Recognition: unknown
RCBSF: A Multi-Agent Framework for Automated Contract Revision via Stackelberg Game
Pith reviewed 2026-05-10 15:43 UTC · model grok-4.3
The pith
RCBSF frames contract revision as a Stackelberg game where risk budgets guide LLM agents to higher-utility equilibria.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
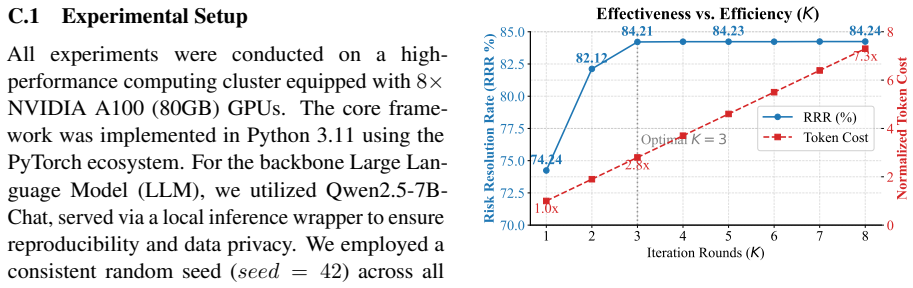
RCBSF formulates contract revision as a non-cooperative Stackelberg game in which a Global Prescriptive Agent imposes risk budgets on a Constrained Revision Agent and a Local Verification Agent. The bilevel formulation converges to an equilibrium yielding strictly superior utility over unguided configurations. On a unified benchmark it reaches state-of-the-art performance with an average Risk Resolution Rate of 84.21 percent and improved token efficiency.
What carries the argument
The Risk-Constrained Bilevel Stackelberg Framework (RCBSF), which organizes three LLM agents into a leader-follower hierarchy to enforce risk budgets and drive iterative contract optimization toward equilibrium.
Where Pith is reading between the lines
- The same hierarchical risk-budget structure could be tested on other constrained generation tasks such as regulatory policy drafting or medical summary editing.
- If the equilibrium property holds across models, the approach might reduce the amount of human post-editing required for legal documents.
- Dynamic adjustment of risk budgets based on document length or complexity offers a natural next experiment to broaden applicability.
Load-bearing premise
LLM-based agents can faithfully implement the Stackelberg leader-follower roles and respect imposed risk budgets without introducing new hallucinations or violating non-cooperative dynamics.
What would settle it
A head-to-head benchmark run in which the RCBSF risk resolution rate falls below 84.21 percent or total utility does not exceed the unguided LLM baseline would disprove the superiority and convergence claims.
Figures
















read the original abstract
Despite the widespread adoption of Large Language Models (LLMs) in Legal AI, their utility for automated contract revision remains impeded by hallucinated safety and a lack of rigorous behavioral constraints. To address these limitations, we propose the Risk-Constrained Bilevel Stackelberg Framework (RCBSF), which formulates revision as a non-cooperative Stackelberg game. RCBSF establishes a hierarchical Leader Follower structure where a Global Prescriptive Agent (GPA) imposes risk budgets upon a follower system constituted by a Constrained Revision Agent (CRA) and a Local Verification Agent (LVA) to iteratively optimize output. We provide theoretical guarantees that this bilevel formulation converges to an equilibrium yielding strictly superior utility over unguided configurations. Empirical validation on a unified benchmark demonstrates that RCBSF achieves state-of-the-art performance, surpassing iterative baselines with an average Risk Resolution Rate (RRR) of 84.21\% while enhancing token efficiency. Our code is available at https://github.com/xjiacs/RCBSF .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Risk-Constrained Bilevel Stackelberg Framework (RCBSF) for automated contract revision with LLMs. It models revision as a non-cooperative Stackelberg game in which a Global Prescriptive Agent (GPA) acts as leader imposing risk budgets on follower agents (Constrained Revision Agent and Local Verification Agent). The authors assert theoretical convergence guarantees to an equilibrium with strictly superior utility, and report empirical results on a unified benchmark showing 84.21% average Risk Resolution Rate (RRR) while improving token efficiency over iterative baselines.
