How You Ask Matters! Adaptive RAG Robustness to Query Variations
Pith reviewed 2026-05-10 15:33 UTC · model grok-4.3
The pith
Small surface changes in queries cause large shifts in Adaptive RAG retrieval decisions and accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
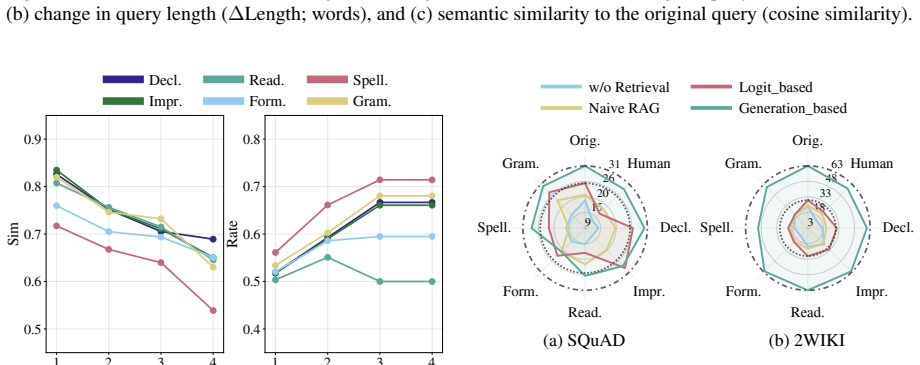
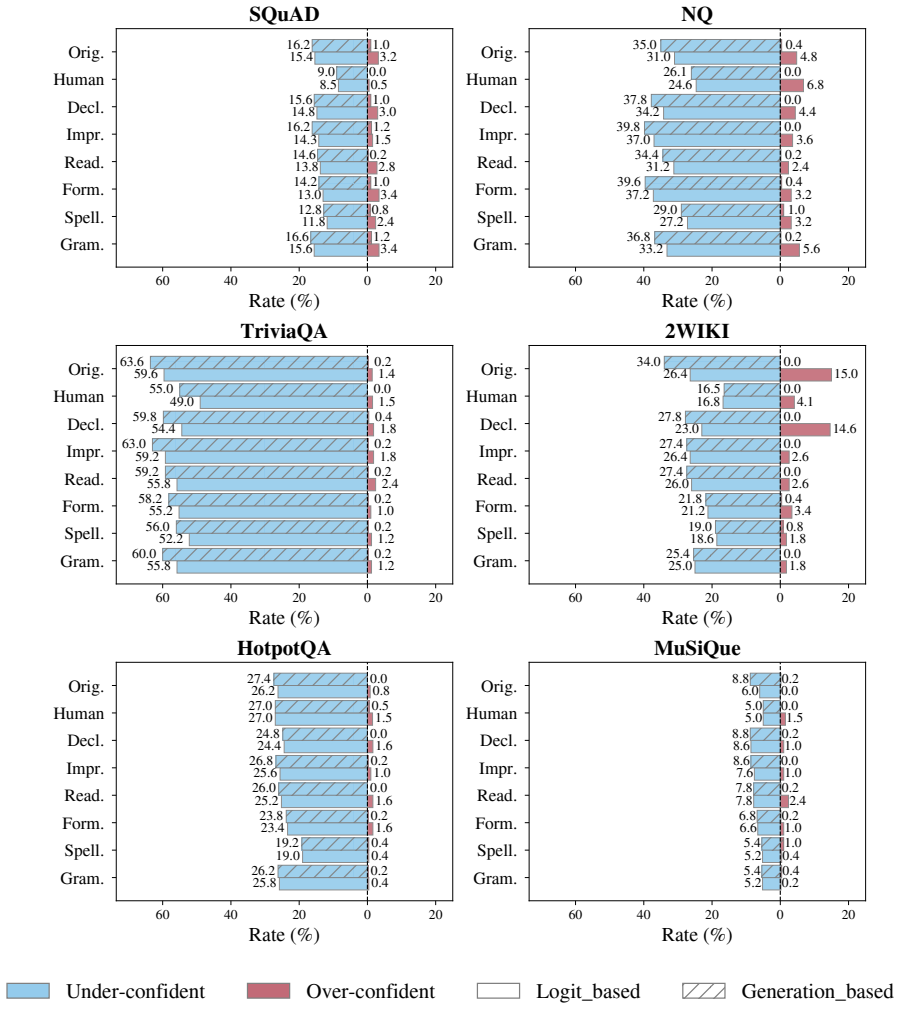
Adaptive RAG methods exhibit a critical robustness gap: semantically identical queries that differ only in surface form produce markedly different retrieval triggers and final accuracies. Larger language models raise overall performance but do not close this gap. The benchmark of human-written and model-generated rewrites makes the gap visible across three measured dimensions—answer quality, computational cost, and retrieval decisions—revealing that Adaptive RAG remains highly vulnerable to query variations that preserve identical semantics.
