Recognition: unknown
SciPredict: Can LLMs Predict the Outcomes of Scientific Experiments in Natural Sciences?
Pith reviewed 2026-05-10 15:52 UTC · model grok-4.3
The pith
LLMs achieve 14-26% accuracy predicting real scientific experiment outcomes, similar to human experts at 20%, but cannot judge when their predictions are reliable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
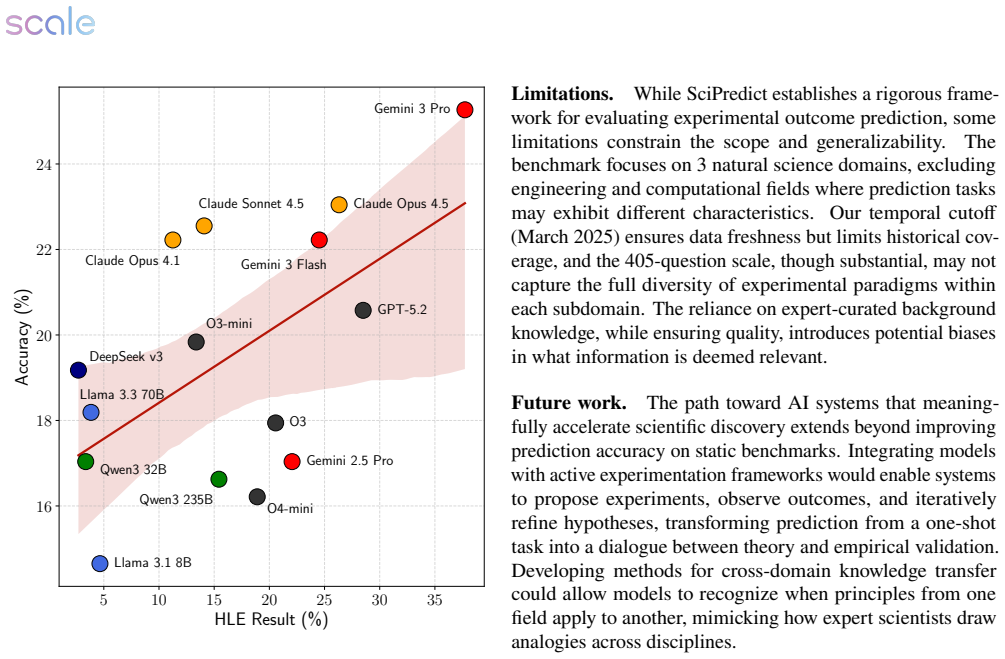
SciPredict reveals that LLMs achieve accuracies between 14% and 26% on predicting outcomes of 405 real scientific experiments across physics, biology, and chemistry, compared to human experts at approximately 20%. Although some advanced models surpass human performance, the overall level falls short of enabling reliable experimental guidance. Models do not distinguish reliable from unreliable predictions, maintaining about 20% accuracy irrespective of their expressed confidence or judgments on predictability. Human experts, however, show strong calibration, with accuracy increasing from 5% to 80% as they rate outcomes more predictable without physical tests. This demonstrates that superhuman
What carries the argument
The SciPredict benchmark of 405 tasks drawn directly from recent empirical papers in 33 specialized sub-fields, used to measure both raw prediction accuracy and calibration of expressed confidence.
If this is right
- AI systems cannot yet reliably select which experiments to run without physical validation.
- Raw predictive accuracy alone is insufficient; models must also improve at knowing when their output is trustworthy.
- Current prompting and training methods do not produce the kind of uncertainty awareness humans demonstrate.
- Benchmarks focused solely on knowledge recall miss the calibration failures that limit practical use in research.
Where Pith is reading between the lines
- A follow-up benchmark using only post-cutoff experiments would isolate whether models are retrieving memorized results or performing genuine forward prediction.
- Training objectives that reward accurate self-assessment of uncertainty could close the calibration gap observed between models and humans.
- The benchmark's structure, built from published studies, could be reused to track progress as new models are released.
Load-bearing premise
The 405 tasks fairly represent the difficulty of real experimental prediction without data leakage from model training data and that the human expert baseline supplies an unbiased comparison.
What would settle it
A test of the same models on experiments published after every model's training cutoff date, measuring whether accuracy remains below 30% or rises substantially.
