FastSHADE: Fast Self-augmented Hierarchical Asymmetric Denoising for Efficient inference on mobile devices
Pith reviewed 2026-05-10 15:58 UTC · model grok-4.3
The pith
FastSHADE introduces a lightweight U-Net with frequency-decoupled blocks and self-augmentation that delivers real-time denoising on mobile GPUs while reaching 37.94 dB PSNR.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
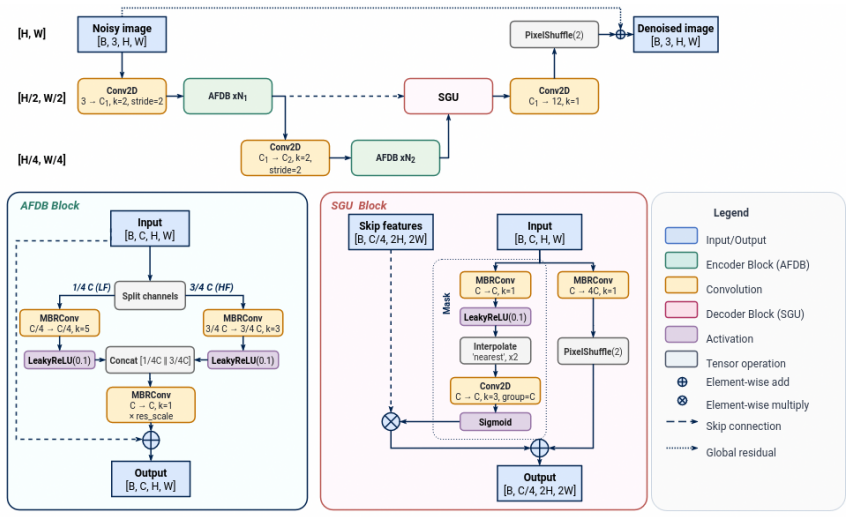
FastSHADE is a scalable U-Net-style network built around an Asymmetric Frequency Denoising Block that decouples spatial structure extraction from high-frequency noise suppression, a Spatially Gated Upsampler that optimizes skip-connection fusion, and a Noise Shifting Self-Augmentation procedure that improves generalization without domain shift. On the MAI2021 benchmark the base FastSHADE-M model sustains real-time inference below 50 ms on Adreno 840 GPU hardware while the scaled FastSHADE-XL variant reaches 37.94 dB PSNR, establishing an efficient speed-fidelity operating curve for mobile denoising.
What carries the argument
The Asymmetric Frequency Denoising Block (AFDB) that decouples spatial structure extraction from high-frequency noise suppression, together with the Spatially Gated Upsampler (SGU) for skip-connection fusion and Noise Shifting Self-Augmentation for data diversity.
If this is right
- The base model sustains real-time latency under 50 ms on Adreno 840 GPU while preserving structural integrity.
- The scaled XL variant reaches 37.94 dB PSNR and sets a new state-of-the-art quality mark on MAI2021.
- The architecture family provides a controllable speed-fidelity trade-off across model sizes.
- The Noise Shifting Self-Augmentation improves generalization without inducing domain shifts.
- The design maintains efficiency under the power and latency constraints typical of edge devices.
Where Pith is reading between the lines
- The same decoupling principle could be tested on related low-level tasks such as deblurring or super-resolution on the same hardware class.
- If the blocks prove hardware-agnostic, the approach might reduce reliance on cloud processing for mobile camera pipelines.
- The self-augmentation method might transfer to other data-scarce restoration problems where synthetic noise is easy to generate but domain shift is costly.
- Direct measurement of power draw on additional mobile GPUs would reveal whether the reported latency advantage holds across vendors.
Load-bearing premise
The new blocks and augmentation strategy deliver the stated efficiency and quality gains on actual mobile hardware without hidden costs in training stability or device tuning.
What would settle it
A side-by-side run of the released FastSHADE-M weights on an Adreno 840 GPU that records either latency above 50 ms or PSNR below the claimed value on the MAI2021 validation set.
