Recognition: unknown
VidAudio-Bench: Benchmarking V2A and VT2A Generation across Four Audio Categories
Pith reviewed 2026-05-10 15:58 UTC · model grok-4.3
The pith
VidAudio-Bench reveals that current V2A models generate speech and singing poorly compared to sound effects, while VT2A conditioning trades visual alignment against instruction adherence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
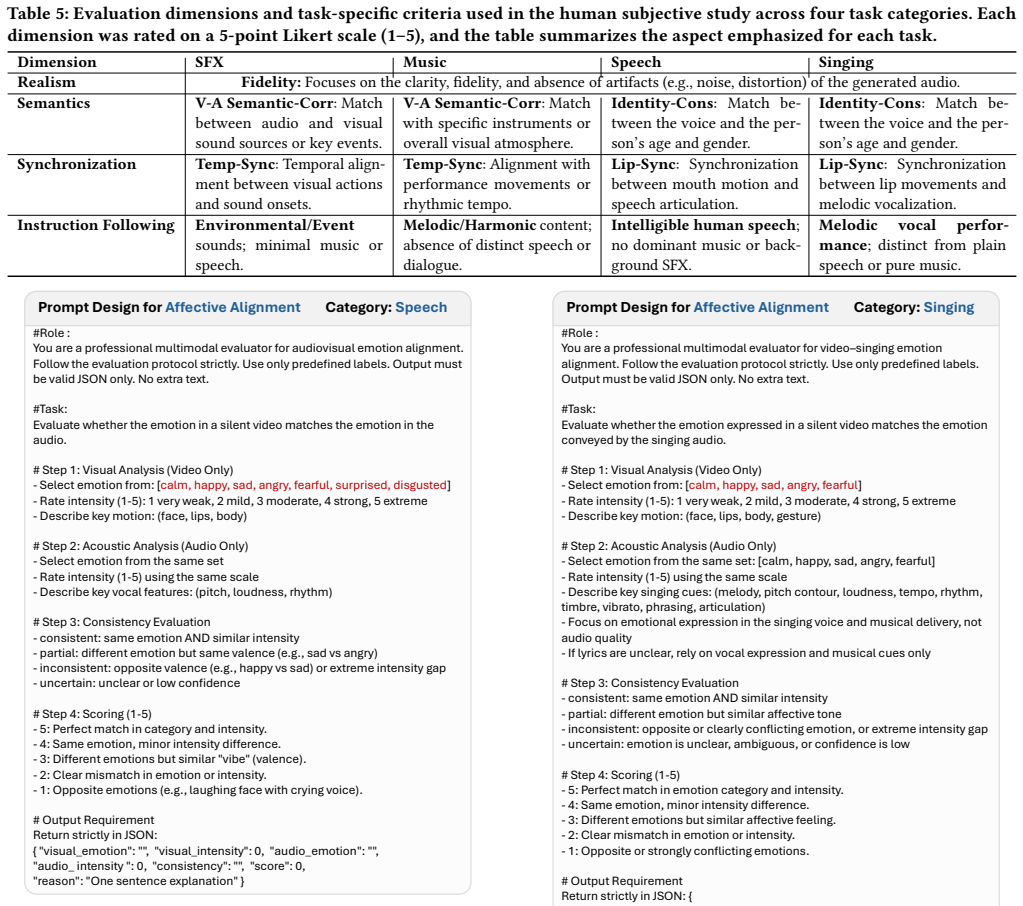
VidAudio-Bench is a benchmark that covers sound effects, music, speech, and singing with both V2A and VT2A tasks. It supplies 1,634 video-text pairs, evaluates 11 state-of-the-art models, and applies 13 task-specific reference-free metrics for audio quality, video-audio consistency, and text-audio consistency. All metrics are validated by subjective human studies that show strong alignment with preferences. The experiments find that existing V2A models perform markedly worse on speech and singing than on sound effects. The VT2A results demonstrate a fundamental tension in which stronger visual conditioning raises video-audio alignment but often prevents the model from producing the audio the
What carries the argument
VidAudio-Bench, a multi-task evaluation framework that splits evaluation by audio category and by conditioning type (visual-only versus visual-plus-text) to isolate category-specific performance and conditioning trade-offs.
Load-bearing premise
The four chosen audio categories together with the thirteen metrics capture the essential quality, consistency, and adherence challenges in video-to-audio generation without major gaps or systematic biases.