Figures










read the original abstract
Accelerating scientific discovery requires the identification of which experiments would yield the best outcomes before committing resources to costly physical validation. While existing benchmarks evaluate LLMs on scientific knowledge and reasoning, their ability to predict experimental outcomes - a task where AI could significantly exceed human capabilities - remains largely underexplored. We introduce SciPredict, a benchmark comprising 405 tasks derived from recent empirical studies in 33 specialized sub-fields of physics, biology, and chemistry. SciPredict addresses two critical questions: (a) can LLMs predict the outcome of scientific experiments with sufficient accuracy? and (b) can such predictions be reliably used in the scientific research process? Evaluations reveal fundamental limitations on both fronts. Model accuracies are 14-26% and human expert performance is $\approx$20%. Although some frontier models exceed human performance model accuracy is still far below what would enable reliable experimental guidance. Even within the limited performance, models fail to distinguish reliable predictions from unreliable ones, achieving only $\approx$20% accuracy regardless of their confidence or whether they judge outcomes as predictable without physical experimentation. Human experts, in contrast, demonstrate strong calibration: their accuracy increases from $\approx$5% to $\approx$80% as they deem outcomes more predictable without conducting the experiment. SciPredict establishes a rigorous framework demonstrating that superhuman performance in experimental science requires not just better predictions, but better awareness of prediction reliability. For reproducibility all our data and code are provided at https://github.com/scaleapi/scipredict
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SciPredict, a benchmark of 405 tasks derived from recent empirical studies in 33 sub-fields of physics, biology, and chemistry. It evaluates whether LLMs can predict experimental outcomes, reporting accuracies of 14-26% for models versus approximately 20% for human experts. The work further examines calibration, showing that models maintain roughly 20% accuracy regardless of confidence level or self-assessed predictability, while human experts calibrate strongly (accuracy rising from ~5% to ~80% as predictability increases). Data and code are released for reproducibility.
Significance. If the benchmark construction and human-model comparison prove robust, the results would provide concrete evidence of current LLMs' limitations in experimental prediction and uncertainty awareness, underscoring that superhuman performance in science requires both accurate forecasts and reliable self-assessment of reliability. The public release of the 405 tasks and evaluation code is a clear strength that supports follow-on work.
major comments (3)
- [§3] §3 (Task Construction): The claim that the 405 tasks are free of data leakage from model training corpora is central to interpreting the 14-26% accuracies as genuine generalization rather than memorization, yet the manuscript provides no explicit verification procedure (e.g., n-gram overlap checks, date-cutoff analysis, or contamination audits against the evaluated models' training data). This directly affects the soundness of the central claim.
- [§4.3] §4.3 (Human Baseline): The human expert performance of ≈20% and the calibration curve (5% to 80%) are load-bearing for the contrast with models, but details on expert selection criteria, domain expertise matching to the 33 sub-fields, and prompt/information parity with the LLM setup are insufficient to rule out bias in the comparison.
- [§5] §5 (Results): The statement that 'some frontier models exceed human performance' requires accompanying statistical tests (e.g., McNemar or bootstrap confidence intervals on the 405-task set) to establish whether the small margins are significant or attributable to sampling variability.
minor comments (2)
- [Abstract] Abstract: The sentence 'Although some frontier models exceed human performance model accuracy is still far below...' is missing punctuation and should read 'performance, model accuracy is still far below...'.
- [Results] Figure 2 or equivalent calibration plot: Axis labels and legend should explicitly state the number of tasks per bin to allow readers to assess the reliability of the 5%-80% human calibration curve.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which has helped us identify areas to strengthen the manuscript. We address each major comment below and commit to revisions that enhance the rigor of our claims without altering the core findings.
read point-by-point responses
-
Referee: §3 (Task Construction): The claim that the 405 tasks are free of data leakage from model training corpora is central to interpreting the 14-26% accuracies as genuine generalization rather than memorization, yet the manuscript provides no explicit verification procedure (e.g., n-gram overlap checks, date-cutoff analysis, or contamination audits against the evaluated models' training data). This directly affects the soundness of the central claim.
