Recognition: unknown
Orthogonal machine learning for conditional odds and risk ratios
Pith reviewed 2026-05-10 16:39 UTC · model grok-4.3
The pith
Orthogonal risk functions for conditional odds and risk ratios produce pseudo-outcomes with second-order remainder properties like those for average treatment effects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We derive orthogonal risk functions for the OR and RR and show that the associated pseudo-outcomes satisfy second-order conditional-mean remainder properties analogous to the ATE case. We also evaluate estimators for the conditional ATE, OR, and RR in a comprehensive nonparametric Monte Carlo simulation study to compare them with common alternatives under hundreds of different data-generating distributions. Our numerical studies provide empirical guidance for choosing an estimator, showing that nonparametric estimators significantly reduce bias and mean squared error in more complex settings.
What carries the argument
Orthogonal risk functions for the odds ratio and risk ratio that generate pseudo-outcomes satisfying second-order conditional-mean remainder properties.
If this is right
- The estimators achieve lower bias and mean squared error than parametric models when data patterns are complex.
- Treatment targeting improves by uncovering heterogeneity obscured by standard regression.
- The approach extends the benefits of DR-learner and R-learner methods from ATE to OR and RR parameters.
- Real-world applications such as NHANES data analysis yield improved decision rules for interventions.
Where Pith is reading between the lines
- Similar orthogonalization may apply to other nonlinear causal effect measures beyond OR and RR.
- Practitioners gain most when they pair these methods with flexible, high-quality nuisance estimators.
- The methods support more reliable subgroup-specific treatment recommendations in precision health settings.
