Recognition: unknown
INCRT: An Incremental Transformer That Determines Its Own Architecture
Pith reviewed 2026-05-10 14:59 UTC · model grok-4.3
The pith
A transformer can determine its own number of attention heads during training by adding and pruning them based on a geometric measure of the task.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The INCRT model begins training with one attention head and incrementally adds a new head whenever a single online-computable geometric quantity shows that the current setup fails to capture enough directional energy from the input. It simultaneously prunes heads that have become redundant. The homeostatic convergence theorem guarantees that this process terminates at a finite configuration that is minimal, containing no redundant heads, and sufficient, with no uncaptured directional energy above the threshold. The compressed-sensing analogy theorem supplies an upper bound on the size of this configuration in terms of the task's spectral complexity. Validation on SARS-CoV-2 variant classific
What carries the argument
The geometric quantity derived from the task's directional structure, which is used both to detect insufficiency for adding heads and to identify redundancy for pruning.
If this is right
- The need for manual architecture design and trial-and-error tuning is removed for attention head count.
- Trained models require substantially less memory and computation due to fewer parameters while maintaining performance on the target tasks.
- No separate validation phase or hand-tuned schedules are required for making growth and pruning decisions.
- The final head count is predictable from the task's spectral complexity via the compressed-sensing bound.
- Competitive results are achievable on domain-specific tasks without relying on large-scale pre-training.
Where Pith is reading between the lines
- This mechanism could be generalized to other architectural decisions like model depth or width if analogous geometric indicators are identified.
- The reliance on directional structure suggests that attention heads primarily capture distinct directions in the data representation space.
- Similar incremental approaches might reduce overparameterization in other neural network families beyond transformers.
- Further tests on high-complexity tasks could verify if the head count scales linearly with spectral complexity as the bound implies.
Load-bearing premise
A single geometric quantity from the directional structure of the task can reliably indicate both when the current head configuration is insufficient and when individual heads have become redundant, all computed online without validation data.
What would settle it
Apply the method to a new task and measure whether the final configuration has every head contributing unique directional information and no further head addition would reduce uncaptured energy, or whether the head count greatly exceeds the predicted upper bound from spectral complexity.
Figures





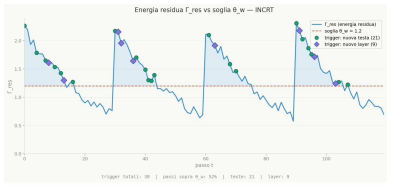


read the original abstract
Transformer architectures are designed by trial and error: the number of attention heads, the depth, and the head size are fixed before training begins, with no mathematical principle to guide the choice. The result is systematic structural redundancy -- between half and four-fifths of all heads in a trained model can be removed without measurable loss -- because the architecture allocates capacity without reference to the actual requirements of the task.This paper introduces INCRT (Incremental Transformer), an architecture that determines its own structure during training. Starting from a single head, INCRT adds one attention head at a time whenever its current configuration is provably insufficient, and prunes heads that have become redundant. Each growth decision is driven by a single, online-computable geometric quantity derived from the task's directional structure, requiring no separate validation phase and no hand-tuned schedule. Two theorems form the theoretical backbone. The first (homeostatic convergence) establishes that the system always reaches a finite stopping configuration that is simultaneously minimal (no redundant heads) and sufficient (no uncaptured directional energy above the threshold). The second (compressed-sensing analogy) provides a geometric upper bound on the number of heads that this configuration can contain, as a function of the spectral complexity of the task. Experiments on SARS-CoV-2 variant classification and SST-2 sentiment analysis confirm both results: the predicted and observed head counts agree within 12% across all benchmarks, and the final architectures match or exceed BERT-base on distribution-specific tasks while using between three and seven times fewer parameters and no pre-training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents INCRT, an incremental transformer that starts with a single attention head and dynamically adds or prunes heads during training driven by a single online-computable geometric quantity derived from the task's directional structure. It claims two theorems: homeostatic convergence, which guarantees the system reaches a finite configuration that is both minimal (no redundant heads) and sufficient (no uncaptured directional energy above threshold), and a compressed-sensing analogy providing a geometric upper bound on the number of heads as a function of the task's spectral complexity. Experiments on SARS-CoV-2 variant classification and SST-2 sentiment analysis report that predicted and observed head counts agree within 12%, with final models matching or exceeding BERT-base performance using 3-7 times fewer parameters and no pre-training.