What would settle it
A new model that scores equally high across speech, singing, music, and sound effects in V2A while preserving both visual alignment and text category adherence in VT2A without measurable degradation would contradict the reported gaps and trade-off.
Figures















read the original abstract
Video-to-Audio (V2A) generation is essential for immersive multimedia experiences, yet its evaluation remains underexplored. Existing benchmarks typically assess diverse audio types under a unified protocol, overlooking the fine-grained requirements of distinct audio categories. To address this gap, we propose VidAudio-Bench, a multi-task benchmark for V2A evaluation with four key features: (1) Broad Coverage: It encompasses four representative audio categories - sound effects, music, speech, and singing - under both V2A and Video-Text-to-Audio (VT2A) settings. (2) Extensive Evaluation: It comprises 1,634 video-text pairs and benchmarks 11 state-of-the-art generation models. (3) Comprehensive Metrics: It introduces 13 task-specific, reference-free metrics to systematically assess audio quality, video-audio consistency, and text-audio consistency. (4) Human Alignment: It validates all metrics through subjective studies, demonstrating strong consistency with human preferences. Experimental results reveal that current V2A models perform poorly in speech and singing compared to sound effects. Our VT2A results further highlight a fundamental tension between instruction following and visually grounded generation: stronger visual conditioning improves video-audio alignment, but often at the cost of generating the intended audio category. These findings establish VidAudio-Bench as a comprehensive and scalable framework for diagnosing V2A systems and provide new insights into multimodal audio generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VidAudio-Bench, a multi-task benchmark for Video-to-Audio (V2A) and Video-Text-to-Audio (VT2A) generation. It covers four audio categories (sound effects, music, speech, singing) using 1,634 video-text pairs, evaluates 11 models, and applies 13 reference-free metrics for audio quality, video-audio consistency, and text-audio consistency. All metrics are validated via subjective human studies demonstrating alignment with preferences. Key results show V2A models perform worse on speech and singing than sound effects, while VT2A exhibits a trade-off where increased visual conditioning boosts alignment but reduces adherence to the target audio category.
Significance. If the findings hold, the work supplies a category-differentiated evaluation framework that improves on prior unified V2A benchmarks. The evaluation scale, dual V2A/VT2A coverage, and human-validated metrics constitute a practical resource for diagnosing model limitations in multimodal audio generation. The reported performance gaps and conditioning trade-off supply concrete directions for future model development.
major comments (2)
- [§3.2] §3.2 (Benchmark Construction): the sourcing of the 1,634 video-text pairs and any exclusion criteria for the four categories are not described in sufficient detail to assess potential selection bias or category representativeness, which directly affects the generalizability of the performance claims.
- [§5.3] §5.3 (VT2A Results): the 'fundamental tension' between visual conditioning and instruction following is presented as a central finding, yet the manuscript does not quantify the trade-off (e.g., correlation coefficients or per-model deltas between alignment and category-adherence metrics) or test whether it persists under alternative conditioning strengths.
minor comments (2)
- [Table 1] Table 1: the list of 11 evaluated models should include explicit citations or version numbers for reproducibility.
- [§4.1] §4.1 (Metric Definitions): a compact table summarizing the 13 metrics, their input requirements, and any tunable parameters would improve readability.
Simulated Author's Rebuttal
We are grateful to the referee for the positive evaluation of our paper and the recommendation for minor revision. We address each major comment point by point below and will incorporate the requested clarifications and quantifications into the revised manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Benchmark Construction): the sourcing of the 1,634 video-text pairs and any exclusion criteria for the four categories are not described in sufficient detail to assess potential selection bias or category representativeness, which directly affects the generalizability of the performance claims.
Authors: We agree that greater detail on benchmark construction is needed to allow readers to assess representativeness and potential biases. In the revised manuscript we will expand §3.2 with a dedicated subsection describing the data sources for each of the four categories, the exact number of video-text pairs per category, the collection procedure, and all exclusion criteria (video duration, audio quality thresholds, content relevance, and category-specific filters). revision: yes
-
Referee: [§5.3] §5.3 (VT2A Results): the 'fundamental tension' between visual conditioning and instruction following is presented as a central finding, yet the manuscript does not quantify the trade-off (e.g., correlation coefficients or per-model deltas between alignment and category-adherence metrics) or test whether it persists under alternative conditioning strengths.