- The simulation design provides a reusable template for evaluating estimators of other conditional causal parameters.
Load-bearing premise
Nuisance functions such as propensity scores and outcome regressions can be estimated at rates fast enough that their product terms dominate the remainder and vanish asymptotically.
What would settle it
A Monte Carlo experiment in which the proposed OR and RR estimators fail to show lower mean squared error than non-orthogonal alternatives despite accurate nuisance function fits in complex data-generating processes.
Figures









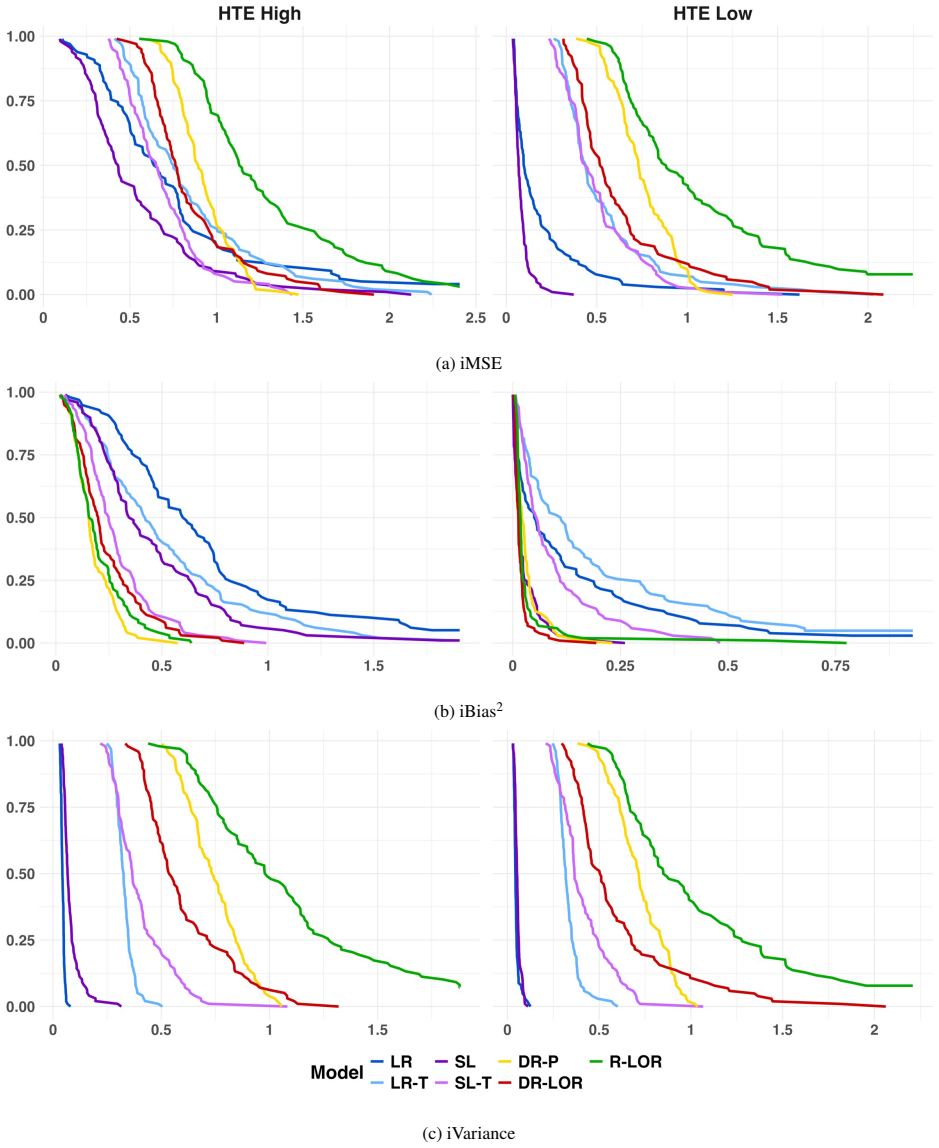










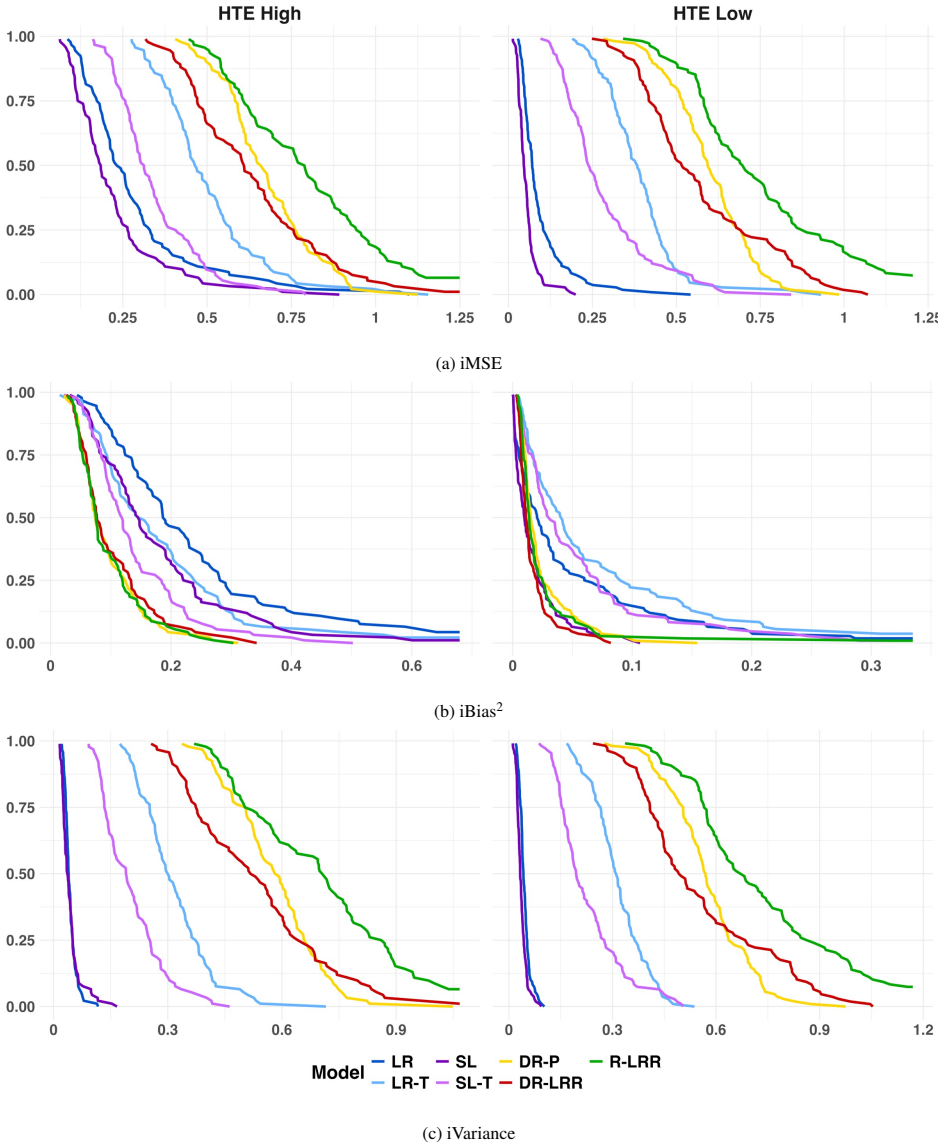





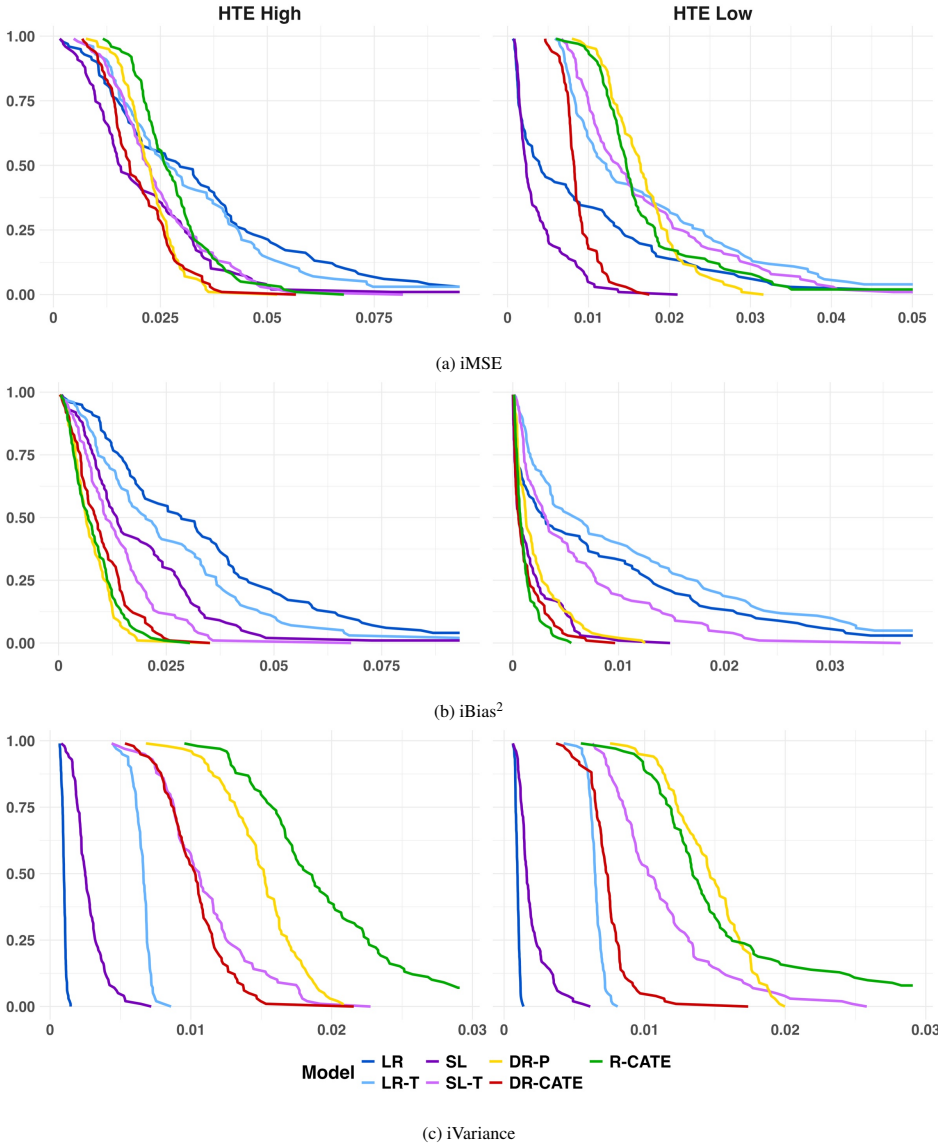










read the original abstract
Conditional effects are commonly used measures for understanding how treatment effects vary across different groups, and are often used to target treatments/interventions to groups who benefit most. In this work we review existing methods and propose novel ones, focusing on the odds ratio (OR) and the risk ratio (RR). While estimation of the conditional average treatment effect (ATE) has been widely studied, estimators for the OR and RR lag behind, and cutting edge estimators such as those based on doubly robust transformations or orthogonal risk functions have not been generalized to these parameters. We propose such a generalization here, focusing on the DR-learner and the R-learner. We derive orthogonal risk functions for the OR and RR and show that the associated pseudo-outcomes satisfy second-order conditional-mean remainder properties analogous to the ATE case. We also evaluate estimators for the conditional ATE, OR, and RR in a comprehensive nonparametric Monte Carlo simulation study to compare them with common alternatives under hundreds of different data-generating distributions. Our numerical studies provide empirical guidance for choosing an estimator. For instance, they show that while parametric models are useful in very simple