Authors: We selected all 405 tasks exclusively from peer-reviewed papers published in 2023–2024, after the documented training cutoffs of the evaluated models (e.g., GPT-4, Claude 3, and Llama-3 variants). While this temporal filtering substantially reduces the risk of leakage, we agree that an explicit verification procedure strengthens the interpretation. In the revised manuscript we will add a dedicated subsection in §3 that reports (i) n-gram overlap analysis against publicly available pre-training corpora proxies and (ii) a date-cutoff audit confirming zero overlap with model training windows. We will also note the practical limits of full contamination audits given proprietary training data. revision: yes
-
Referee: §4.3 (Human Baseline): The human expert performance of ≈20% and the calibration curve (5% to 80%) are load-bearing for the contrast with models, but details on expert selection criteria, domain expertise matching to the 33 sub-fields, and prompt/information parity with the LLM setup are insufficient to rule out bias in the comparison.
Authors: We concur that greater transparency is required. The revised §4.3 will explicitly state: (1) recruitment criteria (PhD-level researchers and postdocs with at least two first-author publications in the target sub-field), (2) domain-matching protocol (experts were assigned tasks only within their documented publication areas across the 33 sub-fields), and (3) information parity (humans received identical task statements, background paragraphs, and output format instructions as the LLMs, with no additional literature access). These additions will allow readers to assess potential bias directly. revision: yes
-
Referee: §5 (Results): The statement that 'some frontier models exceed human performance' requires accompanying statistical tests (e.g., McNemar or bootstrap confidence intervals on the 405-task set) to establish whether the small margins are significant or attributable to sampling variability.
Authors: We accept this recommendation. The revised §5 will report 95% bootstrap confidence intervals for all accuracy figures and will include McNemar’s test (with continuity correction) for paired comparisons between each frontier model and the human baseline across the 405 tasks. These tests will quantify whether observed differences (e.g., 26% vs. 20%) are statistically distinguishable from sampling variability. revision: yes
Circularity Check
No significant circularity; empirical benchmark with external validation
full rationale
The paper introduces SciPredict as an empirical benchmark consisting of 405 tasks drawn from recent published studies across 33 sub-fields. Model and human accuracies are measured directly against the actual experimental outcomes reported in those studies, with no mathematical derivation, equations, fitted parameters, or ansatz involved. Human expert baselines and model prompting setups are compared to these external ground-truth results rather than reducing to any internal definition or self-citation chain. No load-bearing steps rely on self-citations for uniqueness theorems or renamings of known results. The evaluation is self-contained against external benchmarks (real study outcomes and independent human experts), satisfying the criteria for a non-circular empirical assessment.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abdel-Rehim, H
A. Abdel-Rehim, H. Zenil, O. Orhobor, M. Fisher, R. J. Collins, E. Bourne, G. W. Fearnley, E. Tate, H. X. Smith, L. N. Soldatova, et al. Scientific hypothesis generation bylargelanguagemodels: laboratoryvalidationinbreast cancer treatment.Journal of the Royal Society Interface, 22(227):20240674, 2025