Significance. If the theorems hold with a rigorously defined and stable geometric quantity, the work would offer a principled alternative to trial-and-error transformer design, directly addressing structural redundancy in attention heads and enabling task-specific capacity allocation without validation sets or hand-tuned schedules. The reported parameter efficiency and competitive performance on distribution-specific tasks would be a meaningful empirical contribution to dynamic architecture research.
major comments (3)
- [Theoretical Backbone (homeostatic convergence)] Homeostatic convergence theorem: The claim that the online geometric quantity always drives the system to a provably minimal and sufficient finite state assumes stability of directional-energy estimates under stochastic gradient updates. No analysis of variance, oscillation risk, or convergence rates under batch non-stationarity is provided, which is load-bearing for the theorem as small perturbations could lead to premature pruning or non-convergence.
- [INCRT Architecture Description] Growth/pruning mechanism: The exact definition of the 'geometric quantity derived from the task's directional structure' (including the directional energy threshold and its computation from current-batch estimates) is unspecified. This prevents verification that the stopping condition is parameter-free rather than a fitted threshold and directly affects both theorems and the circularity of the decision rule.
- [Experiments] Experimental validation: The 12% agreement between predicted and observed head counts is reported without error bars, number of runs, data-exclusion rules, or confidence intervals. This weakens support for the compressed-sensing bound and makes it impossible to assess whether the match is robust or task-specific.
minor comments (1)
- [Abstract] Abstract: The claim of 'no pre-training' would benefit from a brief clarification on whether baselines were trained from scratch or used standard pre-trained weights, to ensure fair comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and describe the revisions that will be incorporated to strengthen the theoretical and empirical components of the manuscript.
read point-by-point responses
-
Referee: Homeostatic convergence theorem: The claim that the online geometric quantity always drives the system to a provably minimal and sufficient finite state assumes stability of directional-energy estimates under stochastic gradient updates. No analysis of variance, oscillation risk, or convergence rates under batch non-stationarity is provided, which is load-bearing for the theorem as small perturbations could lead to premature pruning or non-convergence.
Authors: We agree that the manuscript currently lacks a formal analysis of the stability of the directional-energy estimates. In the revised version we will add a dedicated subsection that derives probabilistic bounds on the variance of the geometric quantity under SGD, discusses conditions under which oscillation or premature pruning is avoided, and provides a sketch of convergence rates under batch non-stationarity. These additions will make the load-bearing assumptions explicit and verifiable. revision: yes
-
Referee: Growth/pruning mechanism: The exact definition of the 'geometric quantity derived from the task's directional structure' (including the directional energy threshold and its computation from current-batch estimates) is unspecified. This prevents verification that the stopping condition is parameter-free rather than a fitted threshold and directly affects both theorems and the circularity of the decision rule.
Authors: We acknowledge that the current text presents the geometric quantity at a high level. The revised manuscript will contain the complete mathematical definition, the exact formula for computing directional energy from each batch, the derivation of the threshold from the task's spectral properties, and an explicit argument that the threshold is determined without fitting or validation data. This will eliminate any ambiguity regarding parameter-freeness and circularity. revision: yes
-
Referee: Experimental validation: The 12% agreement between predicted and observed head counts is reported without error bars, number of runs, data-exclusion rules, or confidence intervals. This weakens support for the compressed-sensing bound and makes it impossible to assess whether the match is robust or task-specific.
Authors: We will expand the experimental section to report results from at least five independent runs, include error bars and standard deviations, state the data-exclusion criteria, and provide confidence intervals around the reported agreement. Additional robustness checks across random seeds and task variants will be added to strengthen the empirical support for the compressed-sensing bound. revision: yes
Circularity Check
Homeostatic convergence theorem is self-definitional on the geometric quantity
specific steps
-
self definitional
[Abstract, paragraph describing the two theorems]
"Two theorems form the theoretical backbone. The first (homeostatic convergence) establishes that the system always reaches a finite stopping configuration that is simultaneously minimal (no redundant heads) and sufficient (no uncaptured directional energy above the threshold)."
The stopping configuration is defined as the point at which the geometric quantity indicates 'no uncaptured directional energy above the threshold' and 'no redundant heads'. The theorem therefore claims convergence to the exact state at which the algorithm's own add/prune rule triggers termination, without an independent demonstration that the quantity remains accurate and non-oscillatory under stochastic gradients.
full rationale
The paper's central theoretical claim is that a single online geometric quantity drives growth and pruning to a provably minimal-sufficient configuration. The homeostatic convergence theorem asserts exactly that the process reaches the state defined by that quantity's threshold conditions. Because the abstract provides no independent definition or stability proof for the quantity (only that it is 'derived from the task's directional structure'), the theorem reduces to the statement that the algorithm stops when its own rule says to stop. This is self-definitional rather than a non-trivial guarantee. The compressed-sensing bound and experimental match are downstream and do not remove the circularity at the foundation.