settings, the proposed nonparametric estimators significantly reduce bias and mean squared error in the more complex settings expected in the real world. We illustrate the methods in the analysis of physical activity and sleep trouble in U.S. adults using data from the National Health and Nutrition Examination Survey (NHANES). The results demonstrate that our estimators uncover substantial treatment effect heterogeneity that is obscured by traditional regression approaches and lead to improved treatment decision rules, highlighting the importance of data-adaptive methods for advancing precision health research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper derives orthogonal risk functions and associated pseudo-outcomes for the conditional odds ratio (OR) and risk ratio (RR) that exhibit second-order conditional-mean remainder properties analogous to those for the conditional average treatment effect. It proposes generalizations of the DR-learner and R-learner to these functionals, evaluates the resulting estimators against common alternatives in a large-scale nonparametric Monte Carlo study across hundreds of data-generating distributions, and applies the methods to NHANES data on physical activity and sleep trouble to demonstrate improved detection of treatment effect heterogeneity.
Significance. If the second-order remainder properties hold under standard nonparametric nuisance estimators, the work extends doubly robust orthogonal learning to two important conditional effect measures for binary outcomes, enabling more robust estimation of heterogeneous treatment effects in settings where ATE alone is insufficient. The comprehensive simulation design across diverse distributions is a clear strength and supplies practical guidance on estimator choice; the real-data illustration shows the methods can uncover heterogeneity missed by parametric regression.
major comments (2)