Figures


read the original abstract
Real-time image denoising is essential for modern mobile photography but remains challenging due to the strict latency and power constraints of edge devices. This paper presents FastSHADE (Fast Self-augmented Hierarchical Asymmetric Denoising), a lightweight U-Net-style network tailored for real-time, high-fidelity restoration on mobile GPUs. Our method features a multi-stage architecture incorporating a novel Asymmetric Frequency Denoising Block (AFDB) that decouples spatial structure extraction from high-frequency noise suppression to maximize efficiency, and a Spatially Gated Upsampler (SGU) that optimizes high-resolution skip connection fusion. To address generalization, we introduce an efficient Noise Shifting Self-Augmentation strategy that enhances data diversity without inducing domain shifts. Evaluations on the MAI2021 benchmark demonstrate that our scalable model family establishes a highly efficient speed-fidelity trade-off. Our base FastSHADE-M variant maintains real-time latency (<50 ms on an Adreno 840 GPU) while preserving structural integrity, and our scaled-up FastSHADE-XL establishes a new state-of-the-art for overall image quality, achieving 37.94 dB PSNR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FastSHADE, a lightweight U-Net-style architecture for real-time image denoising on mobile GPUs. It introduces an Asymmetric Frequency Denoising Block (AFDB) to decouple spatial structure extraction from high-frequency noise suppression, a Spatially Gated Upsampler (SGU) for optimized skip-connection fusion, and Noise Shifting Self-Augmentation to improve generalization without domain shift. On the MAI2021 benchmark the base FastSHADE-M variant is reported to run in under 50 ms on an Adreno 840 GPU while preserving structural integrity, and the scaled FastSHADE-XL variant is claimed to reach a new state-of-the-art PSNR of 37.94 dB.
Significance. If the performance numbers and efficiency claims can be independently verified, the work would be significant for mobile computer-vision pipelines where denoising must operate under strict latency and power budgets. The architectural choices (frequency-domain decoupling and gated upsampling) target a practical speed-fidelity trade-off that is directly relevant to smartphone photography. However, the absence of ablations, baseline tables, and measurement protocols currently prevents any assessment of whether the reported gains are attributable to the proposed components or are reproducible across devices.
major comments (2)
- [Abstract] Abstract: the central efficiency claim that FastSHADE-M runs in <50 ms on an Adreno 840 GPU supplies no input resolution, batch size, or timing scope (forward pass only versus including data transfer and pre-/post-processing). Because AFDB performs frequency-domain operations whose cost is resolution-dependent, the latency figure cannot be reproduced or compared with prior mobile denoisers.
- [Abstract] Abstract: the reported benchmark numbers (37.94 dB PSNR for FastSHADE-XL, structural-integrity preservation for FastSHADE-M) are given without ablation studies, baseline comparisons, error bars, or statistical tests. These omissions make it impossible to determine whether the novel AFDB, SGU, and self-augmentation blocks are responsible for the claimed gains.
minor comments (1)
- The abstract would be clearer if it stated the input resolution used for all timing and quality measurements and included a brief parameter/FLOP comparison table against representative mobile denoisers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and will incorporate the necessary clarifications and additions in the revised version to improve reproducibility and clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central efficiency claim that FastSHADE-M runs in <50 ms on an Adreno 840 GPU supplies no input resolution, batch size, or timing scope (forward pass only versus including data transfer and pre-/post-processing). Because AFDB performs frequency-domain operations whose cost is resolution-dependent, the latency figure cannot be reproduced or compared with prior mobile denoisers.
Authors: We agree that additional details are required for reproducibility. In the revised manuscript, we will explicitly state the input resolution, batch size of 1, and clarify that the reported latency refers to the forward pass only (excluding data transfer and pre-/post-processing) on the Adreno 840 GPU. We will also add a dedicated subsection in the experimental section describing the full measurement protocol, hardware configuration, and timing methodology. This will directly address the resolution-dependency concern and enable fair comparisons with prior mobile denoisers. revision: yes
-
Referee: [Abstract] Abstract: the reported benchmark numbers (37.94 dB PSNR for FastSHADE-XL, structural-integrity preservation for FastSHADE-M) are given without ablation studies, baseline comparisons, error bars, or statistical tests. These omissions make it impossible to determine whether the novel AFDB, SGU, and self-augmentation blocks are responsible for the claimed gains.