Significance. If the claimed convergence can be rigorously shown under the stochastic LLM setting and the empirical gains are shown to be robust across datasets and baselines, the work would offer a concrete mechanism for injecting behavioral constraints into multi-agent LLM systems for high-stakes legal tasks. The bilevel formulation and explicit risk-budget mechanism are novel in the contract-revision literature and could generalize to other constrained generation domains.
major comments (2)
- [§4] §4 (Theoretical Analysis): The stated convergence guarantee for the bilevel Stackelberg game assumes well-defined continuous strategy sets, convex payoffs, and exact rational best-response computation. The implementation in §3 replaces these with prompt-driven LLM calls whose outputs are discrete and stochastic; no argument is given showing that the generated revisions remain inside the imposed risk budgets or that the followers follow the prescribed non-cooperative protocol. This gap directly affects the central claim of strictly superior equilibrium utility.
- [§5] §5 (Experiments): The reported 84.21% RRR is presented as state-of-the-art, yet the section provides no definition of the RRR metric, no error bars, no statistical significance tests against the iterative baselines, and no ablation isolating the contribution of the Stackelberg risk-budget mechanism versus simple prompting. Without these, the superiority claim cannot be evaluated.
minor comments (2)
- [Abstract] Abstract: The RRR metric and the precise meaning of 'risk budgets' are not defined, forcing the reader to consult the main text to interpret the headline 84.21% figure.
- [§3] §3 (Framework): The roles of CRA and LVA are described at a high level; a concrete example of a single revision round showing the exact prompts, risk-budget encoding, and verification step would clarify how the game is realized.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing the strongest honest defense of the manuscript while acknowledging where revisions are needed to strengthen the work.
read point-by-point responses
-
Referee: §4 (Theoretical Analysis): The stated convergence guarantee for the bilevel Stackelberg game assumes well-defined continuous strategy sets, convex payoffs, and exact rational best-response computation. The implementation in §3 replaces these with prompt-driven LLM calls whose outputs are discrete and stochastic; no argument is given showing that the generated revisions remain inside the imposed risk budgets or that the followers follow the prescribed non-cooperative protocol. This gap directly affects the central claim of strictly superior equilibrium utility.
Authors: We acknowledge the gap between the idealized assumptions in the theoretical analysis (§4) and the stochastic, discrete nature of LLM-based implementation (§3). The bilevel Stackelberg model is intended as a principled abstraction to guide the design of risk-constrained prompting, not as an exact description of LLM behavior. Prompts for the CRA and LVA are explicitly engineered to respect GPA-imposed risk budgets and to approximate best-response dynamics. In the revised manuscript we will add a dedicated subsection in §4 discussing the approximation gap, including (i) how risk-budget enforcement is operationalized via prompt constraints and (ii) empirical measurements of budget adherence across runs. We will also soften the wording of the convergence claim to reflect that the framework converges to a superior equilibrium under the modeled protocol, with practical LLM realizations providing an approximation whose quality is validated empirically. This addresses the concern without misrepresenting the current theoretical scope. revision: partial
-
Referee: §5 (Experiments): The reported 84.21% RRR is presented as state-of-the-art, yet the section provides no definition of the RRR metric, no error bars, no statistical significance tests against the iterative baselines, and no ablation isolating the contribution of the Stackelberg risk-budget mechanism versus simple prompting. Without these, the superiority claim cannot be evaluated.
Authors: We agree that the experimental presentation is incomplete and that these elements are required for rigorous evaluation. The Risk Resolution Rate (RRR) is defined as the fraction of contract risks flagged by the LVA that are successfully eliminated or mitigated in the final revised contract. In the revised manuscript we will (1) insert the formal definition of RRR at the beginning of §5, (2) report means and standard deviations over five independent runs with different random seeds, (3) add paired statistical tests (Wilcoxon signed-rank) against each iterative baseline, and (4) include an ablation that replaces the bilevel Stackelberg structure with a flat multi-agent prompting baseline that uses identical risk-budget language but lacks the leader-follower hierarchy. These additions will allow direct assessment of the contribution of the proposed mechanism. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper claims theoretical convergence guarantees for its bilevel Stackelberg formulation (GPA as leader with risk budgets on CRA/LVA followers) to an equilibrium with strictly superior utility. No equations, fitted parameters, or self-citations are visible in the abstract or context that would reduce this claim to a tautology or input by construction. The superiority assertion is framed as following from the game structure itself rather than from any renaming, ansatz smuggling, or self-referential definition. Empirical RRR results are presented separately and do not feed back into the theoretical claim. The derivation chain is therefore self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents can be made to respect externally imposed risk budgets without introducing new hallucinations
invented entities (3)
-
Global Prescriptive Agent (GPA)
no independent evidence
-
Constrained Revision Agent (CRA)
no independent evidence
-
Local Verification Agent (LVA)
no independent evidence
Forward citations
Cited by 2 Pith papers
-
Learning to Control Summaries with Score Ranking
A score-ranking loss enables controllable summarization by aligning outputs to evaluation scores, matching SOTA performance with dimension-specific control on LLaMA, Qwen, and Mistral.