Authors: We thank the referee for this constructive suggestion. We will revise §5.3 to quantify the trade-off by reporting Pearson (or Spearman) correlation coefficients between video-audio alignment metrics and category-adherence (text-audio consistency) metrics across all evaluated models, together with per-model deltas. We will also add an analysis of how the observed tension varies with different strengths of visual conditioning in our existing VT2A experiments and include this in the revised section. revision: yes
Circularity Check
No significant circularity; benchmark evaluation is self-contained
full rationale
The paper introduces VidAudio-Bench as an evaluation framework with four audio categories, 1634 video-text pairs, 11 models, and 13 reference-free metrics validated via separate subjective human studies. No mathematical derivations, parameter fitting, or predictions appear; performance claims follow directly from applying standard metrics to independent model outputs on held-out data. Self-citations, if present, support prior metric definitions but are not load-bearing for the central experimental findings. The reported trade-offs in VT2A are observational results, not reductions to inputs by construction. This matches the default expectation of no circularity for benchmark papers.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Reference-free metrics can reliably proxy audio quality, video-audio consistency, and text-audio consistency when validated by human studies.
- domain assumption The four chosen audio categories (sound effects, music, speech, singing) sufficiently represent the space of V2A requirements.
Reference graph
Works this paper leans on
-
[1]
Hassan Akbari, Liangzhe Yuan, Rui Qian, Wei-Hong Chuang, Shih-Fu Chang, Yin Cui, and Boqing Gong. 2021. Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text.Advances in neural information processing systems34 (2021), 24206–24221
2021
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al . 2025. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Abigail Berthe-Pardo, Gaspard Michel, Elena V Epure, and Christophe Cerisara
- [4]
-
[5]
Rachel M Bittner, Juan José Bosch, David Rubinstein, Gabriel Meseguer-Brocal, and Sebastian Ewert. 2022. A lightweight instrument-agnostic model for poly- phonic note transcription and multipitch estimation. InICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 781–785
2022
- [6]
-
[7]
Honglie Chen, Weidi Xie, Andrea Vedaldi, and Andrew Zisserman. 2020. Vg- gsound: A large-scale audio-visual dataset. InICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 721–725
2020
-
[8]
Ziyang Chen, Daniel Geng, and Andrew Owens. 2024. Images that sound: Composing images and sounds on a single canvas.Advances in Neural Information Processing Systems37 (2024), 85045–85073
2024
-
[9]
Ziyang Chen, Prem Seetharaman, Bryan Russell, Oriol Nieto, David Bourgin, Andrew Owens, and Justin Salamon. 2025. Video-guided foley sound generation with multimodal controls. InProceedings of the Computer Vision and Pattern Recognition Conference. 18770–18781
2025
-
[10]
Ho Kei Cheng, Masato Ishii, Akio Hayakawa, Takashi Shibuya, Alexander Schwing, and Yuki Mitsufuji. 2025. Mmaudio: Taming multimodal joint training for high-quality video-to-audio synthesis. InProceedings of the Computer Vision and Pattern Recognition Conference. 28901–28911
2025
-
[11]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Fredrik Cumlin, Xinyu Liang, Victor Ungureanu, Chandan KA Reddy, Christian Schüldt, and Saikat Chatterjee. 2024. DNSMOS Pro: A Reduced-Size DNN for Probabilistic MOS of Speech. InInterspeech
2024
-
[13]
Yusheng Dai, Zehua Chen, Yuxuan Jiang, Baolong Gao, Qiuhong Ke, Jun Zhu, and Jianfei Cai. 2026. Omni2Sound: Towards Unified Video-Text-to-Audio Generation. arXiv preprint arXiv:2601.02731(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Shangzhe Di, Zeren Jiang, Si Liu, Zhaokai Wang, Leyan Zhu, Zexin He, Hong- ming Liu, and Shuicheng Yan. 2021. Video background music generation with controllable music transformer. InProceedings of the 29th ACM International Conference on Multimedia. 2037–2045
2021
-
[15]