What carries the argument
A large-scale benchmark of diverse yet semantically identical query variations, built from human-written rewrites and model-generated rewrites, used to measure how Adaptive RAG components respond across answer quality, cost, and retrieval decisions.
If this is right
- Adaptive RAG systems must be evaluated for stability under query rephrasing in addition to raw accuracy.
- Larger models alone will not solve robustness problems in dynamic retrieval decisions.
- Retrieval triggers and cost controls in Adaptive RAG can be triggered by surface features rather than true information need.
- Benchmarking that includes multiple surface forms is required to expose hidden failure modes in production RAG pipelines.
Where Pith is reading between the lines
- Designers of future Adaptive RAG pipelines may need to add explicit semantic normalization steps before deciding whether to retrieve.
- The observed gap could be narrowed by training retrieval routers on paired examples of equivalent queries rather than single surface forms.
- Real-world user interfaces that accept free-form questions may see higher error rates than lab tests suggest unless robustness to wording is addressed.
Load-bearing premise
The rewrites used in the benchmark truly preserve identical semantics and intent without introducing subtle factual shifts or stylistic biases that themselves affect retrieval.
What would settle it
Run the same Adaptive RAG systems on a fresh set of real-user queries that have been independently verified to carry identical meaning, then check whether retrieval decisions and accuracy still vary as widely as observed on the benchmark.
Figures





















read the original abstract
Adaptive Retrieval-Augmented Generation (RAG) promises accuracy and efficiency by dynamically triggering retrieval only when needed and is widely used in practice. However, real-world queries vary in surface form even with the same intent, and their impact on Adaptive RAG remains under-explored. We introduce the first large-scale benchmark of diverse yet semantically identical query variations, combining human-written and model-generated rewrites. Our benchmark facilitates a systematic evaluation of Adaptive RAG robustness by examining its key components across three dimensions: answer quality, computational cost, and retrieval decisions. We discover a critical robustness gap, where small surface-level changes in queries dramatically alter retrieval behavior and accuracy. Although larger models show better performance, robustness does not improve accordingly. These findings reveal that Adaptive RAG methods are highly vulnerable to query variations that preserve identical semantics, exposing a critical robustness challenge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the first large-scale benchmark of query variations for Adaptive RAG, combining human-written and model-generated rewrites claimed to be semantically identical. It systematically evaluates Adaptive RAG methods across three dimensions—answer quality, computational cost, and retrieval decisions—reporting a critical robustness gap in which small surface-level query changes dramatically alter retrieval behavior and accuracy. Larger models are found to improve overall performance but not robustness to these variations.