-
FACT-E: Causality-Inspired Evaluation for Trustworthy Chain-of-Thought Reasoning
FACT-E uses controlled perturbations as an instrumental signal to measure intra-chain faithfulness in CoT reasoning and combines it with answer consistency to select trustworthy trajectories.
Reference graph
Works this paper leans on
-
[1]
Curran Associates, Inc. Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. 2023. Camel: Communicative agents for "mind" exploration of large language model society. InAdvances in Neural Information Processing Systems, volume 36, pages 51991–52008. Curran Associates, Inc. Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan,...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Disc-lawllm: Fine-tuning large language models for intelligent legal services,
Corrective retrieval augmented generation. Xiaoxian Yang, Zhifeng Wang, Qi Wang, Ke Wei, Kaiqi Zhang, and Jiangang Shi. 2024. Large language models for automated q&a involving legal docu- ments: a survey on algorithms, frameworks and ap- plications.International Journal of Web Information Systems, 20(4):413–435. Shengbin Yue, Wei Chen, Siyuan Wang, Bi...
-
[3]
Input Ingestion Raw PDF/TXT text headers are ingested (Hraw)
-
[4]
b) Strip numbering artifacts
Noise Reduction (Regex) Apply cleaning functionf clean(Hraw): a) Remove file extensions (‘.pdf‘, ‘.docx‘). b) Strip numbering artifacts . c) Normalize whitespace to single space
-
[5]
license" AND
Keyword Mapping (Canonicalization) Map headers to Ctarget ∈ C using hierarchical key- word matching: a)IF "license" AND "software" → Software Li- cense b)IF "consulting" OR "service" → Service Agree- ment c)IF"confidential" OR "nds"→NDA
-
[6]
Figure 6: The automated classification logic used in Stage 0 to standardize noisy raw file headers into canon- ical legal categories
Output Structured pair:(Category_ID, Clean_Header). Figure 6: The automated classification logic used in Stage 0 to standardize noisy raw file headers into canon- ical legal categories. A.2.2 Template Standardization (Stage 2) Following classification, the raw contract text un- dergoes a standardization process to remove iden- tifiers and unify structure....
-
[7]
Structural Normalization:Organize the output into these exact sections: • Definitions • Scope of Services • Fees and Payment • IP Ownership • Confidentiality & Data Protection • Indemnification & Liability • Term & Termination
-
[8]
• Replace specific dates with[Effective Date]
PII Anonymization (Strict): • Replace entity names with [Party A] / [Party B]. • Replace specific dates with[Effective Date]. • Replace monetary values with[Amount]
-
[9]
Risk-Mitigation
Formatting:OutputPLAIN TEXT ONLY. Do not use Markdown bolding or code blocks. Keep length≤1500words. Figure 7: The instruction set for LLM used to gener- ate standardized, anonymized legal templates from raw source text. A.2.3 Risk Enrichment (Stage 3) To facilitate the evaluation of risk detection mod- els, the standardized templates are processed by a n...
-
[10]
B Mathematical Proofs and Derivations In this appendix, we provide the rigorous measure- theoretic foundations and proofs for the theorems presented in Section 2
Carve out exceptions for gross negligence." } ] } Figure 8: The adversarial prompt for LLM, designed to generate the standard truth risk dataset used for calcu- lating the Risk Resolution Rate (RRR). B Mathematical Proofs and Derivations In this appendix, we provide the rigorous measure- theoretic foundations and proofs for the theorems presented in Secti...