Hao-Wen Dong, Wen-Yi Hsiao, and Yi-Hsuan Yang. 2018. Pypianoroll: Open source Python package for handling multitrack pianoroll.Proc. ISMIR. Late- breaking paper(2018)
2018
-
[16]
Ariel Ephrat, Inbar Mosseri, Oran Lang, Tali Dekel, Kevin Wilson, Avinatan Hassidim, William T Freeman, and Michael Rubinstein. 2018. Looking to listen at the cocktail party: a speaker-independent audio-visual model for speech separation.ACM Transactions on Graphics (TOG)37, 4 (2018), 1–11
2018
-
[17]
Jort F Gemmeke, Daniel PW Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R Channing Moore, Manoj Plakal, and Marvin Ritter. 2017. Audio set: An ontology and human-labeled dataset for audio events. In2017 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 776–780
2017
-
[18]
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. 2023. Imagebind: One embedding space to bind them all. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 15180–15190
2023
-
[19]
Daili Hua, Xizhi Wang, Bohan Zeng, Xinyi Huang, Hao Liang, Junbo Niu, Xinlong Chen, Quanqing Xu, and Wentao Zhang. 2025. Vabench: A comprehensive benchmark for audio-video generation.arXiv preprint arXiv:2512.09299(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Po-Yao Huang, Hu Xu, Juncheng Li, Alexei Baevski, Michael Auli, Wojciech Galuba, Florian Metze, and Christoph Feichtenhofer. 2022. Masked autoencoders that listen.Advances in neural information processing systems35 (2022), 28708– 28720
2022
-
[21]
Rongjie Huang, Jiawei Huang, Dongchao Yang, Yi Ren, Luping Liu, Mingze Li, Zhenhui Ye, Jinglin Liu, Xiang Yin, and Zhou Zhao. 2023. Make-an-audio: Text- to-audio generation with prompt-enhanced diffusion models. InInternational Conference on Machine Learning. PMLR, 13916–13932
2023
-
[22]
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. 2024. Vbench: Comprehensive benchmark suite for video generative models. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 21807–21818
2024
-
[23]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpt-4o system card.arXiv preprint arXiv:2410.21276(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Vladimir Iashin and Esa Rahtu. 2021. Taming Visually Guided Sound Generation. InBritish Machine Vision Conference. BMVA Press
2021
-
[25]
Vladimir Iashin, Weidi Xie, Esa Rahtu, and Andrew Zisserman. 2024. Synch- former: Efficient synchronization from sparse cues. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 5325–5329
2024
- [26]
-
[27]
Yujin Jeong, Yunji Kim, Sanghyuk Chun, and Jiyoung Lee. 2025. Read, watch and scream! sound generation from text and video. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 17590–17598
2025
-
[28]
Felix Kreuk, Gabriel Synnaeve, Adam Polyak, Uriel Singer, Alexandre Défossez, Jade Copet, Devi Parikh, Yaniv Taigman, and Yossi Adi. [n. d.]. AudioGen: Textually Guided Audio Generation. InThe Eleventh International Conference on Learning Representations
- [29]
-
[30]
Susan Liang, Chao Huang, Filippos Bellos, Yolo Yunlong Tang, Qianxiang Shen, Jing Bi, Luchuan Song, Zeliang Zhang, Jason Corso, and Chenliang Xu
- [31]
-
[32]
Haohe Liu, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo Mandic, Wenwu Wang, and Mark Plumbley. 2023. AudioLDM: Text-to-Audio Generation with Latent Diffusion Models. InProceedings of the 40th International Conference on Machine Learning, PMLR 2023, Vol. 202. International Machine Learning Society (IMLS), 21450–21474
2023
-
[33]
Huadai Liu, Kaicheng Luo, Jialei Wang, Wen Wang, Qian Chen, Zhou Zhao, and Wei Xue. [n. d.]. ThinkSound: Chain-of-Thought Reasoning in Multimodal LLMs for Audio Generation and Editing. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[34]
Yaofang Liu, Xiaodong Cun, Xuebo Liu, Xintao Wang, Yong Zhang, Haoxin Chen, Yang Liu, Tieyong Zeng, Raymond Chan, and Ying Shan. 2024. Evalcrafter: Benchmarking and evaluating large video generation models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 22139–22149
2024
-
[35]
Simian Luo, Chuanhao Yan, Chenxu Hu, and Hang Zhao. 2023. Diff-foley: Synchronized video-to-audio synthesis with latent diffusion models.Advances in Neural Information Processing Systems36 (2023), 48855–48876
2023
-
[36]