2025
-
[2]
Ali-Dib and K
M. Ali-Dib and K. Menou. Physics simulation capabili- ties of llms.Physica Scripta, 99(11):116003, 2024
2024
-
[3]
Amayuelas, K
A. Amayuelas, K. Wong, L. Pan, W. Chen, and W. Y. Wang. Knowledge of knowledge: Exploring known- unknowns uncertainty with large language models. In Findings of the Association for Computational Linguis- tics: ACL 2024, pages 6416–6432, 2024
2024
-
[4]
R. K. Arora, J. Wei, R. S. Hicks, P. Bowman, J. Quiñonero-Candela, F. Tsimpourlas, M. Sharman, 13 M.Shah,A.Vallone,A.Beutel,etal. Healthbench: Eval- uating large language models towards improved human health.arXiv preprint arXiv:2505.08775, 2025
work page internal anchor Pith review arXiv 2025
- [5]
-
[6]
Replicating a high-impact scientific publication using systems of large language models.bioRxiv, pages 2024– 04, 2024
D.Bersenev,A.Yachie-Kinoshita,andS.K.Palaniappan. Replicating a high-impact scientific publication using systems of large language models.bioRxiv, pages 2024– 04, 2024
2024
-
[7]
Brunnsåker, A
D. Brunnsåker, A. H. Gower, P. Naval, E. Y. Bjurström, F.Kronström,I.A.Tiukova,andR.D.King. Self-driven biological discovery through automated hypothesis gen- eration and experimental validation.bioRxiv, pages 2025–06, 2025
2025
-
[8]
J.S.Chan,N.Chowdhury,O.Jaffe,J.Aung,D.Sherburn, E. Mays, G. Starace, K. Liu, L. Maksin, T. Patwardhan, L.Weng,andA.Mądry. Mle-bench: Evaluatingmachine learning agents on machine learning engineering, 2025. URLhttps://arxiv.org/abs/2410.07095
work page Pith review arXiv 2025
-
[9]
N. E. Chayen. Turning protein crystallisation from an art into a science.Current opinion in structural biology, 14 5:577–83, 2004. URLhttps://api.semanticscholar. org/CorpusID:26208535
2004
- [10]
- [11]
-
[12]
Z. Cui, N. Li, and H. Zhou. Can ai replace human subjects? a large-scale replication of psychological experiments with llms.A Large-Scale Replication of PsychologicalExperimentswithLLMs(August25,2024), 2024
2024
- [13]
-
[14]
N. Guha, J. Nyarko, D. E. Ho, C. Ré, A. Chilton, A. Narayana, A. Chohlas-Wood, A. Peters, B. Waldon, D. N. Rockmore, D. Zambrano, D. Talisman, E. Hoque, F.Surani,F.Fagan,G.Sarfaty,G.M.Dickinson,H.Porat, J.Hegland,J.Wu,J.Nudell,J.Niklaus,J.Nay,J.H.Choi, K.Tobia,M.Hagan,M.Ma,M.Livermore,N.Rasumov- Rahe,N.Holzenberger,N.Kolt,P.Henderson,S.Rehaag, S. Goel, S....
- [15]
-
[16]
C. Guo, G. Pleiss, Y. Sun, and K. Q. Weinberger. On calibration of modern neural networks. In D. Pre- cup and Y. W. Teh, editors,Proceedings of the 34th International Conference on Machine Learning, vol- ume 70 ofProceedings of Machine Learning Research, pages 1321–1330. PMLR, 06–11 Aug 2017. URL https://proceedings.mlr.press/v70/guo17a.html
2017
-
[17]
A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks
D. Hendrycks and K. Gimpel. A baseline for detecting misclassified and out-of-distribution examples in neural networks.arXiv preprint arXiv:1610.02136, 2016
work page internal anchor Pith review arXiv 2016
- [18]
-
[19]
Q. Huang, J. Vora, P. Liang, and J. Leskovec. Mlagent- bench: Evaluating language agents on machine learning experimentation, 2024. URLhttps://arxiv.org/abs/ 2310.03302
-
[20]
Jiang, J
Z. Jiang, J. Araki, H. Ding, and G. Neubig. How can we know when language models know? on the calibration oflanguagemodelsforquestionanswering.Transactions of the Association for Computational Linguistics, 9:962– 977, 2021
2021
- [21]
-
[22]
Q. Jin, B. Dhingra, Z. Liu, W. W. Cohen, and X. Lu. Pubmedqa: A dataset for biomedical research question answering, 2019. URLhttps://arxiv.org/abs/1909. 06146
2019
- [23]
-
[24]