-
[11]
Since the budget B >0 , we have ∅ ∈ H B
Inclusion Property:The unguided genera- tion corresponds to the null instruction strat- egy h∅ =∅ . Since the budget B >0 , we have ∅ ∈ H B
-
[12]
Therefore: VSE = sup h∈HB JL(Ψ(h),h) ≥J L(Ψ(∅),∅) =V N E (9)
Global Optimality:The Stackelberg leader maximizes over the entire set HB. Therefore: VSE = sup h∈HB JL(Ψ(h),h) ≥J L(Ψ(∅),∅) =V N E (9)
-
[13]
resolved
Strict Inequality Condition:Let R(x) =P wrδ(r,x) be the risk potential. In the un- guided case, the LLM generates xN E by sam- pling from P(x|∅) . Due to misalignment, there exists a risk rk such that δ(rk,x N E)> ϵ. The GPA constructs a specific hinthk contain- ing theEvidence ek andSuggestion sk. This introduces a forcing term in the Follower’s objectiv...
-
[14]
For instance, with LawLLM-7B, the Rigor score improves from 65.81 (Standard) to 79.81 (RCBSF)
Rigor is the primary beneficiary:Across all backbones, theRigormetric sees the most significant improvement. For instance, with LawLLM-7B, the Rigor score improves from 65.81 (Standard) to 79.81 (RCBSF). This log- ical enhancement is visually striking in Fig- ure 13, where the Rigor columns transition from dark green (worst) in baseline meth- ods to deep ...
-
[15]
The heatmap corroborates this stability, display- ing a consistent high-intensity color band for RCBSF across all model groups compared to the patchy performance of baselines
Stability across Backbones:Even for weaker backbones like LexiLaw-6B, RCBSF boosts the average quality from 60.40 to 72.30. The heatmap corroborates this stability, display- ing a consistent high-intensity color band for RCBSF across all model groups compared to the patchy performance of baselines. This sug- gests that the Stackelberg game mechanism is mo...
-
[16]
As illustrated by the darkest ma- genta blocks in Figure 13, this configuration significantly outperforms the RAG baseline (79.81) and approaches expert human levels (>90)
Peak Performance:The strongest config- uration, QW-7B-Chat + RCBSF, achieves state-of-the-art results with an average CQ of 86.87. As illustrated by the darkest ma- genta blocks in Figure 13, this configuration significantly outperforms the RAG baseline (79.81) and approaches expert human levels (>90). E.2 Ablation Study Breakdown To understand the contri...
-
[17]
Hallucination Rate (HR):The CRA modifies a clause that was NOT risky
-
[18]
Fix Failure Rate (FFR):The CRA attempts to fix a risk but fails to resolve it substantively. Analysis.As shown in Table 6, the results of the component-wise ablation study yield several key observations regarding the contribution of each instruction dimension: 18 Dimension High Quality (80–100) 90–100: Excellent; 80–89: Good Borderline (60–79) 70–79: Abov...
-
[19]
blanket indemnity
Input:The original text contains a "blanket indemnity" clause exposing the provider to unlimited risk
-
[20]
in- demnify... from any and all claims
Leader Analysis:The LV A identifies this as aCategory Arisk (Q2=A). It outputs a structured tuple specifying theEvidence("in- demnify... from any and all claims") and a concreteSuggestion("Insert a liability cap"). 3.Revision Process: • Revision #1:The CRA softens the lan- guage but forgets the specific cap. • Inner Audit:The LV A flags that the "fi- nanc...
-
[21]
Global Prescription (Outer Loop):The Global Prescriptive Agent (GPA)decom- poses the contract text, extracting a 5- dimensional constraint vector for each of the three identified risks
-
[22]
Priority: Reassign Deliv- erable ownership to Client
Execution & Audit (Inner Loop):The Fol- lower system (CRA & LV A) engages in a 3- round iterative revision process. 3.Trajectory Analysis: • Iteration #1:The CRA successfully resolves the Payment and Termination risks but fails to address the IP ownership transfer, merely polishing the language. • Fusion Feedback:The LV A triggers a negative reward signal...