Jan Melechovsky, Zixun Guo, Deepanway Ghosal, Navonil Majumder, Dorien Herremans, and Soujanya Poria. 2024. Mustango: Toward controllable text-to- music generation. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies (Volume 1: Long Papers). 8293–8316
2024
- [37]
-
[38]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[39]
In International conference on machine learning
Learning transferable visual models from natural language supervision. In International conference on machine learning. PmLR, 8748–8763
-
[40]
Dominik Roblek, Kevin Kilgour, Matt Sharifi, and Mauricio Zuluaga. 2019. Fr\’echet Audio Distance: A Reference-free Metric for Evaluating Music En- hancement Algorithms. InProc. Interspeech. 2350–2354. 9
2019
-
[41]
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. 2016. Improved techniques for training gans.Advances in neural information processing systems29 (2016)
2016
- [42]
-
[43]
Roy Sheffer and Yossi Adi. 2023. I hear your true colors: Image guided audio gen- eration. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2023
-
[44]
Guangzhi Sun, Wenyi Yu, Changli Tang, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, Yuxuan Wang, and Chao Zhang. 2024. video-SALMONN: speech-enhanced audio-visual large language models. InProceedings of the 41st International Conference on Machine Learning. 47198–47217
2024
-
[45]
Cees H Taal, Richard C Hendriks, Richard Heusdens, and Jesper Jensen. 2011. An algorithm for intelligibility prediction of time–frequency weighted noisy speech.IEEE Transactions on audio, speech, and language processing19, 7 (2011), 2125–2136
2011
- [46]
-
[47]
Sida Tian, Can Zhang, Wei Yuan, Wei Tan, and Wenjie Zhu. 2025. Xmusic: Towards a generalized and controllable symbolic music generation framework. IEEE Transactions on Multimedia27 (2025), 6857–6871
2025
-
[48]
Zeyue Tian, Yizhu Jin, Zhaoyang Liu, Ruibin Yuan, Xu Tan, Qifeng Chen, Wei Xue, and Yike Guo. 2025. Audiox: Diffusion transformer for anything-to-audio generation.arXiv preprint arXiv:2503.10522(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Zeyue Tian, Zhaoyang Liu, Ruibin Yuan, Jiahao Pan, Qifeng Liu, Xu Tan, Qifeng Chen, Wei Xue, and Yike Guo. 2025. Vidmuse: A simple video-to-music genera- tion framework with long-short-term modeling. InProceedings of the Computer Vision and Pattern Recognition Conference. 18782–18793
2025
- [50]
-
[51]
Ilpo Viertola, Vladimir Iashin, and Esa Rahtu. 2025. Temporally aligned audio for video with autoregression. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2025
-
[52]
Hui Wang, Cheng Liu, Junyang Chen, Haoze Liu, Yuhang Jia, Shiwan Zhao, Jiaming Zhou, Haoqin Sun, Hui Bu, and Yong Qin. 2026. Tta-bench: A compre- hensive benchmark for evaluating text-to-audio models. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 33512–33520
2026
-
[53]
Heng Wang, Jianbo Ma, Santiago Pascual, Richard Cartwright, and Weidong Cai. 2024. V2a-mapper: A lightweight solution for vision-to-audio generation by connecting foundation models. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 15492–15501
2024
- [54]
- [55]
-
[56]
Yongqi Wang, Wenxiang Guo, Rongjie Huang, Jiawei Huang, Zehan Wang, Fuming You, Ruiqi Li, and Zhou Zhao. 2024. Frieren: Efficient video-to-audio generation network with rectified flow matching.Advances in neural information processing systems37 (2024), 128118–128138
2024
-
[57]
Zehan Wang, Ke Lei, Chen Zhu, Jiawei Huang, Sashuai Zhou, Luping Liu, Xize Cheng, Shengpeng Ji, Zhenhui Ye, Tao Jin, et al. 2025. T2A-Feedback: Improving Basic Capabilities of Text-to-Audio Generation via Fine-grained AI Feedback. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics. 23535–23547
2025
-
[58]
Zehan Wang, Ziang Zhang, Xize Cheng, Rongjie Huang, Luping Liu, Zhenhui Ye, Haifeng Huang, Yang Zhao, Tao Jin, Peng Gao, et al. 2024. FreeBind: free lunch in unified multimodal space via knowledge fusion. InProceedings of the 41st International Conference on Machine Learning. 52233–52246
2024
- [59]
-
[60]
Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, and Shlomo Dubnov. 2023. Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2023
-
[61]
Zhifeng Xie, Shengye Yu, Qile He, and Mengtian Li. 2024. Sonicvisionlm: Playing sound with vision language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 26866–26875