Y.Ke, K.George, K.Pandya, D.Blumenthal, M.Sprang, G. Großmann, S. Vollmer, and D. A. Selby. Biodisco: Multi-agent hypothesis generation with dual-mode evi- dence, iterative feedback and temporal evaluation.arXiv preprint arXiv:2508.01285, 2025
- [25]
-
[26]
J.M.Laurent,J.D.Janizek,M.Ruzo,M.M.Hinks,M.J. Hammerling, S. Narayanan, M. Ponnapati, A. D. White, and S. G. Rodriques. Lab-bench: Measuring capabilities of language models for biology research, 2024. URL https://arxiv.org/abs/2407.10362. 14
-
[27]
M. Li, S. Torres-Garcia, S. Halder, P. Kuppa, S. O’Brien, V. Sharma, K. Zhu, and S. Dev. Frontierscience bench: Evaluatingairesearchcapabilitiesinllms.InProceedings of the 1st Workshop for Research on Agent Language Models (REALM 2025), pages 428–453, 2025
2025
- [28]
- [29]
- [30]
- [31]
-
[32]
Medmcqa : A large-scale multi-subject multi-choice dataset for medical domain question answering
A.Pal,L.K.Umapathi,andM.Sankarasubbu. Medmcqa : A large-scale multi-subject multi-choice dataset for medical domain question answering, 2022. URLhttps: //arxiv.org/abs/2203.14371
-
[33]
Stronginference: Certainsystematicmethods of scientific thinking may produce much more rapid progress than others.science, 146(3642):347–353, 1964
J.R.Platt. Stronginference: Certainsystematicmethods of scientific thinking may produce much more rapid progress than others.science, 146(3642):347–353, 1964
1964
-
[34]
D. Saynova, K. Hansson, B. Bruinsma, A. Fredén, and M. Johansson. Identifying non-replicable social sci- ence studies with language models.arXiv preprint arXiv:2503.10671, 2025
-
[35]
Shojaee, K
P. Shojaee, K. Meidani, S. Gupta, A. B. Farimani, and C. K. Reddy. Llm-sr: Scientific equation discovery via programming with large language models. InThe Thirteenth International Conference on Learning Repre- sentations
-
[36]
Shorinwa, Z
O. Shorinwa, Z. Mei, J. Lidard, A. Z. Ren, and A. Ma- jumdar. A survey on uncertainty quantification of large language models: Taxonomy, open research challenges, and future directions.ACM Computing Surveys, 2025
2025
-
[37]
CFDLLMBench: A Benchmark Suite for Evaluating Large Language Models in Computational Fluid Dynamics
N. Somasekharan, L. Yue, Y. Cao, W. Li, P. Emami, P. S. Bhargav, A. Acharya, X. Xie, and S. Pan. Cfd-llmbench: A benchmark suite for evaluating large language mod- els in computational fluid dynamics.arXiv preprint arXiv:2509.20374, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Starace, O
G. Starace, O. Jaffe, D. Sherburn, J. Aung, J. S. Chan, L. Maksin, R. Dias, E. Mays, B. Kinsella, W. Thompson, et al. Paperbench: Evaluating ai’s ability to replicate ai research. InForty-second International Conference on Machine Learning
-
[39]
Galactica: A Large Language Model for Science
R. Taylor, M. Kardas, G. Cucurull, T. Scialom, A. S. Hartshorn, E. Saravia, A. Poulton, V. Kerkez, and R. Stojnic. Galactica: A large language model for science.ArXiv, abs/2211.09085, 2022. URL https: //api.semanticscholar.org/CorpusID:253553203
work page internal anchor Pith review arXiv 2022
-
[40]
G. Tom, S. P. Schmid, S. G. Baird, Y. Cao, K. Darvish, H. Hao, S. Lo, S. Pablo-García, E. M. Rajaonson, M. Skreta, et al. Self-driving laboratories for chem- istry and materials science.Chemical Reviews, 124(16): 9633–9732, 2024
2024
-
[41]
Alvers, M
G.Tsatsaronis,M.Schroeder,G.Paliouras,Y.Almirantis, I.Androutsopoulos,E.Gaussier,P.Gallinari,T.Artieres, M. Alvers, M. Zschunke, and A.-C. Ngonga Ngomo. BioASQ:Achallengeonlarge-scalebiomedicalsemantic indexing and Question Answering. InProceedings of AAAI Information Retrieval and Knowledge Discovery in Biomedical Text, 2012
2012
-
[42]