- [§3.3, Eq. (12)] §3.3, Eq. (12) and surrounding derivation: the claimed second-order remainder for the RR pseudo-outcome is stated as the product of propensity and outcome-regression errors, but the text does not derive or cite the precise rate conditions (e.g., each nuisance converging faster than n^{-1/4}) under which this product is o_p(n^{-1/2}) when the conditional probabilities approach the boundary; without these conditions the advertised sqrt(n) consistency is not guaranteed for standard estimators such as random forests or kernels.
- [§5.1] §5.1, simulation design: none of the 200+ data-generating processes include regimes in which the propensity score approaches 0 or 1 while the outcome regression remains bounded away from 0/1; this omission leaves untested the finite-sample behavior of the second-order property precisely where the product remainder is most likely to degrade.
minor comments (2)
- [§3 and §4] Notation for the OR and RR pseudo-outcomes is introduced in §3 but reused with slight variations in §4; a single consolidated definition table would improve readability.
- [§6] The NHANES application in §6 reports point estimates and confidence intervals but does not include a sensitivity analysis to the choice of nuisance estimators or bandwidths.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments, which have identified important points for clarification and strengthening. We address each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [§3.3, Eq. (12)] §3.3, Eq. (12) and surrounding derivation: the claimed second-order remainder for the RR pseudo-outcome is stated as the product of propensity and outcome-regression errors, but the text does not derive or cite the precise rate conditions (e.g., each nuisance converging faster than n^{-1/4}) under which this product is o_p(n^{-1/2}) when the conditional probabilities approach the boundary; without these conditions the advertised sqrt(n) consistency is not guaranteed for standard estimators such as random forests or kernels.
