From Majorization to Scaling: Advancing Convex Relaxations of Maximum Entropy Sampling Problem
Pith reviewed 2026-05-10 15:15 UTC · model grok-4.3
The pith
Double-scaling strictly dominates prior scaling bounds and establishes formal dominance between linx and Gamma factorization relaxations for the maximum entropy sampling problem.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish the main theoretical properties of double-scaling and prove that it strictly dominates previously known scaling bounds. Using a majorization-based alternative characterization of the Gamma factorization relaxation, they derive formal dominance relations between linx and Gamma factorization bounds as well as between their scaling-strengthened variants.
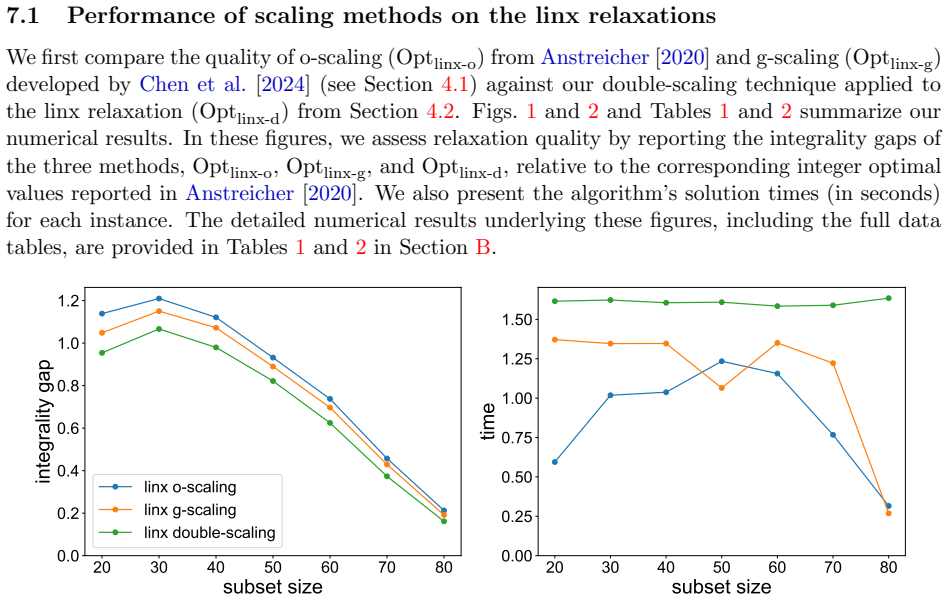
What carries the argument
The double-scaling technique, which applies scaling operations in two stages to tighten bounds, together with the majorization-based symmetrization that converts the non-symmetric log-determinant objective into its convex envelope.
Load-bearing premise
The premise that majorization resolves the spectral objective's lack of permutation symmetry by symmetrizing the function and yielding its convex envelope.
What would settle it
An explicit covariance matrix and subset size where the double-scaled linx bound is no stronger than a single-scaled version, or where the unscaled Gamma factorization bound exceeds the linx bound.
Figures



read the original abstract
In this paper, we study the maximum entropy sampling problem (MESP) and its variants. MESP seeks to identify a small subset of variables that maximizes the determinant of a covariance submatrix, and is a fundamental model in optimal experimental design and information acquisition. Although MESP is combinatorial and NP-hard, continuous relaxations, most notably linx and $\Gamma$ factorization, provide tractable approximations, yet their derivation, relative strength, and potential for systematic improvement remain poorly understood. We address this gap by introducing two main ideas: a unified majorization-based framework for deriving and analyzing relaxations, and a novel scaling-based bound-enhancement technique, which we call double-scaling. Our approach is motivated by the observation that the difficulty of MESP arises from two distinct sources: the combinatorial selection structure and the lack of permutation symmetry in the spectral objective. Majorization naturally resolves the latter by symmetrizing the spectral function and yielding its convex envelope. In the log-determinant setting, we establish the main theoretical properties of double-scaling and prove that it strictly dominates previously known scaling bounds. Using our majorization-based alternative characterization of $\Gamma$ factorization relaxation, we also derive, for the first time, formal dominance relations between linx- and $\Gamma$ factorization-bounds, as well as between their scaling-strengthened variants. Our numerical results show that our double-scaled linx relaxation consistently and substantially outperforms existing scaling methods and compares quite favorably with other state-of-the-art relaxations in terms of both bound quality and computational efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a majorization-based unified framework for convex relaxations of the maximum entropy sampling problem (MESP) and its variants. It introduces a double-scaling technique for bound enhancement, establishes the theoretical properties of double-scaling in the log-determinant setting and proves that it strictly dominates prior scaling bounds, derives formal dominance relations between the linx and Γ-factorization relaxations (and their scaled variants) via an alternative majorization characterization of the Γ relaxation, and reports numerical results showing improved bound quality and efficiency over existing methods.
Significance. If the stated dominance proofs and numerical comparisons hold, the work provides a systematic majorization-based approach to symmetrizing spectral objectives and tightening relaxations for MESP, which is relevant to optimal experimental design. The explicit dominance results between linx and Γ families, together with the double-scaling improvement, represent a clear advance over ad-hoc scaling techniques; the combination of theoretical unification and computational evidence strengthens the contribution.
major comments (1)
- [Introduction and Section 3 (theoretical properties of double-scaling)] The abstract and introduction claim that double-scaling 'strictly dominates previously known scaling bounds' and that dominance relations between linx- and Γ-factorization bounds are derived 'for the first time.' These are load-bearing for the central contribution, yet the manuscript does not appear to include a counterexample check or boundary case (e.g., when the covariance matrix has repeated eigenvalues) that would confirm the strict inequality cannot degenerate.
minor comments (3)
- [Section 2 (preliminaries)] Notation for the majorization operator and the definition of the double-scaling parameters should be introduced earlier and used consistently; readers unfamiliar with majorization theory would benefit from a short self-contained recap before the main theorems.
