A Deep Generative Approach to Stratified Learning
Pith reviewed 2026-05-10 15:36 UTC · model grok-4.3
The pith
Deep generative models can learn distributions on stratified spaces and consistently estimate the number and dimensions of their strata.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We provide a deep generative approach to stratified learning by developing two generative frameworks for learning distributions on stratified spaces. The first is a sieve maximum likelihood approach realized via a dimension-aware mixture of variational autoencoders. The second is a diffusion-based framework that explores the score field structure of a mixture. We establish the convergence rates for learning both the ambient and intrinsic distributions, which are shown to be dependent on the intrinsic dimensions and smoothness of the underlying strata. Utilizing the geometry of the score field, we also establish consistency for estimating the intrinsic dimension of each stratum and propose an
What carries the argument
dimension-aware mixture of variational autoencoders combined with diffusion-based score field analysis of the mixture distribution
If this is right
- Convergence rates for distribution learning depend on the intrinsic dimensions and smoothness of the strata.
- The methods allow consistent estimation of both the number of strata and their individual dimensions.
- The approaches provide insights into the interplay between underlying geometry, ambient noise, and deep generative models.
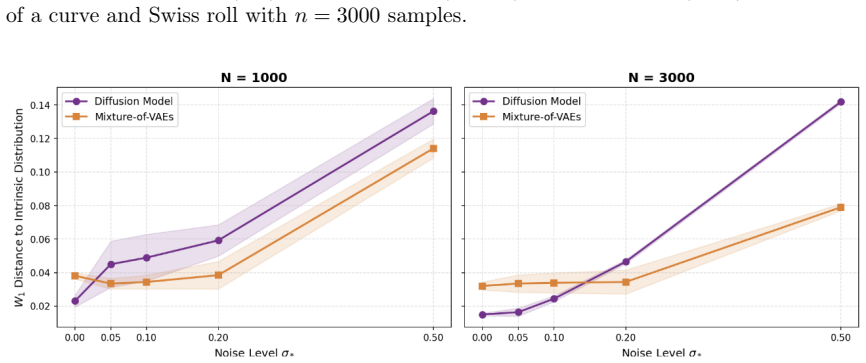
- Effectiveness is shown in simulations and applications such as molecular dynamics data.
Where Pith is reading between the lines
- These frameworks could be extended to handle data with unknown or varying noise levels beyond the assumed ambient noise.
- Applications might include processing image or sensor data where different regions have different intrinsic dimensionalities.
- Testing on synthetic data with controlled singularities at stratum intersections could further validate the score field geometry approach.
Load-bearing premise
The observed data is generated from a stratified space that is a finite union of smooth manifolds with an ambient noise level low enough for the convergence and consistency results to apply.
What would settle it
Running the proposed algorithm on a dataset generated from known strata with specified dimensions and observing that the estimated number or dimensions do not match the true values with high probability.
Figures




read the original abstract
While the manifold hypothesis is widely adopted in modern machine learning, complex data is often better modeled as stratified spaces -- unions of manifolds (strata) of varying dimensions. Stratified learning is challenging due to varying dimensionality, intersection singularities, and lack of efficient models in learning the underlying distributions. We provide a deep generative approach to stratified learning by developing two generative frameworks for learning distributions on stratified spaces. The first is a sieve maximum likelihood approach realized via a dimension-aware mixture of variational autoencoders. The second is a diffusion-based framework that explores the score field structure of a mixture. We establish the convergence rates for learning both the ambient and intrinsic distributions, which are shown to be dependent on the intrinsic dimensions and smoothness of the underlying strata. Utilizing the geometry of the score field, we also establish consistency for estimating the intrinsic dimension of each stratum and propose an algorithm that consistently estimates both the number of strata and their dimensions. Theoretical results for both frameworks provide fundamental insights into the interplay of the underlying geometry, the ambient noise level, and deep generative models. Extensive simulations and real dataset applications, such as molecular dynamics, demonstrate the effectiveness of our methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes two deep generative frameworks for learning distributions on stratified spaces (finite unions of manifolds of varying dimensions): (1) a sieve maximum likelihood estimator realized as a dimension-aware mixture of variational autoencoders, and (2) a diffusion model that exploits the geometry of the score field of a mixture. It claims to derive convergence rates for both ambient and intrinsic distributions that explicitly depend on the intrinsic dimensions and smoothness of the strata, along with consistency guarantees for estimating the number of strata and the dimension of each stratum. The claims are supported by theoretical analysis, simulations, and applications to real data such as molecular dynamics.