Authors: We appreciate the referee highlighting the need for explicit rate conditions. The derivation in §3.3 shows that the remainder for the RR pseudo-outcome is the product of the propensity-score and outcome-regression errors. Under the maintained assumption that the conditional probabilities are bounded away from 0 and 1, standard nonparametric rates (each nuisance estimator o_p(n^{-1/4})) make the product o_p(n^{-1/2}), as is standard in the orthogonal-learning literature. Near boundaries, additional regularity or trimming is indeed required, analogous to conditions in doubly robust estimation for binary outcomes. We will revise the text to state these conditions explicitly and cite the relevant rate results for product remainders. revision: yes
-
Referee: [§5.1] §5.1, simulation design: none of the 200+ data-generating processes include regimes in which the propensity score approaches 0 or 1 while the outcome regression remains bounded away from 0/1; this omission leaves untested the finite-sample behavior of the second-order property precisely where the product remainder is most likely to degrade.
Authors: The referee is correct that our simulation design did not include propensity scores approaching the boundaries. The 200+ DGPs were chosen to span a wide range of complexities in the conditional effects and nuisance functions, but we agree that boundary regimes are a natural stress test for the product remainder. In the revision we will add a targeted set of simulations with propensity scores near 0 and 1 (while keeping outcome regressions bounded away from 0/1) to evaluate finite-sample behavior in these cases. revision: yes
Circularity Check
No significant circularity in derivation of OR/RR orthogonal risks
full rationale
The paper derives orthogonal risk functions and associated pseudo-outcomes for conditional OR and RR as a direct mathematical generalization of the ATE framework, establishing second-order remainder properties through algebraic manipulation of the relevant expressions. This process does not reduce any claimed result to its inputs by construction, nor does it rely on fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations. The derivations stand as independent content, with the simulation study and NHANES application providing separate empirical support rather than circular reinforcement.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard causal assumptions including consistency, no unmeasured confounding, and positivity.
Reference graph
Works this paper leans on
-
[1]
and Pearl, J
Bareinboim, E. and Pearl, J. (2012). Controlling selection bias in causal inference. In Lawrence, N. D. and Girolami, M., editors, Proceedings of the Fifteenth International Conference on Artificial Intelligence and Statistics , volume 22 of Proceedings of Machine Learning Research , pages 100--108, La Palma, Canary Islands. PMLR
2012
-
[2]
J., Klaassen, C
Bickel, P. J., Klaassen, C. A. J., Ritov, Y., and Wellner, J. A. (1993). Efficient and Adaptive Estimation for Semiparametric Models . Johns Hopkins University Press
1993
-
[3]
Chernozhukov, V., Chetverikov, D., Demirer, M., Duflo, E., Hansen, C., Newey, W., and Robins, J. (2018). Double/debiased machine learning for treatment and structural parameters. The Econometrics Journal , 21(1):C1--C68
2018
-
[4]
A., George, E
Chipman, H. A., George, E. I., and McCulloch, R. E. (2010). Bart: Bayesian additive regression trees. The Annals of Applied Statistics , 4(1):266--298
2010
-
[5]
D \' az, I., Savenkov, O., and Ballman, K. (2018). Targeted learning ensembles for optimal individualized treatment rules with time-to-event outcomes. Biometrika , 105(3):723--738
2018
-
[6]
L., and Schenck, E
D \' az, I., Williams, N., Hoffman, K. L., and Schenck, E. J. (2023). Nonparametric causal effects based on longitudinal modified treatment policies. Journal of the American Statistical Association , 118(542):846--857
2023
-
[7]
portable
Doi, S. A., Furuya-Kanamori, L., Xu, C., Chivese, T., Lin, L., Musa, O. A., Hindy, G., Thalib, L., and Harrell Jr, F. E. (2022). The odds ratio is “portable” across baseline risk but not the relative risk: time to do away with the log link in binomial regression. Journal of Clinical Epidemiology , 142:288--293
2022
-
[8]
Dunson, D. B. and Xing, C. (2009). Nonparametric bayes modeling of multivariate categorical data. Journal of the American Statistical Association , 104(487):1042--1051