Significance. If the benchmark's core assumption holds, the work identifies a practically important limitation in Adaptive RAG systems that are already deployed for efficiency. The new benchmark and multi-dimensional evaluation constitute a useful empirical contribution that could motivate more robust trigger mechanisms and query normalization techniques. The finding that scale does not confer robustness is a falsifiable observation worth testing in follow-up studies.
major comments (1)
- [Benchmark construction] Benchmark construction (as described in the abstract and introduction): the central claim attributes the observed robustness gap to surface-form variation alone, yet the manuscript provides no validation metrics—such as inter-annotator agreement scores, human semantic equivalence ratings, embedding cosine thresholds, or disagreement rates—for the human-written and model-generated rewrites. Without these, it is impossible to rule out that subtle factual shifts, entity substitutions, or stylistic cues are driving the reported differences in retrieval decisions and accuracy rather than surface variation.
minor comments (2)
- [Abstract] The abstract would benefit from reporting the total number of queries, number of rewrite pairs, and the specific Adaptive RAG baselines evaluated so readers can immediately gauge scale and coverage.
- [Evaluation] Clarify whether any statistical tests (e.g., paired t-tests or bootstrap confidence intervals) were applied to the differences in retrieval decisions and accuracy across rewrite types.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address the major comment regarding the validation of semantic equivalence in the benchmark construction below, and commit to incorporating additional metrics in the revised version.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction (as described in the abstract and introduction): the central claim attributes the observed robustness gap to surface-form variation alone, yet the manuscript provides no validation metrics—such as inter-annotator agreement scores, human semantic equivalence ratings, embedding cosine thresholds, or disagreement rates—for the human-written and model-generated rewrites. Without these, it is impossible to rule out that subtle factual shifts, entity substitutions, or stylistic cues are driving the reported differences in retrieval decisions and accuracy rather than surface variation.
Authors: We appreciate the referee's point on the need for explicit validation of semantic equivalence. The human-written rewrites were produced following detailed guidelines that instructed annotators to maintain identical meaning, entities, and facts while varying only the surface form. Similarly, the model-generated rewrites used prompts that explicitly required preserving semantics without introducing new information. However, we acknowledge that quantitative validation metrics were not reported in the original submission. In the revised manuscript, we will add a dedicated section on benchmark validation, including inter-annotator agreement for human rewrites, average embedding cosine similarities between original and variant queries, and results from a human evaluation study assessing semantic equivalence ratings. These additions will provide stronger evidence that the observed robustness gap is indeed due to surface variations rather than unintended semantic changes. revision: yes
Circularity Check
Empirical benchmark study with no derivation chain or self-referential fitting.
full rationale
The paper is an empirical evaluation introducing a benchmark of query rewrites and comparing Adaptive RAG methods on answer quality, cost, and retrieval decisions. No equations, fitted parameters, or mathematical derivations are present in the provided text. Claims rest on experimental observations rather than any step that reduces by construction to author-defined inputs or self-citations. The semantic-equivalence assumption for rewrites is an empirical premise open to validation but does not create circularity in any derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantically identical queries can be reliably produced by human writers and LLMs without introducing new factual content or retrieval-relevant biases.
Reference graph
Works this paper leans on
-
[1]
Classifying term variants in query formula- tion. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’25, page 2395–2406, New York, NY , USA. Association for Computing Machinery. Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2024. Self-RAG: Learning to retriev...
-
[2]
The power of noise: Redefining retrieval for rag systems. InProceedings of the 47th Interna- tional ACM SIGIR Conference on Research and De- velopment in Information Retrieval, SIGIR ’24, page 719–729, New York, NY , USA. Association for Com- puting Machinery. Hanxing Ding, Liang Pang, Zihao Wei, Huawei Shen, and Xueqi Cheng. 2025. Rowen: Adaptive retriev...