Significance. If the stated convergence rates and consistency results hold under the data-generation assumption of a stratified space with sufficient smoothness and controlled ambient noise, the work would meaningfully extend generative modeling beyond the standard manifold hypothesis. The explicit dependence of the rates on intrinsic dimension and smoothness, together with the dual likelihood-based and score-based frameworks, provides concrete insights into the geometry-noise-model interplay. The consistent estimation algorithm for stratum count and dimensions is a practical contribution with potential impact in domains where data naturally lives on unions of manifolds of heterogeneous dimension.
major comments (2)
- [Abstract / Theoretical Results] Abstract and theoretical sections: the manuscript asserts convergence rates for ambient and intrinsic distributions and consistency of stratum/dimension estimation, yet supplies no proof sketches, explicit regularity conditions (e.g., Hölder smoothness class, noise-level bounds, or separation conditions on strata), or derivation outlines. Because these rates and consistency statements constitute the central theoretical contribution, their validity cannot be assessed from the provided material.
- [Theoretical Results] The weakest assumption isolated in the reader report (data generated from a stratified space with sufficient smoothness and ambient noise level) is necessary for the claimed rates to apply, but the manuscript does not verify or state the precise quantitative conditions under which the rates remain valid when strata intersect or when ambient noise approaches the intrinsic scale.
minor comments (2)
- [Method 1] The description of the dimension-aware VAE mixture would benefit from an explicit statement of how the per-component latent dimension is selected or regularized during training.
- [Method 2] Notation for the score-field geometry in the diffusion framework should be clarified to distinguish between the ambient score and the intrinsic score on each stratum.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on our work. We address each major comment below and have revised the manuscript to incorporate additional details on regularity conditions and proof outlines as requested.
read point-by-point responses
-
Referee: [Abstract / Theoretical Results] Abstract and theoretical sections: the manuscript asserts convergence rates for ambient and intrinsic distributions and consistency of stratum/dimension estimation, yet supplies no proof sketches, explicit regularity conditions (e.g., Hölder smoothness class, noise-level bounds, or separation conditions on strata), or derivation outlines. Because these rates and consistency statements constitute the central theoretical contribution, their validity cannot be assessed from the provided material.
Authors: We acknowledge that the main text provided limited explicit statements of the regularity conditions and no proof sketches, which hinders assessment. In the revised manuscript we have added a dedicated subsection in Section 3 that states the precise assumptions: data generated from a stratified space with Hölder smoothness of order β on each stratum, ambient noise level σ satisfying σ = o(n^{-1/(2β+d)}) where d is the maximum intrinsic dimension, and strata separated by a minimum distance δ > 0. We have also inserted concise proof outlines for the main convergence theorems (Theorems 3.1 and 3.3) and the consistency result for stratum estimation (Theorem 4.1), with full derivations remaining in the appendix. These additions directly address the central theoretical claims. revision: yes
-
Referee: [Theoretical Results] The weakest assumption isolated in the reader report (data generated from a stratified space with sufficient smoothness and ambient noise level) is necessary for the claimed rates to apply, but the manuscript does not verify or state the precise quantitative conditions under which the rates remain valid when strata intersect or when ambient noise approaches the intrinsic scale.
Authors: We agree that quantitative conditions for intersecting strata and near-intrinsic noise levels were not sufficiently detailed. The revision adds a remark after Theorem 3.2 clarifying that intersections are permitted on sets of Hausdorff dimension strictly lower than the adjacent strata, provided the measure of the intersection is controlled by a factor smaller than the separation δ. For ambient noise approaching the intrinsic scale, we now state that the rates degrade by a multiplicative log n factor but remain consistent; explicit bounds appear in the updated statement of Theorem 3.4. These conditions are verified analytically under the maintained smoothness and noise assumptions. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper develops two generative frameworks (dimension-aware VAE mixture for sieve MLE and diffusion on score-field geometry) for distributions on stratified spaces, derives convergence rates for ambient and intrinsic distributions that explicitly depend on stated assumptions about intrinsic dimensions, smoothness, and ambient noise, and proposes a consistent estimator for stratum count and per-stratum dimensions. No load-bearing step reduces by construction to a fitted parameter renamed as prediction, a self-citation chain, or an ansatz smuggled via prior work; the results follow from the granted data-generation assumption and standard deep generative modeling techniques without self-referential definitions or renaming of known empirical patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Data is generated from a stratified space consisting of a finite union of manifolds of varying intrinsic dimensions.