Authors: We acknowledge that the abstract, being concise, does not include these supporting elements, and the current manuscript lacks explicit ablation studies, baseline tables, error bars, and statistical tests. In the revised version, we will add comprehensive ablation experiments isolating the contributions of AFDB, SGU, and Noise Shifting Self-Augmentation, along with comparisons to relevant baselines on the MAI2021 benchmark. Error bars and statistical significance will be reported where applicable. The abstract will be updated to reference these new analyses, demonstrating that the gains are attributable to the proposed components. revision: yes
Circularity Check
No circularity: empirical architecture claims rest on benchmarks, not derivations
full rationale
The paper introduces a U-Net variant with novel blocks (AFDB, SGU) and a self-augmentation strategy, then reports PSNR and latency on MAI2021. No equations, derivations, or predictions appear in the provided text. All performance numbers are direct empirical measurements rather than quantities obtained by fitting parameters to a subset and renaming the fit as a prediction. No self-citation chains or uniqueness theorems are invoked to justify core choices. The latency claim is under-specified for reproduction but does not reduce to a definitional or fitted tautology.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Asymmetric Frequency Denoising Block (AFDB)
no independent evidence
-
Spatially Gated Upsampler (SGU)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Abdelrahman Abdelhamed, Stephen Lin, and Michael S. Brown. A high-quality denoising dataset for smartphone cameras. In2018 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 1692–1700, 2018. 1, 5
work page 2018
-
[2]
Simple baselines for image restoration
Liangyu Chen, Xiaojie Chu, Xiangyu Zhang, and Jian Sun. Simple baselines for image restoration. InComputer Vision – ECCV 2022, pages 17–33, Cham, 2022. Springer Nature Switzerland. 2
work page 2022
-
[3]
Kostadin Dabov, Alessandro Foi, Vladimir Katkovnik, and Karen Egiazarian. Image denoising by sparse 3-d transform- domain collaborative filtering.IEEE Transactions on Image Processing, 16(8):2080–2095, 2007. 1
work page 2080
-
[4]
Repvgg: Making vgg-style convnets great again
Xiaohan Ding, Xiangyu Zhang, Ningning Ma, Jungong Han, Guiguang Ding, and Jian Sun. Repvgg: Making vgg-style convnets great again. In2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13728–13737, 2021. 2
work page 2021
-
[5]
Litert torch: Support for converting pytorch models to litert, 2026
Google AI Edge. Litert torch: Support for converting pytorch models to litert, 2026. 4
work page 2026
-
[6]
Real-world mobile image denoising dataset with efficient baselines
Roman Flepp, Andrey Ignatov, Radu Timofte, and Luc Van Gool. Real-world mobile image denoising dataset with efficient baselines. In2024 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 22368– 22377, 2024. 1, 2, 3, 5, 6
work page 2024
-
[7]
Amirhosein Ghasemabadi, Muhammad Kamran Janjua, Mo- hammad Salameh, Chunhua Zhou, and Di Niu Fengyu Sun. Cascadedgaze: Efficiency in global context extraction for image restoration.Transactions on Machine Learning Re- search, 2024. 2
work page 2024
-
[8]
Squeeze-and-excitation net- works
Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation net- works. In2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7132–7141, 2018. 7
work page 2018
-
[9]
Ai benchmark: Running deep neural networks on android smartphones
Andrey Ignatov, Radu Timofte, William Chou, Ke Wang, Max Wu, Tim Hartley, and Luc Van Gool. Ai benchmark: Running deep neural networks on android smartphones. In Computer Vision – ECCV 2018 Workshops, pages 288–314, Cham, 2019. Springer International Publishing. 5