-
[3]
Gustavo Penha, Arthur Câmara, and Claudia Hauff
Evaluating the robustness of retrieval pipelines with query variation generators.CoRR, abs/2111.13057. Gustavo Penha, Arthur Câmara, and Claudia Hauff
-
[4]
Evaluating the robustness of retrieval pipelines with query variation generators. InAdvances in In- formation Retrieval: 44th European Conference on IR Research, ECIR 2022, Stavanger, Norway, April 10–14, 2022, Proceedings, Part I, page 397–412, Berlin, Heidelberg. Springer-Verlag. Sezen Perçin, Xin Su, Qutub Sha Syed, Phillip Howard, Aleksei Kuvshinov, L...
work page 2022
-
[5]
S., Dernoncourt, F., Sultania, D., Bagga, K., Zhang, M., Bui, T., and Kotte, V
Qa dataset explosion: A taxonomy of nlp resources for question answering and reading com- prehension.ACM Computing Surveys, 55(10):1–45. Sanat Sharma, David Seunghyun Yoon, Franck Dernon- court, Dewang Sultania, Karishma Bagga, Mengjiao Zhang, Trung Bui, and Varun Kotte. 2024. Retrieval augmented generation for domain-specific question answering.Preprint,...
-
[6]
Knowing you don’t know: Learning when to continue search in multi-round rag through self- practicing. InProceedings of the 48th International ACM SIGIR Conference on Research and Devel- opment in Information Retrieval, SIGIR ’25, page 1305–1315, New York, NY , USA. Association for Computing Machinery. Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, W...
-
[7]
Shengyao Zhuang and Guido Zuccon
Qe-rag: A robust retrieval-augmented gener- ation benchmark for query entry errors.Preprint, arXiv:2504.04062. Shengyao Zhuang and Guido Zuccon. 2022. Character- bert and self-teaching for improving the robustness of dense retrievers on queries with typos. InProceed- ings of the 45th International ACM SIGIR Confer- ence on Research and Development in Info...
-
[8]
Task Definition: You are rewriting a query to make it significantly less readable while preserving the original semantic meaning as closely as possible
-
[9]
Constraints & Goals: - Flesch Reading Ease Score: The rewritten text must have a Flesch score below 60 (preferably below 50). - Semantic Similarity: The rewritten text must have SBERT similarity > 0.7 compared with the original query. - Length: The rewritten text must remain approximately the same length as the original query (±10%). - Preserve Domain Ter...
-
[10]
How to Increase Complexity: - Lexical Changes: Use advanced or academic synonyms only for common words. For domain or key terms (e.g., "distance," "IRS," "tax"), keep the original term or use a very close synonym if necessary to maintain meaning. - Syntactic Complexity: Introduce passive voice, nominalizations, embedded clauses, and parenthetical or subor...
-
[11]
You will be given a query (question) and its corresponding answer
-
[12]
Your task is to rewrite the given query — imagine how you would ask the same question if you were speaking to a large language model (like ChatGPT). What You Should Do
-
[13]
◦Identify what the user is trying to find out
Understand the original query. ◦Identify what the user is trying to find out. ◦Grasp the intent and main topic clearly
-
[14]
◦You may change the tone, phrasing, or structure
Rewrite the query in a new way while keeping the same meaning. ◦You may change the tone, phrasing, or structure. ◦Information loss, addition, or simplification is acceptable. ◦The goal is to make the rewritten query similar in meaning but different in expression. ◦ Make sure that your rewritten query can still be answered appropriately with the same answe...
-
[15]
◦You can make the question sound more casual, detailed, concise, or clear
Incorporate your personal style. ◦You can make the question sound more casual, detailed, concise, or clear. ◦Different writing styles and tones are encouraged
-
[16]
◦Do not simply rephrase it with only minor surface changes
Avoid copying the original query. ◦Do not simply rephrase it with only minor surface changes. ◦The rewritten query should feel genuinely reworded and natural
-
[17]
◦The answer helps you understand what the original query intended to ask
Use the answer only for context. ◦The answer helps you understand what the original query intended to ask. ◦You should not change your rewrite based on the answer’s content. ◦Your task is to rewrite the question, not the answer. Table 15: Human Annotation Instruction: Query Rewriting Task. 20 Orig. Human Decl. Impr. Read. Form. Spell. Gram. 5 10 15 19 24 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.