2024
-
[62]
Yazhou Xing, Yingqing He, Zeyue Tian, Xintao Wang, and Qifeng Chen. 2024. Seeing and hearing: Open-domain visual-audio generation with diffusion latent aligners. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7151–7161
2024
-
[63]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. 2025. Qwen3-omni technical report. arXiv preprint arXiv:2509.17765(2025)
work page internal anchor Pith review arXiv 2025
- [64]
-
[65]
Dongchao Yang, Jianwei Yu, Helin Wang, Wen Wang, Chao Weng, Yuexian Zou, and Dong Yu. 2023. Diffsound: Discrete diffusion model for text-to-sound generation.IEEE/ACM Transactions on Audio, Speech, and Language Processing 31 (2023), 1720–1733
2023
-
[66]
Geng Yang, Shan Yang, Kai Liu, Peng Fang, Wei Chen, and Lei Xie. 2021. Multi- band melgan: Faster waveform generation for high-quality text-to-speech. In 2021 IEEE Spoken Language Technology Workshop (SLT). IEEE, 492–498
2021
-
[67]
Yochai Yemini, Aviv Shamsian, Lior Bracha, Sharon Gannot, and Ethan Fetaya. [n. d.]. LipVoicer: Generating Speech from Silent Videos Guided by Lip Reading. InThe Twelfth International Conference on Learning Representations
-
[68]
Ryandhimas E Zezario, Szu-Wei Fu, Chiou-Shann Fuh, Yu Tsao, and Hsin-Min Wang. 2020. STOI-Net: A deep learning based non-intrusive speech intelligi- bility assessment model. In2020 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC). IEEE, 482–486
2020
-
[69]
Hang Zhang, Xin Li, and Lidong Bing. 2023. Video-llama: An instruction-tuned audio-visual language model for video understanding. InProceedings of the 2023 conference on empirical methods in natural language processing: system demonstrations. 543–553
2023
-
[70]
Liqian Zhang and Magdalena Fuentes. 2025. Sonique: Video background music generation using unpaired audio-visual data. InICASSP 2025-2025 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2025
-
[71]
Yiming Zhang, Yicheng Gu, Yanhong Zeng, Zhening Xing, Yuancheng Wang, Zhizheng Wu, Bin Liu, and Kai Chen. 2026. Foleycrafter: Bring silent videos to life with lifelike and synchronized sounds.International Journal of Computer Vision134, 1 (2026), 46
2026
-
[72]
Yipin Zhou, Zhaowen Wang, Chen Fang, Trung Bui, and Tamara L Berg. 2018. Visual to sound: Generating natural sound for videos in the wild. InProceedings of the IEEE conference on computer vision and pattern recognition. 3550–3558
2018
-
[73]
Zitang Zhou, Ke Mei, Yu Lu, Tianyi Wang, and Fengyun Rao. 2025. Harmonyset: A comprehensive dataset for understanding video-music semantic alignment and temporal synchronization. InProceedings of the Computer Vision and Pattern Recognition Conference. 3152–3162
2025
-
[74]
Alon Ziv, Itai Gat, Gael Le Lan, Tal Remez, Felix Kreuk, Jade Copet, Alexandre Défossez, Gabriel Synnaeve, and Yossi Adi. [n. d.]. Masked Audio Generation using a Single Non-Autoregressive Transformer. InThe Twelfth International Conference on Learning Representations
-
[75]
Heda Zuo, Weitao You, Junxian Wu, Shihong Ren, Pei Chen, Mingxu Zhou, Yujia Lu, and Lingyun Sun. 2025. Gvmgen: A general video-to-music generation model with hierarchical attentions. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 23099–23107
2025
-
[76]
The video shows,
Daniil Zverev, Thaddäus Wiedemer, Ameya Prabhu, Matthias Bethge, Wieland Brendel, and A Koepke. 2025. Vggsounder: Audio-visual evaluations for founda- tion models. InProceedings of the IEEE/CVF International Conference on Computer Vision. 1027–1037. 10 A VidAudio-Bench Construction To support reliable evaluation of V2A and VT2A systems, we con- struct sub...
2025
-
[80]
# Step 2: Acoustic Analysis (Audio Only) Estimate:
age confidence [0.0-1.0] Use only visual cues such as face structure, skin appearance, hair, lip movement, overall visible age impression, and other observable appearance cues. # Step 2: Acoustic Analysis (Audio Only) Estimate:
-
[81]
apparent gender presentation [male-presenting / female-presenting / ambiguous]
-
[82]
apparent age group [Child (0–12), Teenage (13–17), Adult (18–59), Senior (60+)]
-
[83]
gender confidence [0.0-1.0]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.