Axiom & Free-Parameter Ledger
free parameters (1)
- directional energy threshold
axioms (1)
- domain assumption The geometric quantity accurately reflects task directional structure without external validation
invented entities (1)
-
homeostatic convergence property
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Temporal Attention for Adaptive Control of Euler-Lagrange Systems with Unobservable Memory
A single-layer self-attention meta-controller for Euler-Lagrange systems with unobservable friction memory outperforms deeper Transformer baselines by 12-19 percentage points in tracking error for short and matched me...
Reference graph
Works this paper leans on
-
[1]
Blanchard, G
G. Blanchard, G. Lugosi, and N. Vayatis. On the rate of convergence of regularized boosting classifiers.Journal of Machine Learning Research, 4:861–894, 2007
2007
- [2]
-
[3]
B. Chen, Z. Liu, B. Peng, Z. Xu, J. L. Li, T. Dao, Z. Song, A. Shrivastava, and C. Re. Scatterbrain: Unifying sparse and low-rank attention. InAdvances in Neural Information Processing Systems (NeurIPS), volume 34, 2021
2021
-
[4]
Cirrincione
G. Cirrincione. Antisymmetric attention: The forgotten component of self-supervised pre-training.Submitted to Journal of Machine Learning Research, 2026
2026
-
[5]
Cirrincione, M
G. Cirrincione, M. Cirrincione, J. H´ erault, and S. Van Huffel. The MCA EXIN neuron for the minor component analysis.IEEE Transactions on Neural Networks, 21(1): 152–163, 2010
2010
-
[6]
L. Gong, D. He, Z. Li, T. Qin, L. Wang, and T.-Y. Liu. Efficient training of BERT by progressively stacking. InProceedings of ICML 2019, 2019. 21
2019
-
[7]
Jacot, F
A. Jacot, F. Gabriel, and C. Hongler. Neural tangent kernel: Convergence and generalization in neural networks. InAdvances in Neural Information Processing Systems (NeurIPS), volume 31, 2018
2018
-
[8]
H. Liu, K. Simonyan, and Y. Yang. DARTS: Differentiable architecture search. In Proceedings of ICLR 2019, 2019
2019
-
[9]
S. G. Mallat and Z. Zhang. Matching pursuits with time-frequency dictionaries.IEEE Transactions on Signal Processing, 41(12):3397–3415, 1993
1993
-
[10]
Michel, O
P. Michel, O. Levy, and G. Neubig. Are sixteen heads really better than one? In Advances in Neural Information Processing Systems (NeurIPS), volume 32, 2019
2019
-
[11]
Molchanov, A
P. Molchanov, A. Mallya, S. Tyree, I. Frosio, and J. Kautz. Importance estimation for neural network pruning. InProceedings of CVPR 2019, 2019
2019
-
[12]
E. Oja. Simplified neuron model as a principal component analyzer.Journal of Mathematical Biology, 15:267–273, 1982
1982
-
[13]
H. Pham, M. Y. Guan, B. Zoph, Q. V. Le, and J. Dean. Efficient neural architecture search via parameters sharing. InProceedings of ICML 2018, 2018
2018
-
[14]
Socher, A
R. Socher, A. Perelygin, J. Wu, J. Chuang, C. D. Manning, A. Ng, and C. Potts. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of EMNLP 2013, pages 1631–1642, 2013
2013
-
[15]
arXiv preprint arXiv:2406.15786 , year=
M. Sun et al. Not all attention heads are needed: Rethinking the Transformer architecture for efficient language modeling.arXiv preprint arXiv:2406.15786, 2024
-
[16]
J. A. Tropp. User-friendly tail bounds for sums of random matrices.Foundations of Computational Mathematics, 12(4):389–434, 2012
2012
-
[17]
Voita, D
E. Voita, D. Talbot, F. Moiseev, R. Sennrich, and I. Titov. Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. In Proceedings of ACL 2019, pages 5797–5808, 2019
2019
-
[18]
A. Wang, A. Singh, J. Michael, F. Hill, O. Levy, and S. R. Bowman. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In Proceedings of EMNLP 2018 Workshop BlackboxNLP, 2018
2018
-
[19]
S. Wang et al. Learning to grow: Dynamic architecture adaptation for neural networks. arXiv preprint arXiv:2302.12345, 2023
-
[20]
L. Xu. Least mean square error reconstruction principle for self-organizing neural-nets. Neural Networks, 6(5):627–648, 1993
1993
-
[21]
Zoph and Q
B. Zoph and Q. V. Le. Neural architecture search with reinforcement learning. In Proceedings of ICLR 2017, 2017. 22
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.