M. Wang, R. Lin, K. Hu, J. Jiao, N. Chowdhury, E. Chang, and T. Patwardhan. Frontierscience: Evaluating AI’s ability to perform expert-level scientific tasks. https://cdn.openai.com/ pdf/2fcd284c-b468-4c21-8ee0-7a783933efcc/ frontierscience-paper.pdf, Dec. 2025. Technical report. Accessed: 2026-01-26
2025
- [43]
-
[44]
Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs
M. Xiong, Z. Hu, X. Lu, Y. Li, J. Fu, J. He, and B. Hooi. Can llms express their uncertainty? an empirical eval- uation of confidence elicitation in llms.arXiv preprint arXiv:2306.13063, 2023
work page internal anchor Pith review arXiv 2023
- [45]
- [46]
-
[47]
On Verbalized Confidence Scores for LLMs
D. Yang, Y.-H. H. Tsai, and M. Yamada. On ver- balized confidence scores for llms.arXiv preprint arXiv:2412.14737, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Z. Yang, W. Liu, B. Gao, T. Xie, Y. Li, W. Ouyang, S. Poria, E. Cambria, and D. Zhou. Large language models for rediscovering unseen chemistry scientific hypotheses. In2nd AI4Research Workshop: Towards a Knowledge-groundedScientificResearchLifecycle,2025
2025
- [49]
- [50]
-
[51]
Zhang, J
X. Zhang, J. Wu, Z. He, X. Liu, and Y. Su. Medical exam question answering with large-scale reading com- prehension, 2018. URLhttps://arxiv.org/abs/1802. 10279
2018
- [52]
-
[53]
AutoReproduce: Automatic AI Experiment Reproduction with Paper Lineage
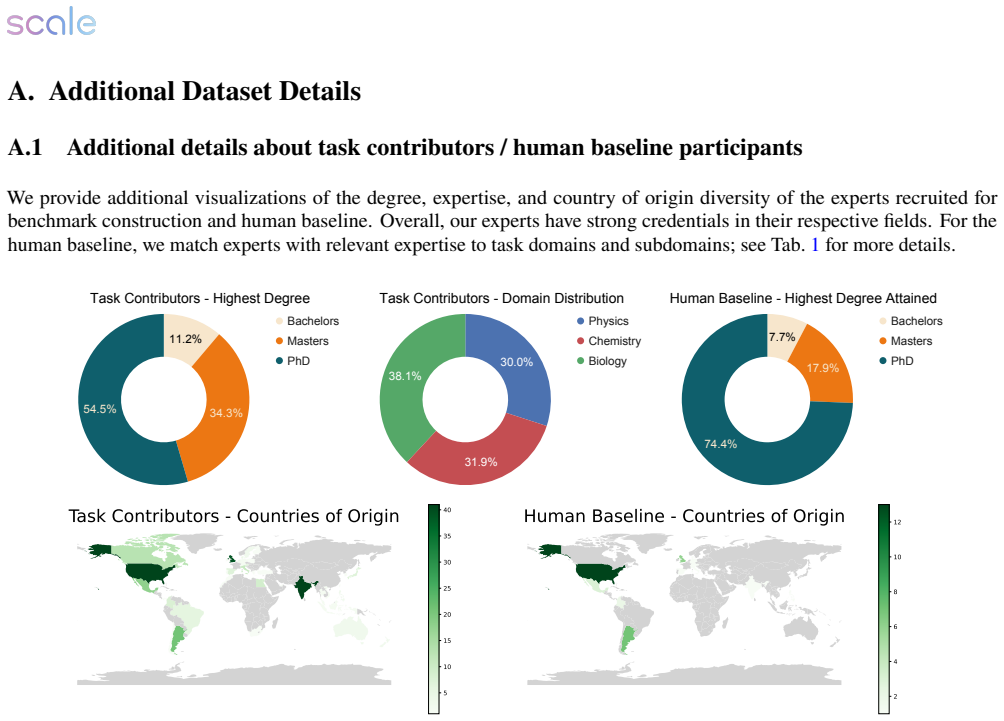
X. Zhao, Z. Sang, Y. Li, Q. Shi, W. Zhao, S. Wang, D. Zhang, X. Han, Z. Liu, and M. Sun. Autoreproduce: Automaticaiexperimentreproductionwithpaperlineage. arXiv preprint arXiv:2505.20662, 2025. 16 A. Additional Dataset Details A.1 Additional details about task contributors / human baseline participants We provide additional visualizations of the degree, e...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1101/2025.09.05.674457v1.full 2025
-
[54]
This is the primary error if the answer, regardless of its correctness, is for the wrong question
Comprehension & Scope Errors: The answer fails because it fundamentally misunderstands the user’s question or violates its core constraints. This is the primary error if the answer, regardless of its correctness, is for the wrong question
-
[55]
It omits, fabricates, or directly contradicts facts that are clearly stated
Factual & Extraction Errors: The answer fails because it incorrectly handles explicit information from the provided ‘experimental_setup‘, ‘measurements_taken‘, or ‘background_knowledge‘. It omits, fabricates, or directly contradicts facts that are clearly stated
-
[56]
The connections between evidence and conclusion are invalid
Logical & Reasoning Flaws: The answer fails because the argument is logically unsound, even if the individual facts cited are correct. The connections between evidence and conclusion are invalid
-
[57]
It may be factually correct but is presented with false certainty or violates a core scientific principle
Deficiencies in Scientific Rigor: The answer fails because it lacks the necessary nuance and rigor expected in scientific communication. It may be factually correct but is presented with false certainty or violates a core scientific principle
-
[58]
Detailed Analysis Flags: First, choose a PRIMARY ERROR CATEGORY from the five main categories above that best explains WHY the ‘suggested_answer‘ is flawed or incorrect
Formatting & Mechanical Bug: The answer fails due to a non-substantive formatting error. Detailed Analysis Flags: First, choose a PRIMARY ERROR CATEGORY from the five main categories above that best explains WHY the ‘suggested_answer‘ is flawed or incorrect. For this choice of the primary error category, provide a 39 comprehensive justification (4-5 sente...