2009
-
[9]
Foster, D. J. and Syrgkanis, V. (2023). Orthogonal statistical learning. The Annals of Statistics , 51(3):879--908
2023
-
[10]
Friedman, J. H. (1991). Multivariate adaptive regression splines. The Annals of Statistics , 19(1):1--67
1991
-
[11]
Regression Modeling Strategies: With Applications to Linear Models, Logistic and Ordinal Regression, and Survival Analysis
Harrell (2015). Regression Modeling Strategies: With Applications to Linear Models, Logistic and Ordinal Regression, and Survival Analysis . Springer Series in Statistics. Springer, Cham, 2 edition
2015
-
[12]
Hines, O., Dukes, O., Diaz-Ordaz, K., and Vansteelandt, S. (2022). Demystifying statistical learning based on efficient influence functions. The American Statistician , 76(3):292--304
2022
-
[13]
W., Lemeshow, S., and Sturdivant, R
Hosmer Jr, D. W., Lemeshow, S., and Sturdivant, R. X. (2013). Applied logistic regression . John Wiley & Sons
2013
-
[14]
Jun, S. J. and Lee, S. (2023). Average adjusted association: Efficient estimation with high dimensional confounders. In Proceedings of The 26th International Conference on Artificial Intelligence and Statistics , volume 206 of Proceedings of Machine Learning Research , pages 5980--5996
2023
-
[15]
Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., Ye, Q., and Liu, T.-Y. (2017). Lightgbm: A highly efficient gradient boosting decision tree. In Advances in Neural Information Processing Systems 30 (NeurIPS 2017)
2017
-
[16]
Kennedy, E. H. (2023). Towards optimal doubly robust estimation of heterogeneous causal effects. Electronic Journal of Statistics , 17(2):3008--3049
2023
-
[17]
H., Ma, Z., McHugh, M
Kennedy, E. H., Ma, Z., McHugh, M. D., and Small, D. S. (2017). Nonparametric methods for doubly robust estimation of continuous treatment effects. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , 79(4):1229--1245
2017
-
[18]
R., Sekhon, J
K \"u nzel, S. R., Sekhon, J. S., Bickel, P. J., and Yu, B. (2019). Metalearners for estimating heterogeneous treatment effects using machine learning. Proceedings of the national academy of sciences , 116(10):4156--4165
2019
-
[19]
Sequential Double Robustness in Right-Censored Longitudinal Models
Luedtke, A. R., Sofrygin, O., van der Laan, M. J., and Carone, M. (2017). Sequential double robustness in right-censored longitudinal models. arXiv preprint arXiv:1705.02459
work page Pith review arXiv 2017
-
[20]
Luedtke, A. R. and van der Laan, M. J. (2016). Super-learning of an optimal dynamic treatment rule. The international journal of biostatistics , 12(1):305--332
2016
-
[21]
Malinsky, D., Shpitser, I., and Tchetgen Tchetgen, E. J. (2022). Semiparametric inference for nonmonotone missing-not-at-random data: the no self-censoring model. Journal of the American Statistical Association , 117(539):1415--1423
2022
-
[22]
Mittinty, M. N. and Lynch, J. (2023). Reflection on modern methods: risk ratio regression—simple concept yet complex computation. International journal of epidemiology , 52(1):309--314
2023
- [23]
-
[24]
and Wager, S
Nie, X. and Wager, S. (2021). Quasi-oracle estimation of heterogeneous treatment effects. Biometrika , 108(2):299--319
2021
-
[25]
Pearl, J. (2009). Causality: Models, Reasoning, and Inference . Cambridge University Press, Cambridge, 2 edition
2009
-
[26]
Pruim, R. (2014). NHANES: Data from the US National Health and Nutrition Examination Study . R package version 2.1.0
2014
-
[27]
and van der Laan , M
Rubin, D. and van der Laan , M. J. (2007). A doubly robust censoring unbiased transformation. The International Journal of Biostatistics , 3(1):Article 4
2007
-
[28]
E., Williams, N
Rudolph, K. E., Williams, N. T., Miles, C. H., Antonelli, J., and D \' az, I. (2023). All models are wrong, but which are useful? comparing parametric and nonparametric estimation of causal effects in finite samples. Journal of Causal Inference , 11(1):20230022
2023
- [29]
-
[30]
van der Laan, M. J. (2006). Statistical inference for variable importance. The International Journal of Biostatistics , 2(1)
2006
-
[31]
J., Polley, E
van der Laan, M. J., Polley, E. C., and Hubbard, A. E. (2007). Super learner. Statistical Applications in Genetics and Molecular Biology , 6(1):Article 25
2007
-
[32]
van der Laan , M. J. and Rubin, D. (2006). Targeted maximum likelihood learning. The International Journal of Biostatistics , 2(1)
2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.