work page 2018
-
[10]
Fast camera image denoising on mobile gpus with deep learning, mobile ai 2021 challenge: Report
Andrey Ignatov, Kim Byeoung-su, Radu Timofte, and An- geline Pouget. Fast camera image denoising on mobile gpus with deep learning, mobile ai 2021 challenge: Report. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pages 2515–2524, 2021. 2, 5
work page 2021
-
[11]
Xinyang Li, Xiaowan Hu, Xingye Chen, Jiaqi Fan, Zhifeng Zhao, Jiamin Wu, Haoqian Wang, and Qionghai Dai. Spa- tial redundancy transformer for self-supervised fluorescence image denoising.Nature Computational Science, 2023. 4
work page 2023
-
[12]
Yawei Li, Yulun Zhang, Radu Timofte, Luc Van Gool, Zhijun Tu, Kunpeng Du, Hailing Wang, Hanting Chen, Wei Li, Xiaofei Wang, Jie Hu, Yunhe Wang, Xiangyu Kong, Jinlong Wu, Dafeng Zhang, Jianxing Zhang, Shuai Liu, Furui Bai, Chaoyu Feng, Hao Wang, Yuqian Zhang, Guangqi Shao, Xiaotao Wang, Lei Lei, Rongjian Xu, Zhilu Zhang, Yunjin Chen, Dongwei Ren, Wangmeng ...
work page 2023
-
[13]
Swinir: Image restoration using swin transformer
Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration using swin transformer. In2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), pages 1833–1844, 2021. 2
work page 2021
-
[14]
Decoupled weight decay regularization, 2019
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019. 4
work page 2019
-
[15]
Ymir M ¨akinen, Lucio Azzari, and Alessandro Foi. Collabo- rative filtering of correlated noise: Exact transform-domain variance for improved shrinkage and patch matching.IEEE Transactions on Image Processing, 29:8339–8354, 2020. 1
work page 2020
-
[16]
Recorrupted-to-recorrupted: Unsupervised deep learning for image denoising
Tongyao Pang, Huan Zheng, Yuhui Quan, and Hui Ji. Recorrupted-to-recorrupted: Unsupervised deep learning for image denoising. In2021 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 2043– 2052, 2021. 4
work page 2043
-
[17]
U- net: Convolutional networks for biomedical image segmen- tation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U- net: Convolutional networks for biomedical image segmen- tation. InMedical Image Computing and Computer-Assisted Intervention – MICCAI 2015, pages 234–241, Cham, 2015. Springer International Publishing. 2
work page 2015
-
[18]
Cbam: Convolutional block attention module
Sanghyun Woo, Jongchan Park, Joon-Young Lee, and In So Kweon. Cbam: Convolutional block attention module. In Computer Vision – ECCV 2018, pages 3–19, Cham, 2018. Springer International Publishing. 7
work page 2018
-
[19]
Hailong Yan, Ao Li, Xiangtao Zhang, Zhe Liu, Zenglin Shi, Ce Zhu, and Le Zhang. Mobileie: An extremely lightweight and effective convnet for real-time image enhancement on mobile devices. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision (ICCV), pages 21949–21960, 2025. 2, 4
work page 2025
-
[20]
Restormer: Efficient transformer for high-resolution image restoration
Syed Waqas Zamir, Aditya Arora, Salman Khan, Mu- nawar Hayat, Fahad Shahbaz Khan, and Ming-Hsuan Yang. Restormer: Efficient transformer for high-resolution image restoration. InCVPR, 2022. 2
work page 2022
-
[21]
Kai Zhang, Wangmeng Zuo, Yunjin Chen, Deyu Meng, and Lei Zhang. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising.IEEE Transactions on Image Processing, 26(7):3142–3155, 2017. 1
work page 2017
-
[22]
Ffdnet: Toward a fast and flexible solution for cnn-based image denoising
Kai Zhang, Wangmeng Zuo, and Lei Zhang. Ffdnet: Toward a fast and flexible solution for cnn-based image denoising. IEEE Transactions on Image Processing, 27(9):4608–4622,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.