-
[23]
Original Contract Segment (Input): "The Provider shall indemnify and hold the Client harmless from and against any and all claims, losses, damages , liabilities, and expenses arising out of or in connection with the Services, regardless of cause."
-
[24]
indemnify... from any and all claims... regardless of cause
Leader Agent Analysis (Strategic Instruction): •Category:EXCESSIVELIABILITY •Location:Section 9.1 (Indemnification) •Evidence:"...indemnify... from any and all claims... regardless of cause." •Issue:Creates unlimited exposure for the Provider; lacks a monetary cap or exclusion for indirect damages. • Suggestion: Limit liability to the fees paid in the pre...
-
[25]
The Provider shall indemnify the Client for direct losses arising from the Provider’s negligence
Follower System Execution (Iterative): [Revision #1 - Attempt]: "The Provider shall indemnify the Client for direct losses arising from the Provider’s negligence..."→Rejected by Inner Audit (Missing Cap). [Final Revision - Convergence]: "The Provider shall indemnify the Client for direct losses... provided that the Provider’s total aggregate liability sha...
-
[26]
Section 1.2
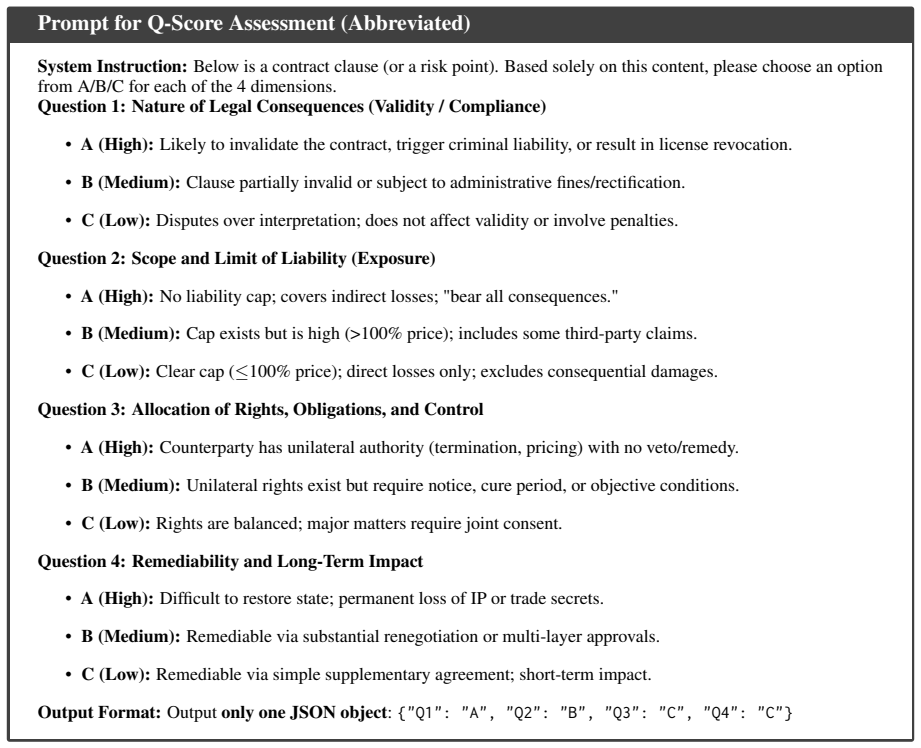
category: Specific risk classification (At least ten words or more, describe the risk category as detailed as possible). 2.location: Where this risk appears (e.g., "Section 1.2"). 3.evidence: Original text quote supporting this risk. If missing, state "Missing clause". 4.issue: Specific description of what is wrong (the defect, ambiguity, or unfairness). ...
-
[27]
You MUST rewrite the content in Section[Detected_Risk_Location]
-
[28]
Mere wording adjustments are insufficient: you MUST alter the logical framework to mitigate[Risk_Category]
-
[29]
bear all consequences
Penalty consequence for non-compliance: Penalty Score=∞(immediate optimization failure). Figure 19: The Force Rewrite injection mechanism. This acts as a perturbation vector to push the CRA out of local optima (i.e., lazy revisions) — triggered when the system detects zero effective edits despite unresolved risks. 26 Prompt for Q-Score Assessment (Abbrevi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.