 4) contains quantitative tables reporting per-method accuracy (RMSE/MAE to ground truth), coverage percentages, and runtimes on both datasets, together with per-scene breakdowns and qualitative residual visualizations. The abstract summarizes these findings concisely. All pipelines were run on identical input images; geometry-guided methods received COLMAP poses and depth priors where required by their design, while end-to-end methods (DUSt3R, VGGT, etc.) operated directly on images without such priors. We will revise the Experiments section to add a dedicated paragraph explicitly tabulating the input configuration and priors used for each method, and we will include error histograms if they are not already present, to make verification straightforward. revision: partial
Circularity Check
Empirical comparison of published MVS methods shows no circularity
full rationale
The paper conducts a direct empirical benchmark of existing COLMAP and learning-based MVS pipelines on two fixed aerial datasets with external LiDAR and Pix4Dmapper ground truth. No equations, parameter fits, uniqueness theorems, or ansatzes are introduced; performance metrics (accuracy, coverage, runtime) are measured outputs rather than derived quantities. Self-citations, if present, are incidental and do not support any load-bearing claim. The derivation chain is therefore empty and the results are self-contained against the chosen benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The published implementations of COLMAP and the listed learning-based MVS methods behave as described in their original papers.
Reference graph
Works this paper leans on
-
[1]
Sun, J., Xie, Y ., Chen, L., Zhou, X., Bao, H., 2021
Pixelwise view selection for unstructured multi-view ste- reo.European conference on computer vision, Springer, 501– 518. Sun, J., Xie, Y ., Chen, L., Zhou, X., Bao, H., 2021. Neur- alrecon: Real-time coherent 3d reconstruction from monocular video.Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 15598–15607. Vallet, J., ...
work page 2021
-
[2]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 14194–14203
PatchmatchNet: Learned multi-view patchmatch stereo. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 14194–14203. Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., No- votny, D., 2025. VGGT: Visual geometry grounded transformer. Proceedings of the Computer Vision and Pattern Recognition Conference, 5294–5306. W...
work page 2025
-
[3]
Wen, B., Trepte, M., Aribido, J., Kautz, J., Gallo, O., Birch- field, S., 2025
DUSt3r: Geometric 3d vision made easy.Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 20697–20709. Wen, B., Trepte, M., Aribido, J., Kautz, J., Gallo, O., Birch- field, S., 2025. Foundationstereo: Zero-shot stereo matching. Proceedings of the Computer Vision and Pattern Recognition Conference, 5249–5260. Wu, X., Landgraf...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.