- [Numerical experiments] The numerical section reports that double-scaled linx 'consistently and substantially outperforms' existing methods, but does not tabulate the specific test instances, dimensions, or number of random covariance matrices used; adding this information would improve reproducibility.
- [Numerical experiments] A few sentences comparing the computational cost of the new double-scaling procedure versus single scaling (e.g., additional SDP variables or iterations) would clarify the efficiency claim.
Simulated Author's Rebuttal
We thank the referee for the careful review and positive recommendation for minor revision. We address the major comment point by point below and will incorporate clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [Introduction and Section 3 (theoretical properties of double-scaling)] The abstract and introduction claim that double-scaling 'strictly dominates previously known scaling bounds' and that dominance relations between linx- and Γ-factorization bounds are derived 'for the first time.' These are load-bearing for the central contribution, yet the manuscript does not appear to include a counterexample check or boundary case (e.g., when the covariance matrix has repeated eigenvalues) that would confirm the strict inequality cannot degenerate.
Authors: We appreciate the referee drawing attention to the need for explicit verification of strictness in boundary cases. The proof of strict dominance for double-scaling (Theorem 3.2) is based on majorization theory and the strict convexity of the log-determinant function; it holds for general positive semidefinite matrices, including those with repeated eigenvalues, because the double-scaling optimization yields a strictly tighter bound except in explicitly characterized degenerate cases (where the two scaling vectors coincide). The alternative majorization characterization of the Γ relaxation similarly yields dominance relations that are non-degenerate in general. However, to address the concern directly, we will add a clarifying remark in Section 3 analyzing the repeated-eigenvalue case and include a small illustrative example (with a covariance matrix having eigenvalue multiplicity) demonstrating that the strict inequality is preserved. These additions will be made in the revision. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper's core contributions rest on applying standard majorization theory to symmetrize the spectral objective and obtain its convex envelope, followed by explicit constructions of double-scaling and formal dominance proofs between linx and Γ-factorization families. These steps are presented as independent mathematical derivations rather than reductions to fitted parameters, self-referential definitions, or load-bearing self-citations. The abstract and described framework cite majorization as an external tool that resolves the lack of permutation symmetry, with new results (double-scaling properties and dominance relations) established via direct analysis. No equation or claim reduces by construction to its own inputs, and the central claims retain independent content beyond any prior work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Majorization theory can be applied to derive the convex envelope of the spectral function in the log-determinant setting for MESP relaxations
Reference graph
Works this paper leans on
-
[1]
Springer Berlin Heidelberg. K. M. Anstreicher, M. Fampa, J. Lee, and J. Williams. Using continuous nonlinear relaxations to solve constrained maximum-entropy sampling problems.Mathematical Programming, 85(2): 221–240, 1999. S. Burer and J. Lee. Solving maximum-entropy sampling problems using factored masks.Mathe- matical Programming, 109(2-3):263–281, 200...
work page 1999
-
[2]
Springer Nature Switzerland. Y. Li and W. Xie. Best principal submatrix selection for the maximum entropy sampling problem: Scalable algorithms and performance guarantees.Operations Research, 72(2):493–513, 2024. M. Lin and H. Wolkowicz. An eigenvalue majorization inequality for positive semidefinite block matrices.Linear and Multilinear Algebra, 60(11-12...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Then, Optlinx-o =f linx-o(x∗, ρ∗ 0)
associated with this problem. Then, Optlinx-o =f linx-o(x∗, ρ∗ 0). As Opt Γ = minx∈X fΓ-g(x,0) and Opt Γc = minx∈X fΓc-g(x,0), we have 1 2 [OptΓ + OptΓc]≤ 1 2 [fΓ-g(x∗,0) +f Γc-g(x∗,0)] ≤f linx-d(x∗, κ1,0) =f linx-o(x∗, κ), where the second inequality follows from Proposition 11 for a properly chosenκ∈R, and the equality holds asf linx-o(x, κ) =f linx-d(x...
-
[4]
Thus, 1 2 [OptΓ + OptΓc]≤f linx-o(x∗, κ)≤f linx-o(x∗, ρ∗
is a saddle point associated with Opt linx-o, we have flinx-o(x∗, ρ0)≤Opt linx-o =f linx-o(x∗, ρ∗ 0)≤f linx-o(x, ρ∗ 0),∀x∈ X,and∀ρ 0 ∈R. Thus, 1 2 [OptΓ + OptΓc]≤f linx-o(x∗, κ)≤f linx-o(x∗, ρ∗
-
[5]
= Optlinx-o . (ii) Recall from (31), (32)-(33), and (26)-(27) that OptΓ-g = min x∈X max ρ∈Rd {fΓ-g(x,ρ)}, OptΓc-g = min x∈X max ω∈Rd {fΓc-g(x,ω)}, Optlinx-d = min x∈X max ρ,ω∈Rd {flinx-d(x,ρ,ω)}, and all these saddle point functions are convex-concave and continuous, all domains are closed and convex, andXis bounded. Then, the saddle points associated wit...
work page 1983
-
[6]
for these problem instances. The ‘conv.’ columns show a convergence measurement for Mirror Descent algorithm for convex minimization problems and for the saddle point problems the PF-NE-EG algorithm, which is guaranteed to converge at a rate ofO(1/ √ T) (see Shen and Kılın¸ c- Karzan [2026]). The ‘time’ column reports the running time in seconds. The ‘# i...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.