- domain assumption The strata possess sufficient smoothness and the observations include ambient noise at a level that permits the claimed convergence rates.
Reference graph
Works this paper leans on
-
[1]
Denotedist(x,M)as the distance of pointx∈R D toM. Then Z ∥∇logp t(x)−S(x, t)∥ 2 pt(x) dx ≤ Z ∥∇logp t(x)−S(x, t)∥ 2 pt(x)·1 dist(x,M)≤c 0eσti p logn dx+ (1 +c 2)·c 1 1 n2 . 43
-
[2]
For anyx∈R D satisfyingdist(x,M)≤c 0eσti √logn, we have (a)∥∇logp t(x)∥∞ ≤c 2 √logn eσti . (b)(2πeσ2 t ) D 2 pt(x)≥n −c3. Furthermore, we will use Lemma C.2 of Tang and Yang (2024) to bound the covering number ofM k. Lemma 25(Lemma C.2 of Tang and Yang (2024)) For anyk∈[K]and anyϵ >0, there exists anϵ-coverN k,ϵ ofM k so thatN k,ϵ ⊂ M k and|N k,ϵ|≲(ϵ∧1) −...
work page 2024
-
[3]
Approximatem t byϕ m(t)∈Φ(L ′ 1, W ′ 1, R′ 1, B′ 1)withL ′ 1 = Θ(log 4 n),∥W ′ 1∥∞ = Θ(log6 n),R ′ 1 = Θ(log8 n)andB 1 = exp(Θ(log4 n))
-
[4]
Approximateσ t byϕ σ(t)∈Φ(L ′ 2, W ′ 2, R′ 2, B′ 2)withL ′ 2 = Θ(log4 n),∥W ′ 2∥∞ = Θ(log6 n), R′ 2 = Θ(log8 n)andB ′ 2 = exp(Θ(log4 n))
-
[5]
Approximate 1 x byϕ rec(x)∈Φ(L ′ 3, W ′ 3, R′ 3, B′ 3)withL ′ 3 = Θ(log 4 n),∥W ′ 3∥∞ = Θ(log6 n),R ′ 3 = Θ(log8 n)andB ′ 3 = exp(Θ(log4 n))
-
[6]
For vectorx∈R D ands∈N D, approximatex s byϕ [D] vpower(x;s)∈Φ(L ′ 4, W ′ 4, R′ 4, B′ 4) withL ′ 4 = Θ(log 2 n·log logn),∥W ′ 4∥∞ = Θ(logn),R ′ 4 = Θ(log 3 n)andB ′ 4 = exp(Θ(logn·log logn))
-
[7]
Forx∈R, Approximatex a byϕ power(x;a)∈Φ(L ′ 5, W ′ 5, R′ 5, B′ 5)withL ′ 5 = Θ(log2 n· log logn),∥W ′ 5∥∞ = Θ(logn),R ′ 5 = Θ(log3 n)andB ′ 5 = exp(Θ(logn·log logn))
-
[8]
Forx∈R, y∈R D, we denoteϕmult(x, y) = (ϕmult(x, y1), ϕmult(x, y2),· · ·, ϕ mult(x, yD))
Forx, y∈R, Approximatex·ybyϕ mult(x, y)∈Φ(L ′ 6, W ′ 6, R′ 6, B′ 6)withL ′ 6 = Θ(log2 n),∥W ′ 6∥∞ = Θ(1),R ′ 6 = Θ(log 2 n)andB ′ 6 = exp(Θ(log 2 n)). Forx∈R, y∈R D, we denoteϕmult(x, y) = (ϕmult(x, y1), ϕmult(x, y2),· · ·, ϕ mult(x, yD)). 49 Then we denoteϕ 1 eσ2 (t) =ϕ rec(σ2 ∗ ·ϕ power(ϕm(t),2) +ϕ power(ϕσ(t),2))andϕ ρ(x;x ∗, a) = ρ |x−x∗| a . Using th...