-
[59]
- Definition: Whether the ‘suggested_answer‘ addresses a fundamentally different question than the one posed
Comprehension & Scope Errors - ‘flag_task_misinterpretation‘: - Evidence Source: ‘question‘, ‘suggested_answer‘. - Definition: Whether the ‘suggested_answer‘ addresses a fundamentally different question than the one posed. - Prerequisite: None. - ‘YES‘: The answer’s core purpose is different from the question’s intent or it addresses a different scientifi...
-
[60]
- Definition: Whether the ‘suggested_answer‘ fails to extract or reports as "missing" a REQUIRED piece of data explicitly present in the provided materials
Factual & Extraction Errors - ‘flag_information_omission‘: - Evidence Source: ‘experimental_setup‘, ‘measurements_taken‘, ‘background_knowledge‘, ‘suggested_ answer‘. - Definition: Whether the ‘suggested_answer‘ fails to extract or reports as "missing" a REQUIRED piece of data explicitly present in the provided materials. - Prerequisite: The information i...
-
[61]
- Definition: Whether the justification restates the conclusion without providing independent evidence
Logical & Reasoning Flaws - ‘flag_tautological_reasoning‘: - Evidence Source: ‘suggested_answer‘. - Definition: Whether the justification restates the conclusion without providing independent evidence. - Prerequisite: The ‘suggested_answer‘ provides a justification or reasoning. - ‘YES‘: The reasoning is circular, using the conclusion as its own evidence....
-
[62]
- Definition: Whether the ‘suggested_answer‘ presents a probabilistic, correlational, or uncertain outcome as a definitive fact
Deficiencies in Scientific Rigor - ‘flag_false_certainty‘: - Evidence Source: ‘experimental_setup‘, ‘measurements_taken‘, ‘background_knowledge‘, ‘suggested_ answer‘. - Definition: Whether the ‘suggested_answer‘ presents a probabilistic, correlational, or uncertain outcome as a definitive fact. - Prerequisite: The outcome described in the provided materia...
-
[63]
"" {experimental_setup}
Formatting & Mechanical Bugs - ‘flag_incorrect_answer_reference‘: - Evidence Source: ‘question‘, ‘suggested_answer‘, ‘ground_truth_answer‘. - Definition: Whether the provided justification or reasoning identifies the correct answer option(s), BUT then a different option letter is given as the final answer. - Prerequisite: The ‘question‘ IS a multiple-choi...
-
[64]
Use the provided ‘experimental_setup‘ and ‘measurements_taken‘ to inform your understanding
First, carefully read and understand the scientific context (domain, field) and the specific ‘question‘. Use the provided ‘experimental_setup‘ and ‘measurements_taken‘ to inform your understanding
-
[65]
Compare the ‘suggested_answer‘ with the ‘ground_truth_answer‘ and reason about the overall correctness and completeness of the ‘suggested_answer‘
-
[66]
true" or
For EACH criterion (INDEPENDENTLY) provided in the ‘rubric_criteria‘ list (could be 1 or more criterion items), you must meticulously assess if the ‘suggested_answer‘ satisfies it ("true" or "false"). The ground truth answer should be used as the reference as the overall correct answer to the ‘question‘. Provide the output in the corresponding ‘_satisfied‘ fields
-
[67]
Do not introduce external knowledge or make assumptions beyond the provided text
Your judgment must be objective. Do not introduce external knowledge or make assumptions beyond the provided text
-
[68]
true"/"false
Provide a concise yet clear justification for EACH criterion’s determined satisfaction status ("true"/"false") in the corresponding‘_reasoning‘ field. Inputs: - ‘domain‘: {domain} 45 - ‘field‘: {field} - ‘rubric_criteria‘: Provided below as a list. Evaluation Criteria: {rubric_criteria_lines} Output Format: You MUST provide your evaluation in a strict JSO...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.