work page 2023
-
[9]
+ 1 2 σ2 ti ≳σ 2 ∗ + 1∧t i, where we have used thatσ∗ ≤1. Hence, we have E Z ti+1 ti Z RD bS(x, t)− ∇logp t(x) 2 pt(x) dxdt = eO KX k=1 (eσti)−dk n = eO KX k=1 min(n − 2αk 2αk +dk , (σ∗ + √1∧t i)−dk n ) , and E ((ti logn)∧1)· Z ti+1 ti Z RD bS(x, t)− ∇logp t(x) 2 pt(x) dxdt = eO KX k=1 (eσti)−dk+2 n = eO 1 n + KX k=1 min(n − 2αk +2 2αk +dk , σ2−dk ∗ n ) ....
-
[10]
= X k∈K2 ωk P eJk j=1 Ey∼Qk h exp − ∥x−mty∥2 2eσ2 t · − x−mty eσ2 t i ·ρ |x−ex∗ kj | c4n−1/(2αk +dk ) max 1,P eJk j=1 ρ |x−ex∗ kj | c4n−1/(2αk +dk ) , and (B ′
-
[11]
= X k∈K2 ωk P eJk j=1 Ey∼Qk h exp − ∥x−mty∥2 2eσ2 t i ·ρ |x−ex∗ kj | c4n−1/(2αk +dk ) max 1,P eJk j=1 ρ |x−ex∗ kj | c4n−1/(2αk +dk ) . 53 With sufficiently largec4, for anyt∈[t i, ti+1]andx∈R D withdist(x,M)≤c 0eσti √logn, ∥(A2)−(A ′ 2)∥ = X k∈K2 ωk ·1 eJkX j=1 ρ |x−ex∗ kj | c4n−1/(2αk+dk) ≤1 · P eJk j=1 ρ |x−ex∗ kj | c4n−1/(2αk +dk ) max 1,P eJk j=1 ρ |x...
-
[12]
2.B r(y∗)∩ M ⊂Ψ y∗(Br(0D)∩T y∗M)⊂B 8r/7(y∗)∩ M
The projection functionProj Ty∗ M(x−y ∗)is a local diffeomorphism iny ∗, with the inverseΨ y∗ defined onB r(0D)∩T y∗Mand isβ-smooth. 2.B r(y∗)∩ M ⊂Ψ y∗(Br(0D)∩T y∗M)⊂B 8r/7(y∗)∩ M. Then for anyk∈ K 2 andj∈[ eJk], letV kj be an arbitrary orthonormal basis for the tangent spaceT ex∗ kj Mk atex∗ kj. Define a functionG∗ kj with domainB r(0dk)so that G∗ kj(z) ...
work page 2024
-
[13]
= X k∈K2 ωk max 1,P eJk j=1 ρ |x−x∗ kj | c4n−1/(2αk +dk ) · eJkX j=1 Z {y=G∗ jk(z) :∥z−ϕ p jk(x)∥∞≤c5eσti √logn} exp − ∥x−m ty∥2 2eσ2 t · − x−m ty eσ2 t qk(y) dvolMk(y) ·ρ |x−ex∗ kj | c4n−1/(2αk+dk) ρ |x−G kj(ϕp kj(x))| c6eσti √logn , and (B ′′ 2 ) = X k∈K2 ωk max 1,P eJk j=1 ρ |x−ex∗ kj | c4n−1/(2αk +dk ) · eJkX j=1 Z {y=G∗ jk(z) :∥z−ϕ p jk(x)∥∞≤c5eσti √...
-
[14]
= X k∈K2 ωk max 1,P eJk j=1 ρ |x−x∗ kj | c4n−1/(2αk +dk ) · eJkX j=1 Z {z∈Rdk :∥z−ϕ p jk(x)∥∞≤c5eσti √logn} exp − ∥x−m tG∗ jk(z)∥2 2eσ2 t · − x−m tG∗ jk(z) eσ2 t v∗ kj(z) dz ·ρ |x−ex∗ kj | c4n−1/(2αk+dk) ρ |x−G kj(ϕp kj(x))| c6eσti √logn For anyk∈ K 2, andj∈[ eJk], consider the Taylor expansion ofv∗ kj at0 dk, v∗ kj(z) =v kj(z) +O(∥z∥ αk), where vkj(z) =v...
-
[15]
= X k∈K2 eJkX j=1 ωkρ |x−ex∗ kj | c4n−1/(2αk +dk ) ρ |x−Gkj(ϕp kj(x))| c6eσti √logn max 1,P eJk j=1 ρ |x−x∗ kj | c4n−1/(2αk +dk ) ·exp − ∥x−G kj(ϕp kj(x))∥2 2eσ2 t · Z {z∈Rdk :∥z−ϕ p jk(x)∥∞≤c5eσti √logn} L1X l1=0 (−1)l1 ∥Gkj(ϕp kj(x))−m tGjk(z)∥2l1 l1!2l1eσ2l1 t · L2X l2=0 (−1)l2 ⟨x−G kj(ϕp kj(x)), Gkj(ϕp kj(x))−m tGjk(z)⟩l2 l2!eσ2l2 t · − x−m tGjk(z) eσ...
-
[16]
= X k∈K2 eJkX j=1 ωkρ |x−ex∗ kj | c4n−1/(2αk +dk ) ρ |x−Gkj(ϕp kj(x))| c6eσti √logn max 1,P eJk j=1 ρ |x−x∗ kj | c4n−1/(2αk +dk ) ·exp − ∥x−G kj(ϕp kj(x))∥2 2eσ2 t · Z {z∈Rdk :∥z−ϕ p jk(x)∥∞≤c5eσti √logn} L1X l1=0 (−1)l1 ∥Gkj(ϕp kj(x))−m tGjk(z)∥2l1 l1!2l1eσ2l1 t · L2X l2=0 (−1)l2 ⟨x−G kj(ϕp kj(x)), Gkj(ϕp kj(x))−m tGjk(z)⟩l2 l2!eσ2l2 t vkj(z) dz. Then no...
-
[17]
using ReLU neural network. SinceGkj(z)andv kj(z) are polynomials with degree at most⌊βk⌋and⌊α k⌋respectively, we can rewrite(A ∗ 2)and (B∗ 2)as (A∗
-
[18]
= X k∈K2 eJkX j=1 ωkρ |x−ex∗ kj | c4n−1/(2αk +dk ) ρ |x−Gkj(ϕp kj(x))| c6eσti √logn max 1,P eJk j=1 ρ |x−x∗ kj | c4n−1/(2αk +dk ) ·exp − ∥x−G kj(ϕp kj(x))∥2 2eσ2 t · L1X l1=0 L2X l2=0 1 eσt 2l1+2l2+2 X 0≤s1≤2l1+l2+1 ms1 t X s2∈N dk 0 ,|s2|≤(2l1+2l2+1)⌊βk⌋+dk+⌊αk⌋ (ϕp jk(x))(s2) · X s3∈ND 0 ,|s3|≤l2+1 a′ k,j,l1,l2,s1,s2,s3 ·x (s3), and (B∗
-
[19]
Then we will use Lemmas 26, 27 and 28 for the approximationm t,σ t, monomial and reciprocal function
= X k∈K2 eJkX j=1 ωkρ |x−ex∗ kj | c4n−1/(2αk +dk ) ρ |x−Gkj(ϕp kj(x))| c6eσti √logn max 1,P eJk j=1 ρ |x−x∗ kj | c4n−1/(2αk +dk ) ·exp − ∥x−G kj(ϕp kj(x))∥2 2eσ2 t · L1X l1=0 L2X l2=0 1 eσt 2l1+2l2 X 0≤s1≤2l1+l2 ms1 t X s2∈N dk 0 ,|s2|≤(2l1+2l2)⌊βk⌋+dk+⌊αk⌋ (ϕp jk(x))(s2) · X s3∈ND 0 ,|s3|≤l2 b′ k,j,l1,l2,s1,s2,s3 ·x (s3), wherea ′ k,j,l1,l2,s1,s2,s3 ∈R D...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.